


語義分割指的是將圖像中的每一個像素關聯到一個類別標簽上的過程,這些標簽可能包括一個人、一輛車、一朵花、一件家具等等。在這篇文章中,作者介紹了近來優秀的語義分割思想與解決方案,它可以稱得上是 2019 語義分割指南了。
我們可以認為語義分割是像素級別的圖像分類。例如,在一幅有很多輛車的圖像中,分割模型將會把所有的物體(車)標記為車輛。但是,另一種被稱為實例分割的模型能夠將出現在圖像中的獨立物體標記為獨立的實例。這種分割在被用在統計物體數量的應用中是很有用的(例如,統計商城中的客流量)。
語義分割的一些主要應用是自動駕駛、人機交互、機器人以及照片編輯/創作型工具。例如,語義分割在自動駕駛和機器人領域是十分關鍵的技術,因為對于這些領域的模型來說,理解它們操作環境的上下文是非常重要的。
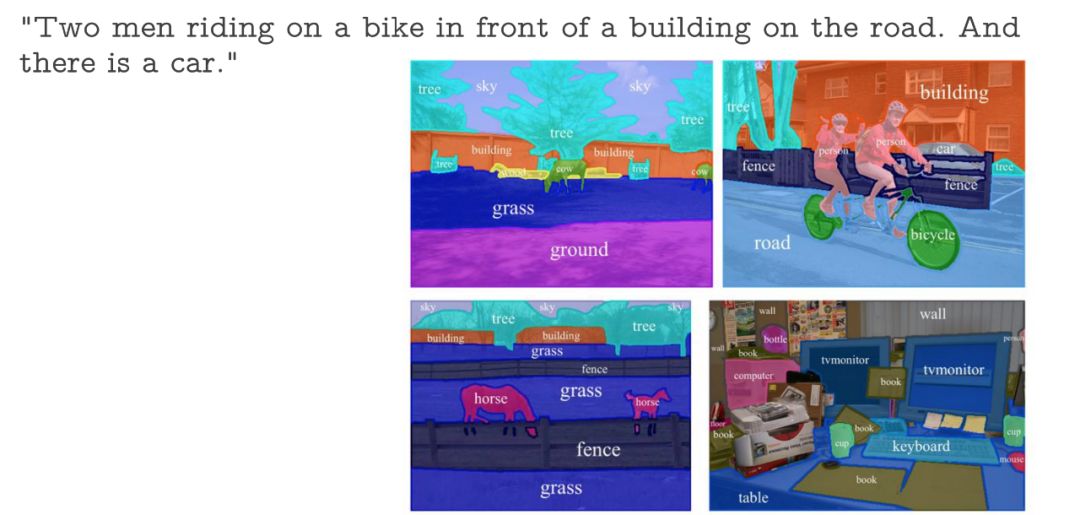
圖片來源: http://www.cs.toronto.edu/~tingwuwang/semantic_segmentation.pdf
接下來,我們將會回顧一些構建語義分割模型的最先進的方法的研究論文,它們分別是:
Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
Fully Convolutional Networks for Semantic Segmentation
U-Net: Convolutional Networks for Biomedical Image Segmentation
The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
Multi-Scale Context Aggregation by Dilated Convolutions
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Rethinking Atrous Convolution for Semantic Image Segmentation
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation
Improving Semantic Segmentation via Video Propagation and Label Relaxation
Gated-SCNN: Gated Shape CNNs for Semantic Segmentation
1. Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation (ICCV, 2015)
這篇論文提出了一個解決方法,主要面對處理深度卷積網絡中的弱標簽數據,以及具有良好標簽和未被合適標記得數據的結合時的挑戰。在這篇論文結合了深度卷積網絡和全連接條件隨機場。
論文地址:https://arxiv.org/pdf/1502.02734.pdf
在 PASCAL VOC 的分割基準測試中,這個模型高于 70% 的交并比(IOU)
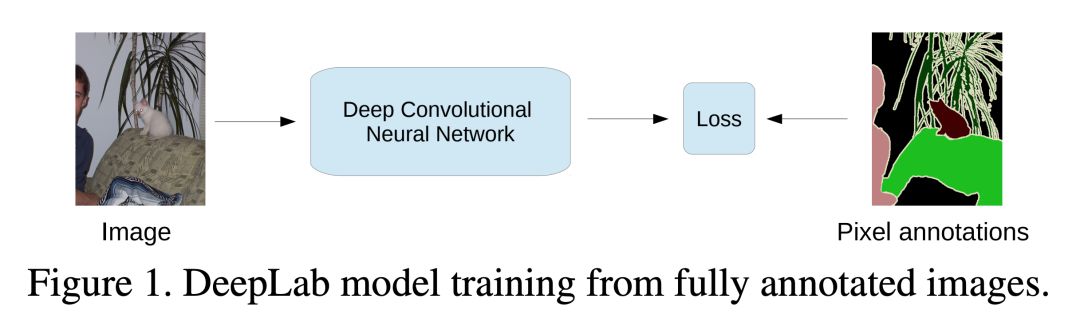
這篇論文的主要貢獻如下:
為邊界框或圖像級別的訓練引入 EM 算法,這可以用在弱監督和半監督環境中。
證明了弱標注和強標注的結合能夠提升性能。在合并了 MS-COCO 數據集和 PASCAL 數據集的標注之后,論文的作者在 PASCAL VOC 2012 上達到了 73.9% 的交并比性能。
證明了他們的方法通過合并了少量的像素級別標注和大量的邊界框標注(或者圖像級別的標注)實現了更好的性能。

