") 史上最大的人工智能算法模型GPT-3問(wèn)世,意味著什么?
史上最大的人工智能算法模型GPT-3問(wèn)世,意味著什么?
2020年,年中。
人類歷史上最大的人工智能模型,來(lái)到人間。
這個(gè)體格巨大的北鼻,哭聲嘹亮,告知全世界:“我寫的作文,幾乎通過(guò)了圖靈測(cè)試。”
那些第一次聽(tīng)說(shuō)參數(shù)數(shù)量的人,那些第一次翻看實(shí)驗(yàn)結(jié)果的人,那些第一次口算增長(zhǎng)速度的人,在彼此確認(rèn)了眼神之后,一致的反應(yīng)是:“哦漏,我大概是瘋了吧。不,是人工智能模型瘋了吧。”
“不僅會(huì)寫短文,而且寫出來(lái)的作文挺逼真的,幾乎可以騙過(guò)人類,可以說(shuō)幾乎通過(guò)了圖靈測(cè)試。”
如果沒(méi)有后兩個(gè)半句,你可能會(huì)誤認(rèn)為這是老師對(duì)文科生學(xué)霸的評(píng)語(yǔ)。
理科也超級(jí)擅長(zhǎng),還能輔導(dǎo)別人編程。
“以前都是人類去寫程序,現(xiàn)在是人類寫一個(gè)人工智能算法,算法自己從數(shù)據(jù)中推導(dǎo)出程序。新的人工智能技術(shù)路線已經(jīng)跑通。”
學(xué)渣,看破紅塵,敲敲木魚,念出喬布斯的名言:
做個(gè)吃貨,做個(gè)蠢貨(Stay hungry,Stay foolish)。
反正養(yǎng)老托付給人工智能了。而這樣的人工智能,需要巨額的資金,需要頂級(jí)的技術(shù)。
科技巨頭微軟大筆一揮,千萬(wàn)美金的支票,拿走不謝。
據(jù)測(cè)算,即使使用市場(chǎng)上價(jià)格最低的GPU云計(jì)算(服務(wù)),也需要355年的時(shí)間和3500多萬(wàn)人民幣的費(fèi)用。
大明宮首席建筑師閻立本,收起畫完《步輦圖》的畫筆,在呈給太宗李世民的臣下章奏中寫道“用工十萬(wàn)”。
千宮之宮,留名千古。
全球頂級(jí)人工智能實(shí)驗(yàn)室,用金千萬(wàn)。
三十一位研究人員,徒手修建了一個(gè)外表看上去擅長(zhǎng)胸口碎大石的北鼻。
挪步震掀桌椅,哭嚎萬(wàn)馬齊喑。
這個(gè)超大人工智能模型,名叫GPT-3。
早期的深度學(xué)習(xí)模型,參數(shù)量小,好比一個(gè)樂(lè)高玩具,每天擺在辦公桌上賣萌。
如今的深度學(xué)習(xí)模型,參數(shù)量挑戰(zhàn)底層GPU并行技術(shù),參數(shù)量挑戰(zhàn)底層地基。
好比同樣是樂(lè)高模型,GPT-3可以在北京朝陽(yáng)區(qū)三里屯優(yōu)衣庫(kù)門口當(dāng)大型擺設(shè)。
當(dāng)然不是試衣服,而是欲與大樓試比高。
知乎問(wèn)題:“如何看和樓一樣高的樂(lè)高模型?”
