 麥克斯·德爾布呂克分子醫學中心的研究人員開發了一種新工具
麥克斯·德爾布呂克分子醫學中心的研究人員開發了一種新工具
麥克斯·德爾布呂克分子醫學中心的研究人員開發了一種新工具,可以更輕松地最大化深度學習在研究基因組學方面的力量。他們在《自然通訊》(Nature Communications)雜志中描述了Janggu的新方法。
想象一下,在晚餐之前,您首先必須重建專門為每種食譜設計的廚房。您將花費更多的時間進行準備,而不是實際做飯。對于計算生物學家來說,分析基因組數據是一個類似的耗時過程。在甚至沒有開始分析之前,他們就花費了大量寶貴的時間來格式化和準備龐大的數據集,以將其輸入到深度學習模型中。
為了簡化此過程,MDC的研究人員開發了一種通用的編程工具,該工具可將各種基因組數據轉換為所需的格式,以供深度學習模型進行分析。MDC柏林生物信息學和組學數據科學研究小組的科學家Wolfgang Kopp博士說:“以前,您最終在技術方面浪費了很多時間,而不是專注于要解決的生物學問題。”醫學系統生物學研究所(BIMSB),該論文的第一作者。“有了長谷,我們的目標是減輕某些技術負擔,并使盡可能多的人可以使用它。”
Janggu的名字來自韓國傳統鼓形,其側面像一個沙漏。沙漏的兩個大部分代表了Janggu的重點領域:基因組數據的預處理,結果可視化和模型評估。中間的狹窄連接器代表研究人員希望使用的任何類型的深度學習模型的占位符。
深度學習模型涉及對大量數據進行排序并找到相關特征或模式的算法。雖然深度學習是一種非常強大的工具,但它在基因組學中的使用受到限制。大多數已發布的模型往往只適用于固定類型的數據,只能回答一個特定問題。交換或添加新數據通常需要從頭開始并進行大量編程工作。
Janggu將不同的基因組學數據類型轉換為通用格式,可以插入使用python(一種廣泛使用的編程語言)的任何機器學習或深度學習模型中。
使我們的方法與眾不同的是,您可以輕松地使用任何基因組數據集解決您的深度學習問題,任何形式的東西都可以使用,”生物信息學和Omics數據科學研究小組負責人Altuna Akalin博士說。
Akalin的研究小組有雙重任務:開發新的機器學習工具,并使用它們來研究生物學和醫學領域的問題。在他們自己的研究工作中,他們一直為格式化數據花費了多少時間而感到沮喪。他們意識到問題的一部分是每個深度學習模型都包含自己的數據預處理。通過將數據提取和格式化與分析分開,它提供了一種更容易的方式來交換,合并或重用數據部分。這就像讓所有廚房工具和食材觸手可及,準備嘗試新食譜一樣。
Kopp說:“困難在于在靈活性和可用性之間找到適當的平衡。”“如果靈活性太強,人們將被淹沒在不同的選擇中,并且將很難上手。”
Kopp準備了一些教程,以幫助其他人開始使用Janggu,以及示例數據集和案例研究。《自然通訊》的論文證明了Janggu在處理大量數據,組合數據流以及回答不同類型的問題(例如根據DNA序列和/或染色質可及性預測結合位點以及分類和回歸任務)方面的多功能性。
盡管Janggu的大部分優勢都在前端,但研究人員希望為深度學習提供完整的解決方案。Janggu還包括在深度學習分析之后的可視化結果,并評估模型學到的知識。值得注意的是,該團隊在包裝中加入了“高階序列編碼”,從而可以捕獲相鄰核苷酸之間的相關性。這有助于提高某些分析的準確性。通過使深度學習更容易且更友好,Janggu幫助打開了回答各種生物學問題的大門。
“最有趣的應用之一是預測突變對基因調控的影響,” Akalin說。“這令人興奮,因為現在我們可以開始了解單個基因組,例如,我們可以查明引起調節變化的遺傳變異,或者我們可以解釋腫瘤中發生的調節突變。
-
連接器
+關注
關注
98文章
14476瀏覽量
136430 -
編程語言
+關注
關注
10文章
1942瀏覽量
34707 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
發布評論請先 登錄
相關推薦
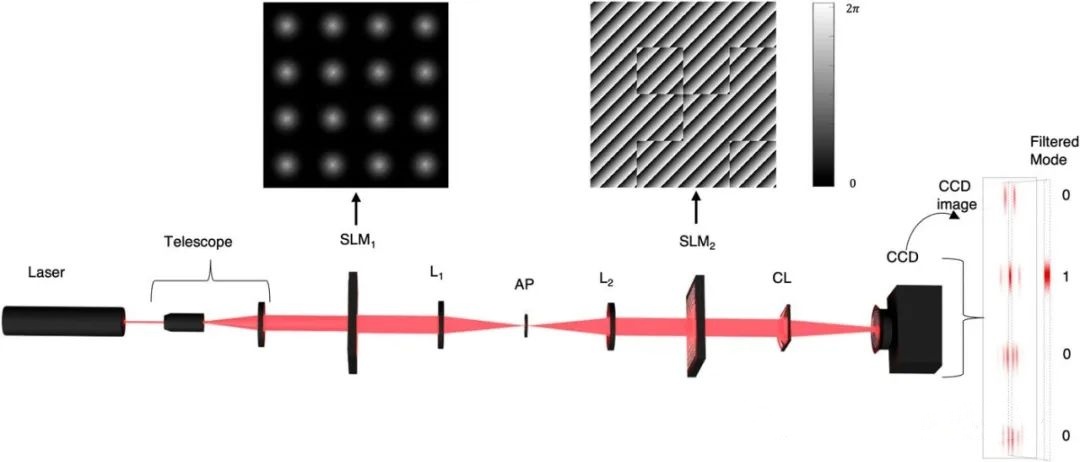
研究人員利用激光束開創量子計算新局面
喜報!武漢普賽斯獲批2024年湖北省工程研究中心