2. Fully Convolutional Networks for Semantic Segmentation (PAMI, 2016)
這篇論文提出的模型在 PASCAL VOC 2012 數據集上實現了 67.2% 的平均 IoU。全連接網絡以任意大小的圖像為輸入,然后生成與之對應的空間維度。在這個模型中,ILSVRC 中的分類器被丟在了全連接網絡中,并且使用逐像素的損失和上采樣模塊做了針對稠密預測的增強。針對分割的訓練是通過微調來實現的,這個過程通過在整個網絡上的反向傳播完成。
論文地址:https://arxiv.org/pdf/1605.06211.pdf
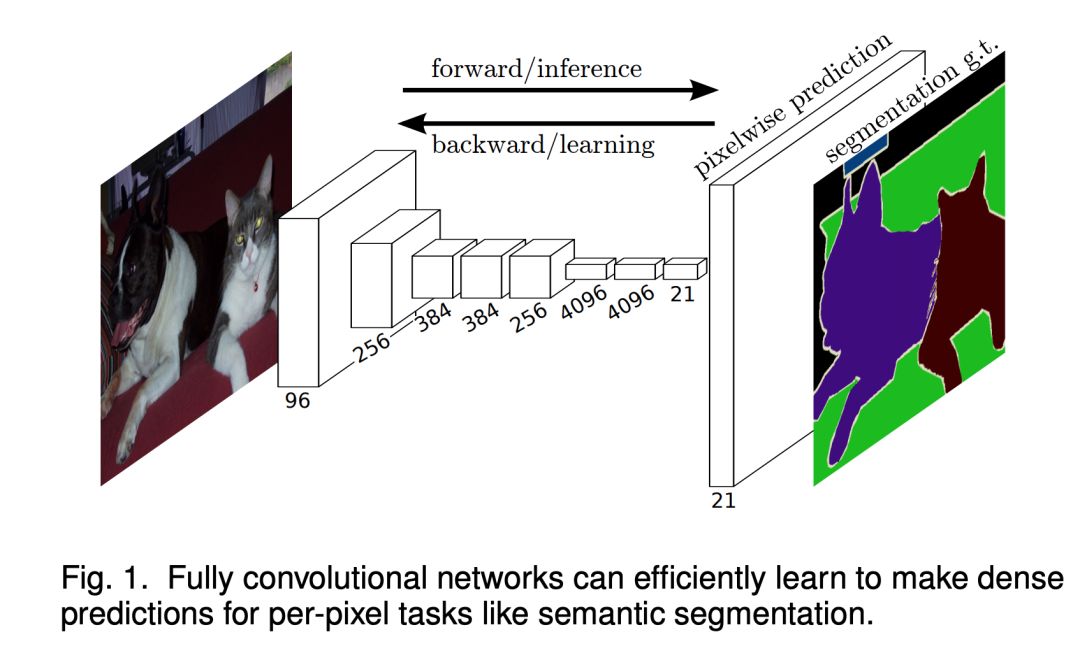
3. U-Net: Convolutional Networks for Biomedical Image Segmentation (MICCAI, 2015)
在生物醫學圖像處理中,得到圖像中的每一個細胞的類別標簽是非常關鍵的。生物醫學中最大的挑戰就是用于訓練的圖像是不容易獲取的,數據量也不會很大。U-Net 是非常著名的解決方案,它在全連接卷積層上構建模型,對其做了修改使得它能夠在少量的訓練圖像數據上運行,得到了更加精確的分割。
論文地址:https://arxiv.org/pdf/1505.04597.pdf
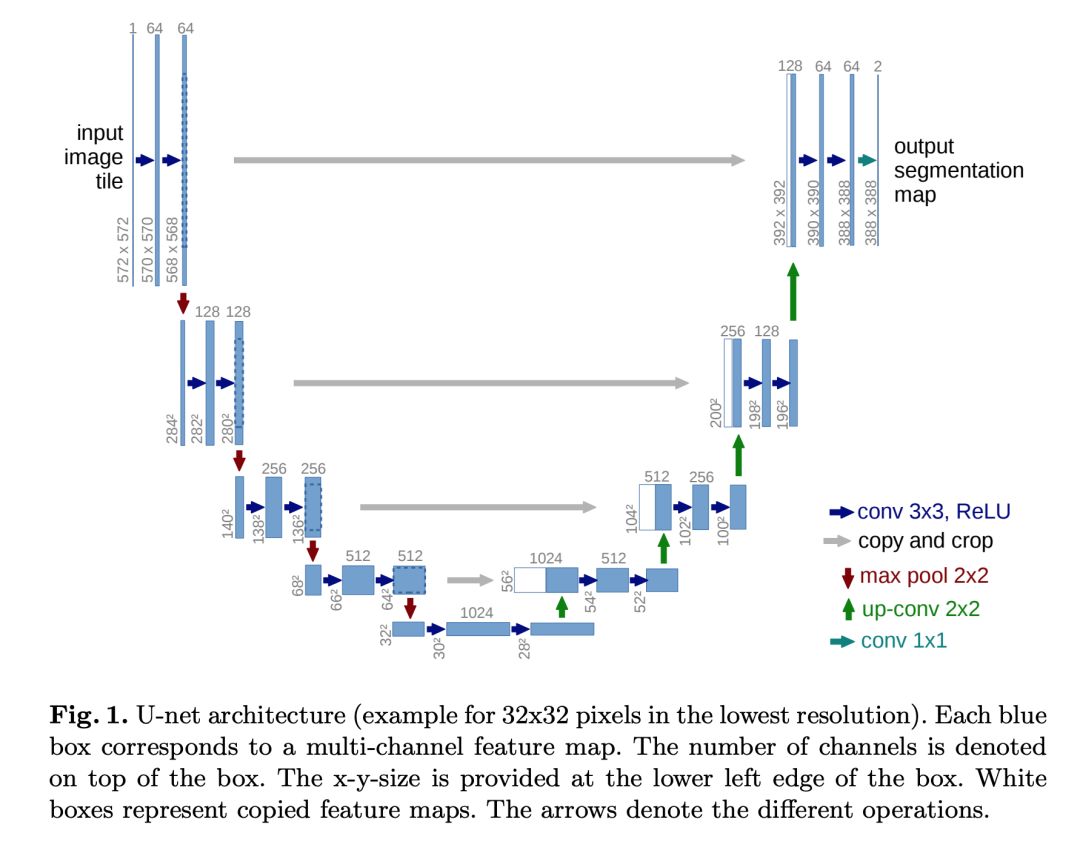
由于少量訓練數據是可以獲取的,所以這個模型通過在可獲得的數據上應用靈活的變形來使用數據增強。正如上面的圖 1 所描述的,模型的網絡結構由左邊的收縮路徑和右邊的擴張路徑組成。
收縮路徑由 2 個 3X3 的卷積組成,每個卷積后面跟的都是 ReLU 激活函數和一個進行下采樣的 2X2 最大池化運算。擴張路徑階段包括一個特征通道的上采樣。后面跟的是 2X2 的轉置卷積,它能夠將特征通道數目減半,同時加大特征圖。最后一層是 1X1 的卷積,用這種卷積來組成的特征向量映射到需要的類別數量上。
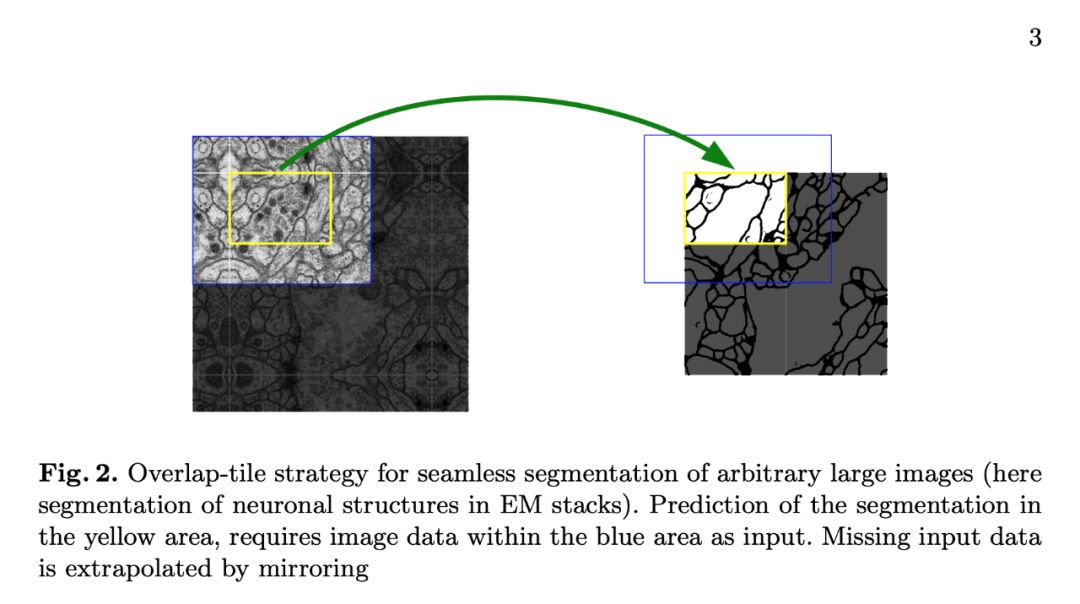
在這個模型中,訓練是通過輸入的圖像、它們的分割圖以及隨機梯度下降來完成的。數據增強被用來教網絡學會在使用很少的訓練數據時所必需的魯棒性和不變性。這個模型在其中的一個實驗中實現了 92% 的 mIoU。

4. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation (2017)
DenseNets 背后的思想是讓每一層以一種前饋的方式與所有層相連接,能夠讓網絡更容易訓練、更加準確。
模型架構是基于包含下采樣和上采樣路徑的密集塊構建的。下采樣路徑包含 2 個 Transitions Down (TD),而上采樣包含 2 個 Transitions Up (TU)。圓圈和箭頭代表網絡中的連接模式。
論文地址:https://arxiv.org/pdf/1611.09326.pdf
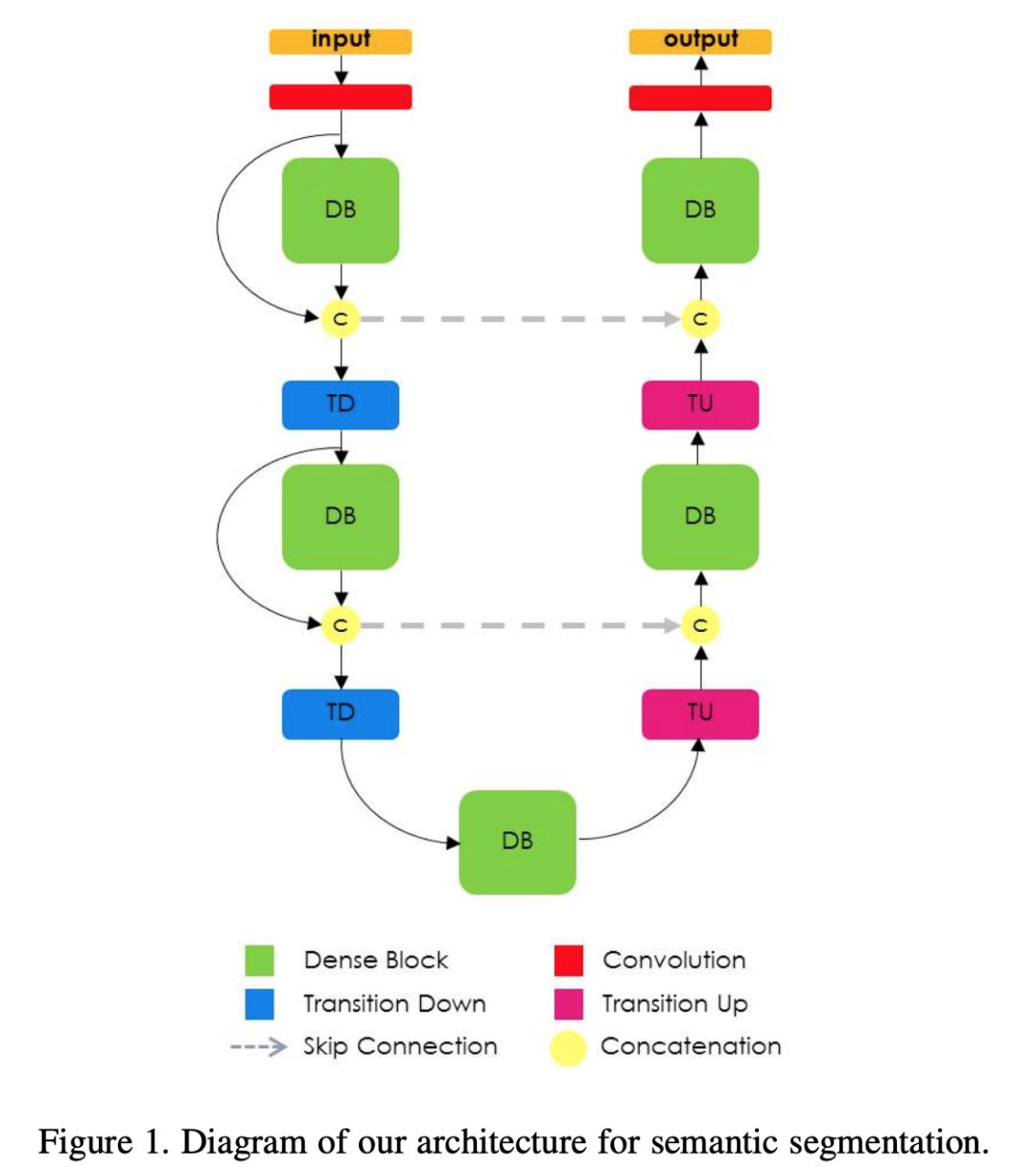
這篇論文的主要貢獻是:
針對語義分割用途,將 DenseNet 的結構擴展到了全卷積網絡。
提出在密集網絡中進行上采樣路徑,這要比其他的上采樣路徑性能更好。
證明網絡能夠在標準的基準測試中產生最好的結果。
這個模型在 CamVid 數據集中實現 88% 的全局準確率。
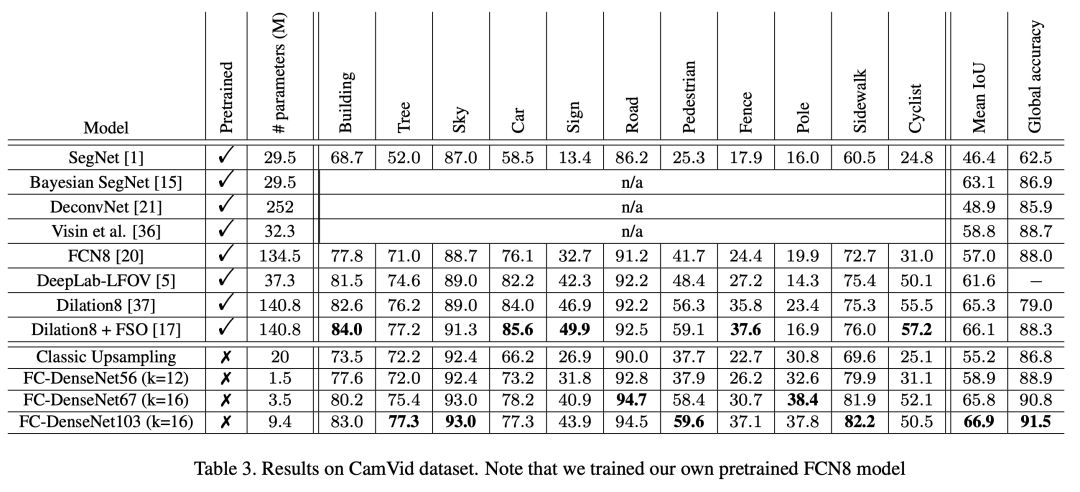