網(wǎng)友回答:“抬頭看。”
不抬頭,只能看到腳丫子。一個(gè)正常的模型大小刻度表,綠巨人GPT-3模型是放不進(jìn)來(lái)的,得重新畫一下坐標(biāo)軸的刻度。
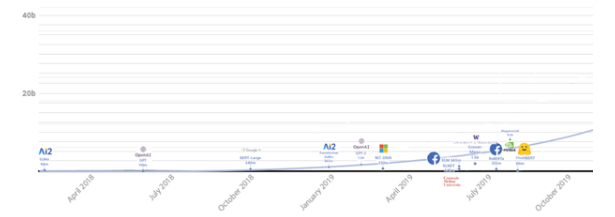
(原來(lái)的隊(duì)列)
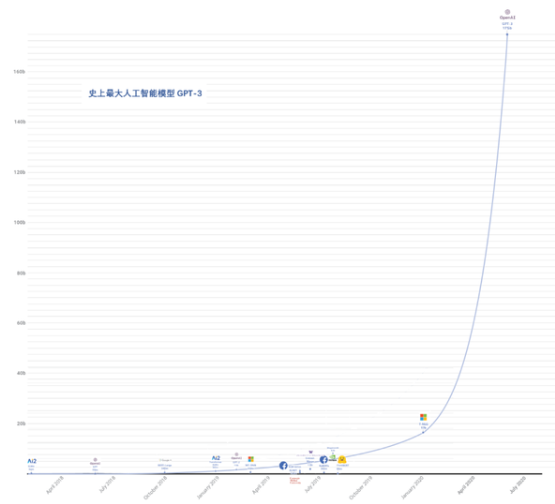
(GPT-3來(lái)后的隊(duì)列)
人工智能超大模型GPT-3和綠巨人浩克一樣,都是大塊頭。
經(jīng)常觀摩,可以治療頸椎病。
綠巨人GPT-3模型出生于美國(guó)Open AI實(shí)驗(yàn)室。
在看到自己的論文刷爆了朋友圈后,像他們這么低調(diào)的科研團(tuán)隊(duì),一點(diǎn)也沒(méi)有得意,只是在辦公室旋轉(zhuǎn)、跳躍,并巡回炫耀了24小時(shí),而已。
早在2019年,Open AI實(shí)驗(yàn)室就發(fā)出前方高能預(yù)警。
他們核算了自2012年以來(lái)模型所用的計(jì)算量,從AlexNet模型到AlphaGo Zero模型。AlexNet模型,是冠軍模型。AlphaGo Zero模型,是打敗韓國(guó)圍棋九段棋手李世石的那個(gè),它們都是人工智能模型。
參數(shù)指標(biāo)很爭(zhēng)氣,增長(zhǎng)30萬(wàn)倍。
那些堪稱“最大”的AI訓(xùn)練模型所使用的計(jì)算量,呈指數(shù)型增長(zhǎng)。
3.4個(gè)月就會(huì)倍增。這是Open AI實(shí)驗(yàn)室的結(jié)論。
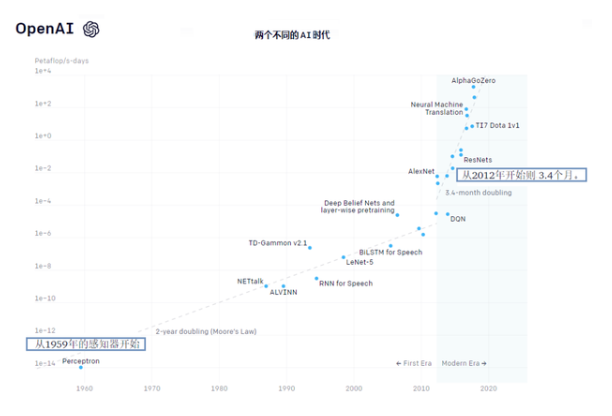
雖然還沒(méi)有成為“定律”,但已經(jīng)有很多人用“摩爾定律”和其比較。
摩爾定律說(shuō),芯片性能翻倍的周期是18個(gè)月。Open AI說(shuō),人工智能訓(xùn)練模型所需要的計(jì)算量的翻倍周期是3.4個(gè)月。
三個(gè)半月,一臺(tái)計(jì)算機(jī)就不夠了,得兩臺(tái)。掐指一算,618大促買新的機(jī)器,雙11大促又得買新的了。
對(duì)于人工智能的科研工作來(lái)說(shuō),金錢是個(gè)好仆人。
如果你不知道Open AI,那要補(bǔ)補(bǔ)課了。
世界歷史上,美國(guó)時(shí)隔9年第一次使用國(guó)產(chǎn)火箭從本土將宇航員送入太空,民營(yíng)航天企業(yè)第一次進(jìn)行載人發(fā)射,馬斯克就是這家震驚世界的公司的創(chuàng)始人。
Open AI是全球人工智能頂級(jí)實(shí)驗(yàn)室,這家機(jī)構(gòu)也曾有馬斯克的支持。
平庸的人,都是相似的。
瘋狂的人,各有各的瘋狂。
一個(gè)人工智能的算法模型可以大到什么程度?
