 通過界面和功能測試不能保證AI軟件的質量
通過界面和功能測試不能保證AI軟件的質量
近兩年人工智能發展迅猛,各種應用層出不窮,但其質量卻是良莠不齊。原因在于大部分測試童鞋還在用傳統的測試方式也就是通過界面和功能對人工智能軟件進行測試,但是AI軟件從開發到測試都很不同于傳統軟件,本文就以智能文本分類系統為例通過兩步來介紹為何傳統的測試方法不能保證AI軟件的質量。
一、第一步------------人工智能軟件測試的痛點
目標
掌握人工智能軟件測試面臨的現實痛點
步驟
1.智能文本分類系統是AI自然語言處理的一個基本應用,界面如下圖所示
2.對其測試時需要根據不同的輸入點擊獲取標簽得出所屬的類別以及所屬類別的概率值
3.通過功能和界面進行測試的話需要輸入各種可能輸入的文本,耗時巨大,并且也不太現實
4.從界面上對得到的score代表的概率值進行判斷無法得出一個客觀的評判,這個值多少合適判斷不了
5.因此傳統界面和功能測試完了判斷不了智能文本分類系統能否上線
二、第二步----------------AI軟件測試的正確方式
目標
掌握AI軟件測試的正確方式
步驟
1.了解AI軟件測試的本質
人工智能軟件是根據算法對大量的數據進行訓練找規律,最終得出一個模型來對新的數據進行預測,預測的時候會給出一個概率值。