5. Multi-Scale Context Aggregation by Dilated Convolutions (ICLR, 2016)
這篇論文提出了一個卷積網絡模塊,能夠在不損失分辨率的情況下混合多尺度的上下文信息。然后這個模塊能夠以任意的分辨率被嵌入到現有的結構中,它主要基于空洞卷積。
論文地址:https://arxiv.org/abs/1511.07122
這個模塊在 Pascal VOC 2012 數據集上做了測試。結果證明,向現存的語義分割結構中加入上下文模塊能夠提升準確率。
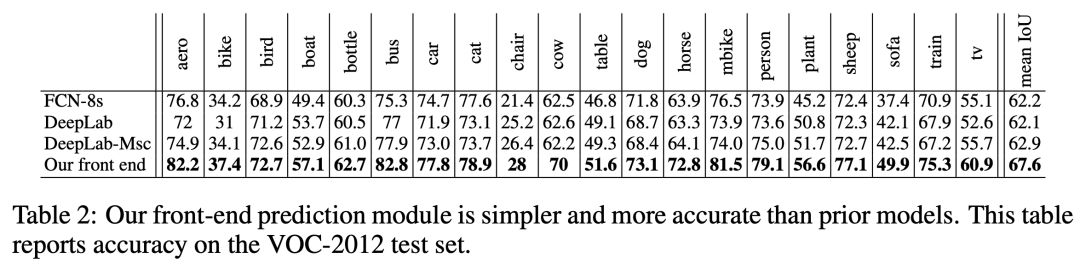
在實驗中訓練的前端模塊在 VOC-2012 驗證集上達到了 69.8% 的平均交并比(mIoU),在測試集上達到了 71.3% 的平均交并比。這個模塊對不同對象的預測準確率如下所示:
6. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (TPAMI, 2017)
在這篇論文中,作者對語義分割任務中做出了下面的貢獻:
為密集預測任務使用具有上采樣的卷積
在多尺度上為分割對象進行帶洞空間金字塔池化(ASPP)
通過使用 DCNNs 提升了目標邊界的定位
論文地址:https://arxiv.org/abs/1606.00915
這篇論文提出的 DeepLab 系統在 PASCAL VOC-2012 圖像語義分割上實現了 79.7% 的平均交并比(mIoU)。