綠巨人GPT-3模型給出了新答案——1750億個(gè)參數(shù)。
實(shí)話實(shí)說(shuō),模型創(chuàng)新程度很難用單個(gè)指標(biāo)量化,模型復(fù)雜度和參數(shù)量有一定關(guān)系,模型參數(shù)量決定模型大小。
綠巨人GPT-3模型是啥?
是一個(gè)超級(jí)大的自然語(yǔ)言處理模型,將學(xué)習(xí)能力轉(zhuǎn)移到同一領(lǐng)域的多個(gè)相關(guān)任務(wù)中,既能做組詞造句,又能做閱讀理解。聽(tīng)上去像小學(xué)語(yǔ)文課的內(nèi)容。
把這種(預(yù)訓(xùn)練)模型比喻為小學(xué)生,一年級(jí)的語(yǔ)文作業(yè),組詞和造句,早就會(huì)做。你接手過(guò)來(lái),給模型輔導(dǎo)功課,無(wú)需從頭教起,接著教二年級(jí)的題目就可以了。
《語(yǔ)文》課本里熟悉的一幕:“閱讀全文,并總結(jié)段落大意。”
綠巨人GPT-3 模型“參數(shù)”身價(jià)幾何?我們來(lái)看看《福布斯·模型參數(shù)量排行榜》。
回首2011那年,AlexNet,冠軍模型,有0.6億個(gè)參數(shù)。
回顧前兩年,BERT模型,流行一時(shí),有3億個(gè)參數(shù)。
綠巨人GPT-3 模型的親哥哥GPT-2,有15億個(gè)參數(shù)。
英偉達(dá)的Megatron-BERT,有80 億參數(shù)。
2020年2月,微軟Turing NLP,有170 億參數(shù)。
2020年6月,綠巨人GPT-3,有1750億個(gè)參數(shù)。
小學(xué)數(shù)學(xué)老師告訴我們:綠巨人GPT-3模型穩(wěn)贏。
連體育老師也得這么教。
這時(shí)候,麥當(dāng)勞對(duì)人工智能說(shuō),更多參數(shù),更多歡樂(lè)。
理解模型的復(fù)雜度,要回顧一下歷史。
2015年,微軟發(fā)明的用于圖像識(shí)別的ResNet模型訓(xùn)練過(guò)程大約包含次浮點(diǎn)計(jì)算,模型含有千萬(wàn)級(jí)參數(shù)。
2016年,百度發(fā)明的用于語(yǔ)音識(shí)別的DeepSpeech模型訓(xùn)練過(guò)程大約包含次浮點(diǎn)計(jì)算,模型含有億級(jí)參數(shù)。
2017年,谷歌發(fā)明的用于機(jī)器翻譯的深度學(xué)習(xí)模型訓(xùn)練過(guò)程大約包含次浮點(diǎn)計(jì)算,模型含有數(shù)十億參數(shù)。
微軟、百度、谷歌,仿佛走進(jìn)了羅馬角斗場(chǎng),雙眼充滿紅血絲。
拜托,哪有這么血腥,看看科技巨頭的年度利潤(rùn)。人工智能本來(lái)就是貴族的游戲,哪個(gè)玩家沒(méi)有幾頭健壯的現(xiàn)金牛。
2018年之后,人工智能模型的消費(fèi)水平,進(jìn)入了奢侈品俱樂(lè)部。驢牌教父起身站立,鼓掌歡迎。
要是俱樂(lè)部有個(gè)微信群,奢侈品品牌掌門人,會(huì)依次“拍了拍微軟、百度、谷歌”。
此時(shí)此景,人工智能超級(jí)大模型,賦詩(shī)一首:
訓(xùn)練想得意,
先花一個(gè)億。
性能要兇猛,
揮金得如土。
人工智能算法模型“瘋狂”增長(zhǎng)的背后,究竟意味著什么?
