 由淺入深的一步步迭代出無鎖隊列的實現原理
由淺入深的一步步迭代出無鎖隊列的實現原理
這篇長文除了由淺入深的一步步迭代出無鎖隊列的實現原理,也會借此說說如何在項目中注意避免寫出有 BUG 的程序,與此同時也會簡單聊聊如何測試一段代碼,而這些能力應該是所有軟件開發工作者都應該引起注意的。而在介紹的過程中也會讓你明白理論和實際的差距到底在哪。
高級程序員和初級程序員之間,魚鷹認為差距之一就在于寫出來的代碼 BUG 多還是少,當然解決 BUG 的能力也很重要。
既要有挖坑的能力,也要有填坑的實力!
很早之前魚鷹就聽說過無鎖隊列,但由于以前的項目不是很復雜,很多時候都可以不需要無鎖隊列,所以就沒有更深入的學習,直到這次串口通信想試試無鎖隊列的效果,才最終用上了這一神奇的代碼。
網上有個詞形容無鎖隊列魚鷹覺得很貼切:巧奪天工!
現在就從隊列開始說起吧。
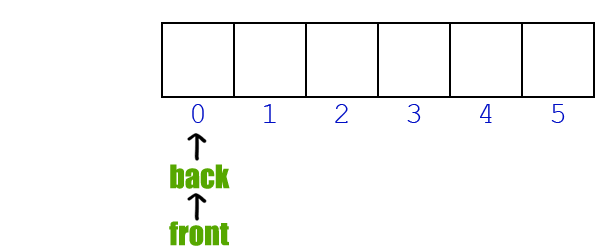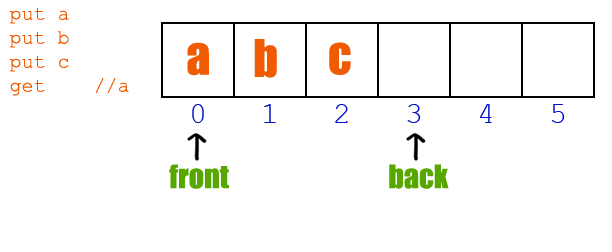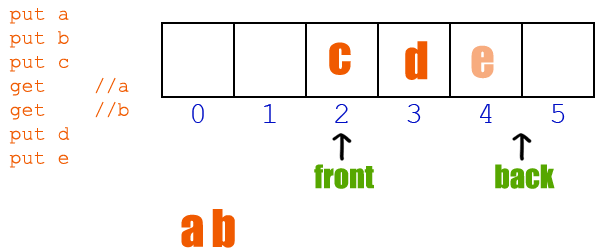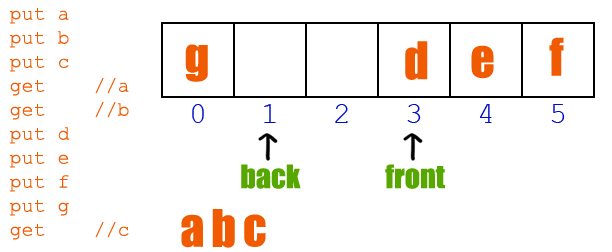
什么是隊列,顧名思義,就類似于超市面前排起的一個隊伍,當最前面的顧客買完了東西,后面的顧客整體向前移動,而處于新隊頭的顧客繼續消費。如果沒有后來的顧客,那么最終這個隊伍將消失。而如果有新的顧客到來,那么他將排在隊伍最后等待購買。
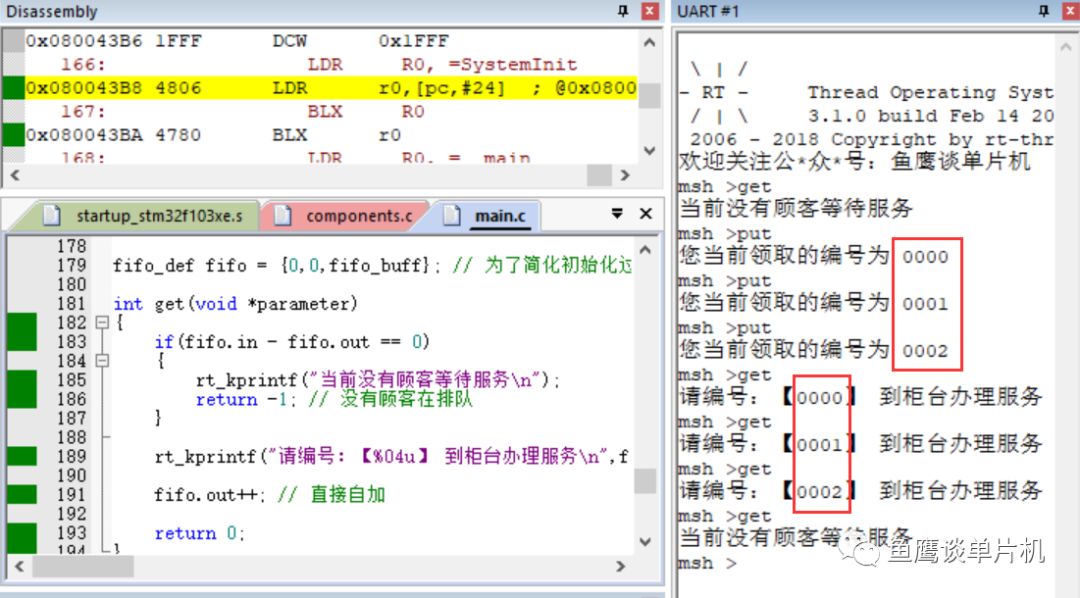
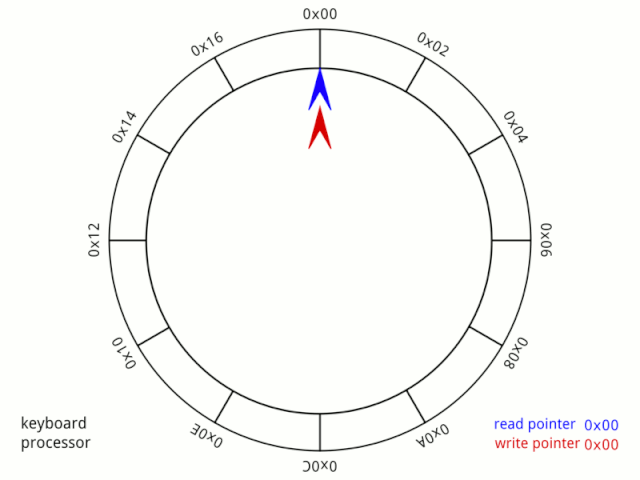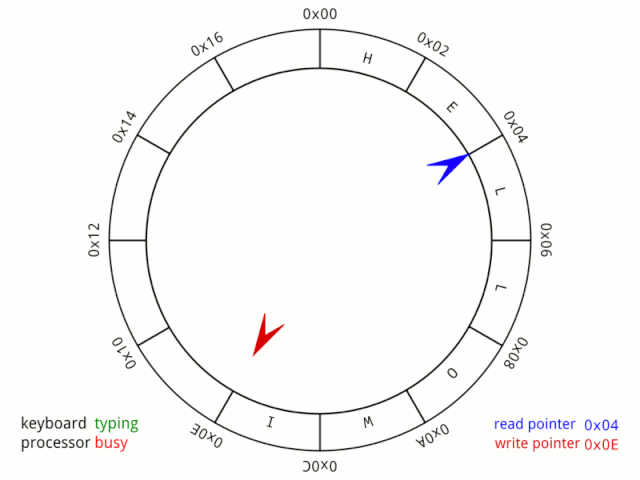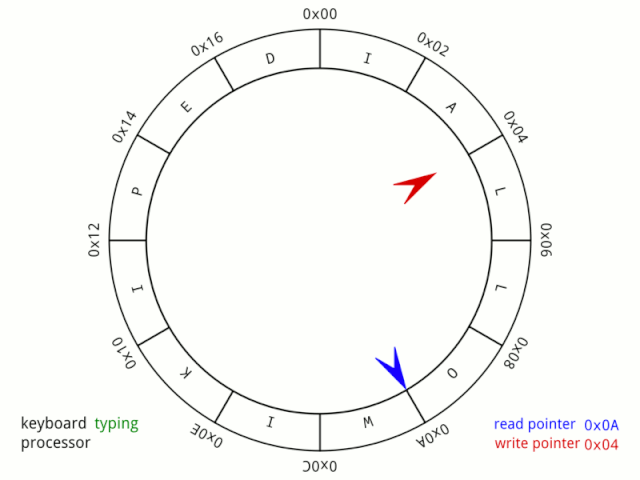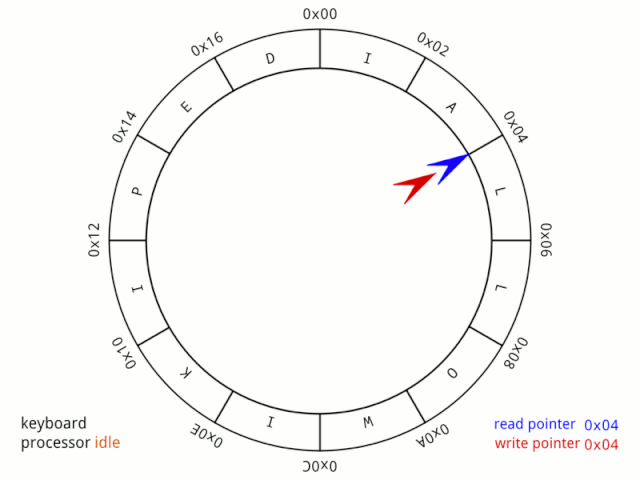
(忽略后面那個搗蛋的你) 對于顧客隊伍來說,消費者,在這里其實是超市(不是顧客),因為它讓這個隊伍越來越短,直至消失;而生產者,在這個模型中無法看到,只能說是市場需求導致隊伍越來越長。 如果對此較難理解的話,不如說說目前口罩購買情況。 如果市場上所有的口罩會自動排隊的話,那么購買口罩的人就是口罩隊伍的消費者,而生產口罩的廠家就是生產者。因為廠家生產的少,而購買者多,所以才會出現供不應求的情況,而一旦廠家產能上來了,供需就能平衡,而這種平衡不僅是市場需要的,也是軟件所追求的目標。 說回超市模型,如果我們用軟件模擬這種排隊情況,應該怎么做呢? 聲明一個足夠大的數組,后面來的數據(顧客)總是放在最后面,一旦有程序取用了數據,那么整體向前移動,后面來的數據繼續放在最后。(這里需要一個變量指示隊伍的長度,畢竟不是真實的排隊場景,無法直接從隊伍本身看出哪里是隊尾)。 這樣確實很好的模擬了現實中的情況,但對于軟件來說,效率太低! 對于顧客而言,所有的顧客每次前進一小步,感覺好像沒什么,也很正常,畢竟最終等待的時間還是一樣的,但是每隔一小段時間就要動一動,還是挺麻煩的事情。 而對于程序而言,不僅僅是移動數據需要耗費CPU,更重要的是在移動過程中,如何保證“消費者”能正確提取數據,“生產者”能正確插入數據。畢竟你在移動數據的過程中有可能消費者需要消費數據,而生產者需要生成數據,如何進行同步呢? 那么是否有更好的方式呢? 現實其實已經給了我們答案。 不知道你是否發現一個現象,銀行里面一排排的椅子上坐滿了人,但是銀行窗口前卻沒有了長長的隊伍?這是怎么回事?為什么那些人不再排隊了,他們不怕有人插隊嗎? 當你親自體驗了之后就知道,沒人會插你的隊,為什么? 當你走進銀行時,服務員會提醒你去一臺機器前領取一個紙質號碼,然后就請你在座位上等著。 等了一會,銀行內廣播開始播報“9527,請到2號柜臺辦理業務”,你一聽,這不就是自己剛領的號嘛,所以你馬上就到窗口前辦理需要的業務了。 那么這是如何實現的?為什么你不再需要站著排隊了,也不需要一點一點的向前挪動,而是一直坐著就把隊給排了? 這個關鍵就在那臺機器。 每來一個人領取號碼,機器就把當前的計數值給顧客,然后增加當前的計數,作為下一位顧客使用的號碼;而每當銀行柜員服務完一位顧客,機器就會自動播報本次已服務對象號碼的下一個號碼前來辦理業務,并自加另一個計數值,作為下一次辦理業務的對象。而當兩計數器值相等時,就代表該柜員完成了所有顧客的服務。 所以,不是沒有排隊,而是機器在幫你排隊。 那么這種機制在程序中該如何實現呢? 在這里我們先假設只有一個柜臺能辦理業務(實際銀行是有多個柜臺,這里暫時不考慮那么復雜),一個機器為顧客發放編號。 首先需要兩個變量充當機器的職能: in:初始化為 0,當來了顧客,將當前值發給客戶,然后自動加 1 out:初始化為 0,當柜員需要請求下一位顧客前來服務時,服務顧客編號為當前值,然后自動加 1 因為紙條上可展示的位數是有限的,所以我們可以先假設為4位數,即兩個變量值范圍是0~9999(還好STM32F103 RAM內存足夠)。 然后需要一個元素容量為10000大數組,存放目前排隊顧客的編號,因為數組中存放的是0~9999的編號,所以數組的聲明采用uint16_t 進行聲明,這樣才能把編號存放在數組單元中。 現在看代碼(RT-Thread系統):