這篇論文解決了語義分割的主要挑戰,包括:
由重復的最大池化和下采樣導致的特征分辨率降低
檢測多尺度目標
因為以目標為中心的分類器需要對空間變換具有不變性,因而降低了由 DCNN 的不變性導致的定位準確率。
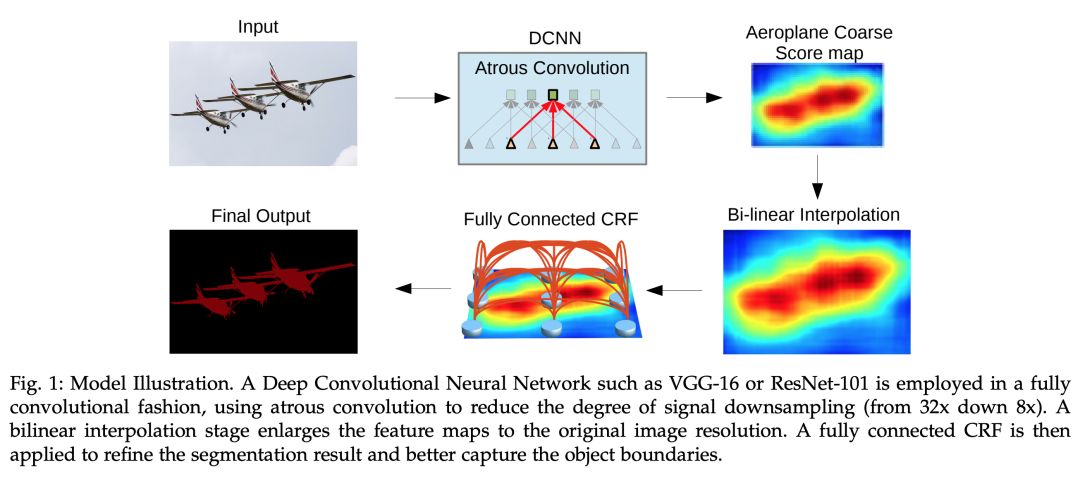
帶洞卷積(Atrous convolution)有兩個用途,要么通過插入零值對濾波器進行上采樣,要么對輸入特征圖進行稀疏采樣。第二個方法需要通過等于帶洞卷積率 r 的因子來對輸入特征圖進行子采樣,然后對它進行去交錯(deinterlacing),使其變成 r^2 的低分辨率圖,每一個 r×r 區域都有一個可能遷移。在此之后,一個標準的卷積被應用在中間的特征圖上,并將其與原始圖像分辨率進行交錯。

7. Rethinking Atrous Convolution for Semantic Image Segmentation (2017)
這篇論文解決了使用 DCNN 進行語義分割所面臨的兩個挑戰(之前提到過):當使用連續的池化操作時會出現特征分辨率的降低,以及多尺度目標的存在。
論文地址:https://arxiv.org/pdf/1706.05587.pdf
為了解決第二個問題,本文提出了帶洞卷積(atrous convolution),也被稱作 dilated convolution。我們能使用帶洞卷積增大感受野,因此能夠包含多尺度上下文,這樣就解決了第二個問題。

在沒有密集條件隨機場(DenseCRF)的情況下,論文的 DeepLabv3 版本在 PASCAL VOC 2012 測試集上實現了 85.7% 的性能。

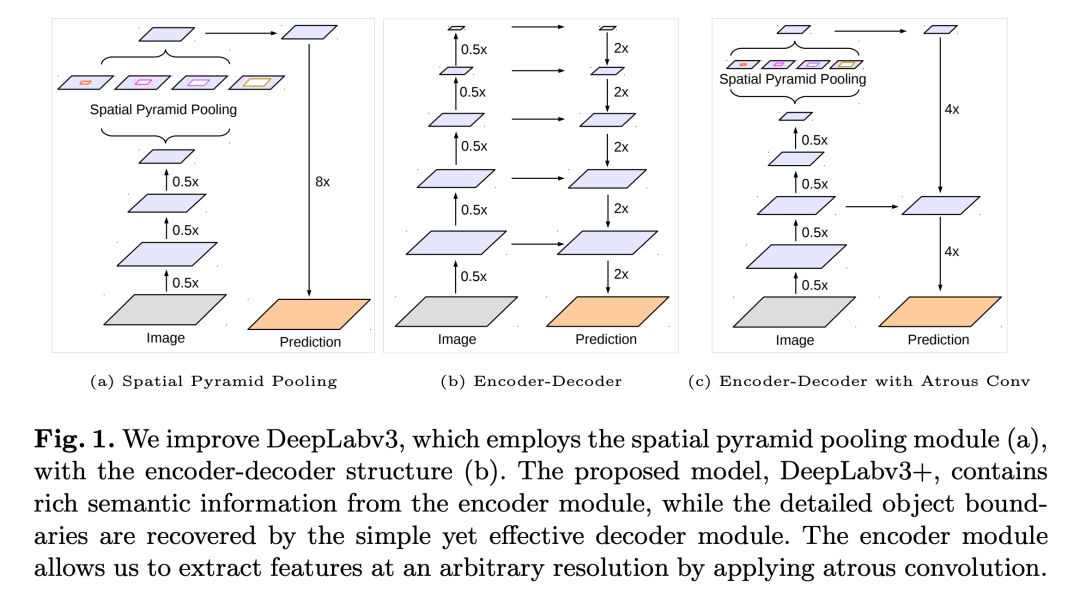
8. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (ECCV, 2018)
這篇論文的方法「DeepLabv3+」在 PASCAL VOC 2012 數據集和 Cityscapes 數據集上分別實現了 89.0% 和 82.1% 的性能,而且沒有做任何后處理。這個模型在 DeepLabv3 的基礎上增加一個簡單的解碼模塊,從而改善了分割結果。
論文地址:https://arxiv.org/pdf/1802.02611v3.pdf

