 解決機器學習中有關學習率的常見問題
解決機器學習中有關學習率的常見問題
什么是學習率?它的用途是什么?
神經網絡計算其輸入的加權和,并通過一個激活函數得到輸出。為了獲得準確的預測,一種稱為梯度下降的學習算法會在從輸出向輸入后退的同時更新權重。
梯度下降優化器通過最小化一個損失函數(L)來估計模型權重在多次迭代中的良好值,這就是學習率發揮作用的地方。它控制模型學習的速度,換句話說,控制權重更新到l最小點的速度。新(更新后)和舊(更新前)權重值之間的關系如下:

學習率是否為負值?
梯度L/w是損失函數遞增方向上的向量。L/w是L遞減方向上的向量。由于η大于0,因此是正值,所以-ηL/w朝L的減小方向向其最小值邁進。如果η為負值,則您正在遠離最小值,這是它正在改變梯度下降的作用,甚至使神經網絡無法學習。如果您考慮一個負學習率值,則必須對上述方程式做一個小更改,以使損失函數保持最小:

學習率的典型值是多少?
學習率的典型值范圍為10 E-6和1。
梯度學習率選擇錯誤的問題是什么?
達到最小梯度所需的步長直接影響機器學習模型的性能:
小的學習率會消耗大量的時間來收斂,或者由于梯度的消失而無法收斂,即梯度趨近于0。
大的學習率使模型有超過最小值的風險,因此它將無法收斂:這就是所謂的爆炸梯度。

梯度消失(左)和梯度爆炸(右)
因此,您的目標是調整學習率,以使梯度下降優化器以最少的步數達到L的最小點。通常,您應該選擇理想的學習率,該速率應足夠小,以便網絡能夠收斂但不會導致梯度消失,還應足夠大,以便可以在合理的時間內訓練模型而不會引起爆炸梯度。
除了對學習率的選擇之外,損失函數的形狀以及對優化器的選擇還決定了收斂速度和是否可以收斂到目標最小值。
錯誤的權重學習率有什么問題?
當我們的輸入是圖像時,低設置的學習率會導致如下圖所示的噪聲特征。平滑、干凈和多樣化的特征是良好調優學習率的結果。是否適當地設置學習率決定了機器學習模型的預測質量:要么是進行良好的訓練,要么是不收斂的網絡。
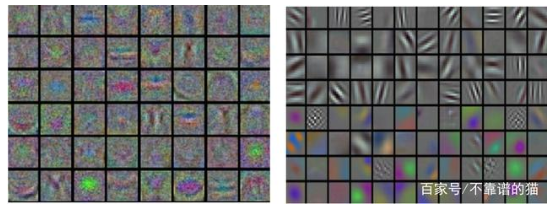
繪制神經網絡第一層產生的特征:不正確(左)和正確(右)設置學習率的情況
我們可以事先計算出最佳學習率嗎?
通過理論推導,不可能計算出導致最準確的預測的最佳學習率。為了發現給定數據集上給定模型的最佳學習率值,必須進行觀察和體驗。
我們如何設置學習率?
以下是配置η值所需了解的所有內容。
使用固定學習率:
您確定將在所有學習過程中使用的學習率的值。這里有兩種可能的方法。第一個很簡單的。它由實踐中常用的常用值組成,即0.1或0.01。第二種方法,您必須尋找適合您的特定問題和神經網絡架構的正確學習率。如前所述,學習率的典型值范圍是10 E-6和1。因此,你粗略地在這個范圍內搜索10的各種階數,為你的學習率找到一個最優的子范圍。然后,您可以在粗略搜索所找到的子范圍內以較小的增量細化搜索。你在實踐中可能看到的一種啟發式方法是在訓練時觀察損失,以找到最佳的學習率。
學習率時間schedule的使用:
與固定學習率不同,此替代方法要求根據schedule在訓練epochs內改變η值。在這里,您將從較高的學習率開始,然后在模型訓練期間逐漸降低學習率。在學習過程的開始,權重是隨機初始化的,遠遠沒有優化,因此較大的更改就足夠了。隨著學習過程的結束,需要更完善的權重更新。通常每隔幾個epochs減少一次學習Learning step。學習率也可以在固定數量的訓練epochs內衰減,然后對于其余的訓練epochs保持較小的恒定值。
常見的兩種方案。第一種方案,對于固定數量的訓練epochs,每次損失平穩(即停滯)時,學習率都會降低。第二種方案,降低學習率,直到達到接近0的較小值為止。三種衰減學習率的方法,即階躍衰減、指數衰減和1/t衰減。
在SGD中添加Momentum:
它是在經典的SGD方程中加入一項:

這個附加項考慮了由于Vt-1而帶來的權重更新的歷史,Vt-1是過去梯度的指數移動平均值的累積。這就平滑了SGD的進程,減少了SGD的振蕩,從而加速了收斂。然而,這需要設置新的超參數γ。除了學習率η的挑戰性調整外,還必須考慮動量γ的選擇。γ設置為大于0且小于1的值。其常用值為0.5、0.9和0.99。
自適應學習率的使用:
與上述方法不同,不需要手動調整學習率。根據權重的重要性,優化器可以調整η來執行更大或更小的更新。此外,對于模型中的每個權重值,都確保了一個學習率。Adagrad,Adadelta,RMSProp和Adam是自適應梯度下降變體的例子。您應該知道,沒有哪個算法可以最好地解決所有問題。

學習率配置主要方法概述
學習率的實際經驗法則是什么?
學習率是機器學習模型所依賴的最重要的超參數。因此,如果您不得不設置一個且只有一個超參數,則必須優先考慮學習率。
機器學習模型學習率的調整非常耗時。因此,沒有必要執行網格搜索來找到最佳學習率。為了得到一個成功的模型,找到一個足夠大的學習率使梯度下降法有效收斂就足夠了,但又不能大到永遠不收斂。
如果您選擇一種非自適應學習率設置方法,則應注意該模型將具有數百個權重(或者數千個權重),每個權重都有自己的損失曲線。因此,您必須設置一個適合所有的學習率。此外,損失函數在實際中往往不是凸的,而是清晰的u形。他們往往有更復雜的非凸形狀局部最小值。
自適應方法極大地簡化了具有挑戰性的學習率配置任務,這使得它們變得更加常用。此外,它的收斂速度通常更快,并且優于通過非自適應方法不正確地調整其學習率的模型。
SGD with Momentum,RMSProp和Adam是最常用的算法,因為它們對多種神經網絡架構和問題類型具有魯棒性。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
函數
+關注
關注
3文章
4327瀏覽量
62573 -
機器學習
+關注
關注
66文章
8408瀏覽量
132567
發布評論請先 登錄
相關推薦
zeta在機器學習中的應用 zeta的優缺點分析
什么是機器學習?通過機器學習方法能解決哪些問題?

NPU與機器學習算法的關系
電路設計常見問題解答
人工智能、機器學習和深度學習存在什么區別


【「時間序列與機器學習」閱讀體驗】+ 簡單建議
機器學習中的數據分割方法
人工智能、機器學習和深度學習是什么
機器學習算法原理詳解
深度學習與傳統機器學習的對比
機器學習的經典算法與應用
機器學習8大調參技巧
傅里葉變換基本原理及在機器學習應用






 工商網監
工商網監
評論