


一、算法介紹
排序算法(Sorting algorithm)是計算機科學最古老、最基本的課題之一。要想成為合格的程序員,就必須理解和掌握各種排序算法。其中”快速排序”(Quicksort)使用得最廣泛,速度也較快。它是圖靈獎得主C. A. R. Hoare(托尼·霍爾)于1960時提出來的。
二、算法原理
快排的實現方式多種多樣,豬哥給大家寫一種容易理解的:分治+迭代,只需要三步:
在數列之中,選擇一個元素作為”基準”(pivot),或者叫比較值。
數列中所有元素都和這個基準值進行比較,如果比基準值小就移到基準值的左邊,如果比基準值大就移到基準值的右邊
以基準值左右兩邊的子列作為新數列,不斷重復第一步和第二步,直到所有子集只剩下一個元素為止。
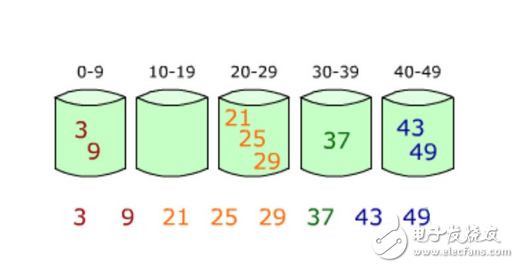
舉個例子,假設我現在有一個數列需要使用快排來排序:{3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48},我們來看看使用快排的詳細步驟:
選取中間的26作為基準值(基準值可以隨便選)
數列從第一個元素3開始和基準值26進行比較,小于基準值,那么將它放入左邊的分區中,第二個元素44比基準值26大,把它放入右邊的分區中,依次類推就得到下圖中的第二列。
然后依次對左右兩個分區進行再分區,得到下圖中的第三列,依次往下,直到最后只有一個元素
分解完成再一層一層返回,返回規則是:左邊分區+基準值+右邊分區
三、代碼實現
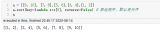
quick_sort = lambda array: array if len(array) 《= 1 else quick_sort([item for item in array[1:] if item 《= array[0]]) + [array[0]] + quick_sort([item for item in array[1:] if item 》 array[0]])
是不是很簡潔很秀,如果再有面試官讓你手寫一個快排,你就把這行寫上去吧,面試官見了都要喊你秀兒,哈哈。
在你感嘆python炫酷吊炸天的同時,你因該考慮到代碼的可讀性問題,lambda函數設計是為了代碼的簡潔性,但是濫用的話會導致可讀性變得極差,而且現在pep8代碼規范中也不建議使用lambda函數了,建議使用關鍵字def去定義一個函數,所以下面豬哥給大家寫一段符合pythonic風格的快排代碼
def quick_sort(arr): “”“快速排序”“” if len(arr) 《 2: return arr # 選取基準,隨便選哪個都可以,選中間的便于理解 mid = arr[len(arr) // 2] # 定義基準值左右兩個數列 left, right = [], [] # 從原始數組中移除基準值 arr.remove(mid) for item in arr: # 大于基準值放右邊 if item 》= mid: right.append(item) else: # 小于基準值放左邊 left.append(item) # 使用迭代進行比較 return quick_sort(left) + [mid] + quick_sort(right)
四、算法分析
穩定性:快排是一種不穩定排序,比如基準值的前后都存在與基準值相同的元素,那么相同值就會被放在一邊,這樣就打亂了之前的相對順序
比較性:因為排序時元素之間需要比較,所以是比較排序
時間復雜度:快排的時間復雜度為O(nlogn)
空間復雜度:排序時需要另外申請空間,并且隨著數列規模增大而增大,其復雜度為:O(nlogn)
歸并排序與快排 :歸并排序與快排兩種排序思想都是分而治之,但是它們分解和合并的策略不一樣:歸并是從中間直接將數列分成兩個,而快排是比較后將小的放左邊大的放右邊,所以在合并的時候歸并排序還是需要將兩個數列重新再次排序,而快排則是直接合并不再需要排序,所以快排比歸并排序更高效一些,可以從示意圖中比較二者之間的區別。
五、快排優化
快速排序有一個缺點就是對于小規模的數據集性能不是很好。可能有人認為可以忽略這個缺點不計,因為大多數排序都只要考慮大規模的適應性就行了。但是快速排序算法使用了分治技術,最終來說大的數據集都要分為小的數據集來進行處理,所以快排分解到最后幾層性能不是很好,所以我們就可以使用揚長避短的策略去優化快排:
先使用快排對數據集進行排序,此時的數據集已經達到了基本有序的狀態
然后當分區的規模達到一定小時,便停止快速排序算法,而是改用插入排序,因為我們之前講過插入排序在對基本有序的數據集排序有著接近線性的復雜度,性能比較好。
這一改進被證明比持續使用快速排序算法要有效的多,下期豬哥就會帶大家實際測試這幾種算法的性能。
六、模擬面試
面試官:你了解快排嗎?
你:略知一二
面試官:那你講講快排的算法思想吧
你:快排基本思想是:從數據集中選取一個基準,然后讓數據集的每個元素和基準值比較,小于基準值的元素放入左邊分區大于基準值的元素放入右邊分區,最后以左右兩邊分區為新的數據集進行遞歸分區,直到只剩一個元素。
面試官:快排有什么優點,有什么缺點?
你:分治思想的排序在處理大數據集量時效果比較好,小數據集性能差些。
面試官:那該如何優化?
你:對大規模數據集進行快排,當分區的規模達到一定小時改用插入排序,插入排序在小數據規模時排序性能較好。
面試官:那你能手寫一個快排嗎?
你:
quick_sort = lambda array: array if len(array) 《= 1 else quick_sort([item for item in array[1:] if item 《= array[0]]) + [array[0]] + quick_sort([item for item in array[1:] if item 》 array[0]])
-
排序算法
+關注
關注
0文章
53瀏覽量
10256 -
python
+關注
關注
56文章
4828瀏覽量
86967
原文標題:Python一行代碼實現快速排序
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
matlab實現快速排序法(原創)
matlab快速排序算法實現
快速學習Python的技巧
C#實現快速排序法
快速排序是一種交換排序



C語言排序中快速排序的技巧

php版冒泡排序是如何實現的?






 工商網監
工商網監

評論