這篇論文實現了為語義分割使用兩種帶空間金字塔池化的神經網絡。一個通過以不同的分辨率池化特征捕捉上下文信息,另一個則希望獲取明確的目標邊界。
9. FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation (2019)
這篇論文提出了一種被稱作聯合金字塔上采樣(Joint Pyramid Upsampling/JPU)的聯合上采樣模塊來代替消耗大量時間和內存的帶洞卷積。它通過把抽取高分辨率圖的方法形式化,并構建成一個上采樣問題來取得很好的效果。
論文地址:https://arxiv.org/pdf/1903.11816v1.pdf
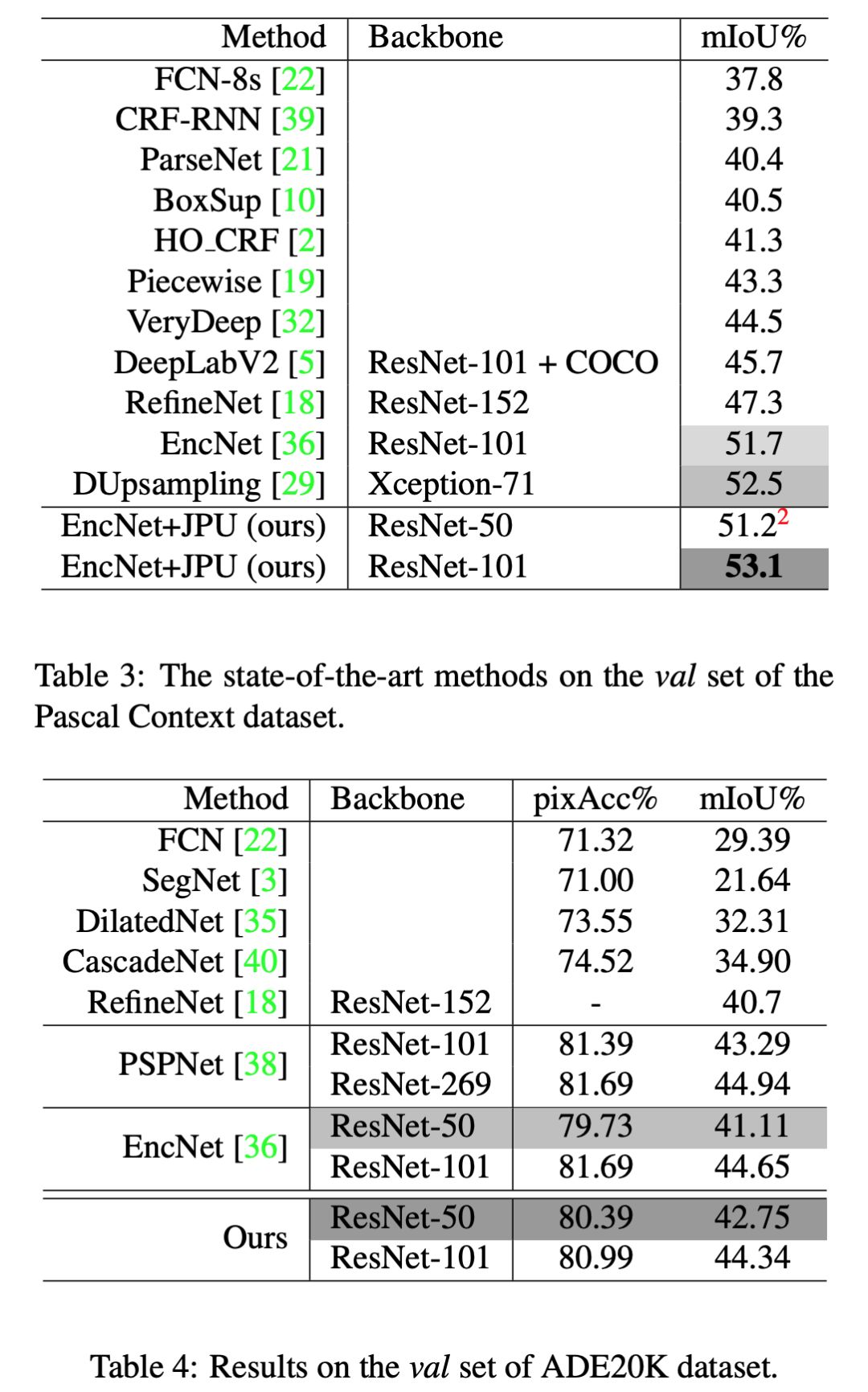
此方法在 Pascal Context 數據集上實現了 53.13% 的 mIoU,并且具有三倍的運行速度。
該方法以全卷積網絡(FCN)作為主體架構,同時應用 JPU 對低分辨率的最終特征圖進行上采樣,得到了高分辨率的特征圖。使用 JPU 代替帶洞卷積并不會造成任何性能損失。