圍繞這個(gè)問(wèn)題,我采訪了微軟亞洲研究院前研究員,一流科技創(chuàng)始人袁進(jìn)輝博士。
袁博士說(shuō)了兩層意思。
第一層,錢很重要。
袁進(jìn)輝博士說(shuō)道:“人工智能模型瘋狂增長(zhǎng)的背后,意味著人工智能的競(jìng)爭(zhēng)已經(jīng)進(jìn)入到軍備競(jìng)賽級(jí)別。長(zhǎng)時(shí)間的使用GPU集群是非常花錢的。制造一個(gè)像GPT-3這樣的超級(jí)模型的想法,可能有人能想到,但不是每個(gè)團(tuán)隊(duì)都有錢驗(yàn)證這一想法。除谷歌之外,很多公司沒(méi)有財(cái)力訓(xùn)練BERT-Large模型,并且,實(shí)現(xiàn)這個(gè)想法對(duì)工程能力要求極高。”
土豪的生活就是這樣,樸實(shí)無(wú)華又枯燥。訓(xùn)練超大GPT-3模型,須使用超大規(guī)模GPU機(jī)器學(xué)習(xí)集群。一個(gè)人工智能模型訓(xùn)練一次的花銷是千萬(wàn)美金,一顆衛(wèi)星的制造成本被馬斯克降到50萬(wàn)美元以下。人工智能模型比衛(wèi)星成本還昂貴。
土豪的生活又加了一點(diǎn),土豪也得勤奮。
第二層,不是有錢就能行,技術(shù)也很重要。
在袁進(jìn)輝看來(lái),人工智能的大模型運(yùn)行在大規(guī)模GPU(或者TPU)集群上,訓(xùn)練需要分布式深度學(xué)習(xí)框架,才能在可接受的時(shí)間內(nèi)看到提升效果,大模型的訓(xùn)練如果沒(méi)有分布式深度學(xué)習(xí)框架支持,即使能投入大筆資金搭建大規(guī)模GPU集群也無(wú)濟(jì)于事。在模型和算力都如此快速增長(zhǎng)的情況下,深度學(xué)習(xí)框架如果不跟著一起發(fā)展的話,會(huì)限制算法研究的水平和迭代速度。
對(duì)深度學(xué)習(xí)框架,人工智能模型的要求是,在努力上進(jìn)的我身邊,有一個(gè)同樣努力上進(jìn)的你。
深度學(xué)習(xí)框架呼喚技術(shù)創(chuàng)新,再墨守成規(guī)就會(huì)被“甩”了。
無(wú)情未必真豪杰,那究竟是什么技術(shù)如此重要?