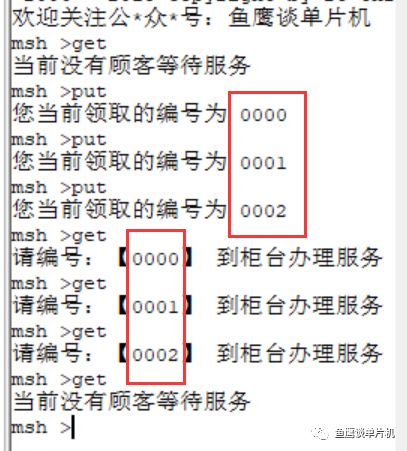
// 魚鷹*公***眾**號:魚鷹談單片機,uint16_t queue[10000]; // 隊列,0~9999,共 10000 uint16_t in;uint16_t out; int get(void *parameter){ if(in == out) { rt_kprintf("當前沒有顧客等待服務 "); return -1; // 沒有顧客在排隊 } rt_kprintf("請編號:【%04u】 到柜臺辦理服務 ",queue[out]); // 自加 1 ,但因為數組只有 10000 大小,所以需要讓 out 在 0~9999 之間進行循環 out = (out + 1) % 10000; return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); int put(void){ if((in + 1) % 10000 == out) { // 因為 in 和 out 值相等時,可能為空和滿的,無法判斷哪種情況 // 所以為了避免這種情況,總是空一個位置,這樣滿的時候 in 和 out 的值就不一樣 rt_kprintf("現在排隊人數太多,請下次嘗試 "); return -1; // 隊列滿 } // 把當前的編號存入數組中進行排隊 rt_kprintf("您當前領取的編號為 %04u ",in); queue[in] = in; // 自加 1 ,但因為數組只有 10000 大小,所以需要讓 in 在 0~9999 之間進行循環 in = (in + 1) % 10000; return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample);(滑動查看全部) 現在假設柜員剛開始上班,他不清楚有沒有顧客等待服務,所以他首先使用 get函數獲取自己的服務顧客編號,但是因為柜員來的有點早,顧客還沒來銀行辦理業務,所以第一次機器告訴柜員沒有顧客等待服務。

后來陸續來了三位顧客,柜員再一次獲取時,編號為 0 的顧客開始前來辦理業務,柜員服務完之后,接著繼續把剩下兩位的業務都辦理完成,第四次獲取時,柜員發現沒有顧客等待了,所以柜員可以休息一下(實際情況是,柜員前應該有顯示當前排隊人數,當排隊人數為 0 時,就不會去使用 get 函數了)
V 1.0
雖然可顯示的位數為四位數,有可能出現一天共有9999位顧客需要辦理服務,但事實上同一時刻不可能有那么多人同時在銀行排隊辦理業務,所以為了節約空間,有必要縮小數組空間。 假設一次排隊最多同時有99位顧客需要業務,那么數組設置為 100(為什么多一個?)。 但是因為一天之中總共可能有超過 99 位顧客辦理業務,那么直接使用in作為顧客編號肯定不合適,因為in的范圍是0~99,那么必然需要另一個變量用于記錄當天的總人數,這里假設為counter(當你修改代碼時,你會發現把之前的 10000 設置為宏是明智的選擇)。 這里除了修改數組大小和put函數外,其他都一樣:
// 測試代碼 V1.0// 魚鷹*公***眾**號:魚鷹談單片機,#define BUFF_SIZE 100uint16_t queue[BUFF_SIZE]; // 隊列,0~99,共 100 uint16_t in;uint16_t out;uint16_t counter; // 記錄 int get(void *parameter){ if(in == out) { rt_kprintf("當前沒有顧客等待服務 "); return -1; // 沒有顧客在排隊 } rt_kprintf("請編號:【%04u】 到柜臺辦理服務 ",queue[out]); // 自加 1 ,但因為數組只有 100 大小,所以需要讓 out 在 0~99 之間進行循環 out = (out + 1) % BUFF_SIZE; return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); int put(void){ if((in + 1) % BUFF_SIZE == out) { // 因為 in 和 out 值相等時,可能為空和滿的,無法判斷哪種情況 // 所以為了避免這種情況,總是空一個位置,這樣滿的時候 in 和 out 的值就不一樣 rt_kprintf("現在排隊人數太多,請下次嘗試 "); return -1; // 隊列滿 } // 把當前的編號存入數組中進行排隊 rt_kprintf("您當前領取的編號為 %04u ",counter); queue[in] = counter; counter = (counter + 1) % 10000; // 限制它的大小,不可超過四位數 // 自加 1 ,但因為數組只有 100 大小,所以需要讓 in 在 0~99 之間進行循環 in = (in + 1) % BUFF_SIZE; return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample);(滑動查看全部) 再次測試:
