 神經網絡的DBN與GAN及RNN等形象的詳細資料講解
神經網絡的DBN與GAN及RNN等形象的詳細資料講解
一、深度信念網絡(DBN)
2006年,神經網絡之父Geoffrey Hinton祭出神器深度信念網絡,一舉解決了深層神經網絡的訓練問題,推動了深度學習的快速發展。 深度信念網絡(Deep Belief Nets),是一種概率生成模型,能夠建立輸入數據和輸出類別的聯合概率分布。 深度信念網絡通過采用逐層訓練的方式,解決了深層次神經網絡的優化問題,通過逐層訓練為整個網絡賦予了較好的初始權值,使得網絡只要經過微調就可以達到最優解。 深度信念網絡的每個隱藏層都扮演著雙重角色:它既作為之前神經元的隱藏層,也作為之后神經元的可見層。 在逐層訓練的時候起到最重要作用的是“受限玻爾茲曼機” 結構上看,深度信念網絡可以看成受限玻爾茲曼機組成的整體 1. 玻爾茲曼機(BM) 玻爾茲曼機,(Boltzmann Machines,簡稱BM),1986年由大神Hinton提出,是一種根植于統計力學的隨機神經網絡,這種網絡中神經元只有兩種狀態(未激活、激活),用二進制0、1表示,狀態的取值根據概率統計法則決定。 由于這種概率統計法則的表達形式與著名統計力學家L.E.Boltzmann提出的玻爾茲曼分布類似,故將這種網絡取名為“玻爾茲曼機”。 在物理學上,玻爾茲曼分布是描述理想氣體在受保守外力的作用時,處于熱平衡態下的氣體分子按能量的分布規律。 在統計學習中,如果我們將需要學習的模型看成高溫物體,將學習的過程看成一個降溫達到熱平衡的過程。能量收斂到最小后,熱平衡趨于穩定,也就是說,在能量最少的時候,網絡最穩定,此時網絡最優。 玻爾茲曼機(BM)可以用在監督學習和無監督學習中。 在無監督學習中,隱變量可以看做是可見變量的內部特征表示,能夠學習數據中復雜的規則。玻爾茲曼機代價是訓練時間很長很長很長。2. 受限玻爾茲曼機(RBM) 受限玻爾茲曼機(Restricted Boltzmann Machines,簡稱RBM) 將“玻爾茲曼機”(BM)的層內連接去掉,對連接進行限制,就變成了“受限玻爾茲曼機”(RBM) 一個兩層的神經網絡,一個可見層和一個隱藏層。 可見層接收數據,隱藏層處理數據,兩層以全連接的方式相連,同層之前不相連。 受限玻爾茲曼機需要將輸出結果反饋給可見層,通過讓重構誤差在可見層和隱藏層之間循環往復地傳播,從而重構出誤差最小化的一組權重系數。 傳統的反向傳播方法應用于深度結構在原則上是可行的,可實際操作中卻無法解決梯度彌散的問題 梯度彌散(gradient vanishing),當誤差反向傳播時,傳播的距離越遠,梯度值就變得越小,參數更新的也就越慢。 這會導致在輸出層附近,隱藏層的參數已經收斂;而在輸入層附近,隱藏層的參數幾乎沒有變化,還是隨機選擇的初始值。
二、生成對抗網絡(GAN)
就像孫悟空和牛魔王一樣搶奪紫霞仙子,進入對抗狀態
