


前言
機器學習是什么,是用來干什么的?
機器學習就是樣本中有大量的x(特征量)和y(目標變量)然后求這個function。
機器學習是讓機器尋找函數Y=f(X)的過程,使得當我們給定一個X時,會返回我們想要得到的Y值。
例:
房價預測:X:位置、層數 -》 Y:xxxx元/平
相親預測:X:高富帥、矮矬窮 -》 Y:見、不見
車牌識別:X:(車牌圖片)-》 Y:車牌號碼
機器翻譯:X:(中文) -》 Y:(英文)
語音識別:X:(一段語音)-》 Y:(一段文字)
聊天機器人:X:How are you -》 Y:IM fine
一、機器學習
大致可以把機器學習分為Supervised learning(監督學習)和Unsupervised learning(非監督學習)兩類。兩者區別在于訓練樣本。
監督學習( supervised learning): 這種方法使用已標記數據來學習,它使用的標記數據可以是用戶對電影的評級(對推薦來說)、電影標簽(對分類來說)或是收入數字(對回歸預測來說)。
無監督學習( unsupervised learning): 一些模型的學習過程不需要標記數據,我們稱其為無監督學習。這類模型試圖學習或是提取數據背后的結構或從中抽取最為重要的特征。
監督學習多用于回歸分析(求解是連續值,比如某一區間)和分類問題(求解是離散值,比如對錯)。非監督學習初步多用于聚類算法(群分析)。
1. 監督學習
1.1 回歸分析
初識:
“回歸于事物本來的面目”
出自高爾頓種豆子的實驗,通過大量數據統計,他發現個體小的豆子往往傾向于產生比其更大的子代,而個體大的豆子則傾向于產生比其小的子代,然后高爾頓認為這是由于新個體在向這種豆子的平均尺寸“回歸”,大概的意思就是事物總是傾向于朝著某種“平均”發展,也可以說是回歸于事物本來的面目。
進階:
線性回歸:
即y=ax+b,因變量和自變量為線性關系,輸出y為一具體數值,例如房價預測中的房價,產量預測中的產量等等,主要用于預測某一具體數值。
邏輯回歸:
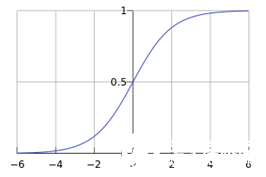
一個被logistic方程(sigmoid函數,如下圖)歸一化后的線性回歸,將線性回歸輸出的很大范圍的數,壓縮到0和1之間,這樣的輸出值表達為某一類別的概率,主要用于二分類問題。
1.2 決策樹
初識:
相親預測:
決策樹分類的思想類似于找對象。現想象一個女孩的母親要給這個女孩介紹男朋友,于是有了下面的對話:
女兒:多大年紀了?
母親:26。
女兒:長的帥不帥?
母親:挺帥的。
女兒:收入高不?
母親:不算很高,中等情況。
女兒:是公務員不?
母親:是,在稅務局上班呢。
女兒:那好,我去見見。
這個女孩的決策過程就是典型的分類樹決策。相當于通過年齡、長相、收入和是否公務員對將男人分為兩個類別:見和不見。
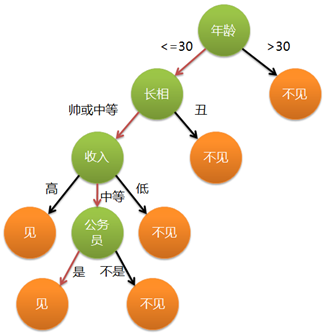
其中綠色節點表示判斷條件,橙色節點表示決策結果,箭頭表示在一個判斷條件在不同情況下的決策路徑。
進階:
決策樹(decision tree)是一個樹結構。其每個非葉節點表示一個特征屬性上的測試,每個分支代表這個特征屬性在某個值域上的輸出,而每個葉節點存放一個類別。使用決策樹進行決策的過程就是從根節點開始,測試待分類項中相應的特征屬性,并按照其值選擇輸出分支,直到到達葉子節點,將葉子節點存放的類別作為決策結果。
1.3 隨機森林
初識:
“三個臭皮匠頂過諸葛亮”
隨機森林中的每一棵決策樹可以理解為一個精通于某一個窄領域的專家,這樣在隨機森林中就有了很多個精通不同領域的專家,對一個新的問題(新的輸入數據),可以用不同的角度去看待它,最終由各個專家投票得到結果。
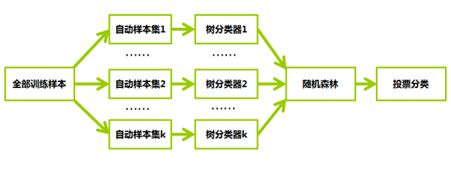
進階:
隨機森林通過自助法(bootstrap)重采樣技術,從原始訓練樣本集N中有放回地重復隨機抽取k個樣本生成新的訓練樣本集合,然后根據自助樣本集生成k個分類樹組成隨機森林,新數據的分類結果按分類樹投票多少形成的分數而定。
隨機森林可以用于分類和回歸。當因變量Y是分類變量時,是分類;當因變量Y是連續變量時,是回歸。
1.4 樸素貝葉斯