一個(gè)能打敗“內(nèi)存墻”的技術(shù)。
那內(nèi)存墻是什么呢?這個(gè)問(wèn)題的答案,有(hen)點(diǎn)(ke)長(zhǎng)(pu)。
早期深度學(xué)習(xí)模型,參數(shù)量小,一個(gè)GPU夠用。當(dāng)參數(shù)量變大,一個(gè)GPU不夠了,麻煩就來(lái)了。當(dāng)計(jì)算量相當(dāng)?shù)拇螅?xùn)練一個(gè)模型跑上十天半個(gè)月啥的是常事,分布式的意義就出現(xiàn)了。既然一張GPU卡跑得太慢就來(lái)兩張,一塊GPU芯片單獨(dú)處理不了,得多塊GPU。對(duì)某些深度學(xué)習(xí)應(yīng)用來(lái)說(shuō),比較容易實(shí)現(xiàn)“線性加速比”,投入多少倍的GPU資源就獲得多少倍加速效果。
只要砸錢,就能降低運(yùn)算時(shí)間,一切看上去,都還挺美好。
但是,現(xiàn)實(shí)扼住咽喉,把你從“美好”中搖醒。
超大模型對(duì)計(jì)算量的需求,百倍、千倍地提升,不僅超越了任何一類芯片(GPU)單獨(dú)處理的能力,而且即使砸錢堆了成百上千塊的GPU,對(duì)不起,加速比很低。投了一百倍資源,只有幾倍加速效果,甚至出現(xiàn)多個(gè)GPU比單個(gè)GPU還慢的情況。
為啥呢?
首先,深度學(xué)習(xí)是一種接近“流式”的計(jì)算模式,計(jì)算粒度變得很小,難把硬件跑滿。
傳統(tǒng)大數(shù)據(jù)處理多屬于批式計(jì)算,對(duì)全體數(shù)據(jù)掃描處理后才獲得結(jié)果。與此相反,深度學(xué)習(xí)訓(xùn)練是基于隨機(jī)梯度下降算法的,這是典型的流式計(jì)算,每掃描和處理一小部分?jǐn)?shù)據(jù)后,就開(kāi)始調(diào)整和更新內(nèi)部參數(shù)。
批式計(jì)算是,一次端過(guò)來(lái)一鍋,全部吃完。流式計(jì)算是,一次來(lái)一小碗。再不給大爺盛飯,就要停嘴了,嘴停,手就停。
一般,一個(gè)GPU處理一小塊數(shù)據(jù)只需要100毫秒的時(shí)間,那么問(wèn)題就成了,“調(diào)度”算法能否在100毫秒的時(shí)間內(nèi)為GPU處理下一小塊數(shù)據(jù)做好準(zhǔn)備。如果可以的話, GPU就會(huì)一直保持在運(yùn)算狀態(tài)。如果不可以,那么GPU就要間歇性地停頓,意味著設(shè)備利用率降低。
深度學(xué)習(xí)訓(xùn)練中的計(jì)算任務(wù)粒度非常小,通常是數(shù)十毫秒到百毫秒級(jí)別。換句話說(shuō),干活干得快,不趕緊給分派新的任務(wù),大爺就要歇著了。
總歇著,活肯定也干不快,工期長(zhǎng),急死人。
另一方面,深度學(xué)習(xí)使用的裝備太牛逼,不是GPU就是AI芯片,運(yùn)算速度非常快。
一塊GPU芯片單獨(dú)處理不了,單靠GPU這一類芯片也處理不了。通常是CPU和GPU一塊兒工作,CPU 負(fù)責(zé)任務(wù)的調(diào)度和管理,而GPU 負(fù)責(zé)實(shí)現(xiàn)計(jì)算(稠密),這就是經(jīng)常說(shuō)的異構(gòu)計(jì)算(Heterogenous computing)。
但是又有了新問(wèn)題,GPU 吞吐率非常高,可以是CPU的10倍以上,意味著同樣大小的計(jì)算任務(wù),GPU可以更快完成。GPU計(jì)算的時(shí)候,如果每次需要的數(shù)都從CPU或者從另外的GPU上拿,就把GPU也拖慢了。
CPU就好比一個(gè)吃飯比較慢的人,以前一大鍋可以吃很長(zhǎng)時(shí)間。GPU相當(dāng)于吃飯?zhí)貏e快的人,現(xiàn)在一次來(lái)一小碗,一口就吃下去了。所以,把碗端上桌的速度就非常關(guān)鍵。
CPU和GPU,異口同聲說(shuō):
“內(nèi)存墻,How are you(怎么是你)?”