柔軟可拉伸的新型3D打印材料可改善可穿戴傳感應用
研究人員提出一種電磁微鏡驅動系統
基于一種AI輔助可穿戴微流控比色傳感器系統
一種可實現穩定壓力傳感的新型可拉伸電子皮膚
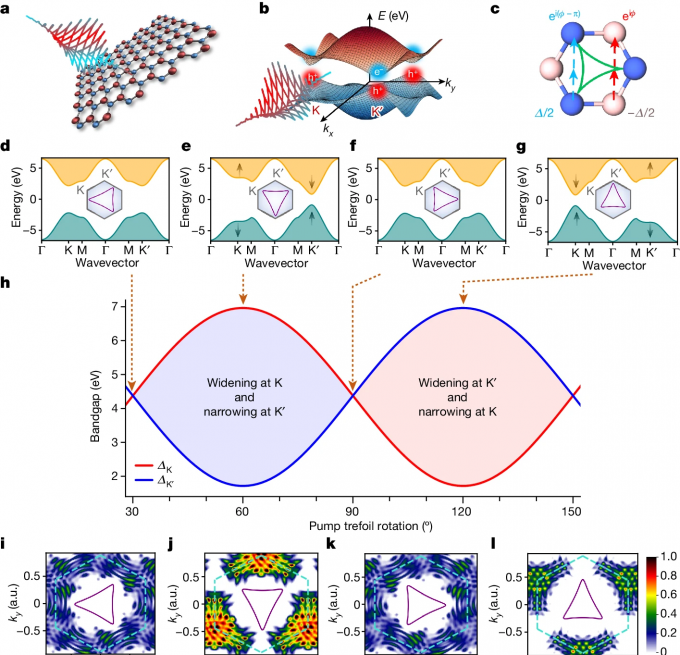
研究人員利用定制光控制二維材料的量子特性
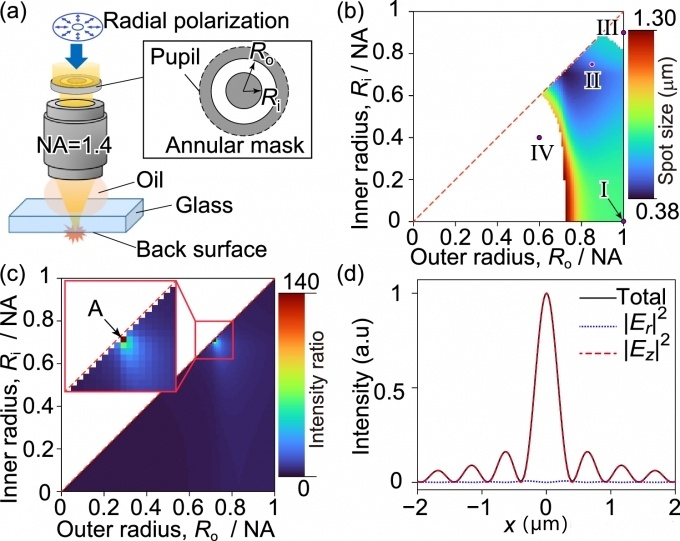
研究人員發現提高激光加工分辨率的新方法
一種用于化學和生物材料識別的便攜式拉曼光譜解決方案
基于量子干涉技術的單分子晶體管問世
一種基于單像素光電探測器的高光譜視頻成像系統設計

利用太赫茲超構表面開發一款革命性的生物傳感器
研究人員開發出一種新型太赫茲成像系統





 工商網監
工商網監
評論