") 谷歌采用全新AI架構(gòu),晶體管性能得到巨幅提升
谷歌采用全新AI架構(gòu),晶體管性能得到巨幅提升
(文章來源:機器之心Pro)
TSP 的全稱是 Tensor Streaming Processor,專為機器學(xué)習(xí)等 AI 相關(guān)需求打造。該架構(gòu)在單塊芯片上可以實現(xiàn)每秒 1000 萬億(10 的 15 次方)次運算,是全球首個實現(xiàn)該級別性能的架構(gòu),其浮點運算性能可達每秒 250 萬億次(TFLOPS)。在摩爾定律走向消亡的背景下,這一架構(gòu)的問世標(biāo)志著芯片之爭從晶體管轉(zhuǎn)向架構(gòu)。
250 TFLOPS 浮點運算性能是什么概念?目前的世界第一超級計算機 Summit,其峰值算力為 200,794.9 TFLOPS,它的背后是 28,000 塊英偉達 Volta GPU。如果 TSP 達到了類似的效率,僅需 803 塊就可以實現(xiàn)同樣的性能。Groq 在一份白皮書中介紹了這項全新的架構(gòu)設(shè)計。此外,他們還將在于美國丹佛舉辦的第 23 屆國際超算高峰論壇上展示這一成果。
我們?yōu)檫@一行業(yè)和我們的客戶感到興奮,Groq 的聯(lián)合創(chuàng)始人和 CEO Jonathan Ross 表示。頂級 GPU 公司都在宣稱他們有望在未來幾年向用戶交付一款每秒百萬億次運算性能的產(chǎn)品,但 Groq 現(xiàn)在就做到了,而且建立了一個新的性能標(biāo)準(zhǔn)。就低延遲和推理速度而言,Groq 的架構(gòu)比其他任何用于推理的架構(gòu)都要快許多倍。我們與用戶的互動證明了這一點。
Groq 的 TSP 架構(gòu)是專為計算機視覺、機器學(xué)習(xí)和其他 AI 相關(guān)工作負載的性能要求設(shè)計的。對于一大批需要深度學(xué)習(xí)推理運算的應(yīng)用來說,Groq 的解決方案是非常理想的選擇,Groq 的首席架構(gòu)師 Dennis Abts 表示,但除此之外,Groq 的架構(gòu)還能用于廣泛的工作負載。它的性能和簡潔性使其成為所有高性能即數(shù)據(jù)和計算密集型工作復(fù)雜的理想平臺。
Groq 的這款架構(gòu)受到軟件優(yōu)先(software first)理念的啟發(fā)。它在 Groq 開發(fā)的 TSP 中實現(xiàn),為實現(xiàn)計算靈活性和大規(guī)模并行計算提供了一種新的范式,但沒有傳統(tǒng) GPU 和 CPU 架構(gòu)的限制和溝通開銷。在 Groq 的架構(gòu)中,Groq 編譯器負責(zé)編碼所有內(nèi)容:數(shù)據(jù)流入芯片,并在正確的時間和正確的地點插入,以確保計算實時進行,沒有停頓。執(zhí)行規(guī)劃由軟件負責(zé),這樣就可以釋放出原本要用于動態(tài)指令執(zhí)行的寶貴硬件資源。
在傳統(tǒng)的體系架構(gòu)中,將數(shù)據(jù)從 DRAM 移動到處理器需要大量的算力和時間,而且相同工作負載上的處理性能也是可變的。在典型的工作流中,開發(fā)人員通過反復(fù)運行工作負載或程序來對其進行配置和測試,以驗證和度量其平均處理性能。由于處理器接收和發(fā)送數(shù)據(jù)的方式不同,這種處理可能會得到略有差別的結(jié)果,而開發(fā)人員的工作就是手動調(diào)整程序以達到預(yù)定的可靠性級別。
但有了 Groq 的硬件和軟件,編譯器就可以準(zhǔn)確地知道芯片的工作方式以及執(zhí)行每個計算所需的時間。編譯器在正確的時間將數(shù)據(jù)和指令移動到正確的位置,這樣就不會有延遲。到達硬件的指令流是完全編排好的,使得處理速度更快,而且可預(yù)測。開發(fā)人員可以在 Groq 芯片上運行相同的模型 100 次,每次得到的結(jié)果都完全相同。對于安全和準(zhǔn)確性要求都非常高的應(yīng)用來說(如自動駕駛汽車),這種計算上的準(zhǔn)確性至關(guān)重要。