模型太大,就需要把模型拆開(kāi)。比如說(shuō)神經(jīng)網(wǎng)絡(luò)前幾層拆在這個(gè)GPU上,后幾層拆在另一個(gè)GPU上,或者神經(jīng)網(wǎng)絡(luò)中某一層被切割到多個(gè)GPU上去了。
[怎么切割是一道超綱題,暫(wo)且(ye)不(bu)答(hui)。]
把數(shù)據(jù)或模型拆分之后,就需要多個(gè)GPU頻繁互動(dòng),互通有無(wú)。然而,漏屋偏逢連夜雨,設(shè)備互聯(lián)帶寬也不爭(zhēng)氣,沒(méi)有實(shí)質(zhì)改進(jìn),同機(jī)內(nèi)部PCIe或多機(jī)互聯(lián)使用的高速網(wǎng)的傳輸帶寬,要低于GPU內(nèi)部數(shù)據(jù)帶寬一兩個(gè)數(shù)量級(jí)。
可以用計(jì)算和數(shù)據(jù)傳輸之間的比例來(lái)衡量“內(nèi)存墻“的壓力有多大。計(jì)算機(jī)系統(tǒng)理論上恰好有一個(gè)叫運(yùn)算強(qiáng)度(Arithmetic intensity)的概念可以刻畫,說(shuō)洋氣一點(diǎn),flops perbyte,表示一個(gè)字節(jié)的數(shù)據(jù)上發(fā)生的運(yùn)算量。
只要這個(gè)運(yùn)算量足夠大,傳輸一個(gè)字節(jié)可以消耗足夠多的計(jì)算量,那么即使設(shè)備間傳輸帶寬低于設(shè)備內(nèi)部帶寬,也有可能使得設(shè)備處于滿負(fù)荷狀態(tài)。
進(jìn)一步,如果采用比GPU更快的芯片,處理一小塊兒數(shù)據(jù)的時(shí)間就比100毫秒更低,比如10毫秒,帶寬不變,“調(diào)配”算法能用10毫秒的時(shí)間為下一次計(jì)算做好準(zhǔn)備嗎?事實(shí)上,即使是使用不那么快(相對(duì)于TPU 等專用芯片)的GPU,當(dāng)前主流的深度學(xué)習(xí)框架對(duì)模型并行已經(jīng)力不從心了。
CPU和GPU,仰天長(zhǎng)嘯:
“內(nèi)存墻,How old are you(怎么老是你)?”
“內(nèi)存墻”帶來(lái)巨大壓力,處理不好,就會(huì)造成設(shè)備利用率低、整體系統(tǒng)性能差的后果。
理論上,訓(xùn)練框架與硬件平臺(tái)耦合程度相對(duì)較高,深度學(xué)習(xí)框架需要基于異構(gòu)硬件支持訓(xùn)練超大規(guī)模數(shù)據(jù)或模型,分布式訓(xùn)練的實(shí)際性能高度依賴底層硬件的使用效率。換句話說(shuō),解決這個(gè)問(wèn)題,得靠深度學(xué)習(xí)框架。
內(nèi)存墻,得解決。沒(méi)辦法,誰(shuí)讓深度學(xué)習(xí)框架處在上接算法、下接芯片的位子上,在技術(shù)江湖里的卡位很關(guān)鍵。
袁博士在“內(nèi)存墻”上,用白漆畫了個(gè)大圈,寫下一個(gè)大大的“拆”字。
他認(rèn)為,這是深度學(xué)習(xí)框架最應(yīng)該解決的問(wèn)題。人生在世,錢能解決絕大多數(shù)問(wèn)題;但是,不能解決的少數(shù)問(wèn)題,才是根本性的問(wèn)題。訓(xùn)練超大人工智能模型,有錢就能買硬件,但要有技術(shù),才能把硬件用好。
道理,很簡(jiǎn)單。
現(xiàn)實(shí),很殘酷。
“國(guó)內(nèi)深度學(xué)習(xí)框架發(fā)展水平并不落后,有多家公司開(kāi)源了水準(zhǔn)很高的,這些夠用了嗎?”