GAN(Generative Adversarial Network)是由Goodfellow等人于2014年設計的生成模型,受博弈論中的零和博弈啟發,將生成問題視作生成器和判別器這兩個網絡的對抗和博弈。 該方法由是由Goodfellow等人于2014年提出,生成對抗網絡由一個生成器與一個判別器組成,生成網器從潛在空間中隨機取樣作為輸入,其輸出結果需要盡量模仿訓練集中的真實樣本。 判別器的輸入為真實樣本或生成器的輸出,其目的是將生成器的輸出從真實樣本中盡可能分辨出來。 GAN主要優點是超越了傳統神經網絡分類和特征提取的功能,能夠按照真實數據的特點生成新的數據。 兩個網絡在對抗中進步,在進步后繼續對抗,由生成式網絡得的數據也就越來越完美,逼近真實數據,從而可以生成想要得到的數據(圖片、序列、視頻等)。1. 生成器(generator)生成器從給定噪聲中(一般是指均勻分布或者正態分布)產生合成數據。試圖產生更接近真實的數據。 “生成器像是白骨精,想方設法從隨機噪聲中模擬真實數據樣本的潛在分布,以生成以假亂真的數據樣本”2. 判別器(discriminator)判別器分辨生成器的的輸出和真實數據。試圖更完美地分辨真實數據與生成數據。 “判別器是孫悟空,用火眼金睛來判斷是人畜無害的真實數據還是生成器假扮的偽裝者” 生成器和判別器都可以采用深度神經網絡實現,建立數據的生成模型,使生成器盡可能精確你有沒出數據樣本的分布,從學習方式上對抗性學習屬于無監督學習,
網絡訓練可以等效為目錄函數的極大-極小問題
極大:讓判別器區分真實數據和偽造數據的準確率最大化
極小:讓生成器生成的數據被判別器發現的概率最小化
傳統生成模型定義了模型的分布,進而求解參數。比如在已知數據滿足正態分布的前提下,生成模型會通過極大似然估計等方法根據樣本來求解正態的均值和方差。 生成對抗網絡擺脫了對模型分布的依賴,也不限制生成的維度,大大拓寬了生成數據樣本的范圍,還能融合不同的損失函數,增加了設計的自由度。
三、循環神經網絡(RNN)
循環網絡,如同月光寶盒,時間在不停地循環
循環神經網絡(Recurrent Neural Network),也可以表示遞歸神經網絡(Recursive Neural Network)。循環神經網絡可以看成是遞歸神經網絡的特例,遞歸神經網絡可以看成是循環神經網絡的推廣。 卷積神經網絡具有空間上的參數共享的特性,可以讓同樣的核函數應用在圖像的不同區域。 把參數共享調整到時間維度上,讓神經網絡使用相同權重系數來處理具有先后順序的數據,得到的就是循環神經網絡。
時間
循環神經網絡引入了”時間“的維度,適用于處理時間序列類型的數據。
循環神經網絡就是將長度不定的輸入分割為等長的小塊,再使用相同的權重系統進行處理,從而實現對變長輸入的計算與處理。
比方說媽媽在廚房里突然喊你:“菜炒好了,趕緊來。。.。。.”,即使后面的話沒有聽清楚,也能猜到十有八九是讓你趕緊吃飯
記憶
循環神經網絡t時刻的輸出取決于當前時刻的輸入,也取決于網絡前一時刻t-1甚至更早的輸出。
從這個意義上來講,循環神經網絡引入引入了反饋機制,因而具有了記憶功能。記憶功能使循環神經網絡能夠提取來自序列自身的信息,輸入序列的內部信息存儲在神經網絡的隱藏層中,并隨著時間的推移在隱藏層中流轉。循環網絡的記憶特性可以用公式表示為
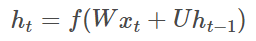

W 表示從輸入到狀態的權重矩陣,U 表示從狀態到狀態的轉移矩陣。