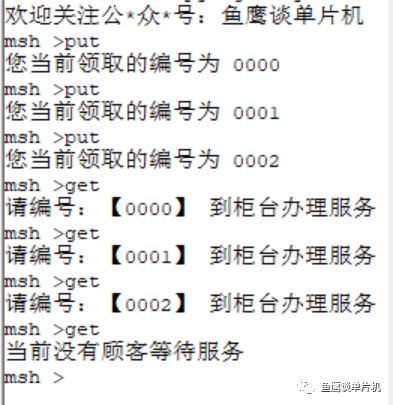
你會發現,雖然修改了數組大小,但是只要不會出現同時超過100人來銀行排隊,那么和之前的效果是一樣的,這樣一來,大大降低了內存空間使用。 這里展示的效果其實和《數據結構系列文章之隊列 FIFO》寫的類似了,這里魚鷹定為V1.0吧(對,前面那個版本連V1.x都算不上,因為太耗空間了)。 那么魚鷹繼續寫另一種處理方式,稱之為V1.5吧。
V 1.5
雖然因為一個神奇的取余公式,可以讓一個數始終在某一個范圍內變化,但這也帶來非常一個明顯的問題,那就是始終不能把隊列真正填滿。
雖然只是空閑了一個元素,但是對于喜歡追求極致的人來說,這也是不可忍受的事情,所以是否有好的辦法利用所有隊列空間呢? 這里再加入一個變量,實時跟蹤隊列長度,代碼如下:
// 測試代碼 V1.5// 魚鷹*公***眾**號:魚鷹談單片機#define BUFF_SIZE 7 typedef struct { uint16_t queue[BUFF_SIZE]; // 隊列,0~99,共 100 uint16_t in; uint16_t out; uint16_t used;}fifo_def; // 把隊列相關的變量整合在一塊,方便使用 uint16_t counter; // 記錄 fifo_def fifo; int get(void *parameter){ if(fifo.used == 0) { rt_kprintf("當前沒有顧客等待服務 "); return -1; // 沒有顧客在排隊 } rt_kprintf("請編號:【%04u】 到柜臺辦理服務 ",fifo.queue[fifo.out]); // 自加 1 ,但因為數組只有 100 大小,所以需要讓 out 在 0~99 之間進行循環 fifo.out = (fifo.out + 1) % BUFF_SIZE; fifo.used--; return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); // 導出到命令行中使用 int put(void){ if(fifo.used >= BUFF_SIZE) { // 因為 in 和 out 值相等時,可能為空和滿的,無法判斷哪種情況 // 所以為了避免這種情況,總是空一個位置,這樣滿的時候 in 和 out 的值就不一樣 rt_kprintf("現在排隊人數太多,請下次嘗試 "); return -1; // 隊列滿 } // 把當前的編號存入數組中進行排隊 rt_kprintf("您當前領取的編號為 %04u ",counter); fifo.queue[fifo.in] = counter; counter = (counter + 1) % 10000; // 限制它的大小,不可超過四位數 // 自加 1 ,但因為數組只有 100 大小,所以需要讓 in 在 0~99 之間進行循環 fifo.in = (fifo.in + 1) % BUFF_SIZE; fifo.used++; return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample);在這個版本中,魚鷹將隊列所需的元素整合成一個結構體方便使用(當需要增加一個隊列時,顯得比較方便),并加入一個used變量,還縮小了隊列大小,變成7,方便我們關注隊列最本質的東西。 測試如下:
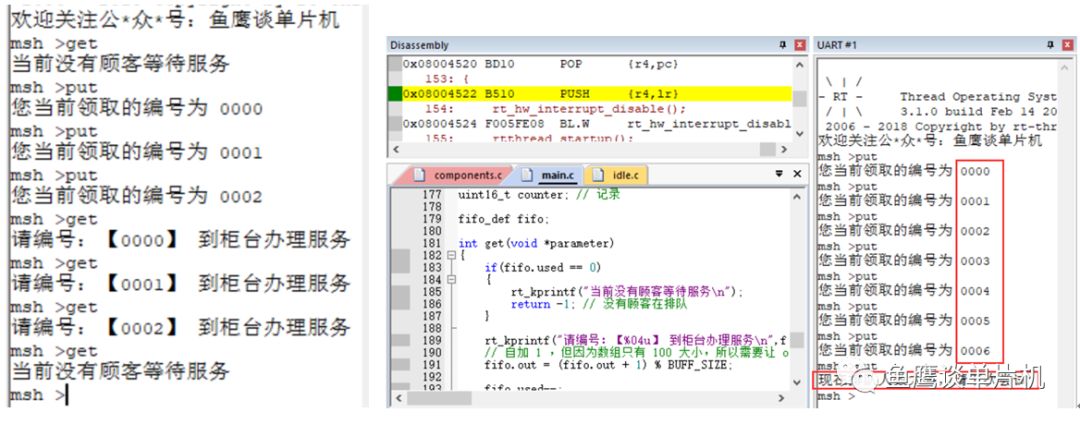
因為增加了一個變量,所以可以完整利用所有空間,但是是否有更好的方式呢? 有的,就是今天的主角,無鎖隊列。
V 2.0
這還不是無鎖隊列的最終形態,而是一個初版,但已經是無鎖隊列中最核心的內容了,也是實現無鎖隊列的關鍵,定為V2.0。 測試代碼:
// 測試代碼 V2.0// 魚鷹*公***眾**號:魚鷹談單片機#define BUFF_SIZE 8 // 文章說的是 7,但是這是不能用的,只能為 2 的冪次方 typedef struct { uint32_t in; // 注意,這里是 32 位 uint32_t out; // 注意,這里是 32 位 uint8_t *queue; // 這里不再指定大小,而是根據實際情況設置緩存大小}fifo_def; // 把隊列相關的變量整合在一塊,方便使用 uint8_t counter; // 記錄人數,也是發放的編號,因為隊列類型變了,所以這里也改成 uint8_tuint8_t fifo_buff[BUFF_SIZE]; fifo_def fifo = {0,0,fifo_buff}; // 為了簡化初始化過程,直接定義時初始化 int get(void *parameter){ if(fifo.in - fifo.out == 0) { // 也可以寫成 fifo.in == fifo.out,效率或許會高一些 rt_kprintf("當前沒有顧客等待服務 "); return -1; // 沒有顧客在排隊 } rt_kprintf("請編號:【%04u】 到柜臺辦理服務 ",fifo.queue[fifo.out % BUFF_SIZE]); fifo.out++; // 