 為什么將AI注入到IT運營中比數據本身更多的是數據
為什么將AI注入到IT運營中比數據本身更多的是數據
我與之交談的幾乎每個CIO都大膽地宣稱他們的企業是“數據驅動的企業”。但是,畢馬威會計師事務所(KPMG)最近進行的 全球CEO前景 調查卻截然不同:全球67%的CEO(美國的這一數字躍升至78%)表明,他們忽略了由CIO /他們提供的數據驅動的分析和預測模型IT團隊,因為這與他們自己的經驗相矛盾;他們根據自己的直覺做出了重大的企業決策。
忽略了數據驅動的見解而遵循直覺的CEO
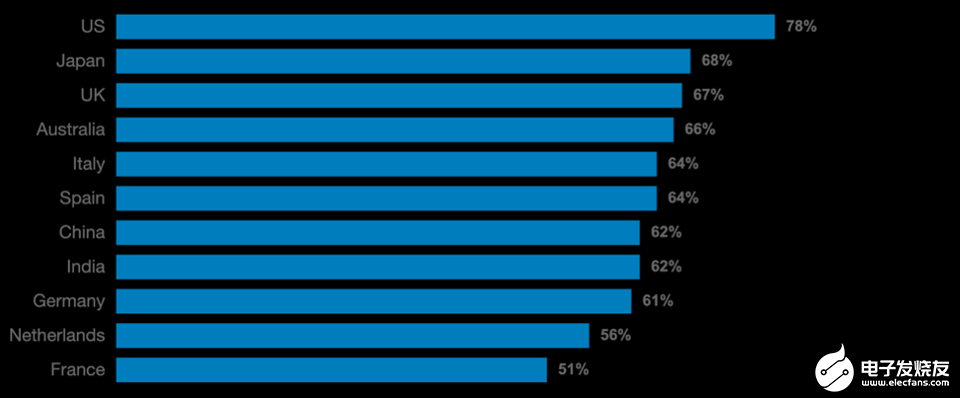
雖然結果有些令人震驚,但可以很容易地解釋它。首先,盡管企業生產的數據量足夠多,但是數據仍然在業務單元,域,平臺和實現(例如云與私有數據中心)之間非常分散。根據Forrester的說法,多達73%的公司數據未用于分析和見解。難怪首席執行官僅使用總數據的27%生成的模型就獲得了可怕的結果!其次,大多數當前的預測模型僅使用歷史數據,而不使用流(實時)數據。這兩個重要因素導致預測的準確性不高。首席執行官如果不信任模型,就無法做出決策,因為他們業務的成敗取決于他們做出的決策。
更多數據可以帶來更好的預測
盡管是IT運營使其他企業AI計劃保持平穩運行,但實施AI以改善其自身的運營速度卻很慢。原因之一是上述數據零散。當向AI / ML模型提供部分數據時,您只會獲得企業的部分視圖。另一個主要原因是因為當前大多數AI / ML實施都是為了創新,并且通常由BU資助。傳統上,企業將IT視為成本中心,因此他們不愿意花錢來使用AI來改善運營。但是,隨著大量的數據,以及當前的大流行病產生了更多的未連接的遠程數據,這種感覺在開始淹沒Ops團隊時發生了變化。IT運營團隊正在達到一個臨界點,要處理的數據過多,這是AI的理想方案。這是AI和ML的最佳選擇。人工智能在大量數據上蓬勃發展。實際上,向AI算法饋送的數據越多,模型就越好。
傳統上,IT運營團隊多年來一直監視IT基礎結構監視(ITIM)和網絡性能監視與診斷(NPMD)層。在過去的十年中,應用程序性能管理(APM)幫助提高了每個應用程序的可見性。但是,即使所有這些系統都表明它們正常工作,客戶仍會根據位置,連接類型(移動/互聯網),所使用的緩存/ CDN提供程序的類型等而遇到問題。現代應用程序及其組件的復雜性加載到客戶視圖中會使其變得非常復雜。數字體驗監視(DEM)的概念已獲得可見性,可以專門監視,分析和優化客戶體驗。但是,它們更像是監視工具,而不是診斷工具。
AIOps(IT運營中的人工智能)解決方案可以幫助解決此問題。一個好的AIOps解決方案應該能夠從多個來源獲取數據,消除噪聲,關聯事件序列并基于歷史數據和實時數據的組合產生可行的見解。
數據采集
可以說,這是最重要的一步。不僅需要將歷史數據饋送給AI進行模型創建,而且還需要將實時數據饋給AI進行推理和更新模型。僅像過去那樣收集日志或SNMP并不能提供企業的全面情況。收集盡可能多的信息,包括事件,日志,時間序列數據,應用程序數據,性能數據,利用率數據等。新的基于事件的范式轉移到發布/訂閱或基于事件的消息傳遞。盡管這些消息非常重要,但它們對于收集實時數據以提供企業的完整視圖并做出準確的預測絕對至關重要。大多數基于云的系統,無論是基于容器的還是基于虛擬機的,都通過API提供大量信息。
收集結構化,半結構化和非結構化數據。盡管現有的BI和分析系統在處理非結構化數據時遇到困難,但AI還是喜歡它。它可以解析幾乎所有內容,包括音頻,視頻,文本文件,圖像,配置文件,文檔,PDF文件等。
