 如何在統計軟件R中進行方差分析測試
如何在統計軟件R中進行方差分析測試
步驟1:入門:
如果您的計算機上尚未存在R,則可以從官方網站免費下載位于:
http://cran.r-project.org/bin/windows/base/(Windows)
http://cran.r-project.org/bin/macosx/(Mac)
http://cran.r-project.org/(Linux)
選擇該版本的(32bit/64bit)版本操作系統的自然基礎。
打開R:
您將看到基本命令建議已打開。這是已執行命令的日志和輸出。但是,無法對其進行編輯,使其難以使用,而是使用以下命令打開腳本窗口:
文件》》
新腳本
此窗口充當基本的文字處理器(靠近記事本),可以通過右鍵單擊一行或所選內容并運行它來編寫,編輯和執行命令。或者,快捷鍵Control + r也將執行一行或選擇。
注意:
您可以通過在注釋的開頭加上井號(#)來在R中編寫注釋。步驟3中顯示了一個示例。
步驟2:讀取數據:
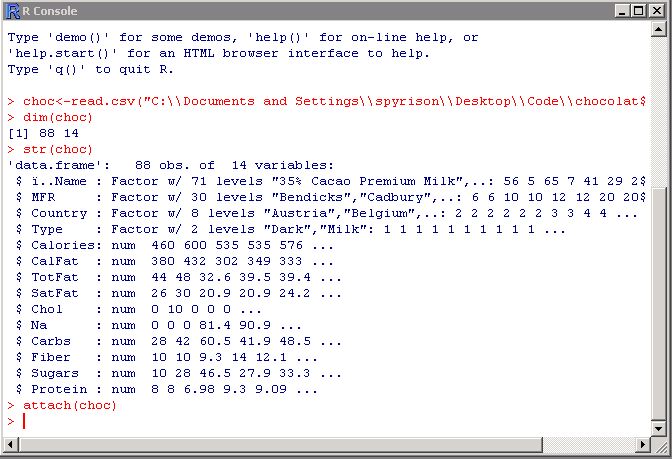
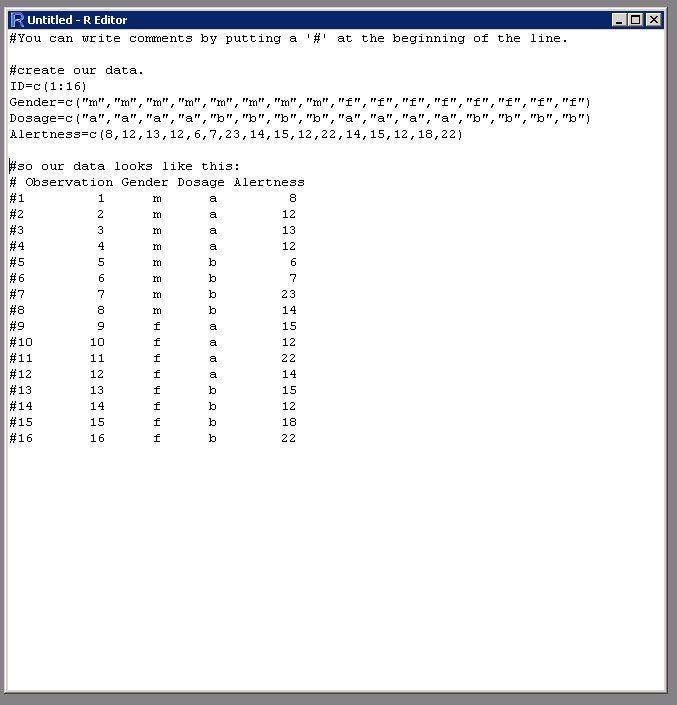
.csv也許是最流行的文件處理數據文件時鍵入。 .csv文件可以從excel輕松制作。或者,您可以通過命名和指向變量將數據直接輸入R中(請參見輔助映像)。如果您有.csv文件,那就太好了!使用以下命令之一讀取它:
數據名稱= read.csv(“適當的網頁或文件目錄”)
數據名稱= read.csv(file.choose( ))
完成此操作之后,請使用以下命令瀏覽數據:
dim(數據名稱)
str(數據名稱)
頭(數據名稱)
附加(數據名稱)
注意:
您將需要運行附加,否則需要R不會知道您要指的是什么數據集。
第3步:運行ANOVA測試:


