") 智能體如何應(yīng)對訓(xùn)練中故意碰瓷兒的“弱”對手呢?
智能體如何應(yīng)對訓(xùn)練中故意碰瓷兒的“弱”對手呢?
人們通常會派出最強大的選手和場景訓(xùn)練人工智能,但是,智能體如何應(yīng)對訓(xùn)練中故意碰瓷兒的“弱”對手呢?
來看看下邊的兩個場景:兩個AI智能體正在“訓(xùn)練場“進行一場激烈的足球賽,一個守門、一個射門。當守門員忽然自己摔倒,攻方?jīng)]有選擇乘勝追擊,也忽然不知所措了起來。
在相撲的規(guī)則下也一樣,當其中一個隊員開始不按套路出牌時,另一個對手也亂作一團,雙方立刻開始毫無規(guī)則扭打在一起。
這樣“人工智障”的場景可不是隨意配置的游戲,而是一項對AI對抗訓(xùn)練的研究。
我們知道,通常情況下,智能體都是通過相互對抗來訓(xùn)練的,無論是下圍棋的阿法狗還是玩星際爭霸的AlphaStar,都是通過海量的對局來訓(xùn)練自己的模型,從而探索出獲勝之道。
但是試想一下,如果給阿法狗的訓(xùn)練數(shù)據(jù)都是圍棋小白亂下的對局,給AlphaStar提供的是小學(xué)生局,結(jié)果會是如何?
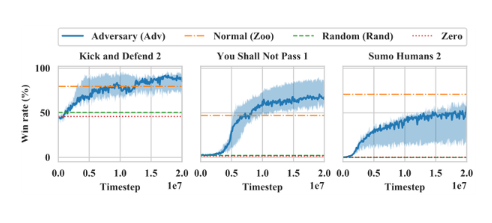
近期,來自伯克利的研究人員就進行了這樣的實驗。紅色機器人與已經(jīng)是專家級別的藍色機器人進行對抗訓(xùn)練,紅色機器人采取一定的對抗策略攻擊藍色機器人進行的深度學(xué)習(xí)。這項研究的論文作者也在NIPS大會上對該研究進行了展示。

論文鏈接:
https://arxiv.org/pdf/1905.10615.pdf
在實驗中,紅色機器人為了不讓藍色機器人繼續(xù)從對抗中學(xué)習(xí),沒有按照應(yīng)有的方式玩游戲,而是開始“亂舞”起來,結(jié)果,藍色機器人開始玩得很糟糕,像喝醉了的海盜一樣來回搖晃,輸?shù)舻挠螒驍?shù)量是正常情況下的兩倍。
研究發(fā)現(xiàn),在采取對抗性政策的對局中,獲勝不是努力成為一般意義上的強者,而是采取迷惑對手的行動。研究人員通過對對手行為的定性觀察來驗證這一點,并發(fā)現(xiàn)當被欺騙的AI在對對手視而不見時,其表現(xiàn)會有所改善。
我們都知道,讓人工智能變得更聰明的一個方法是讓它從環(huán)境中學(xué)習(xí),例如,未來的自動駕駛可能比人類更善于識別街道標志和避開行人,因為它們可以通過海量的視頻獲得更多的經(jīng)驗。
但是如果有人利用這一方式進行研究中所示的“對抗性攻擊” ——通過巧妙而精確地修改圖像,那么你就可以愚弄人工智能,讓它對圖像產(chǎn)生錯誤的理解。例如,在一個停車標志上貼上幾個貼紙可能被視為限速標志,同時這項新的研究也表明,人工智能不僅會被愚弄,看到不該看到的東西,還會以不該看到的方式行事。
這給基于深度學(xué)習(xí)的人工智能應(yīng)用敲響了一個警鐘,這種對抗性的攻擊可能會給自動駕駛、金融交易或產(chǎn)品推薦系統(tǒng)帶來現(xiàn)實問題。
論文指出,在這些安全關(guān)鍵型的系統(tǒng)中,像這樣的攻擊最受關(guān)注,標準做法是驗證模型,然后凍結(jié)它,以確保部署的模型不會因再訓(xùn)練而產(chǎn)生任何新問題。
因此,這項研究中的攻擊行為也真實地反映了在現(xiàn)實環(huán)境中,例如在自動駕駛車輛中看到的深度學(xué)習(xí)訓(xùn)練策略,此外,即使被攻擊目標使用持續(xù)學(xué)習(xí),也會有針對固定攻擊目標進行訓(xùn)練的策略,攻擊者可以對目標使用模擬學(xué)習(xí)來生成攻擊模型。
或者,在自動駕駛車輛,攻擊者可以通過購買系統(tǒng)的副本并定期在工廠重置它,一旦針對目標訓(xùn)練出了敵對策略,攻擊者就可以將此策略傳輸?shù)侥繕耍⒗盟钡焦舫晒橹埂?/p>
研究也對今后的工作提出了一些方向:深度學(xué)習(xí)策略容易受到攻擊,這突出了有效防御的必要性,因此在系統(tǒng)激活時可以使用密度模型檢測到可能的對抗性攻擊,在這種情況下,還可以及時退回到保守策略。
-
機器人
+關(guān)注
關(guān)注
211文章
28466瀏覽量
207311 -
智能體
+關(guān)注
關(guān)注
1文章
152瀏覽量
10588 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5504瀏覽量
121222
發(fā)布評論請先 登錄
相關(guān)推薦
《具身智能機器人系統(tǒng)》第7-9章閱讀心得之具身智能機器人與大模型
瓷介電容器失效模式分析方法
瓷介電容器在性能上有哪些主要優(yōu)缺點
華嶺申瓷正式竣工投產(chǎn)!
電磁干擾訓(xùn)練系統(tǒng)原理是什么
海上電磁干擾訓(xùn)練系統(tǒng)
工業(yè)一體機在智能分揀中的應(yīng)用
其利天下技術(shù)·無刷電機弱磁控制是什么?有什么好處·BLDC驅(qū)動方案

什么是電機的弱磁?電機弱磁的可能原因有哪些?
遇到液晶拼接屏幕左右黑屏的問題應(yīng)該怎樣應(yīng)對呢?







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論