初識:
貝葉斯公式:
已知某種疾病的發病率是0.001,即1000人中會有1個人得病。現有一種試劑可以檢驗患者是否得病,它的準確率是0.99,即在患者確實得病的情況下,它有99%的可能呈現陽性。它的誤報率是5%,即在患者沒有得病的情況下,它有5%的可能呈現陽性。現有一個病人的檢驗結果為陽性,請問他確實得病的可能性有多大?
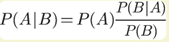
P(A|B)約等于0.019。也就是說,即使檢驗呈現陽性,病人得病的概率:也只從0.1%增加到了2%左右。這就是所謂的“假陽性”,即陽性結果完全不足以說明病人得病。
進階:
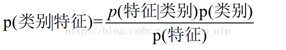
對于給出的待分類項,求解在此項特征出現的條件下各個類別出現的概率,哪個最大,就認為此待分類項屬于哪個類別。
比如輸入法里的錯拼也能搜出正確的詞,根據輸入的字母及其周邊可能出現的字母出現的概率,推薦出最符合想輸入的詞組。
1.5 支持向量機
初識:
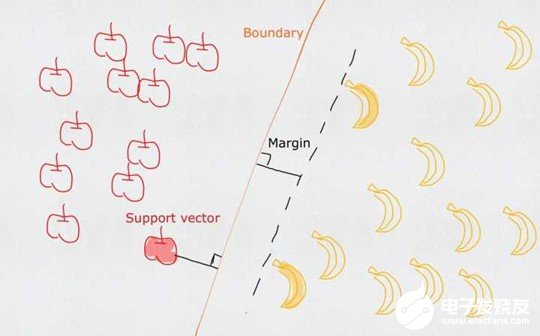
一個普通的支持向量機(SVM)就是一條直線,用來完美劃分線性分割的兩類。但這又不是一條普通的直線,這是無數條可以分類的直線當中最完美的,因為它恰好在兩個類的中間,距離兩個類的點都一樣遠。而所謂的支持向量就是這些離分界線最近的『點』。如果去掉這些點,直線多半是要改變位置的。可以說是這些vectors(主,點)support(謂,定義)了machine(賓,分類器)。
進階:
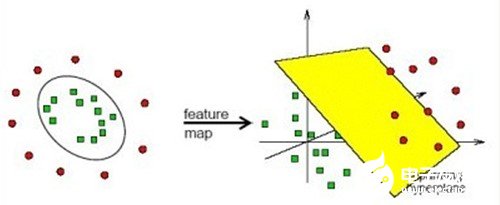
在線性不可分的情況下,支持向量機通過某種事先選擇的非線性映射(核函數)將輸入變量映射到一個高維特征空間,在這個空間中構造最優分類超平面。
2. 非監督學習
2.1 Kmeans
初識:
“人以類聚,物以群分”
例:你左手在地上撒一把鹽,右手在地上撒一把糖。假設你分不清鹽和糖,但是你分別是用左右手撒的,所以兩個東西位置不同,你就可以通過倆玩意的位置,判斷出兩個東西是兩類(左手撒的,右手撒的)。然而能不能區別出是糖還是鹽?不行。你只能分出這是兩類而已。但是分成兩類以后再去分析,就比撒地上一堆分析容易多了。
聚類分析主要就是把大類分為小類,然后再人工的對每一小類進行分析。
進階:
K-均值是把數據集按照k個簇分類,其中k是用戶給定的,其中每個簇是通過質心來計算簇的中心點。
首先創建一個初始劃分,隨機地選擇 k 個對象(中心點),每個對象初始地代表了一個簇中心。對于其他的對象,根據其與各個簇中心的距離,將它們賦給最近的簇,然后重新計算簇的平均值,將每個簇的平均值重新作為中心點,然后對對象進行重新分配。這個過程不斷重復,直到沒有簇中對象的變化。
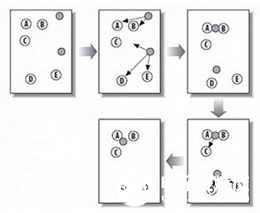
上圖中,A,B,C,D,E是五個聚類點,灰色的點是質心點,聚為兩類。
(1)隨機在圖中取K(這里K=2)個種子點。
(2)然后對圖中的所有點求到這K個種子點的距離,假如點Pi離種子點Si最近,那么Pi屬于Si點群。(上圖中,我們可以看到A,B屬于上面的種子點,C,D,E屬于下面中部的種子點)
(3)接下來,我們要移動種子點到屬于他的“點群”的中心。(見圖上的第三步)
(4)然后重復第2)和第3)步,直到,種子點沒有移動(我們可以看到圖中的第四步上面的種子點聚合了A,B,C,下面的種子點聚合了D,E)。
-
變量
+關注
關注
0文章
614瀏覽量
28986 -
機器學習
+關注
關注
66文章
8507瀏覽量
134745
發布評論請先 登錄
一篇文章告訴你電性能測試是做什么的

綜合配線柜是干什么的
gtta光纜是干什么的
如果需要使用DMD進行成像控制,需要用到哪些部件?

PLM項目管理系統主要干什么?制造業企業的PLM應用與效益

安泰功率放大器是干什么的

電視上的usb是用來干什么的
VCA821給出的AGC電路,出來的波形奇奇怪怪的,為什么?
用TINA仿真LMH6505,TINA-TI如何導入SPICE模型?
浙江氣密性檢測設備主要是用來干什么的






 工商網監
工商網監

評論