對循環神經網絡的訓練就是根據輸出結果和真實結果之間的誤差不斷調整參數 W 和 U,直到達到預設要求的過程,訓練方法也是基于梯度的反向傳播算法。 前饋神經網絡某種程序上也具有記憶特性,只要神經網絡參數經過最優化,優化的參數就會包含以往數據的蹤跡,但是優化的記憶只局限于訓練數據集上,當訓練的醋應用到新的測試數據集上時,其參數并不會根據測試數據的表現做出進一步調整。1. 雙向RNN比如有一部電視劇,在第三集的時候才出現的人物,現在讓預測一下在第三集中出現的人物名字,你用前面兩集的內容是預測不出來的,所以你需要用到第四,第五集的內容來預測第三集的內容,這就是雙向RNN的想法
如果想讓循環神經網絡利用來自未來的信息,就要讓當前的狀態和以后時刻的狀態建立直聯系,就是雙向循環神經網絡。
雙向循環網絡包括正向計算和反向計算兩個環節

雙向循環網絡需要分別計算正向和反向的結果,并將兩者作為隱藏層的最終參數。
2. 深度RNN將深度結構引入循環神經網絡就可以得到深度循環網絡。 比如你學習英語的時候,背英語單詞一定不會就看一次就記住了所有要考的單詞,一般是帶著先前幾次背過的單詞,然后選擇那些背過但不熟的內容或者沒背過的單詞來背
深層雙向RNN 與雙向RNN相比,多了幾個隱藏層,因為他的想法是很多信息記一次記不下來, 深層雙向RNN就是基于這么一個想法,每個隱藏層狀態h_{t}^{i}既取決于同一時刻前一隱藏層的狀態h_{t}^{i-1},也取決于同一隱藏層的狀態h_{t-1}^{i} 深度結構的作用在于建立更清晰的表示。用“完形填空”來說,需要根據上下文,來選擇合適的詞語。有些填空只需要根據它所在的句子便可以推斷出來,這對應著單個隱藏層在時間維度上的依賴性;有些填空則可能要通讀整段或全文才能確定,這對應了時間維度和空間維度共有的依賴性。3. 遞歸RNN遞歸神經網絡能夠處理具有層次化結構的數據,可以看成循環網絡的推廣
循環神經網絡特點是在時間維度上共享參數,從而展開處理序列,如果展開成樹狀態結構,用到的就是遞歸神經網絡。遞歸神經網絡首先將輸入數據轉化為某種拓撲結構,再在相同的結構上遞歸使用相同的權重系數,通過遍歷方式得到結構化的預測。 例如,“兩個大學的老師”有歧義,如果單純拆分為詞序列無法消除歧義。
遞歸神經網絡通過樹狀結構將一個完整的句子打散為若干分量的組合,生成的向量不是樹結構的根節點。
四、長短期記憶網絡(LSTM)
如果非要給記憶加一個期限,希望是一萬年
長短期記憶網絡(LSTM,Long Short-Term Memory)是一種時間循環神經網絡,為了解決一般的RNN(循環神經網絡)存在的長期依賴問題而專門設計出來的,論文首次發表于1997年。由于獨特的設計結構,LSTM適合于處理和預測時間序列中間隔和延遲非常長的重要事件。
RNN通過在時間共享參數引入了記特性,從而可以將先前的信息應用在當前的任務上,可是這種記憶通常只有有限的深度。 例如龍珠超或者火影每周更新一集,即使經歷了一周的空檔期,我們還是能將前一集的內容和新一集的情節無縫銜接起來。但是RNN的記憶就沒有這么強的延續性,別說一個星期,5分鐘估計都已經歇菜了。 LSTM可以像人的記憶中選擇性地記住一些時間間隔更久遠的信息,它會根據組成元素的特性,來判斷不同信息是被遺忘或被記住繼續傳遞下去。