直接自加 return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); // 導出到命令行中使用 int put(void){ if(BUFF_SIZE-fifo.in+fifo.out==0) { rt_kprintf("現在排隊人數太多,請下次嘗試 "); return -1; // 隊列滿 } // 把當前的編號存入數組中進行排隊 rt_kprintf("您當前領取的編號為 %04u ",counter); fifo.queue[fifo.in % BUFF_SIZE] = counter; // 這里用 fifo.in % (BUFF_SIZE - 1) 效率會高一些 counter += 1; // 遞增計數器 fifo.in++; // 直接自加 return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample);
這里最難理解的部分應該是兩個判斷:
if(BUFF_SIZE - (fifo.in - fifo.out) == 0) { rt_kprintf("現在排隊人數太多,請下次嘗試 "); return -1; // 隊列滿 } if(fifo.in - fifo.out == 0) { // 也可以寫成 fifo.in == fifo.out,效率或許會高一些 rt_kprintf("當前沒有顧客等待服務 "); return -1; // 沒有顧客在排隊 }還有兩個不可以思議的自加操作:
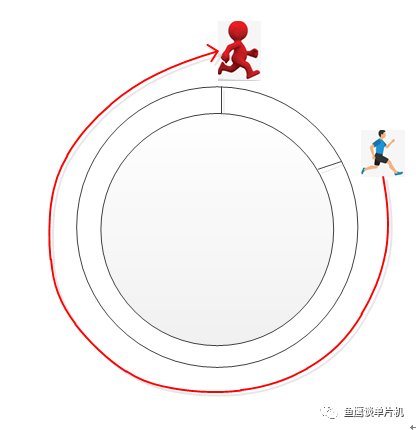
fifo.in++; // 直接自加 fifo.out++; // 直接自加現在先說第一個簡單的,為什么in和out相等了,就代表為空? 先看一個動圖(公**眾&&號可查看):
我們可以這樣理解,小紅、小藍兩個人在一個環形操場跑步,在起步時,兩個人的位置一樣,但跑了一段時間時,兩人位置不同了,因為小紅跑的快,所以總在小藍前面,但他們是好朋友,所以小紅總是在跑了一段時間后停下來等小藍。 雖然小藍跑的慢,但因為小紅的等待,所以每次追上小紅處于同一個位置時,都可以認他們又處于起步階段,就好像他們從來沒有動過。 也就是說in和out相等時,就可以認為隊列為空。 那么第二個判斷該怎么理解? 這個說實話,魚鷹不知道該如何說明,只能強行解釋一波了(說笑的,不過確實很難說清楚)。 首先這個公式需要簡單變換一下:
BUFF_SIZE - (fifo.in - fifo.out)內括號里面的其實就是《延時功能進化論》中說的那個神奇的算式。 這個算式總是能準確in和out之間的差值(不管是in大于out還是小于),也就是隊列中已使用了的空間大小,當然這是有條件的。 想象一下這樣一個場景,小紅不再等待小藍,而是一口氣跑下去,當小紅再次接近小藍時,你會發現小紅看到的是小藍的后背,也就是說,從表象來看,小藍跑到小紅的前面了。 但是群眾的眼光是雪亮的,他們知道小紅其實是跑在小藍的前面的,所以按小紅在小藍前面這種情況用尺子量一下兩者就能準確知道兩者的距離。
我們現在繼續分析,因為小紅跑太快了,它超越了小藍!
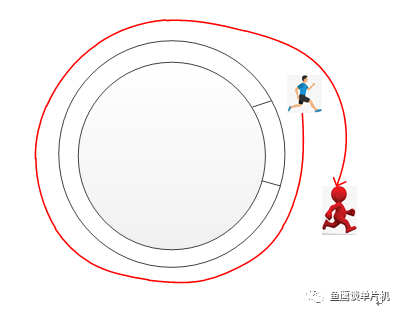
雖然觀眾還是可以通過尺子進行距離測量,但是如果單從操場絕對位置(假設操場上有距離刻度)的角度來看,已經無法準確計算他們的距離了(當然如果能記錄小紅超越小藍的次數,那還是可以計算的,現在按下不表)。 所以如果把 in 當成小紅操場所在的刻度信息,out當成小藍的操場刻度信息,那么兩者 in 減 out 就是他們的距離信息(當然了,這里利用了變量溢出的特性才能準確計算,關于這個可以看《運算符 % 的妙用》)。 上面動圖的隊列空間是0x18,即24,如果我們把這個隊列空間增大,增大到四個字節大小4294967295 + 1怎么樣? 然后給你一把長度為 7 的尺子,讓你能準確測量小紅和小藍的距離,你會怎么做(想象一下這個場景)? 因為尺子能測量的距離太多,而小紅跑的太快,所以你必須約束一下小紅,讓他在距離小藍為7或者更短的距離時必須停下來等小藍或者放慢速度! 就像兩者被尺子綁住了一般,距離只能短,不能長。 由此我們就可以同時理解下面這個公式和in與out的自加了。
BUFF_SIZE - (fifo.in - fifo.out) fifo.in++; // 直接自加 fifo.out++;//直接自加 BUFF_SIZE 就是這把尺子,而 in 和 out 相減可以得到兩者距離,尺子總長減去兩者距離,就可得到尺子剩余可測量的距離,也是小紅還可再跑的距離。 而一直自加其實就是利用變量自動溢出的特性,而即使溢出導致 out 大于 in 也不會影響計算結果。 看一個動圖結合理解溢出(公**眾&&號可查看):

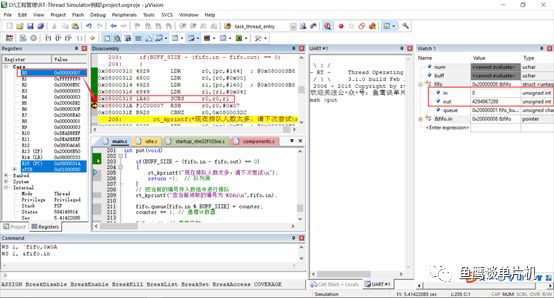
那為什么這里使用32位無符號整型,可不可以用8位數? 不可以,起碼在上面那個公式下是不可以的(可以稍作修改)。 這里其實涉及到計算機最為基礎的知識(基礎不牢,地動山搖,不過還好魚鷹掌握一點匯編知識和許多調試技巧)。 現在魚鷹把 in 和 out 修改為 8 位無符號數,然后測試當 in = 0 和 out = -7(因為是無符號,這里其實是249),開始測試這個公式:
