 干貨:一些Python有用的小技巧,離精通更進一步
干貨:一些Python有用的小技巧,離精通更進一步
Python看起來似乎是一種任何人都可以學習的簡單語言,但實際上,學會不等于精通,Python的“后勁兒”超乎我們的想象,它容易入門卻很難掌握。在Python中,一個通常有多種處理方法,但很容易出錯的地方很多;或者僅僅因為不知道模塊的存在,你就得重新創建標準庫,這很浪費時間。
Python標準庫是一個巨大的野獸,它的生態系統絕對是龐大的。雖然Python模塊可能有200萬千兆字節,好在有一些使用技巧存在,我們可以用Python中與科學計算相關的標準庫和包來學習。
1.反轉字符串
雖然看似是很基礎的操作,但是用char循環來反轉字符串可能會非常繁瑣麻煩。幸運的是,Python包含了一個簡單的內置操作來準確地執行這個任務,我們只需訪問字符串上的索引::-1。
a = “!dlrow olleH”
backward = a[::-1]

2.Dims作為變量
在大多數語言中,為了將數組放入一組變量中需迭代循環值,或按位置訪問暗點,如下所示:
firstdim = array[1]
然而,在Python中有一種更好更快的方法。為了將一列值改為變量,可以簡單地將變量名設置為與數組長度相同的數組:
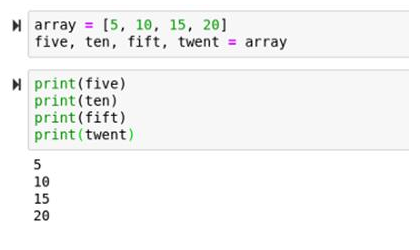
array = [5, 10, 15, 20]
five, ten, fift, twent = array
3.生成器的next()迭代
在編程中的大多數正常情況下,可以訪問一個索引,并使用計數器獲取位置數字,計數器將只是一個值,添加到:
array1 = [5, 10, 15, 20]
array2 = (x ** 2 for x in range(10))
counter = 0for i in array1:# This code wouldn‘t work because ’i‘ is not in array2.
# i = array2[i]
i = array2[counter]
# ^^^ This code would because we areaccessing the position of i
我們也可以用next()代替它。Next使用一個迭代器,該迭代器將當前位置存儲在內存中,并在后臺迭代列表:
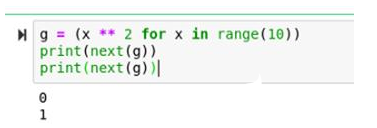
g = (x ** 2 for x in range(10))
print(next(g))
print(next(g))
4.智能拆包
迭代地解壓值可能會非常耗費時力,Python中有幾種不錯的方法可以用來解壓列表的方法。其中一個是*,它將填充未分配的值并將它們添加到變量名下的新列表中。
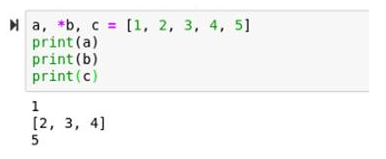
a, *b, c = [1, 2, 3, 4, 5]
5.列舉
不了解列舉那可不太行。列舉可以獲取列表中某些值的索引,在數據科學中使用數組而不是數據幀時,這就特別有用:
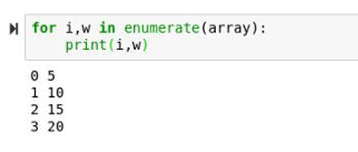
for i,w in enumerate(array):
print(i,w)
6.命名切片
Python中,分割列表非常簡單,各式各樣優秀工具都能做到。特別好的一點是,它還能夠給列表命名,這對于Python中的線性代數特別有用:
a = [0, 1, 2, 3, 4, 5]
LASTTHREE = slice(-3, None)
slice(-3, None, None)
print(a[LASTTHREE])