袁博士答道:“現(xiàn)有開(kāi)源框架直接拿過(guò)來(lái),真是做不了大模型這事兒,尤其參數(shù)量上到GPT-3模型這個(gè)級(jí)別的時(shí)候。
深度學(xué)習(xí)模型進(jìn)入到現(xiàn)在這個(gè)階段,大規(guī)模帶來(lái)的問(wèn)題,僅靠開(kāi)源的深度學(xué)習(xí)框架已經(jīng)有點(diǎn)吃力了。已有開(kāi)源分布式深度學(xué)習(xí)框架無(wú)論使用多大規(guī)模的GPU集群,都需要漫長(zhǎng)的時(shí)間(幾個(gè)月以上)才能訓(xùn)練完成,時(shí)間和人力成本極高。
弱者坐失時(shí)機(jī),強(qiáng)者制造時(shí)機(jī)。
“在開(kāi)源版本上修改,能否滿足工業(yè)級(jí)的用途?”
袁博士回答道:“現(xiàn)在市面上的深度學(xué)習(xí)框架,有選擇的余地,但當(dāng)前在某些場(chǎng)景(比如,模型并行)改造和定制也力不從心。就比如綠巨人GPT-3這件事兒,直接把現(xiàn)有開(kāi)源深度學(xué)習(xí)框架拿來(lái)是搞不定的,OpenAI實(shí)驗(yàn)室對(duì)開(kāi)源框架做了深度定制和優(yōu)化,才可能在可接受的時(shí)間內(nèi)把這個(gè)實(shí)驗(yàn)完整跑下來(lái)。”
一般人,只看到了模型開(kāi)銷的昂貴,沒(méi)有看到技術(shù)上的難度。
“單個(gè)芯片或單個(gè)服務(wù)器無(wú)法滿足訓(xùn)練大模型的需求,這就是所謂的Silicon Scaling的局限性。為解決這個(gè)難題,我們必須使用橫向擴(kuò)展的方法,通過(guò)高速互聯(lián)手段把多個(gè)服務(wù)器連在一起形成計(jì)算資源池,使用深度學(xué)習(xí)框架等分布式軟件來(lái)協(xié)同離散耦合的多個(gè)加速器一起高效工作,從而提高計(jì)算力的上限。”
袁博士繼續(xù)解釋。
袁博士還特別介紹了解決這個(gè)問(wèn)題對(duì)人才的要求,他說(shuō):“改造深度學(xué)習(xí)框架,是一件困難的事。從團(tuán)隊(duì)方面來(lái)說(shuō),算法工程師難招聘,有計(jì)算機(jī)系統(tǒng)理論背景或者工程能力到位,又懂算法的工程師更難找。挖人也不解決問(wèn)題。一位算法工程師挖走了,算法的巧思之處被帶走了。但是,深度學(xué)習(xí)框架得把差不多整個(gè)團(tuán)隊(duì)挖走,才夠用。”
“超大模型不是今天才有,也不是今天才被人注意到,而是一直以來(lái)就有這個(gè)趨勢(shì)。有遠(yuǎn)見(jiàn)的人,較早就能看到趨勢(shì)。最先發(fā)現(xiàn)個(gè)趨勢(shì)和最先準(zhǔn)備的人,最有機(jī)會(huì)。”
“很多深度學(xué)習(xí)框架剛開(kāi)始研發(fā)的時(shí)候都沒(méi)有瞄準(zhǔn)這種問(wèn)題,或者說(shuō)沒(méi)有看到這個(gè)問(wèn)題。深度學(xué)習(xí)框架沒(méi)有完成的作業(yè),就要留給算法團(tuán)隊(duì)去做,考驗(yàn)算法公司技術(shù)團(tuán)隊(duì)對(duì)深度學(xué)習(xí)框架的改進(jìn)能力。市面上的情況是,極少數(shù)企業(yè)搞得定,大多數(shù)企業(yè)搞不定。”
聊了很久,我拋出最后一個(gè)問(wèn)題。
“GPT-3模型在企業(yè)業(yè)務(wù)里用不到,很多人覺(jué)得無(wú)用,實(shí)驗(yàn)室的玩意而已,其科學(xué)意義是什么呢?”