LSTM就是實現長期記憶用的,實現任意長度的記憶。要求模型具備對信息價值的判斷能力,結合自身確定哪些信息應該保存,哪些信息該舍棄,元還要能決定哪一部分記憶需要立刻使用。4種組成LSTM通常由下面4個模塊組成
① 記憶細胞(memory cell)
作用是存儲數值或狀態,存儲的時限可以是長期也可以是短期 ② 輸入門(input gate)
決定哪些信息在記憶細胞中存儲 ③ 遺忘門(forget gate)
決定哪些信息從記憶細胞中丟棄 ④ 輸出門(output gate)
決定哪些信息從記憶細胞中輸出
五、卷積神經網絡(CNN)
將鮮花用包裝紙沿著對角線卷起來,顧名思義卷積
卷積神經網絡(convolutional neural network)指至少某一導中用了卷積運算(convolution)來代替矩陣乘法的神經網絡。
1. 卷積是什么卷積是對兩個函數進行的一種數學運算,我們稱(f?g)(n)為f,g的卷積
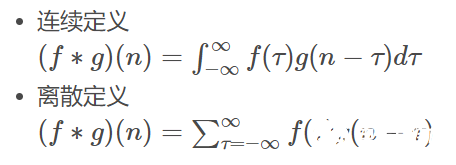
我們令x=τ,y=n?τ,那么x+y=n,相當于下面的直線
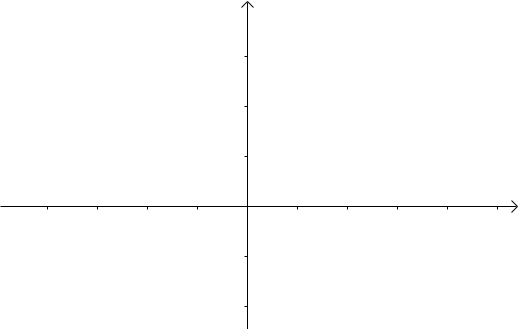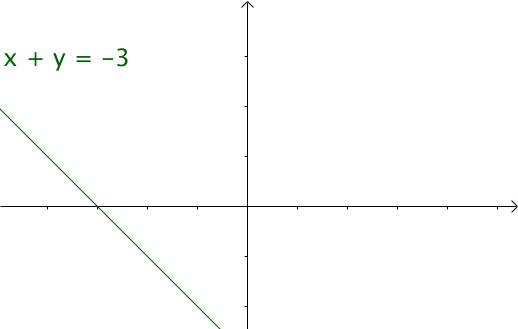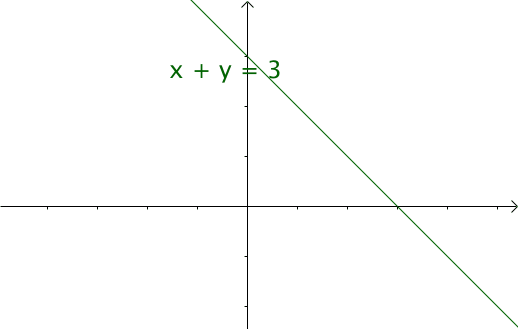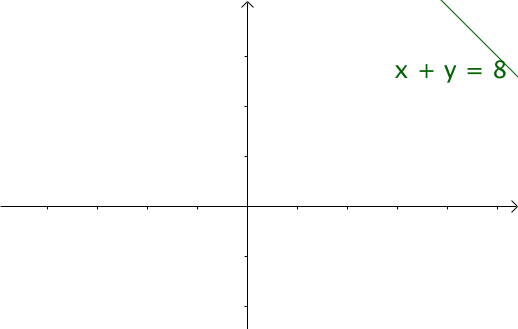
如果遍歷這些直線,就像毛巾卷起來一樣,顧名思義“卷積” 在卷積網絡中,卷積本質就是以核函數g作為權重系數,對輸入函數f進行加權求和的過程。 其實把二元函數U(x,y)=f(x)g(y)卷成一元函數V(t),俗稱降維打擊 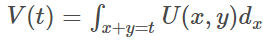 函數 f 和 g 應該地位平等,或者說變量 x 和 y 應該地位平等,一種可取的辦法就是沿直線 x+y = t 卷起來;① 擲骰子求兩枚骰子點數加起來為4的概率,這正是卷積的應用場景。 第一枚骰子概率為為f(1)、f(2)、。。.f(6)
函數 f 和 g 應該地位平等,或者說變量 x 和 y 應該地位平等,一種可取的辦法就是沿直線 x+y = t 卷起來;① 擲骰子求兩枚骰子點數加起來為4的概率,這正是卷積的應用場景。 第一枚骰子概率為為f(1)、f(2)、。。.f(6)
第二枚骰子概率為g(1)、g(2)、。。.g(m)
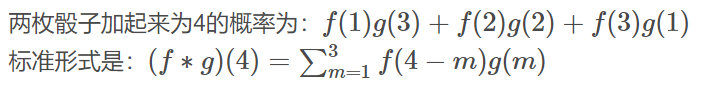
② 做饅頭機器不斷的生產饅頭,假設饅頭生產速度是f(t),
那么一天生產出來的饅頭總量為
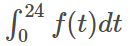
生產出來后會逐漸腐敗,腐敗函數為g(t),比如10個饅頭,24小時會腐敗
10?g(t)
一天生產出來的饅頭就是
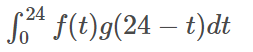
③ 做魚
卷積看做做菜,輸入函數是原料,核函數是菜譜,對于同一輸入函數鯉魚來說
核函數中的醬油權重較大,輸出紅燒魚
核函數中的糖和醋權重大較大,輸出西湖醋魚
核函數中的辣椒權重較大,輸出朝鮮辣魚