7.Itertools
如果深入學習Python,那你肯定要熟悉itertools。itertools是標準庫中的一個模塊,它可以不斷地解決迭代問題。它不僅使編寫復雜循環大幅度變容易,而且還使代碼更簡潔快速。有數百種Itertools的使用示例,來看看其中一個:
c = [[1, 2], [3, 4], [5, 6]]
# Let’s convert this matrix to a 1 dimensional list.
import itertools as it
newlist = list(it.chain.from_iterable(c))
8.分組相鄰列表
在for循環中,對相鄰循環進行分組當然很容易,特別是使用zip(),但這肯定不是最好的方法。為了更輕松便捷地實現這一點,可以用zip編寫一個lambda表達式,該表達式將對相鄰列表進行分組,如下所示:
a = [1, 2, 3, 4, 5, 6]
group_adjacent = lambda a, k: zip(*([iter(a)] * k))
group_adjacent(a, 3) [(1, 2, 3), (4, 5, 6)]
group_adjacent(a, 2) [(1, 2), (3, 4), (5, 6)]
group_adjacent(a, 1)
9.計數器
集合也是模塊中很好的標準庫,這里向大家介紹的是集合中的計數器。使用計數器,可以輕松獲得一個列表的計數。這對于獲取數據中的值總數、數據的空計數,以及查看數據的唯一值非常有用。
“為什么不直接使用Pandas呢?”使用Pandas來實現這一點無疑會困難得多,而且這只是在部署算法時需要添加到虛擬環境中的另一個依賴項。另外,Python中的計數器類型有很多Pandas系列沒有的特性,這使其在某些情況下更有用。
A = collections.Counter([1, 1, 2,2, 3, 3, 3, 3, 4, 5, 6, 7])
A Counter({3: 4, 1: 2, 2: 2, 4: 1, 5: 1, 6: 1, 7: 1})
A.most_common(1) [(3, 4)]
A.most_common(3) [(3, 4), (1, 2), (2, 2)]
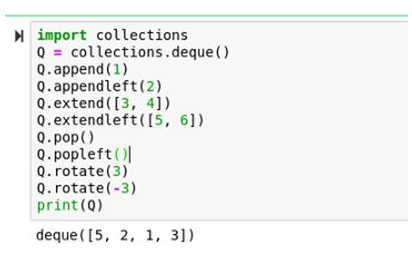
10.出隊
如下所示,出隊能讓代碼非常整潔:
import collections
Q = collections.deque()
Q.append(1)
Q.appendleft(2)
Q.extend([3, 4])
Q.extendleft([5, 6])
Q.pop()
Q.popleft()
Q.rotate(3)
Q.rotate(-3)
print(Q)
這些是筆者一直愛用的Python技巧,都非常通用和實用,實踐中總有機會能用到。Python的標準庫函數工具箱變得越來越多樣,還有很多筆者也沒聽說過的工具。學無止境,這多么令人興奮!
-
字符串
+關注
關注
1文章
578瀏覽量
20506 -
python
+關注
關注
56文章
4792瀏覽量
84627 -
標準庫
+關注
關注
0文章
31瀏覽量
7432
發布評論請先 登錄
相關推薦
【OK210申請】嵌入式進一步學習(想試著做個簡單的平板玩玩)
E4406A達到adc對齊時不會更進一步了
進一步提高UPS電源的可靠性
天齊鋰業年產2萬噸碳酸鋰工廠項目的實施 離2020年實現10萬噸目標更進一步
如何從工業4.0更進一步轉向工業5.0?
Oculus Quest VR頭盔獲得FCC認證 意味著距離上市更進一步
縮短交互路徑 智能家居產品或者全屋智能的體驗將更進一步
智能家居交互方向或是無感化 全屋智能的體驗將更進一步
華為推出新功能,鴻蒙系統將更進一步
Type-C接口需求的增加,使得USB PD實現進一步擴增
更進一步學習MySQL


榮耀Magic4系列3月17日發布會,隱私保護更進一步






 工商網監
工商網監
評論