 Python快速入門指南基礎知識詳細說明
Python快速入門指南基礎知識詳細說明
隨著人工智能大火,我們身邊幾乎處處充滿著AL的氣息,就連停車,都是機器人值班了。
可是很多人都不知道人工智能是由什么開發的,各種相關聯的框架都是以Python作為主要語言開發出來的。
Python本身很普通,是所有編程語言中和自然語言或者說偽代碼最像的,更為可貴的是其中一些特殊的庫非常方便和強大,像numpy, scipy, matplotlib。
如果是一名新手想學習編程,一般都是選擇python,因為更容易上手,并且,從Python學起,很快就能運用Python編程的底層邏輯去學習另外的語言,也就是說,學習Python是學習編程的絕佳起點。
接下來小編教大家如何快速入門,節約時間,能夠一邊工作一邊學新知識!
學習基礎知識
掌握元素(列表、字典、元組等)、變量、循環、函數等基礎知識,達到能夠熟練編寫代碼,至少不能出現語法錯誤。
1.交互式解釋器
在命令行窗口執行python后,進入 Python 的交互式解釋器。exit() 或Ctrl + D 組合鍵退出交互式解釋器。
2.命令行腳本
在命令行窗口執行python script-file.py,以執行 Python 腳本文件。
3.指定解釋器
如果在 Python 腳本文件首行輸入#!/usr/bin/env python,那么可以在命令行窗口中執行/path/to/script-file.py以執行該腳本文件。
運算符合集
算術運算符:
比較運算符:
賦值運算符:
成員運算符:
這個階段最重要的就是:學好基礎知識。掌握了基礎之后,便可以開始做項目練習鍛煉編程思維了。
學習爬蟲知識
所謂爬蟲,就是按照一定的規則,自動的從網絡中抓取信息的程序或者腳本。萬維網就像一個巨大的蜘蛛網,我們的爬蟲就是上面的一個蜘蛛,不斷的去抓取我們需要的信息。
基礎的抓取操作:
1、urllib
在Python2.x中我們可以通過urllib 或者urllib2 進行網頁抓取,但是再Python3.x 移除了urllib2。只能通過urllib進行操作
帶參數的urllib
url = 'https://blog.csdn.net/weixin_43499626'
url = url + '?' + key + '=' + value1 + '&' + key2 + '=' + value2
2、requests
requests庫是一個非常實用的HTPP客戶端庫,是抓取操作最常用的一個庫。Requests庫滿足很多需求
常見的反爬有哪些
1、通過user-agent來控制訪問
user-agent能夠使服務器識別出用戶的操作系統及版本、cpu類型、瀏覽器類型和版本。很多網站會設置user-agent白名單,只有在白名單范圍內的請求才能正常訪問。所以在我們的爬蟲代碼中需要設置user-agent偽裝成一個瀏覽器請求。
2、通過IP來限制
當我們用同一個ip多次頻繁訪問服務器時,服務器會檢測到該請求可能是爬蟲操作。因此就不能正常的響應頁面的信息了。
存儲
通過分析網頁內容,獲取到我們想要的數據,我們可以選擇存到文本文件中,亦可以存儲在數據庫中,常用的數據庫有MySql、MongoDB
存儲為json文件
存儲為cvs文件
存儲到Mongo
以上知識雖然只是皮毛,給大家整理了一些知識,不過想要深入了解,還需要自己去學習, 在學習中有迷茫不知如何學習的朋友小編推薦去“蟻小二”,打破傳統學習,每一課程一個小時就搞定,或者關注小編,傳授你們更多python知識!
-
機器人
+關注
關注
211文章
28381瀏覽量
206919 -
人工智能
+關注
關注
1791文章
47193瀏覽量
238268 -
python
+關注
關注
56文章
4792瀏覽量
84630
發布評論請先 登錄
相關推薦

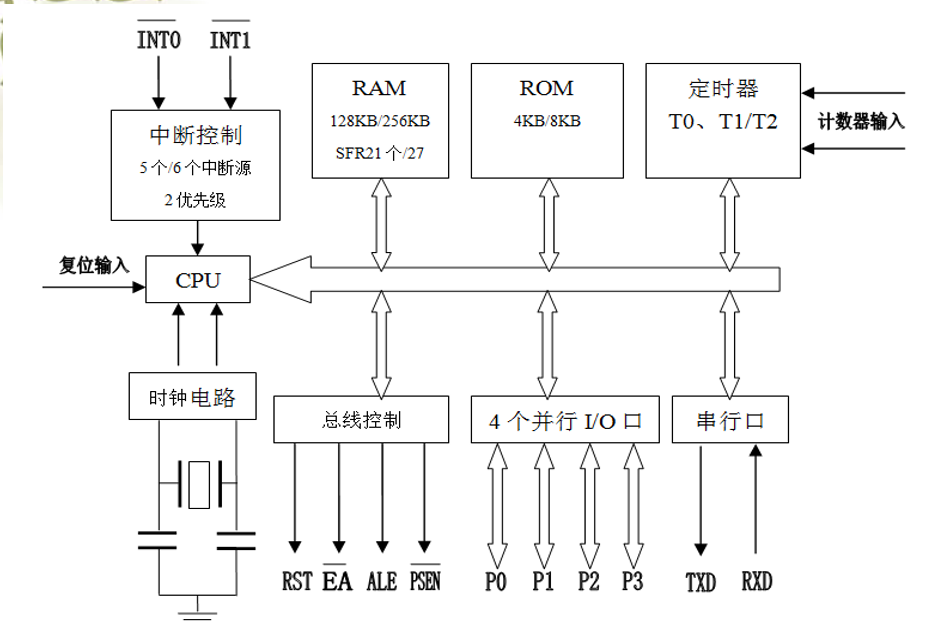
51單片機的結構及工作方式等基礎知識詳細說明

射頻的基礎知識培訓教程詳細說明

被動電子元器件的基礎知識詳細說明









 工商網監
工商網監
評論