 Spark SQL性能實現17.7倍的提升,是如何做到的
Spark SQL性能實現17.7倍的提升,是如何做到的
(文章來源:砍柴網)
Apache Spark是專為大規模數據處理而設計的快速通用的計算引擎,常用來構建大型、低延遲的數據分析應用程序。Spark一個主要特點在于,其能夠在內存中進行計算,這使得其數據分析效率往往高于其它計算引擎,但是,服務器內存資源的限制也使得其性能的擴展存在著一定的瓶頸,在超大規模負載中無法充分發揮其利用內存進行計算的性能優勢。
某全球領先的語音識別服務提供商是最早將Spark應用到生產環境的團隊之一,該公司的語音云通過幾千臺服務器構成的云計算平臺向用戶提供多樣的、實時語音處理能力,日均服務終端用戶超過15億,日增數據超過100TB。2014年該公司基于Spark和AI技術構建了DMP大數據平臺(用戶數據管理平臺)。DMP平臺的主要功能就是收集、存儲、分析和挖掘龐大的用戶數據,以實現廣告精準投放。
Spark在該公司的大數據平臺中主要用于海量用戶數據分析,每天支撐穩定運行的Spark SQL統計分析指標和SQL腳本有幾千個。但是在將Spark SQL用于海量用戶數據分析的過程中,仍然面臨著一些痛點,這些都限制了該公司語音云的數據分析能力。
Spark的性能不僅受到CPU、內存、網絡、磁盤等硬件設備的制約,而且Spark SQL目前還不支持索引,也嚴重影響了Spark SQL在進行大規模數據分析時的性能,索引能夠提升數據檢索的效率,降低硬盤的IO瓶頸。
