 如何利用Tensorflow編寫一個基本的端到端自動語音識別
如何利用Tensorflow編寫一個基本的端到端自動語音識別
本文闡述了如何利用Tensorflow編寫一個基本的端到端自動語音識別(Automatic Speech Recognition,ASR)系統,詳細介紹了最小神經網絡的各個組成部分以及可將音頻轉為可讀文本的前綴束搜索解碼器。
雖然當下關于如何搭建基礎機器學習系統的文獻或資料有很多,但是大部分都是圍繞計算機視覺和自然語言處理展開的,極少有文章就語音識別展開介紹。本文旨在填補這一空缺,幫助初學者降低入門難度,提高學習自信。
前提
初學者需要熟練掌握:
· 神經網絡的組成
· 如何訓練神經網絡
· 如何利用語言模型求得詞序的概率
概述
· 音頻預處理:將原始音頻轉換為可用作神經網絡輸入的數據
· 神經網絡:搭建一個簡單的神經網絡,用于將音頻特征轉換為文本中可能出現的字符的概率分布
· CTC損失:計算不使用相應字符標注音頻時間步長的損失
· 解碼:利用前綴束搜索和語言模型,根據各個時間步長的概率分布生成文本
本文重點講解了神經網絡、CTC損失和解碼。
音頻預處理
搭建語音識別系統,首先需要將音頻轉換為特征矩陣,并輸入到神經網絡中。完成這一步的簡單方法就是創建頻譜圖。
def create_spectrogram(signals):
stfts = tf.signal.stft(signals, fft_length=256)
spectrograms = tf.math.pow(tf.abs(stfts), 0.5)
return spectrograms
這一方法會計算出音頻信號的短時傅里葉變換(Short-time Fourier Transform)以及功率譜,其最終輸出可直接用作神經網絡輸入的頻譜圖矩陣。其他方法包括濾波器組和MFCC(Mel頻率倒譜系數)等。
了解更多音頻預處理知識:https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
神經網絡
下圖展現了一個簡單的神經網絡結構。
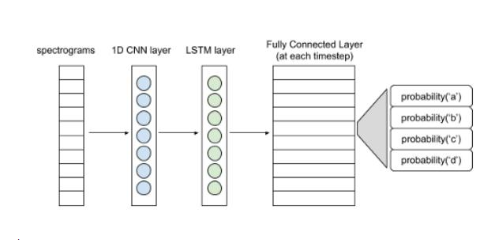
語音識別基本結構
頻譜圖輸入可以看作是每個時間步長的向量。1D卷積層從各個向量中提取出特征,形成特征向量序列,并輸入LSTM層進一步處理。LSTM層(或雙LSTM層)的輸入則傳遞至全連接層。利用softmax激活函數,可得出每個時間步長的字符概率分布。整個網絡將會用CTC損失函數進行訓練(CTC即Connectionist Temporal Classification,是一種時序分類算法)。熟悉整個建模流程后可嘗試使用更復雜的模型。
class ASR(tf.keras.Model):
def __init__(self, filters, kernel_size, conv_stride, conv_border, n_lstm_units, n_dense_units):
super(ASR, self).__init__()
self.conv_layer = tf.keras.layers.Conv1D(filters,
kernel_size,
strides=conv_stride,
padding=conv_border,
activation=‘relu’)
self.lstm_layer = tf.keras.layers.LSTM(n_lstm_units,
return_sequences=True,
activation=‘tanh’)
self.lstm_layer_back = tf.keras.layers.LSTM(n_lstm_units,
return_sequences=True,
go_backwards=True,
activation=‘tanh’)
self.blstm_layer = tf.keras.layers.Bidirectional(self.lstm_layer, backward_layer=self.lstm_layer_back)
self.dense_layer = tf.keras.layers.Dense(n_dense_units)
def call(self, x):
x = self.conv_layer(x)
x = self.blstm_layer(x)
x = self.dense_layer(x)
return x
為什么使用CTC呢?搭建神經網絡旨在預測每個時間步長的字符。然而現有的標簽并不是各個時間步長的字符,僅僅是音頻的轉換文本。而文本的各個字符可能橫跨多個步長。如果對音頻的各個時間步長進行標記,C-A-T就會變成C-C-C-A-A-T-T。而每隔一段時間,如10毫秒,對音頻數據集進行標注,并不是一個切實可行的方法。CTC則解決上了上述問題。CTC并不需要標記每個時間步長。它忽略了文本中每個字符的位置和實際相位差,把神經網絡的整個概率矩陣輸入和相應的文本作為輸入。
CTC 損失計算
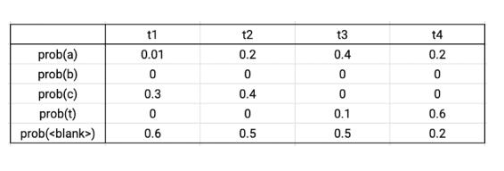
輸出矩陣示例
假設真實的數據標簽為CAT,在四個時間步長中,有序列C-C-A-T,C-A-A-T,C-A-T-T,_-C-A-T,C-A-T-_與真實數據相對應。將這些序列的概率相加,可得到真實數據的概率。根據輸出的概率矩陣,將序列的各個字符的概率相乘,可得到單個序列的概率。則上述序列的總概率為0.0288+0.0144+0.0036+0.0576+0.0012=0.1056。CTC損失則為該概率的負對數。Tensorflow自帶損失函數文件。
解碼
由上文的神經網絡,可輸出一個CTC矩陣。這一矩陣給出了各個時間步長中每個字符在其字符集中的概率。利用前綴束搜索,可從CTC矩陣中得出所需的文本。
