") 信息保留的二值神經(jīng)網(wǎng)絡(luò)IR-Net,落地性能和實用性俱佳
信息保留的二值神經(jīng)網(wǎng)絡(luò)IR-Net,落地性能和實用性俱佳
在CVPR 2020上,商湯研究院鏈接與編譯組和北京航空航天大學(xué)劉祥龍老師團隊提出了一種旨在優(yōu)化前后向傳播中信息流的實用、高效的網(wǎng)絡(luò)二值化新算法IR-Net。不同于以往二值神經(jīng)網(wǎng)絡(luò)大多關(guān)注量化誤差方面,本文首次從統(tǒng)一信息的角度研究了二值網(wǎng)絡(luò)的前向和后向傳播過程,為網(wǎng)絡(luò)二值化機制的研究提供了全新視角。同時,該工作首次在ARM設(shè)備上進行了先進二值化算法效率驗證,顯示了IR-Net部署時的優(yōu)異性能和極高的實用性,有助于解決工業(yè)界關(guān)注的神經(jīng)網(wǎng)絡(luò)二值化落地的核心問題。
動機
二值神經(jīng)網(wǎng)絡(luò)因其存儲量小、推理效率高而受到社會的廣泛關(guān)注 [1]。然而與全精度的對應(yīng)方法相比,現(xiàn)有的量化方法的精度仍然存在顯著的下降。
對神經(jīng)網(wǎng)絡(luò)的研究表明,網(wǎng)絡(luò)的多樣性是模型達到高性能的關(guān)鍵[2],保持這種多樣性的關(guān)鍵是:(1) 網(wǎng)絡(luò)在前向傳播過程中能夠攜帶足夠的信息;(2) 反向傳播過程中,精確的梯度為網(wǎng)絡(luò)優(yōu)化提供了正確的信息。二值神經(jīng)網(wǎng)絡(luò)的性能下降主要是由二值化的有限表示能力和離散性造成的,這導(dǎo)致了前向和反向傳播的嚴(yán)重信息損失,模型的多樣性急劇下降。同時,在二值神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程中,離散二值化往往導(dǎo)致梯度不準(zhǔn)確和優(yōu)化方向錯誤。如何解決以上問題,得到更高精度的二值神經(jīng)網(wǎng)絡(luò)?這一問題被研究者們廣泛關(guān)注,本文的動機在于:通過信息保留的思路,設(shè)計更高性能的二值神經(jīng)網(wǎng)絡(luò)。
基于以上動機,本文首次從信息流的角度研究了網(wǎng)絡(luò)二值化,提出了一種新的信息保持網(wǎng)絡(luò)(IR-Net):(1)在前向傳播中引入了一種稱為Libra參數(shù)二值化(Libra-PB)的平衡標(biāo)準(zhǔn)化量化方法,最大化量化參數(shù)的信息熵和最小化量化誤差;(2) 在反向傳播中采用誤差衰減估計器(EDE)來計算梯度,保證訓(xùn)練開始時的充分更新和訓(xùn)練結(jié)束時的精確梯度。
IR-Net提供了一個全新的角度來理解二值神經(jīng)網(wǎng)絡(luò)是如何運行的,并且具有很好的通用性,可以在標(biāo)準(zhǔn)的網(wǎng)絡(luò)訓(xùn)練流程中進行優(yōu)化。作者使用CIFAR-10和ImageNet數(shù)據(jù)集上的圖像分類任務(wù)來評估提出的IR-Net,同時借助開源二值化推理庫daBNN進行了部署效率驗證。
方法設(shè)計