2.AI軟件測試的正確方式
通過實現人工智能算法自帶的評測指標來進行AI軟件的測試可以很好的評估軟件的質量,完美解決窮舉各種輸入和概率值大小的現實問題
3.通過AI模型測試的具體評測指標
以智能文本分類為例,其采用了監督示機器學習的分類算法,對應的評測指標有:
準確率、精確率、召回率
總結
本文通過智能文本分類系統面臨的測試難點來指出AI軟件測試過程中的通用難題。以此指出了通過功能和界面測試人工智能軟件不能保證AI軟件的質量,正確的方式應該是通過實現AI軟件算法自帶的評測進行進行測試
-
AI
+關注
關注
87文章
30763瀏覽量
268906 -
人工智能
+關注
關注
1791文章
47208瀏覽量
238287
發布評論請先 登錄
相關推薦
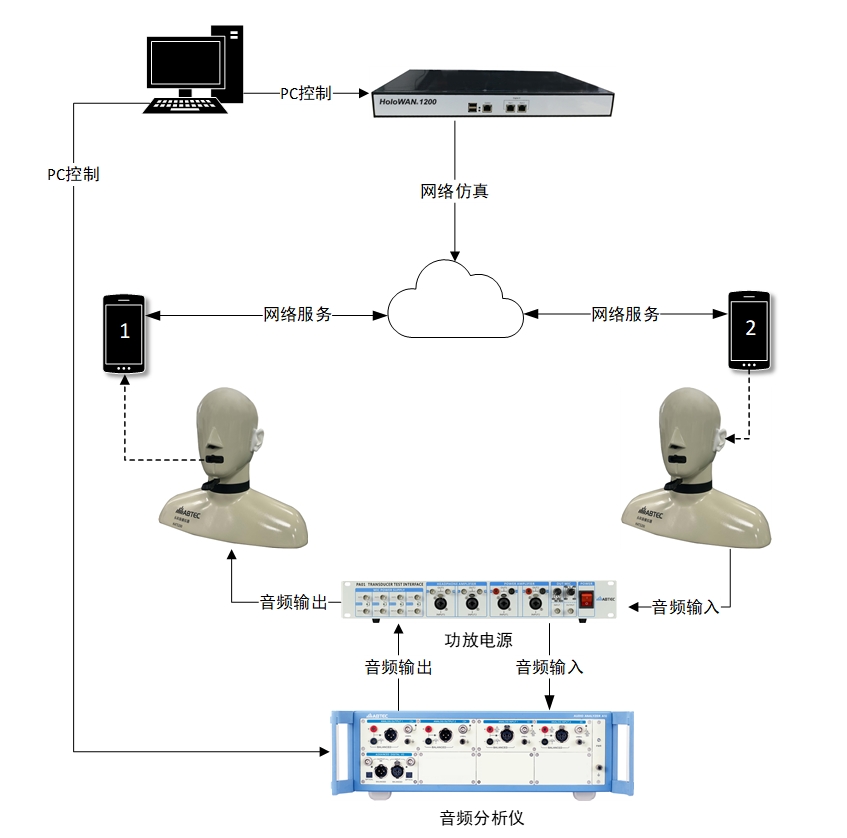
即時通話軟件音頻傳輸質量測試方案
AI大模型在智能座艙軟件測試中的應用與思考

Adobe在Illustrator和Photoshop設計軟件中引入新工具和生成性AI功能
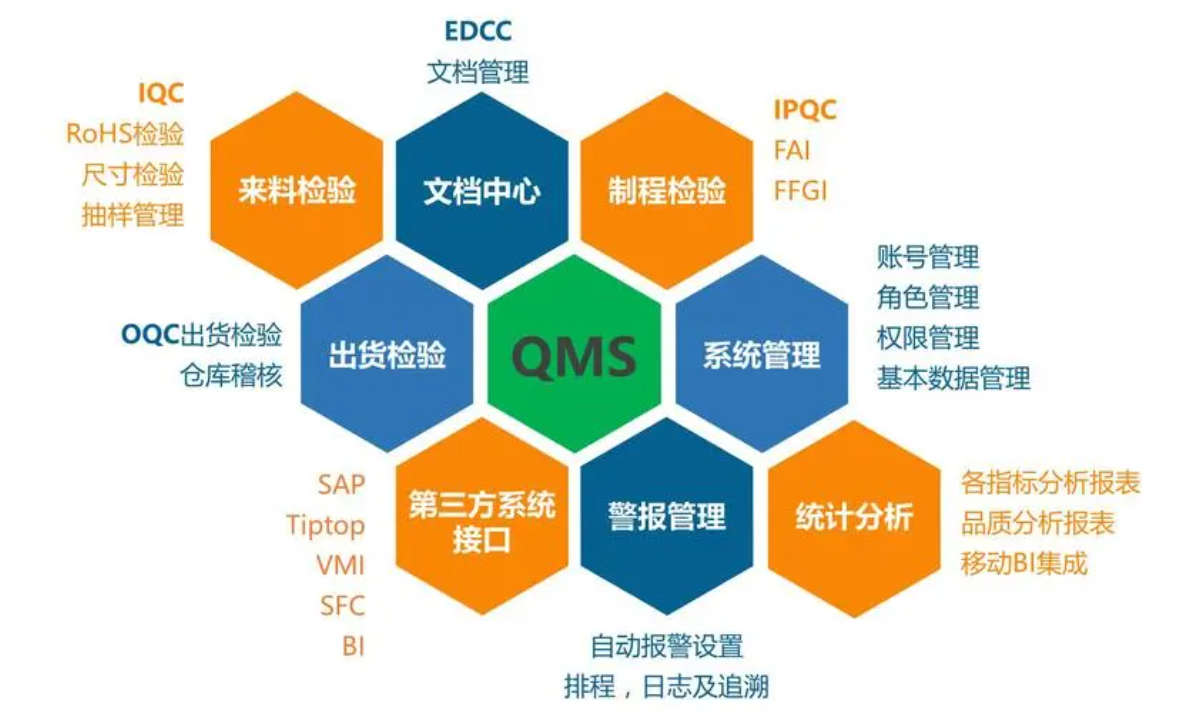
MES里面有質量模塊,為什么還要實施質量管理軟件QMS





 工商網監
工商網監
評論