您做的很棒!您已經接近完成一個獨立變量ANOVA測試。
使用以下R命令運行方差分析:
name = aov(y variable?x variable)#運行ANOVA測試。 》 ls(name)#列出測試存儲的項目。
summary(name)#給出基本的方差分析輸出。
圖像中的示例將卡路里作為因變量y與一個自變量進行比較(在此示例中為糖)。
注意:
如果R找不到指定的變量,請確保標點符號匹配并且您已經執行了‘attach(data)’命令。
步驟4:然后是一個自變量
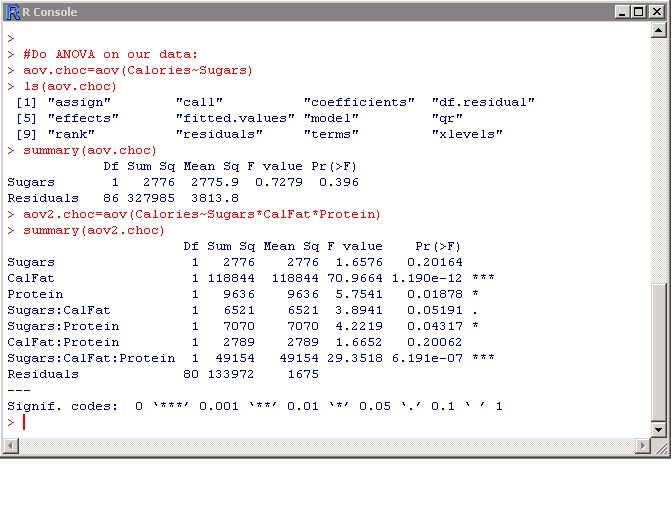
具有多個自變量x1,x2到xn的情況是一個簡單的變化。 br》修改代碼,使自變量成為在它們之間帶有星號(*)的乘積:
name = aov(y?x1 * x2 * xn)
步驟5:解釋數據:
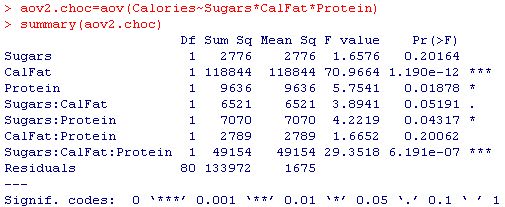
讓我們從中獲取多元模型第4步。在這里,我們嘗試用糖,卡路里,脂肪,蛋白質以及它們彼此之間的相互作用(糖* CalFat,糖*蛋白質,CalFat *蛋白質和糖* CalFat *蛋白質)來描述卡路里。
焦點在列上:F大于上一列列出的值的概率。這通常稱為 p值。在大多數情況下,您將重要性置于alpha = .05級別,或者我們要求P值小于.05 才被視為具有統計意義。
立即我們可以看到,術語Sugars ,Sugars * CalFat和CalFat * Protein在.05級別上不顯著。或者,我們看到CalFat和Sugars * CalFat * Protein分別是最佳術語,P值遠小于.05。
由此我們可以得出結論,如果您的目標是描述卡路里,則只需對CalFat進行回歸或潛在的糖* CalFat *蛋白質。如果您打算采集更多樣本,而您只關心它的預測或描述卡路里,那么您現在只需要從Fat中收集卡路里,而不必收集所有其他變量。
責任編輯:wv
-
軟件
+關注
關注
69文章
4970瀏覽量
87714
發布評論請先 登錄
相關推薦
Minitab常用功能介紹 如何在 Minitab 中進行回歸分析
Minitab 在統計分析中的應用
示波器統計曲線和故障分析pass/fail測試
TS RadiMation測試軟件如何在脈沖抗擾度測試中發揮作用?
TS-RadiMation測試軟件如何在序列測試中發揮作用?
Allan 方差理論及測量方法

泰克推出SignalVu頻譜分析儀軟件5.4版,可進行多通道調制分析
機器學習模型偏差與方差詳解






 工商網監
工商網監
評論