除了字母和空格符,CTC矩陣的字符集還包括兩種特別的標記(token,也稱為令牌)——空白標記和字符串結束標記。
空白標記的作用:CTC矩陣中的時間步長通常比較小,如10毫秒。因此,句子中的一個字符會橫跨多個時間步長。如,C-A-T會變成C-C-C-A-A-T-T。所以,需要將CTC矩陣中出現該問題的字符串中的重復部分折疊,消除重復。那么像FUNNY這種本來就有兩個重復字符(N)的詞要怎么辦呢?在這種情況下,就可以使用空白標記,將其插入兩個N中間,就可以防止N被折疊。而這么做實際上并沒有在文本中添加任何東西,也就不會影響其內容或形式。因此,F-F-U-N-[空白]-N-N-Y最終會變成FUNNY。
結束標記的作用:字符串的結束表示著一句話的結束。對字符串結束標記后的時間步長進行解碼不會給候選字符串增加任何內容。
步驟
初始化
· 準備一個初始列表。列表包括多個候選字符串,一個空白字符串,以及各個字符串在不同時間步長以空白標記結束的概率,和以非空白標記結束的概率。在時刻0,空白字符串以空白標記結束的概率為1,以非空白標記結束的概率則為0。
迭代
· 選擇一個候選字符串,將字符一個一個添加進去。計算拓展后的字符串在時刻1以空白標記和非空白標記結束的概率。將拓展字符串及其概率記錄到列表中。將拓展字符串作為新的候選字符串,在下一時刻重復上述步驟。
· 情況A:如果添加的字符是空白標記,則保持候選字符串不變。
· 情況B:如果添加的字符是空格符,則根據語言模型將概率與和候選字符串的概率成比例的數字相乘。這一步可以防止錯誤拼寫變成最佳候選字符串。如,避免COOL被拼成KUL輸出。
· 情況C:如果添加的字符和候選字符串的最后一個字符相同,(以候選字符串FUN和字符N為例),則生成兩個新的候選字符串,FUNN和FUN。生成FUN的概率取決于FUN以空白標記結束的概率。生成FUNN的概率則取決于FUN以非空白標記結束的概率。因此,如果FUN以非空白標記結束,則去除額外的字符N。
輸出
經過所有時間步長迭代得出的最佳候選字符串就是輸出。
為了加快這一過程,可作出如下兩個修改。
1.在每一個時間步長,去除其他字符串,僅留下最佳的K個候選字符串。具體操作為:根據字符串以空白和非空白標記結束的概率之和,對候選字符串進行分類。
2.去除矩陣中概率之和低于某個閾值(如0.001)的字符。
具體操作細節可參考如下代碼。
def prefix_beam_search(ctc,
alphabet,
blank_token,
end_token,
space_token,
lm,
k=25,
alpha=0.30,
beta=5,
prune=0.001):
‘’‘
function to perform prefix beam search on output ctc matrix and return the best string
:param ctc: output matrix
:param alphabet: list of strings in the order their probabilties are present in ctc output
:param blank_token: string representing blank token
:param end_token: string representing end token
:param space_token: string representing space token
:param lm: function to calculate language model probability of given string
:param k: threshold for selecting the k best prefixes at each timestep
:param alpha: language model weight (b/w 0 and 1)
:param beta: language model compensation (should be proportional to alpha)
:param prune: threshold on the output matrix probability of a character.
If the probability of a character is less than this threshold, we do not extend the prefix with it
:return: best string
’‘’
zero_pad = np.zeros((ctc.shape[0]+1,ctc.shape[1]))
zero_pad[1:,:] = ctc
ctc = zero_pad
total_timesteps = ctc.shape[0]
# #### Initialization ####
null_token = ‘’
Pb, Pnb = Cache(), Cache()
Pb.add(0,null_token,1)
Pnb.add(0,null_token,0)
prefix_list = [null_token]
# #### Iterations ####
for timestep in range(1, total_timesteps):
pruned_alphabet = [alphabet[i] for i in np.where(ctc[timestep] 》 prune)[0]]
for prefix in prefix_list:
if len(prefix) 》 0 and prefix[-1] == end_token:
Pb.add(timestep,prefix,Pb.get(timestep - 1,prefix))