他笑了笑,用一貫低沉的聲音說(shuō)道:“GPT-3模型說(shuō)明,OpenAI實(shí)驗(yàn)室很有科學(xué)洞見(jiàn),不是人人都能想到往那個(gè)方向去探索,他們的背后有一種科學(xué)理念支持。思考大模型的時(shí)候,有一種假設(shè)(hypothesis)的方法論,當(dāng)假設(shè)成立,能夠解決與之相對(duì)應(yīng)的科學(xué)問(wèn)題。在這個(gè)方法論的指導(dǎo)下,勇于探索,肯定不是莫名其妙的一拍腦袋就花千萬(wàn)級(jí)別的美金往超大模型的方向上魯莽的冒險(xiǎn)。”
袁進(jìn)輝把人工智能和人腦做了一個(gè)比較。
他說(shuō)道:
“人類的大腦與我們現(xiàn)在的人工智能自然語(yǔ)言處理模型進(jìn)行比較:人類大腦有100萬(wàn)億個(gè)突觸,這比最大的人工智能模型還要大三個(gè)數(shù)量級(jí)。這個(gè)人工智能模型,名叫GPT-3,幾乎通過(guò)圖靈測(cè)試了。一直以來(lái),科研團(tuán)隊(duì)都在尋找‘能正常工作’的聊天機(jī)器人,這個(gè)模型讓人看到了突破口。”
他在思考,當(dāng)真正實(shí)現(xiàn)了具有百萬(wàn)億參數(shù)的神經(jīng)網(wǎng)絡(luò)時(shí),今天人工智能和深度學(xué)習(xí)模型面臨的困難會(huì)不會(huì)就迎刃而解了呢?機(jī)器人進(jìn)行真正智能對(duì)話的日子是不是就快到來(lái)了?
說(shuō)到這里,他眼神中閃過(guò)一絲亮光。
在袁進(jìn)輝看來(lái),這種里程碑式的突破,通常需要杰出團(tuán)隊(duì)才能取得。OpenAI想到了,也做到了。它代表了這方面全球的最高水平,探索了能力的邊界,拓展了人類的想象力。就像飛船飛往宇宙的最遠(yuǎn)處,觸摸到了人工智能模型參數(shù)量增長(zhǎng)的邊界。
這種模型的問(wèn)世,就像航天界“發(fā)射火箭”一樣,成本高,工程要求也高。他們的成功,既實(shí)現(xiàn)了理論上的意義,也實(shí)現(xiàn)了工程上的意義。
人工智能的希望,在路上。
無(wú)論實(shí)驗(yàn)怎么苦惱,
無(wú)論效果如何不濟(jì),
GPT-3模型始終是人類邁向“智能”的無(wú)盡長(zhǎng)階上的一級(jí)。
沒(méi)有偉大的愿景,就沒(méi)有偉大的洞見(jiàn)。
沒(méi)有偉大的奮斗,就沒(méi)有偉大的工程。
-
算法
+關(guān)注
關(guān)注
23文章
4608瀏覽量
92844 -
人工智能
+關(guān)注
關(guān)注
1791文章
47207瀏覽量
238280 -
模型
+關(guān)注
關(guān)注
1文章
3229瀏覽量
48811
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論