") 設(shè)計(jì)非對(duì)稱(chēng)式互信息估計(jì)器減少音頻向視頻模態(tài)表達(dá)的不確定性
設(shè)計(jì)非對(duì)稱(chēng)式互信息估計(jì)器減少音頻向視頻模態(tài)表達(dá)的不確定性
隨著近年來(lái)音視頻生成技術(shù)的不斷發(fā)展,“虛擬主播”逐漸走入人們視野,并以其在虛擬客服、遠(yuǎn)程會(huì)議、電影剪輯等現(xiàn)實(shí)應(yīng)用場(chǎng)景中的重要作用而獲得了社會(huì)各界的廣泛關(guān)注。該技術(shù)旨在對(duì)輸入的音頻預(yù)測(cè)相應(yīng)口型,從而生成指定或任意人物的自然而準(zhǔn)確的面部說(shuō)話視頻。近日,中科院自動(dòng)化所智能感知與計(jì)算研究中心為此提出了一種新穎的音視頻協(xié)同計(jì)算方法,并重點(diǎn)解決了此前難以達(dá)成的任意人物協(xié)同生成問(wèn)題。
該方法一方面實(shí)現(xiàn)了利用語(yǔ)音驅(qū)動(dòng)任意對(duì)象的高清視頻生成,另一方面在正臉、側(cè)臉等多種場(chǎng)景下均顯著提升了生成視頻質(zhì)量。目前,該成果已被IJCAI 2020大會(huì)接收。
由于音視頻模態(tài)之間差異性等問(wèn)題,這項(xiàng)技術(shù)目前仍然存在著眾多挑戰(zhàn)。以往的研究方法往往將重點(diǎn)放在了模態(tài)內(nèi)之間,如只關(guān)注了視頻幀之間的損失約束,卻忽略了音視頻模態(tài)間最重要的問(wèn)題之一:如何將音頻信息高效充分地表達(dá)入視頻模態(tài)?同時(shí)由于人物與人物之間的個(gè)體差異,將同一模型應(yīng)用于任意人物視頻生成也存在較大的挑戰(zhàn)。
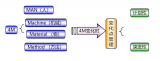
為解決上述問(wèn)題,團(tuán)隊(duì)精心設(shè)計(jì)了一個(gè)非對(duì)稱(chēng)式互信息估計(jì)器(Asymmetric Mutual Information Estimator, AMIE),以構(gòu)建音視頻模態(tài)間的約束。如圖1示,輸入一對(duì)音頻與人臉圖像數(shù)據(jù),互信息估計(jì)器輸出預(yù)測(cè)的互信息值。在這里,該方法使用Jensen-Shannon表示形式來(lái)改善互信息計(jì)算方式,使其更好地應(yīng)用于神經(jīng)網(wǎng)絡(luò)。通過(guò)這樣的互信息估計(jì)方式,該方法最大化音頻與視頻模態(tài)之間的互信息,減少音頻向視頻模態(tài)表達(dá)的不確定性,并以此獲得音頻和視頻信息之間的跨模態(tài)一致性,使得生成視頻中人物的口型更加準(zhǔn)確自然。
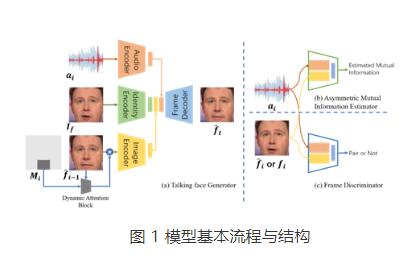
該方法在LRW和GRID基礎(chǔ)數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn)驗(yàn)證。圖2中的結(jié)果表明該方法生成的口型準(zhǔn)確度高,且能夠有效適應(yīng)不同膚色與嘴唇形狀差異。表1的量化結(jié)果顯示該方法在常用的對(duì)比指標(biāo)上的優(yōu)越性能。

該方法有能力對(duì)不存在于數(shù)據(jù)集中的任意人物進(jìn)行視頻合成,并能夠有效處理如姿態(tài)表情、性別差異等變化因素(見(jiàn)圖3)。例如,輸入一段女性語(yǔ)音(圖中第二行),該方法分別生成了現(xiàn)實(shí)場(chǎng)景的同性別人臉視頻(圖中第一行),和跨性別人臉視頻(圖中第三行)。

責(zé)任編輯:gt
-
音頻
+關(guān)注
關(guān)注
29文章
2882瀏覽量
81631 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4772瀏覽量
100857 -
視頻
+關(guān)注
關(guān)注
6文章
1947瀏覽量
72950
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
AFE5808A串并變換之后數(shù)據(jù)錯(cuò)位,輸出結(jié)果具有不確定性,為什么?
“雙系統(tǒng)”出爐!瑞芯微RK3562J非對(duì)稱(chēng)AMP:Linux+RTOS/裸機(jī)
科技云報(bào)到:數(shù)字化轉(zhuǎn)型,從不確定性到確定性的關(guān)鍵路徑

計(jì)及多重不確定性的規(guī)模化電動(dòng)汽車(chē)接入配電網(wǎng)調(diào)度方法及解決方案
OPA828運(yùn)放非對(duì)稱(chēng)電源供電有什么好處嗎?
相對(duì)于人工的不確定性,機(jī)器人碼垛有何優(yōu)勢(shì)
ETAS推出Time-Triggered Scheduling (TTS)的確定性調(diào)度解決方案
什么是嵌入式實(shí)時(shí)系統(tǒng)的確定性?簡(jiǎn)析EDMS中的確定性
單相降壓轉(zhuǎn)換器雙非對(duì)稱(chēng)AG評(píng)估板數(shù)據(jù)手冊(cè)

海信馬曉龍:堅(jiān)定長(zhǎng)期主義的戰(zhàn)略定力,激發(fā)“確定性”增長(zhǎng)的內(nèi)生動(dòng)力

華玉通軟宣布“海鷗”確定性調(diào)度中間件(SEAGULL DS)正式商用

上海交大科研團(tuán)隊(duì)使用Moku:pro推進(jìn)在量子光學(xué)實(shí)驗(yàn)中的多參數(shù)估計(jì)

為什么三相短路是對(duì)稱(chēng)故障?單相短路是非對(duì)稱(chēng)故障呢?
確定性網(wǎng)絡(luò)技術(shù)如何提高網(wǎng)絡(luò)的可靠性?

智能制造的本質(zhì)是解決不確定性





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論