④ 圖像處理假設一幅圖有噪點,要將它進行平滑處理,可以把圖像轉為一個矩陣
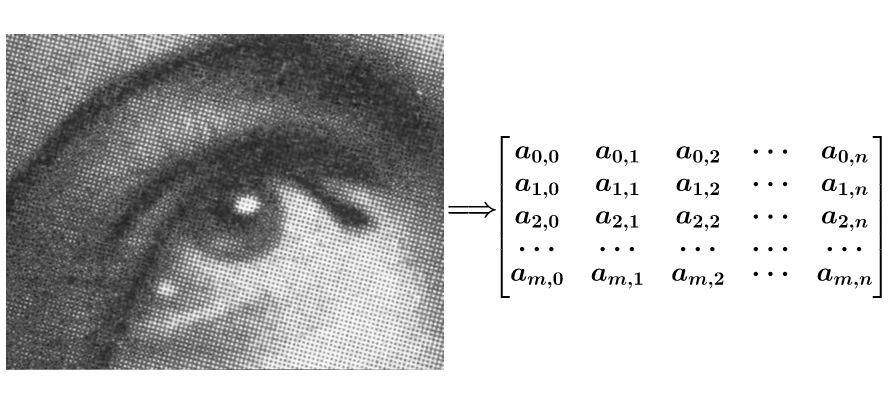
如果要平滑a1,1點,就把a1,1點附近的組
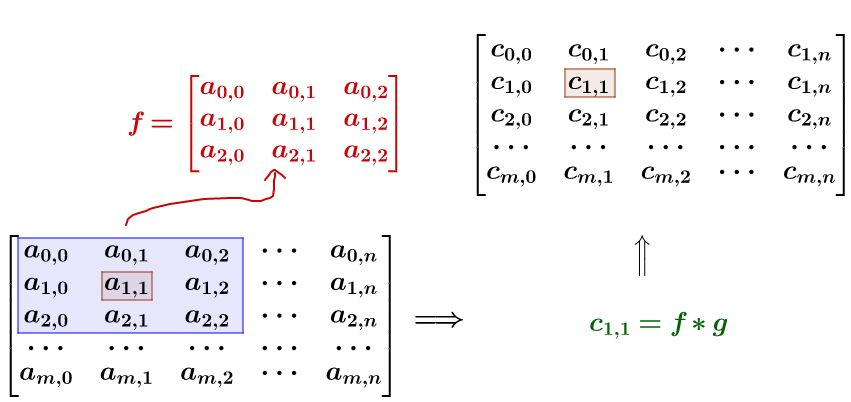
成矩陣f,和g進行卷積運算,再填充回去f 和g的計算如下,其實就是以相反的方向進行計算,像卷毛巾一樣

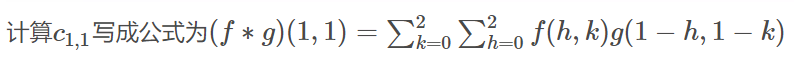
2. 卷積神經網絡特性
卷積運算的特性決定了神經網絡適用于處理具有網絡狀結構的數據。 典型的網絡型數據就是數字圖像,無論是灰度還是彩色圖像,都是定義在二維像素網絡上的一組標題或向量。 卷積神經網絡廣泛地應用于圖像與文本識別之中,并逐漸擴展到自然語言處理等其他領域。① 稀疏感知性
卷積層核函數的大小通常遠遠小于圖像的大小。
圖像可能在兩個維度上都有幾千個像素,但核函數最大不會超過幾十個像素。
選擇較小的核函數有助于發現圖像中細微的局部細節,提升算法的存儲效率和運行效率。② 參數共享性
一個模型中使用相同的參數。每一輪訓練中用單個核函數去和圖像的所有分塊來做卷積。③ 平移不變性
當卷積的輸入產生平衡時,其輸出等于原始輸出相同數量的平移,說明平移操作和核函數的作用是可以交換的。
3. 卷積神經網絡分層
當輸入圖像被送入卷積神經網絡后,先后要循環通過卷積層、激勵層和池化層,最后從全連接層輸出分類結果。① 輸入層
輸入數據,通常會做一些數據處理,例如去均值、歸一化、 PCA/白化等② 卷積層
卷積層是卷積神經網絡的核心部分,參數是一個或多個隨機初始化的核函數,核函數就像按照燈一樣,逐行逐列掃描輸入圖像。掃描完畢后計算出的所有卷積結果可以構成一個矩陣,這個新的矩陣叫特征映射(feature map)。卷積層得到的特征一般會送到激勵層處理③ 激勵層
主要作用是將卷積層的結果做非線性映射。常見的激勵層函數有sigmoid、tanh、Relu、Leaky Relu、ELU、Maxout④ 池化層
在連續的卷基層和激勵層中間,用于壓縮數據和參數的量,用于減少過擬合。
簡而言之,如果輸入是圖像的話,那么池化層的最主要作用就是壓縮圖像。
常見的最大池化做法就是將特征映射劃分為若干個矩形區域,挑選每個區域中的最大值。
⑤ 全連接層
兩層之間所有神經元都有權重連接,通常全連接層在卷積神經網絡尾部,輸出分類結果。
在卷積神經網絡的訓練里,待訓練的參數是卷積核。
卷積核:也就是用來做卷積的核函數。
卷積神經網絡的作用是逐層提取輸入對象的特征,訓練采用的也是反向傳播的方法,參數的不斷更新能夠提升圖像特征提取的精度
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
函數
+關注
關注
3文章
4327瀏覽量
62573 -
生成器
+關注
關注
7文章
315瀏覽量
21003
發布評論請先 登錄
相關推薦
什么是RNN (循環神經網絡)?
遞歸神經網絡(RNN)
循環神經網絡(RNN)和(LSTM)初學者指南
MATLAB和BP人工神經網絡算法源代碼與演示程序詳細資料免費下載






 工商網監
工商網監
評論