聯合采樣使用低分辨率的目標圖像和高分辨率的指導圖像。然后通過遷移指導圖像的結構和細節生成高分辨率的目標圖像。
10. Improving Semantic Segmentation via Video Propagation and Label Relaxation (CVPR, 2019)
這篇論文提出了基于視頻的方法來增強數據集,它通過合成新的訓練樣本來達到這一效果,并且該方法還能提升語義分割網絡的準確率。本文探討了視頻預測模型預測未來幀的能力,進而繼續預測未來的標簽。
論文地址:https://arxiv.org/pdf/1812.01593v3.pdf
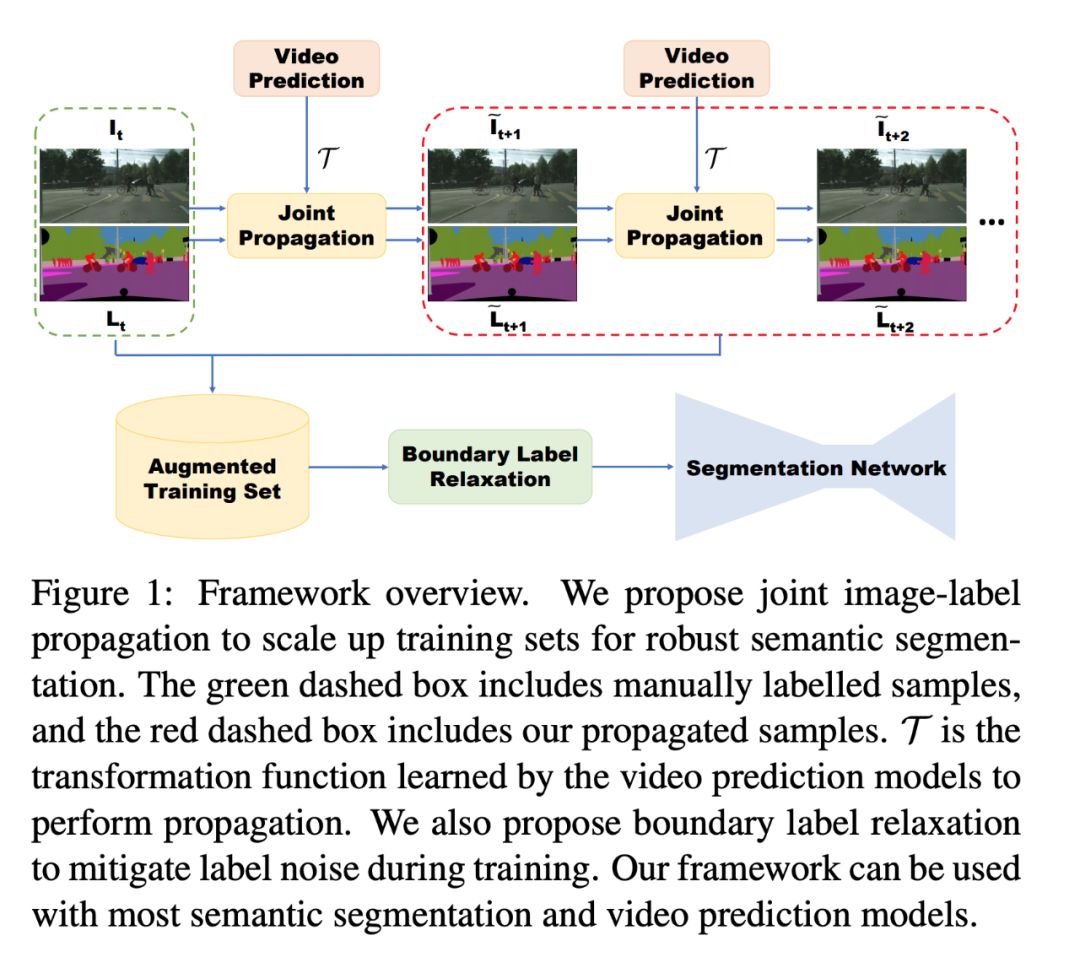
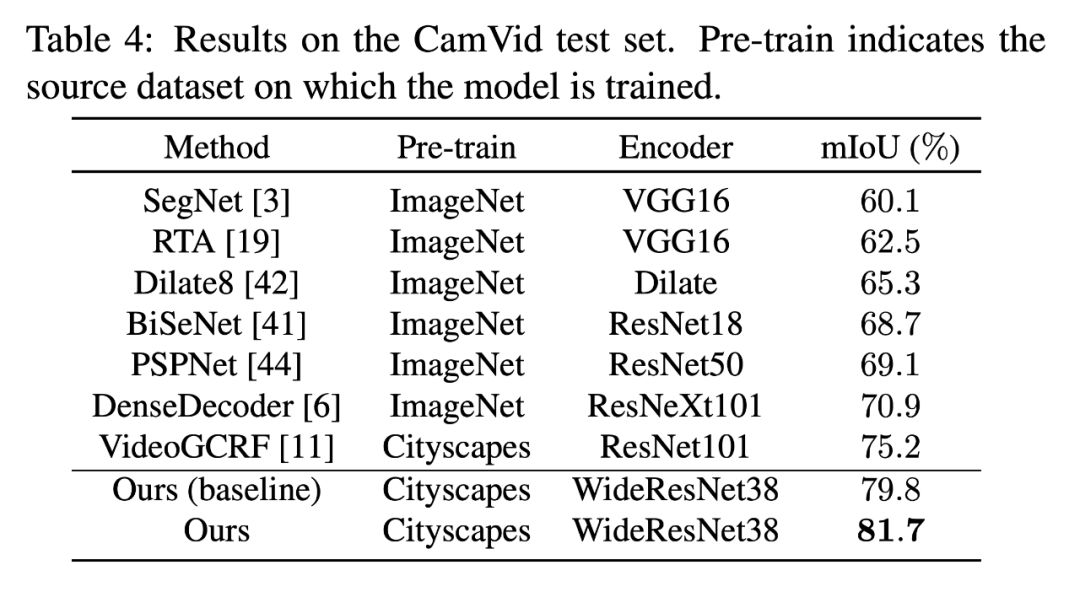
這篇論文證明了用合成數據訓練語義分割網絡能夠帶來預測準確率的提升。論文提出的方法在 Cityscape 上達到了 8.5% 的 mIoU,在 CamVid 上達到了 82.9% 的 mIoU。
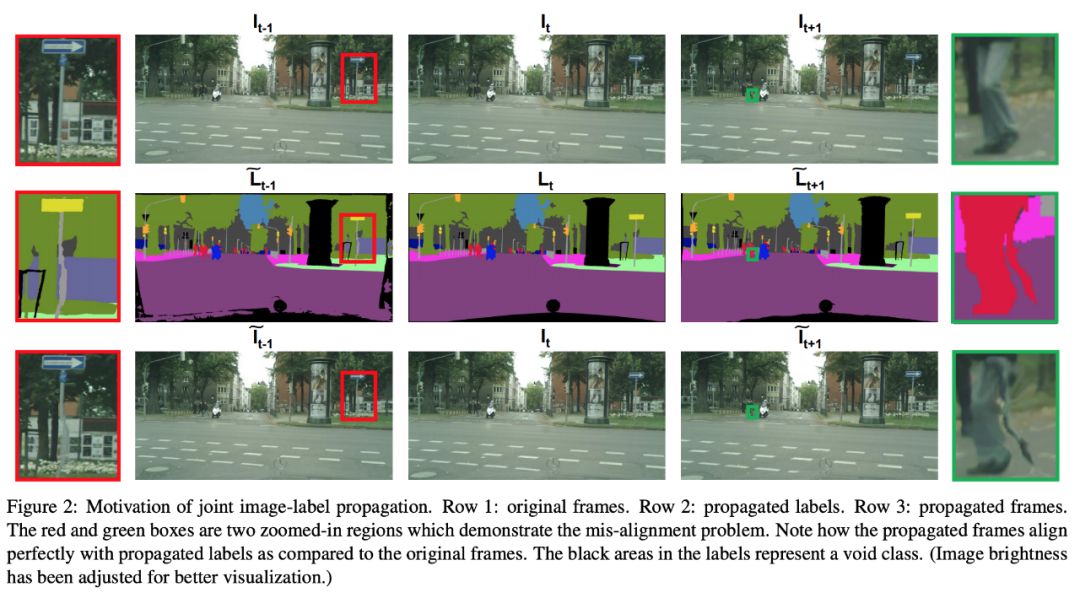
論文提出了兩種預測未來標簽的方法:
Label Propagation (標簽傳播,LP):通過將原始的未來幀與傳播來的標簽配對來創建新的訓練樣本。
Joint image-label Propagation (聯合圖像標簽傳播,JP):通過配對對應的傳播圖像與傳播標簽來創建新的訓練樣本。
這篇論文有 3 個主要貢獻:利用視頻預測模型將標簽傳播到當前的鄰幀,引入聯合圖像標簽傳播(JP)來處理偏移問題,通過最大化邊界上分類的聯合概率來松弛 one-hot 標簽訓練。
11. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation (2019)
這篇論文是語義分割領域最新的成果(2019.07),作者提出了一個雙流 CNN 結構。在這個結構中,目標的形狀信息通過一個獨立的分支來處理,該形狀流僅僅處理邊界相關的信息。這是由模型的門卷控積層(GCL)和局部監督來強制實現的。
論文地址:https://arxiv.org/pdf/1907.05740.pdf