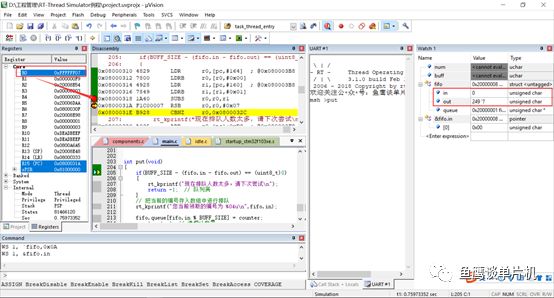
你會發現in - out = 0xFFFF FF07(這個結果會導致順利執行put函數,而不是直接退出),而不是0x0000 0007,這是因為計算8位數時,采用的是32位整型計算,也就是運算等級提升了,就類似浮點型和整型一起混合計算,自動使用浮點計算! 但是當你使用32位數聲明in和out,還是in = 0,out = -7(其實是4294967289),那么計算結果就完全不一樣了(變成了0x0000 0007,put函數直接退出)。
這里講的太細了,使道友少了很多獨立思考,現在留個問題給各位,為什么選擇 -7 ? 寫完這部分,魚鷹才發現 V2.0 版本是存在 BUG 的,原因就在于存儲數據和讀取數據那需要注意的代碼,之前魚鷹想當然的認為直接取余 % 即可正確讀取和存儲數據,實際上因為 7 這個數根本不能被 0xFFFF FFFF + 1 給整除,也就無法正確使用了,所以V2.0版本無法使用,但如果把 7 換成 8,就沒有問題了,這里需要特別注意(還好提早發現了,不然就是誤人子弟了)。 好了 ,終于把最難理解的部分勉強說完了! 但是目前這只是前菜,還有很多。 現在繼續。 因為 in 和 out 一直自加,所以不像 V1.0 一樣出現空和滿時 in 和 out 都是相等,也就不需要留下一個空間了,完美的利用了所有可用的空間! 但是 in 和 out 總是自加,必然會出現 in 和 out 大于空間大小的情況,所以在取隊列中的元素時必須使用 % 限制大小,才能準確獲取隊列中的數據(前提是隊列大小為 2 的冪次方),而 get 和 put 開頭的判斷總能保證in大于或等于out(這個只是從結果來看是這樣,但實際有可能 in 小于 out,但這個不影響最終結果),而in – out 小于或等于隊列大小,防止了可能的數組越界情況。
V 2.5
現在開始介紹真正的無鎖隊列。 如果僅僅從無鎖的角度來說,前面幾個版本除了 V1.5 外其實都是無鎖模式了(后面會說為什么 V1.5 不是無鎖),那為什么還要升級?目的何在?。 不知道你是否還記得筆記開頭魚鷹曾說因為效率太低而未采用循環隊列,為什么,因為按照目前的實現來說,每次 get 都只能獲取一個隊列元素,而每次 put 也只能寫入一個元素,這對于大量隊列元素的拷貝來說效率非常低下(比如從隊列中拷貝大量串口數據)。 假如說你從隊列中獲取所有的數據,常規方式你只能使用 get 函數一個一個元素的取出,每次 get 除了函數體本身的運算外(判斷是否為空、調整索引、取隊列元素、自加 out),還有進入、退出函數的消耗,如果獲取的數量少還好,一旦多了,這其中的消耗就不得不考慮了。 而put函數同理。 所以存在大量隊列數據拷貝的情況下,以上各個版本都是不合適的,所以有必要進行優化升級! 既然上述版本不合適,我們就會思考,如果能僅從in和out的信息就能拷貝所有隊列中的數據那該多好。 事實上,linux 中的無鎖隊列實現就是利用 in 和 ou t就解決了大量數據拷貝問題。 而這個拷貝思想如果能運用在塊存儲設備,那么將極大簡化代碼。 那么我們來看看無鎖隊列是如何實現的。 首先上代碼(魚鷹為了方便說明和測試,未提供完整函數,這個可后臺領取):
// 測試代碼 V2.5// 魚鷹*公***眾**號:魚鷹談單片機#define BUFF_SIZE 8 typedef struct { uint32_t in; // 注意,這里是 32 位 uint32_t out; // 注意,這里是 32 位 uint32_t size; // 設置緩存大小 uint8_t *buffer; // 這里不再指定大小,而是根據實際情況設置緩存大小}fifo_def; // 把隊列相關的變量整合在一塊,方便使用 uint8_t counter; // 記錄人數,也是發放的編號,因為隊列類型變了,所以這里也改成 uint8_tuint8_t fifo_buff[BUFF_SIZE]; fifo_def fifo = {0,0,BUFF_SIZE,fifo_buff}; // 為了簡化初始化過程,直接定義時初始化 void init(fifo_def *pfifo,uint8_t *buff,uint32_t size){ if(size == 0 || (size & (size - 1))) // 2 的 冪次方 { retern; } pfifo->in = 0 pfifo->out = 0; pfifo->size = size; pfifo->buffer = buff; } int get(void *parameter){ fifo_def *pfifo = &fifo; // 這里直接使用全局變量,因為命令行不方便傳參 uint32_t len = 2; // 這里假設一次獲取 2 個字節數據 uint8_t buffer[2]; // 將隊列中的數據提取到這個緩存中 uint32_t l; len = min(len, pfifo->in - pfifo->out); /* first get the data from