另外,使用 Groq 硬件設(shè)計的系統(tǒng)不會受到長尾延遲的影響,AI 系統(tǒng)可以在特定的功率或延遲預(yù)算內(nèi)進行調(diào)整。這種軟件優(yōu)先的設(shè)計(即編譯器決定硬件架構(gòu))理念幫助 Groq 設(shè)計出了一款簡單、高性能的架構(gòu),可以加速推理流程。該架構(gòu)既支持傳統(tǒng)的機器學(xué)習(xí)模型,也支持新的計算學(xué)習(xí)模型,目前在 x86 和非 x86 系統(tǒng)的客戶站點上運行。
為了滿足深度學(xué)習(xí)等計算密集型任務(wù)的需求,芯片的設(shè)計似乎正在變得越來越復(fù)雜。但 Groq 認為,這種趨勢從根本上就是錯誤的。他們在白皮書中指出,當(dāng)前處理器架構(gòu)的復(fù)雜性已經(jīng)成為阻礙開發(fā)者生產(chǎn)和 AI 應(yīng)用部署的主要障礙。當(dāng)前處理器的復(fù)雜性降低了開發(fā)者工作效率,再加上摩爾定律逐漸變慢,實現(xiàn)更高的計算性能變得越來越困難。
Groq 的芯片設(shè)計降低了傳統(tǒng)硬件開發(fā)的復(fù)雜度,因此開發(fā)者可以更加專注于算法(或解決其他問題),而不是為了硬件調(diào)整自己的解決方案。有了這種更加簡單的硬件設(shè)計,開發(fā)者無需進行剖析研究(profiling),因此可以節(jié)省資源,更容易大規(guī)模部署 AI 應(yīng)用。與基于 CPU、GPU 和 FPGA 的傳統(tǒng)復(fù)雜架構(gòu)相比,Groq 的芯片還簡化了認證和部署,使客戶能夠簡單而快速地實現(xiàn)可擴展、單瓦高性能的系統(tǒng)。
Groq 的張量流架構(gòu)可以在任何需要的地方提供算力。與當(dāng)前領(lǐng)先的 GPU、CPU 相比,Groq 處理器的每個晶體管可以實現(xiàn) 3-6 倍的性能提升。這一改進意味著交付性能的提升、延遲的下降以及成本的降低。結(jié)果是,Groq 的架構(gòu)使用起來更加簡單,而且性能高于傳統(tǒng)計算平臺。
(責(zé)任編輯:fqj)
-
谷歌
+關(guān)注
關(guān)注
27文章
6173瀏覽量
105634 -
AI芯片
+關(guān)注
關(guān)注
17文章
1894瀏覽量
35103
發(fā)布評論請先 登錄
相關(guān)推薦
如何測試晶體管的性能 常見晶體管品牌及其優(yōu)勢比較
晶體管與場效應(yīng)管的區(qū)別 晶體管的封裝類型及其特點
晶體管的輸出特性是什么
CMOS晶體管的尺寸規(guī)則
NMOS晶體管和PMOS晶體管的區(qū)別
GaN晶體管和SiC晶體管有什么不同
GaN晶體管的基本結(jié)構(gòu)和性能優(yōu)勢
芯片晶體管的深度和寬度有關(guān)系嗎
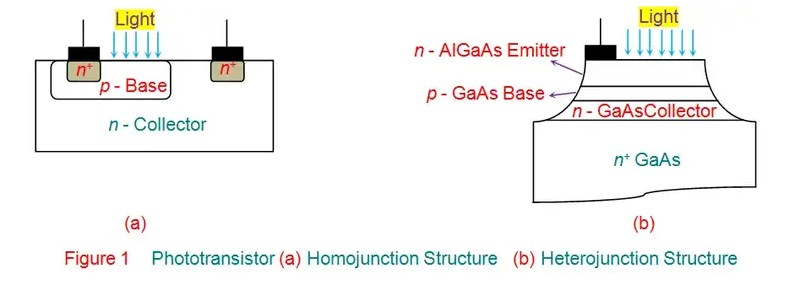
什么是光電晶體管?光電晶體管的工作原理和結(jié)構(gòu)
晶體管測試儀的主要作用
蘋果M3芯片有多少晶體管組成
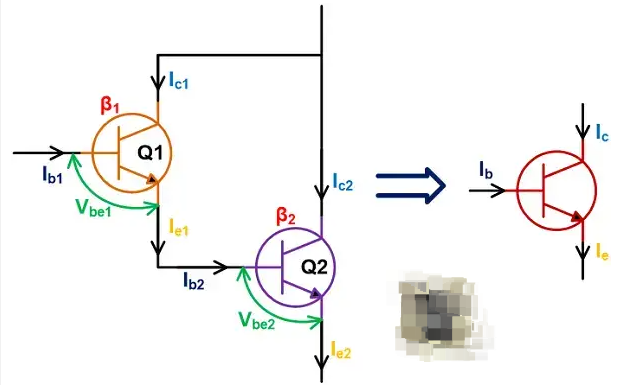
什么是達林頓晶體管?達林頓晶體管的基本電路
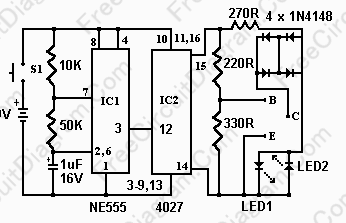
晶體管測試儀電路圖分享





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論