在用 Cityscapes 基準測試中,這個模型的 mIoU 比 DeepLab-v3 高出 1.5%,F-boundary 得分比 DeepLab-v3 高 4%。在更小的目標上,該模型能夠實現 7% 的 IoU 提升。下表展示了 Gated-SCNN 與其他模型的性能對比。

以上就是近來語義分割的主要進展,隨著模型和數據的進一步提升,語義分割的速度越來越快、準確率越來越高,也許以后它能應用到各種現實生活場景中。
-
人機交互
+關注
關注
12文章
1252瀏覽量
56658 -
圖像
+關注
關注
2文章
1094瀏覽量
41407 -
語義
+關注
關注
0文章
21瀏覽量
8744
原文標題:9102年了,語義分割的入坑指南和最新進展都是什么樣的
文章出處:【微信號:cas-ciomp,微信公眾號:中科院長春光機所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

樹莓派發布了迄今為止最優秀的電源解決方案!


海康威視再獲文旅部優秀解決方案殊榮
海康威視文旅板塊第二次獲評文化和旅游部部級優秀解決方案
芯訊通榮獲智能模組優秀解決方案獎
SparseViT:以非語義為中心、參數高效的稀疏化視覺Transformer

中科曙光南京研究院方案入選江蘇省信息技術創新優秀解決方案
中科曙光入選2024年江蘇省信息技術應用創新優秀解決方案名單
利用VLM和MLLMs實現SLAM語義增強

機智云入選廣州市“人工智能+”優秀解決方案冊
語義分割25種損失函數綜述和展望

畫面分割器怎么調試
喜報 物通博聯入選2024年廈門市優秀物聯網產品和應用方案






 工商網監
工商網監

評論