高精度二值神經(jīng)網(wǎng)絡(luò)訓(xùn)練的瓶頸主要在于訓(xùn)練過程中嚴(yán)重的信息損失。前向sign函數(shù)和后向梯度逼近所造成的信息損失嚴(yán)重影響了二值神經(jīng)網(wǎng)絡(luò)的精度。為了解決以上問題,本文提出了一種新的信息保持網(wǎng)絡(luò)(IR-Net)模型,它保留了訓(xùn)練過程中的信息,實現(xiàn)了二值化模型的高精度。
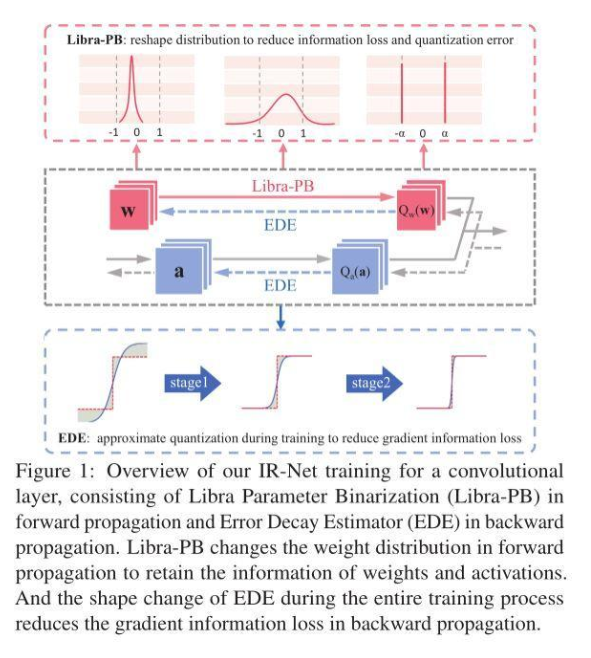
前向傳播中的Libra Parameter Binarization(Libra-PB)
在此之前,絕大多數(shù)網(wǎng)絡(luò)二值化方法試圖減小二值化操作的量化誤差。然而,僅通過最小化量化誤差來獲得一個良好的二值網(wǎng)絡(luò)是不夠的。因此,Libra-PB設(shè)計的關(guān)鍵在于:使用信息熵指標(biāo),最大化二值網(wǎng)絡(luò)前向傳播過程中的信息流。
根據(jù)信息熵的定義,在二值網(wǎng)絡(luò)中,二值參數(shù)Qx(x)的熵可以通過以下公式計算:
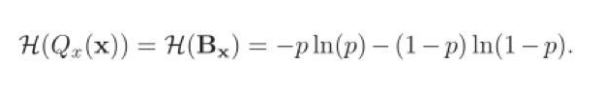
如果單純地追求量化誤差最小化,在極端情況下,量化參數(shù)的信息熵甚至可以接近于零。因此,Libra-PB將量化值的量化誤差和二值參數(shù)的信息熵同時作為優(yōu)化目標(biāo),定義為:
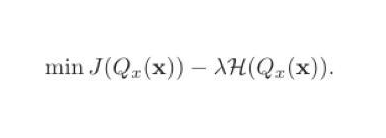
在伯努利分布假設(shè)下,當(dāng)p=0.5時,量化值的信息熵取最大值。
因此,在Libra-PB通過標(biāo)準(zhǔn)化和平衡操作獲得標(biāo)準(zhǔn)化平衡權(quán)重,如圖2所示,在Bernoulli分布下,由Libra-PB量化的參數(shù)具有最大的信息熵。有趣的是,對權(quán)重的簡單變換也可以極大改善前向過程中激活的信息流。因為此時,各層的二值激活值信息熵同樣可以最大化,這意味著特征圖中信息可以被保留。
在以往的二值化方法中,為了使量化誤差減小,幾乎所有方法都會引入浮點尺度因子來從數(shù)值上逼近原始參數(shù),這無疑將高昂的浮點運算引入其中。在Libra-PB中,為了進一步減小量化誤差,同時避免以往二值化方法中代價高昂的浮點運算,Libra-PB引入了整數(shù)移位標(biāo)量s,擴展了二值權(quán)重的表示能力。
因此最終,針對正向傳播的Libra參數(shù)二值化可以表示如下:
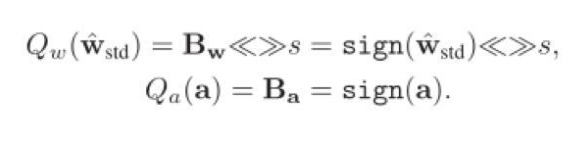
IR-Net的主要運算操作可以表示為:
反向傳播中的Error Decay Estimator(EDE)
由于二值化的不連續(xù)性,梯度的近似對于反向傳播是不可避免的,這種對sign函數(shù)的近似帶來了兩種梯度的信息損失,包括截斷范圍外參數(shù)更新能力下降造成的信息損失,和截斷范圍內(nèi)近似誤差造成的信息損失。為了更好的保留反向傳播中由損失函數(shù)導(dǎo)出的信息,平衡各訓(xùn)練階段對于梯度的要求,EDE引入了一種漸進的兩階段近似梯度方法。