fifo->out until the end of the buffer */ l = min(len, pfifo->size - (pfifo->out & (pfifo->size - 1))); memcpy(buffer, pfifo->buffer + (pfifo->out & (pfifo->size - 1)), l); /* then get the rest (if any) from the beginning of the buffer */ memcpy(buffer + l, pfifo->buffer, len - l); pfifo->out += len; if(len) // 為了判斷是否寫入數據,加入調試信息 { for(int i = 0; i < len; i++) { rt_kprintf("請編號:【%04u】 到柜臺辦理服務 ",buffer[i]); } } else { rt_kprintf("當前沒有顧客等待服務 "); } return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); // 導出到命令行中使用 int put(void){ fifo_def *pfifo = &fifo; // 這里直接使用全局變量,因為命令行不方便傳參 uint32_t len = 1; // 這里假設一次寫入 1 個字節數據????uint32_t?l;????????? uint8_t buffer[1] = {counter}; // 存入編號,即將寫入到隊列中 len = min(len, pfifo->size - pfifo->in + pfifo->out); /* first put the data starting from pfifo->in to buffer end */ l = min(len, pfifo->size - (pfifo->in & (pfifo->size - 1))); memcpy(pfifo->buffer + (pfifo->in & (pfifo->size - 1)), buffer, l); /* then put the rest (if any) at the beginning of the buffer */ memcpy(pfifo->buffer, buffer + l, len - l); pfifo->in += len; if(len) // 為了判斷是否寫入數據,加入調試信息 { rt_kprintf("您當前領取的編號為 %04u ",buffer[0]); } else { rt_kprintf("當前沒有顧客等待服務 "); } counter++;// 寫完自加,不屬于無鎖隊列內容 return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample); 首先說說和 V2.0 的主要區別: 1、將隊列大小改為 8,即符合2的冪次方(這是in和out無限自加所要求的,也是一種限制) 2、將緩存名更改為buffer,更容易理解(所以取名字也很重要) 3、增加了一個變量size,這是方便在多個fifo情況可以使用同一個函數體(函數復用),通常這個值只在初始化時賦值一次,之后不會修改。 然后最難理解的就是那兩個拷貝函數了。 現在著重說明一種特殊拷貝情況,當能理解這種特殊情況,那么其他情況也就不難理解了。 首先看兩個min,這是用來取兩者之間最小的那一個。
len=min(len,pfifo->in-pfifo->out);/* first get the data from fifo->out until the end of the buffer */ l = min(len, pfifo->size - (pfifo->out & (pfifo->size - 1))); memcpy(buffer,pfifo->buffer+(pfifo->out&(pfifo->size-1)),l);/* then get the rest (if any) from the beginning of the buffer */ memcpy(buffer+l,pfifo->buffer,len-l);開始的len是用戶要求拷貝的長度,但考慮到用戶可能拷貝大于隊列已有數據的長度,所以有必要對它進行重新設置,即最多只能拷貝目前隊列中已有的大小。 第二個min其實用來獲取隊列out開始到數組結束的大小,難理解?看下圖就很清楚了:

所以,它獲取的就是out到數組結束的地方,即上圖5~7的數據,那么為什么它能從out這個值得到數組內的索引,它不是一直在自加嗎?它肯定會出現超過數組的情況啊? 是的,你猜的沒錯,如果數組大小小于四個字節所表示的大小的話,它肯定會超過數組的索引值的,但你不要忘了,數組的大小是2的冪次方,也就是說out % size的余數必然還在數組中,即out這個值其實已經蘊含了數組索引值的信息的。 難理解,繼續看之前的動態(沒辦法,資源太少啦):