隨著數據量越來越大,即席分析的需求越來越強烈,即席查詢是用戶根據用戶自己的需求,靈活選擇查詢條件,系統能夠根據用戶的選擇生成響應的統計報表和結果集;在數據倉庫和大數據分析系統中,即席查詢使用的越多,對系統的性能要求也就越高,如果內存能夠緩存更多的熱點數據,能夠極大的提升即席查詢處理速度并降低響應延遲。
數據既有隨機讀的需求(即席查詢-Ad-hoc),又有全表掃描的需求(機器學習);機器學習就是通過特定算法從海量的歷史數據中學習規律,從而對新的樣本進行分析并對未來做出預測,在模型訓練的過程中會產生大量的中間結果數據,通常情況下需要將中間結果數據持久化到文件系統上,如果內存能夠緩存更多的中間結果數據,可以提升模型訓練的速度。
(責任編輯:fqj)
-
互聯網
+關注
關注
54文章
11167瀏覽量
103480 -
ai技術
+關注
關注
1文章
1281瀏覽量
24351
發布評論請先 登錄
相關推薦
藍牙AOA定位系統如何做到高精準度?
谷歌正式發布Gemini 2.0 性能提升近兩倍
QPS提升10倍的sql優化
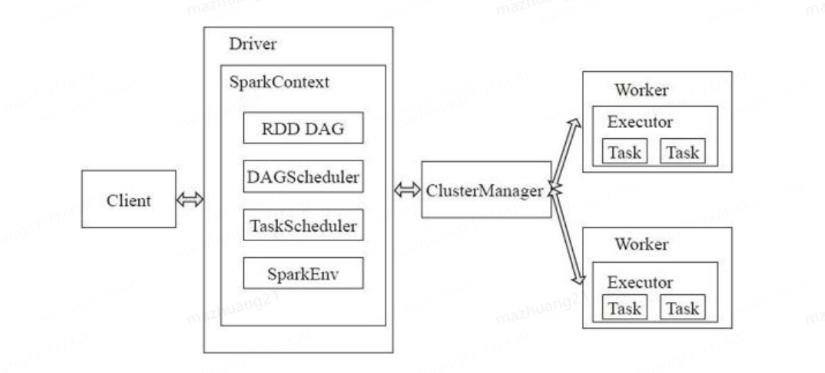
spark運行的基本流程
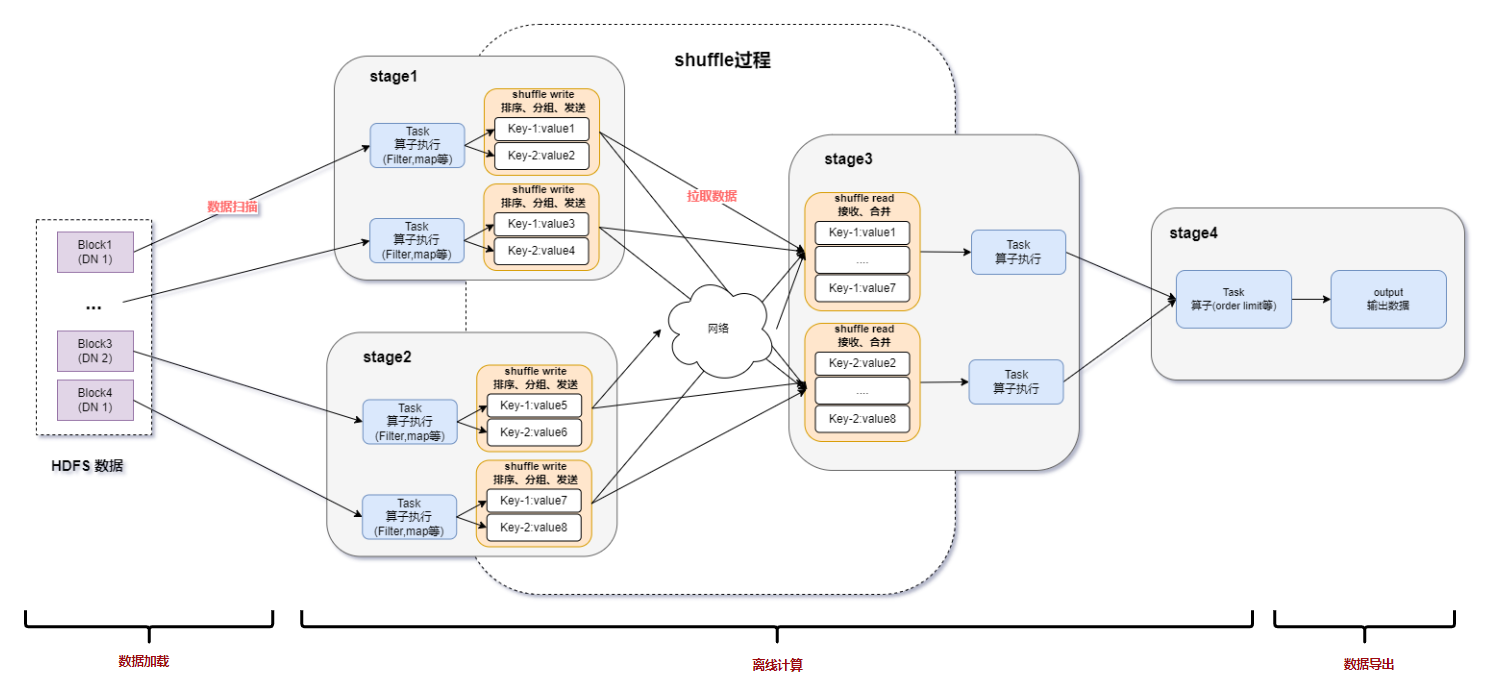
Spark基于DPU的Native引擎算子卸載方案

Flow Computing引領CPU性能革命:PPU技術實現百倍性能提升
STM32在PWM輸出模式中,如何做到PWM移向輸出?
龍芯:自主研發CPU提升性能,單核通用性能提高20倍
Spark基于DPU Snappy壓縮算法的異構加速方案
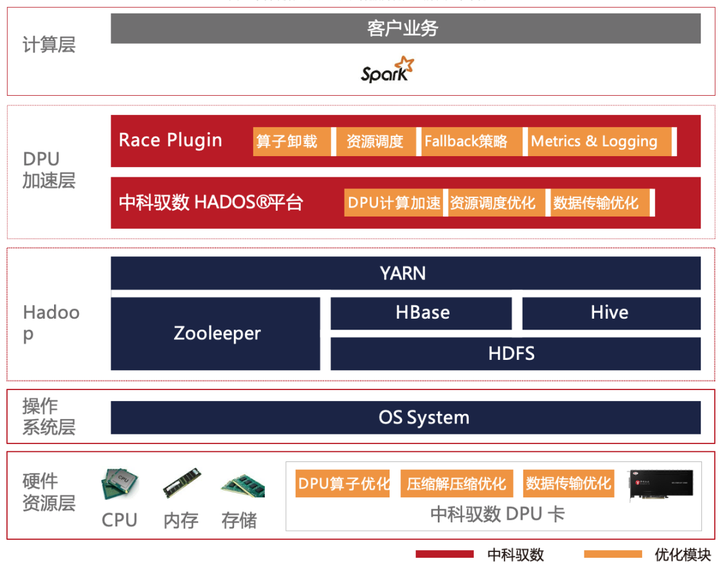
基于DPU和HADOS-RACE加速Spark 3.x





 工商網監
工商網監
評論