第一階段:保留反向傳播算法的更新能力。將梯度估計函數(shù)的導(dǎo)數(shù)值保持在接近1的水平,然后逐步將截斷值從一個大的數(shù)字降到1。利用這一規(guī)則,近似函數(shù)從接近Identity函數(shù)演化到Clip函數(shù),從而保證了訓(xùn)練早期的更新能力。第二階段:使0附近的參數(shù)被更準(zhǔn)確地更新。將截斷保持為1,并逐漸將導(dǎo)數(shù)曲線演變到階梯函數(shù)的形狀。利用這一規(guī)則,近似函數(shù)從Clip函數(shù)演變到sign函數(shù),從而保證了前向和反向傳播的一致性。
各階段EDE的形狀變化如圖3(c)所示。通過該設(shè)計,EDE減小了前向二值化函數(shù)和后向近似函數(shù)之間的差異,同時所有參數(shù)都能得到合理的更新。

實驗結(jié)果
作者使用了兩個基準(zhǔn)數(shù)據(jù)集:CIFAR-10和ImageNet(ILSVRC12)進行了實驗。在兩個數(shù)據(jù)集上的實驗結(jié)果表明,IR-Net比現(xiàn)有的最先進方法更具競爭力。
Deployment Efficiency
為了進一步驗證IR-Net在實際移動設(shè)備中的部署效率,作者在1.2GHz 64位四核ARM Cortex-A53的Raspberry Pi 3B上進一步實現(xiàn)了IR-Net,并在實際應(yīng)用中測試了其真實速度。表5顯示,IR-Net的推理速度要快得多,模型尺寸也大大減小,而且IR-Net中的位移操作幾乎不會帶來額外的推理時間和存儲消耗。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100721 -
算法
+關(guān)注
關(guān)注
23文章
4608瀏覽量
92845 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24691
發(fā)布評論請先 登錄
相關(guān)推薦
一文詳解物理信息神經(jīng)網(wǎng)絡(luò)
BP神經(jīng)網(wǎng)絡(luò)和人工神經(jīng)網(wǎng)絡(luò)的區(qū)別
rnn是遞歸神經(jīng)網(wǎng)絡(luò)還是循環(huán)神經(jīng)網(wǎng)絡(luò)
人工神經(jīng)網(wǎng)絡(luò)的特點和優(yōu)越性不包括什么
遞歸神經(jīng)網(wǎng)絡(luò)是循環(huán)神經(jīng)網(wǎng)絡(luò)嗎
循環(huán)神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)的區(qū)別
深度神經(jīng)網(wǎng)絡(luò)與基本神經(jīng)網(wǎng)絡(luò)的區(qū)別
反向傳播神經(jīng)網(wǎng)絡(luò)和bp神經(jīng)網(wǎng)絡(luò)的區(qū)別
bp神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)區(qū)別是什么
bp神經(jīng)網(wǎng)絡(luò)模型怎么算預(yù)測值
如何提高BP神經(jīng)網(wǎng)絡(luò)算法的R2值
卷積神經(jīng)網(wǎng)絡(luò)和bp神經(jīng)網(wǎng)絡(luò)的區(qū)別
神經(jīng)網(wǎng)絡(luò)架構(gòu)有哪些
基于毫米波雷達的手勢識別神經(jīng)網(wǎng)絡(luò)
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論