當你只盯著后三位bit 數據,而不管前面有多少 bit 時,你就能理解了。 雖然 out 如上所示一直在自加過程中,但后三位(十進制 0 ~ 7)是自成循環的,而這自成循環的值就是我們的數組索引 0~7 的值,所以為了效率,可使用 & 運算(效率一說后面再講)。 我們再進一步思考,因為它利用了最后的循環數作為數組的索引,在 in、out、size 都是四個字節的情況下,隊列最大的長度是多大? 4 GB?畢竟 in 能表示的范圍也就這么大了。 錯,應該是 0x8000 0000,2 GB。因為如果是4GB的話,size 的值為 0x1 0000 0000,超過四字節大小了,所以隊列大小被除了被 in、out 所限制,還被size限制了。 size – out 不就是數組右邊部分的數據大小了,拷它! 然后數組開頭部分剩余數據大小,拷它! 這樣一來,就很清楚了,當你明白了這些,你會發現這兩個拷貝函數能適應隊列存儲的各種情況,巧奪天工! 無鎖隊列的原理看似結束了,關鍵代碼也介紹清楚了,但其實一個關鍵點到現在還沒有進行說明,那就是,怎么它就是無鎖了,而V1.5又為什么不是無鎖? 無鎖,有個很重要的前提,就是一個生產者,一個消費者,如果沒有這個前提,以上所有版本都不能稱之為無鎖! 那么首先討論,軟件中的生產者和消費者到底是什么? 如果一個資源(這里可以是各種變量、外設)只在一個任務中順序使用,那么無鎖、有鎖都沒有關系,但是在多個任務中就不一樣了。 那么現在再來說說這里的任務代表著什么?任務是一個函數,一個功能?是,也不是。 裸機系統中,main 算一個函數,也是一個主功能函數,但它可以算任務嗎?算!系統中有很多中斷處理函數,他們算一個個的任務嗎?算!除此之外還有任務嗎?沒了! 操作系統中(以RT-Thread為例),main 算一個任務嗎?算!RT-thread 將它設置為一個線程,所以系統中的所有的線程都是一個個的任務;中斷處理函數算一個個的任務嗎?算!除此之外還有任務嗎?沒了! 那么這里所說的任務是靠什么劃分的?你總不能拍腦袋就定下來了吧,總要有依據有標準吧! 靠什么?靠的是一個函數會不會被另一個函數打斷執行! 何為打斷?打斷是指一個函數正在執行,然后中間因為某種原因,不得不先執行別的函數,此時需要把一些臨界資源保存以供下次恢復使用? 何為臨界資源?說白了,就是一個個 CPU 寄存器,當你進行任務切換時,為了保證下次能回到正確的位置正確的執行,就需要把寄存器保存起來。 線程能在這稱之為任務,就是因為當它被打斷執行時(可能執行其他任務,可能執行中斷處理函數),需要保存臨界資源;而中斷處理函數也是如此,雖然它保存臨界資源時不是由CPU執行的,但它也要由硬件自動完成(STM32是如此)。 所以,這里所說的任務和你想的任務稍有不同,但為了方便理解,繼續使用“任務”一詞。 好了,清楚了任務,下面就簡單了。 當一個資源同時被兩個以上任務(比如一個線程和一個中斷函數)所使用時,為了防止一個任務正在使用過程中被其他任務所使用,可能采取如下措施: 1、關中斷(簡單、高效) 2、使用互斥鎖(操作系統提供) 3、使用特殊互斥匯編指令(單片機提供) 4、使用單位信號量(操作系統提供) 5、使用位帶(單片機提供,理解徹底后會發現和無鎖隊列類似,詳情看魚鷹信號量筆記) 6、無鎖隊列實現 現在就來看看無鎖隊列是如何實現無鎖的? 以前面所講的終極串口接收(詳情請看《終極串口接收方式,極致效率》)為例進行說明。 如果你認真分析兩個函數,你會發現不管是 get 函數還是 put 函數,其實都只修改了一個全局變量,另一個全局變量只作為讀取操作。所以雖然 in 和out(size 一直都只是讀取)同時在兩個任務中使用,但并不需要加鎖。 當然修改的位置也很重要,它們都是在數據存儲或者提取之后才修改的全局變量,如果順序反了呢?以前魚鷹說順序的時候,都說先把資源鎖占領了再說,但這里卻不同,而是先使用資源,最后才修改,為什么?請自行思考。 那么為什么 V1.5 需要加鎖呢?還記得那個 used 全局變量嗎? 當 used 全局變量在一個任務中自加,在另一個任務中自減,而沒有任何保護措施,你認為會發生什么? 你要知道,自加、自減C語言代碼只有一條,但匯編語句卻有多條。 首先讀取used的值,然后加1或減1。如果兩者之間被打斷了,就會出現問題。 比如used 開始等于 5,一個任務1讀取后保存到寄存器R0中準備加1,然后被另一個任務2打斷,它也讀取了used,還是5,順利減 1,變成4,回到任務1繼續加 1,變成了 6。最終used變成了6,但實際上因為執行了任務2,它此時應該還是 5的。 這樣一來,used 就不能準確反映隊列中已使用的空間了,只能加鎖保護。 但是無鎖隊列卻不會出現這種情況,因為它只修改一個屬于自己的那個變量,另一個變量只讀取,不修改,這才是無鎖實現的關鍵之處! 無鎖、無鎖,其實是有鎖!這里的鎖是in和out這兩把鎖,各司其職,實現了無鎖的效果(沒有用關中斷之類的鎖),使數組這個共享資源即使被兩個任務同時使用也不會出現問題。但是三個以上任務使用還能這么處理嗎? 當然不能,因為這必然涉及到一個in或者out同時被兩個任務修改的情況,這樣一來就會出現used的情況,而且你還不能單純只鎖定in或者out,而需要同時把整個函數鎖定,否則就會出現問題。 好了,到此無鎖所有關鍵細節問題都清清楚楚,明明白白了,但是對于一個項目來說,這就足夠了? 如果你認為掌握了理論就沒問題了,那你就太天真了!