最后,大多數團隊忘記將配置記錄,變更管理系統,CMBD等作為等式的一部分。這對于每天有時會推動多個發布周期的敏捷團隊尤其重要。除非IT運營團隊意識到最近的變化,否則他們將浪費大量時間試圖找出問題的根本原因。
數據質量和數據攝取
AI存在數據質量問題。創建AI / ML模型時,“垃圾填埋,垃圾填埋”是非常正確的。您的算法有多好或數據科學家有多好都無關緊要。如果您沒有提供足夠的質量數據,那么您將一無所獲。當企業收集大量數據時,它仍然是不完整,不正確和/或不一致的。您還需要收集相鄰和相關的數據。您可能會認為它們無關緊要,但是對于AI使用看似無關的數據所能找到的東西,您會感到驚訝。一個例子是,當NASA衛星破裂時,IBM的AI工程師和NASA科學家找到了一種方法,可以利用太陽光以98%的準確度來計算紫外線強度。我最近寫了一篇關于此的文章,可以在這里看到。
如果您與數據科學家交談,他們會告訴您他們花了多少時間準備數據。他們多達80%的時間用于準備數據,而不是分析數據或創建和微調模型。
數據分類和標簽
數據需要正確分類,分類和標記,以便AI / ML從中學習。對于監督學習模型尤其如此。在訓練,驗證和調整模型之前,這是重要的一步。標簽的準確性和質量是最重要的兩件事。準確性衡量的是標簽與真實情況之間的接近程度,或與您的企業事實和/或實際條件匹配的程度。質量與用于模型的整個數據集的標注準確性有關。當您結合使用自動,外包和內部標簽工作時,尤其如此。所有組都會在整個數據集中一致地標記嗎?
數據清理
如果使用偏差數據訓練AI模型,則無疑會產生偏差模型。我寫了一篇有關如何避免這種情況并使您的數據失偏的文章。原始數據可能包含隱性偏見信息,例如種族,性別,出身,政治,社會或其他意識形態偏見。消除它們的唯一方法是分析不平等并在創建模型之前對其進行修復。如果不從數據中消除歧視性做法,該模型將傾向于產生有偏見的結果。
僅當數據來自經驗證,權威,經過驗證和可靠的來源時,才應包括在內。來自不可靠來源的數據應該完全消除,或者在輸入模型時應給予較低的置信度。另外,通過控制分類精度,可以以最小的增量成本來大大減少辨別力。這種數據預處理優化應集中在控制區分,限制數據集中的失真和保留實用程序上。
資料儲存庫
考慮到數據的數量,速度和種類,用于數據存儲和數據管理的傳統現場解決方案不適用于數字本機解決方案。許多公司已采用數據湖解決方案來解決此問題。盡管單個集中的數據源可以提供幫助,但需要對其進行適當的安全保護,管理和定期更新。它應該能夠無縫處理結構化和非結構化數據。
結論
人工智能需要大量數據。正如我最喜歡的《短路》中的角色Johnny V(基于AI的機器人)說:“我需要更多的輸入……”。如果您的高管要基于此做出重大的企業決策,請確保為AI提供正確數量和質量的數據。如果沒有,他們將忽略您的模型輸出/建議并做出自己的決定,從而最大程度地降低您的價值,并最終使您獲得數字化和改善業務所需的資金。
-
AI
+關注
關注
87文章
30763瀏覽量
268909 -
數據驅動
+關注
關注
0文章
127瀏覽量
12333
發布評論請先 登錄
相關推薦
數據驅動AI工具在哪
維智科技用數據+AI驅動業務增長
Lumen將AI光纖交易鏈接亞馬遜數據中心
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
在FX3S上如何通過USB和GPIF將數據存儲到eMMC中?
esp8266怎么做才能每秒發送更多的數據包呢?
平衡創新與倫理:AI時代的隱私保護和算法公平
AI時代,我們需要怎樣的數據中心?AI重新定義數據中心






 工商網監
工商網監
評論