Pnb.add(timestep,prefix,Pnb.get(timestep - 1,prefix))
continue
for character in pruned_alphabet:
character_index = alphabet.index(character)
# #### Iterations : Case A ####
if character == blank_token:
value = Pb.get(timestep,prefix) + ctc[timestep][character_index] * (Pb.get(timestep - 1,prefix) + Pnb.get(timestep - 1,prefix))
Pb.add(timestep,prefix,value)
else:
prefix_extended = prefix + character
# #### Iterations : Case C ####
if len(prefix) 》 0 and character == prefix[-1]:
value = Pnb.get(timestep,prefix_extended) + ctc[timestep][character_index] * Pb.get(timestep-1,prefix)
Pnb.add(timestep,prefix_extended,value)
value = Pnb.get(timestep,prefix) + ctc[timestep][character_index] * Pnb.get(timestep-1,prefix)
Pnb.add(timestep,prefix,value)
# #### Iterations : Case B ####
elif len(prefix.replace(space_token, ‘’)) 》 0 and character in (space_token, end_token):
lm_prob = lm(prefix_extended.strip(space_token + end_token)) ** alpha
value = Pnb.get(timestep,prefix_extended) + lm_prob * ctc[timestep][character_index] * (Pb.get(timestep-1,prefix) + Pnb.get(timestep-1,prefix))
Pnb.add(timestep,prefix_extended,value)
else:
value = Pnb.get(timestep,prefix_extended) + ctc[timestep][character_index] * (Pb.get(timestep-1,prefix) + Pnb.get(timestep-1,prefix))
Pnb.add(timestep,prefix_extended,value)
if prefix_extended not in prefix_list:
value = Pb.get(timestep,prefix_extended) + ctc[timestep][-1] * (Pb.get(timestep-1,prefix_extended) + Pnb.get(timestep-1,prefix_extended))
Pb.add(timestep,prefix_extended,value)
value = Pnb.get(timestep,prefix_extended) + ctc[timestep][character_index] * Pnb.get(timestep-1,prefix_extended)
Pnb.add(timestep,prefix_extended,value)
prefix_list = get_k_most_probable_prefixes(Pb,Pnb,timestep,k,beta)
# #### Output ####
return prefix_list[0].strip(end_token)
這樣,一個基礎的語音識別系統就完成了。對上述步驟進行復雜化,可以得到更優的結果,如,搭建更大的神經網絡和利用音頻預處理技巧。
完整代碼:https://github.com/apoorvnandan/speech-recognition-primer
注意事項:
1. 文中代碼使用的是TensorFlow2.0系統,舉例使用的音頻文件選自LibriSpeech數據庫(http://www.openslr.org/12)。
2. 文中代碼并不包括訓練音頻數據集的批量處理生成器。讀者需要自己編寫。
3. 讀者亦需自己編寫解碼部分的語言模型函數。最簡單的方法就是基于語料庫生成一部二元語法字典并計算字符概率。
-
語音識別
+關注
關注
38文章
1742瀏覽量
112697 -
機器學習
+關注
關注
66文章
8422瀏覽量
132741 -
tensorflow
+關注
關注
13文章
329瀏覽量
60537
發布評論請先 登錄
相關推薦
端到端自動駕駛技術研究與分析
端到端在自動泊車的應用
階躍星辰發布國內首個千億參數端到端語音大模型
準確性超Moshi和GLM-4-Voice,端到端語音雙工模型Freeze-Omni

爆火的端到端如何加速智駕落地?
連接視覺語言大模型與端到端自動駕駛

Waymo利用谷歌Gemini大模型,研發端到端自動駕駛系統
Mobileye端到端自動駕駛解決方案的深度解析

端到端語音解決方案的Renesas RA8M1語音套件


理想汽車加速自動駕駛布局,成立“端到端”實體組織
佐思汽研發布《2024年端到端自動駕駛研究報告》

理想汽車自動駕駛端到端模型實現






 工商網監
工商網監
評論