效率討論
先上點小菜,之前一直有說 % 和 & 兩個運算符效率的問題,那么它們效率差別到底多大? 以前魚鷹剛開始接觸循環隊列時,以魚鷹當時的水平根本就沒有考慮效率的問題,就只是感覺 % 好神奇啊,然后到處用;也不明白為啥uCOS 的內存管理不用 % ,畢竟它是那么的神奇,是吧!
后來無意中看到說 % 效率比 & 低,那么低多少?我們來測試一下 V1.0 和V2.0 的執行效率好了。因為 V2.0 對大小有限制,那么就設置為 8 好了。 測試代碼如下:
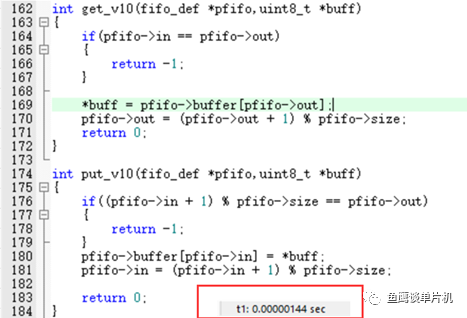
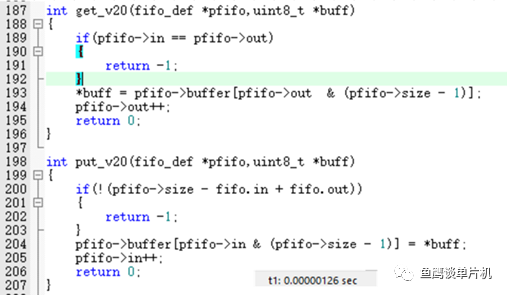
從測試結果來看1.44 us和1.26 us(72 M主頻,如何測量的下篇筆記告訴你,記得關注哦)相差也不是很大,14%左右的差距,不過數據量大的情況下還是選擇 & 吧,畢竟高效一些。 但是如果單純從 & 和 % 運算角度來說,在STM32F103環境下能達到3倍的差距,這個自行測試就好了。 還有一個效率問題,那就是在單個隊列元素插入與獲取上。 因為V2.5是通用型的put、get函數,在單個元素的情況下效率必然不是很高,所以魚鷹針對單個元素的插入與獲取又封裝了兩個新函數,通過測試對比put函數,發現一個為1.60,一個0.67 us,差距還是挺大的(如果用在串口中斷中,當然效率越高越好),所以需要根據場合使用合適的方式。
BUG 討論
好了,現在來聊聊一個消費者一個生產者模式下可能產生的BUG以及該如何解決吧。 首先說說min。 如果min是一個函數,那么V2.5代碼沒有任何問題,但是如果它是一個宏呢?
#definemin(x,y)((x)
len=len
測試
終于即將結束了,現在再簡單嘮嗑一下如何測試無鎖隊列或者鏈表問題。 我們知道隊列出隊入隊都是有順序的,如果我們在測試時,把有規律的數據放入隊列中,那么獲取數據時也根據這個規律來進行判斷是否出現問題,那么就可以實現自動檢測隊列是否正常運行。 比如說,存入的數據一直自加,而接收時用一個變量記錄上次接收的數據,然后和現在的數據進行比對是否相差1,那么就能簡單判斷無鎖隊列的功能。
而為了測試溢出之后in小于out的情況(in和out實在是太大了,要讓他溢出太難等了),那么可以將in和out一開始設置為接近溢出值就行,比如 -7 等。 如果簡單的兩個線程間進行壓力測試,那么你很難測出問題來,這是因為線程測試代碼量太少,大部分時間CPU都是空閑狀態,所以函數總是能順序執行而不會被打斷,如果想讓代碼可以被頻繁打斷以測試安全,那么將兩個函數分別放到微秒級別的中斷處理函數中或許能夠測試出一些問題。 當然以上方法只是比較粗淺的測試,真正還是要在實際中進行長時間的穩定性測試才行,只有這樣,你的程序才算是經受住了考驗,否則紙上談兵終覺淺啊!
-
代碼
+關注
關注
30文章
4791瀏覽量
68686 -
BUG
+關注
關注
0文章
155瀏覽量
15679
原文標題:【深度長文】還是沒忍住,聊聊神奇的無鎖隊列吧!
文章出處:【微信號:mcu168,微信公眾號:硬件攻城獅】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
沙子變芯片,一步步帶你走進高科技的微觀世界



用XDS200仿真PGA900時候,單步執行程序PC支持并沒有按照C語言一步一步執行,為什么?
昂科芯片燒錄高質量出海 唱響越南一步步新技術研討會
散熱第一步是導熱


英偉達官宣新一代Blackwell架構,把AI擴展到萬億參數
Prevayl的下一步是什么






 工商網監
工商網監
評論