 2012年以來AI算法消耗算力的情況
2012年以來AI算法消耗算力的情況
今天OpenAI更新了AI計算量報告,分析了自2012年以來AI算法消耗算力的情況。
根據對實際數據的擬合,OpenAI得出結論:AI計算量每年增長10倍。從AlexNet到AlphaGo Zero,最先進AI模型對計算量的需求已經增長了30萬倍。
英偉達的黃仁勛一直在強調摩爾定律已死,就是沒死也頂不住如此爆炸式的算力需求啊。
至于為何發布AI計算量報告?OpenAI說,是為了用計算量這種可以簡單量化的指標來衡量AI的發展進程,另外兩個因素算法創新和數據難以估計。
每年增長10倍
OpenAI根據這些年的實際數據進行擬合,發現最先進AI模型的計算量每3.4個月翻一番,也就是每年增長10倍,比摩爾定律2年增長一倍快得多。
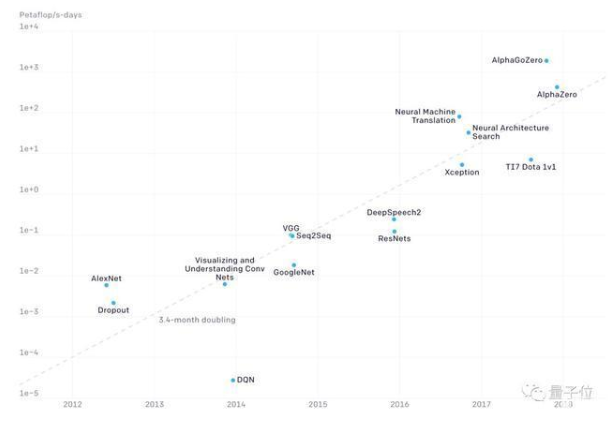
上圖中的縱坐標單位是PetaFLOPS×天(以下簡寫為pfs-day),一個pfs-day是以每秒執行1015次浮點運算的速度計算一天,或者說總共執行大約1020次浮點運算。
需要注意的是,上圖使用的是對數坐標,因此AlphaGoZero比AlexNet的運算量多了5個數量級。
從2012年至今,按照摩爾定律,芯片算力只增長了7倍,而在這7年間AI對算力的需求增長了30萬倍。硬件廠商是否感覺壓力山大?
OpenAI還分析了更早期的數據,從第一個神經網絡感知器(perceptron)誕生到2012年AI技術爆發前夕的狀況。
在之前的幾十年中,AI計算量的增長速度基本和摩爾定律是同步的,2012年成為AI兩個時期的分水嶺。
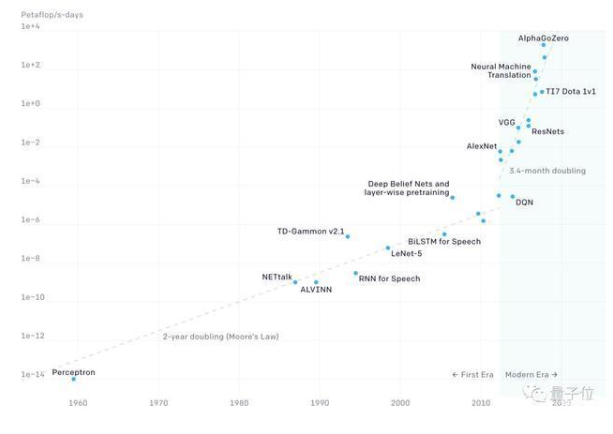
(注:OpenAI原報告引用18個月作為摩爾定律的翻倍時間,之后修正為2年。)
AI硬件的4個時代
對算力的爆炸式需求也催生了專門用于AI運算的硬件,從1959年至今,AI硬件經歷了4個不同的時期。
2012年之前:使用GPU進行機器學習運算并不常見,因此這部分的數據比較難準確估計。
2012年至2014年:在多個GPU上進行訓練的設備并不常見,大多數使用算力為1~2 TFLOPS的1到8個GPU,計算量為0.001~0.1 pfs-day。
2014年至2016年:開始大規模使用10~100個GPU(每個5~10 TFLOPS)進行訓練,總計算量為0.1-10 pfs-day。數據并行的邊際效益遞減,讓更大的訓練量受到限制。
2016年至2017年:更大的算法并行性(更大的batch size、架構搜索和專家迭代)以及專用硬件(TPU和更快的連接),極大地放寬了并行計算的限制。
未來還會高速增長嗎?
OpenAI認為,我們有很多理由相信,AI計算量快速增長的需求還會繼續保持下去。但是我們不必太過擔心算力不夠。
首先,越來越多的公司開發AI專用芯片,這些芯片會在一兩年內大幅提高單位功率或單位價格的算力(FLOPS/W或FLOPS/$)。另一方面并行計算也會成為主流,沒有太強的芯片還可以堆數量。
其次,并行計算也是解決大規模運算的一個有效方法,未來也會有并行算法創新,比如體系結構搜索和大規模并行SGD等。
但是,物理規律限制芯片效率,成本將限制并行計算。
如今訓練一個最大模型需要的硬件購置成本高達幾百萬美元,不是每個企業都可以像英偉達那樣,用512個V100花費10天訓練一個模型的。
-
摩爾定律
+關注
關注
4文章
635瀏覽量
79093 -
AI算法
+關注
關注
0文章
252瀏覽量
12291 -
OpenAI
+關注
關注
9文章
1100瀏覽量
6572
發布評論請先 登錄
相關推薦
青云科技強化AI算力架構,升級產品與服務體系
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
淺析三大算力之異同

大模型時代的算力需求
中科曙光入選2024算力服務產業圖譜及算力服務產品名錄
DPU技術賦能下一代AI算力基礎設施


立足算力,聚焦AI!順網科技全面走進AI智算時代






 工商網監
工商網監
評論