 算法工程師面臨危機 如何最優化職業發展?
算法工程師面臨危機 如何最優化職業發展?
AI概念在2015年起就紅得發紫,不論是送外賣,搞團購,賣車,或是推薦莆田醫院的,是個公司都會標榜自己是搞人工智能的。
在21世紀的第二個十年,計算機專業相關的學生不說自己是搞AI算法的,同學聚會都抬不起頭,相親都沒機會。
隨便從一摞簡歷里抽出一份,一定會有AI、調參、CNN、LSTM這些關鍵詞。未來最賺錢的職業,一定不是天橋貼膜,而是天橋調參,50塊錢一次,一調就靈:
NIPS會議,人滿為患,改改網絡結構,弄個激活函數就想水一篇paper; 到處都是AI算法的培訓廣告,三個月,讓你年薪45萬!
在西二旗或望京的地鐵車廂里打個噴嚏,就能讓10個算法工程師第二天因為感冒請假。
誰也不知道這波熱潮還能持續多久,但筆者作為一線算法工程師,已經能明顯感受到危機的味道: 以大紅大紫的圖像為例,圖像方向簡歷堆滿了HR的辦公臺,連小學生都在搞單片機和計算機視覺。
在筆者所在的公司,人工智能部門正在從早前研究院性質的組織架構分別向前臺和后臺遷移:前者進入業務部門,背上繁重的KPI,與外部競爭者貼身肉搏。
后者則完全融入基礎架構,像數據庫一樣普通和平凡。之前安逸的偏研究生活被打破, AI早已走下神壇。
以筆者愚見,對于一般的算法工程師,這種危機包含兩部分:一方面是來自人的競爭,大量便宜的畢業生和培訓生涌入這個行業,人才缺口被迅速填滿甚至飽和,未來的競爭會更激烈。
另一方面則是來自機器的競爭,大量算法工程師會很快被他們每天研究的算法所代替。 這兩者互相惡化,AI人才市場終會變成一片紅海。
1.連小學生都會寫模型
工具和框架本身的發展,讓設計模型所需的代碼寫得越來越簡潔。10年前從頭用C++和矩陣庫實現梯度下降還是有不小的門檻的,動輒上千行。而當今幾十行Keras甚至圖形化的模型構建工具,讓小學生都能設計出可用的二分類模型。
強大的類庫吞噬了知識,掩蓋了內部的復雜性,但也給從業者帶來了不小的惰性。從業者的技術水平,和使用模型的復雜程度關系不大,越是大牛,用的技術更底層更make sense。
不僅如此,深度學習本身的性質,造成了明顯的數學鴻溝。與SVM, 決策樹不同,由于模型存在大量的非線性和復雜的層次關系,且輸入信號(例如圖像,文本)也很復雜,因此嚴格的數學論證是需要極高的抽象技巧的。
該方法為什么好,在什么類型的數據上好,有時連作者都在拍腦袋,很多state of arts的方法,成了口口相傳的經驗和trick,而非嚴謹的theory。 連batch normlization(批規范化,只包含四個初中數學級別的簡單公式)為何有效,都被爭論了好幾年。
只有鳳毛棱角的專家,能深入到模型最深處,用數值分析和理論證明給出嚴謹的答案。 大部分人在入門后便進入漫長的平臺期,美其名曰參數調優,實際就像太上老君煉丹一樣。
我們把這種現象繪制成下面的AI學習曲線,左側是稍顯陡峭的入門期,需要學習基本的矩陣論,微積分和編程,之后便是漫長的平臺期。
隨著復雜性越來越高,其學習曲線也越來越陡峭,大部分人也就止步于此。 越來越易用的工具,讓曲線的斜率變大,入門期變短,卻并不能改變右側的陡峭程度。
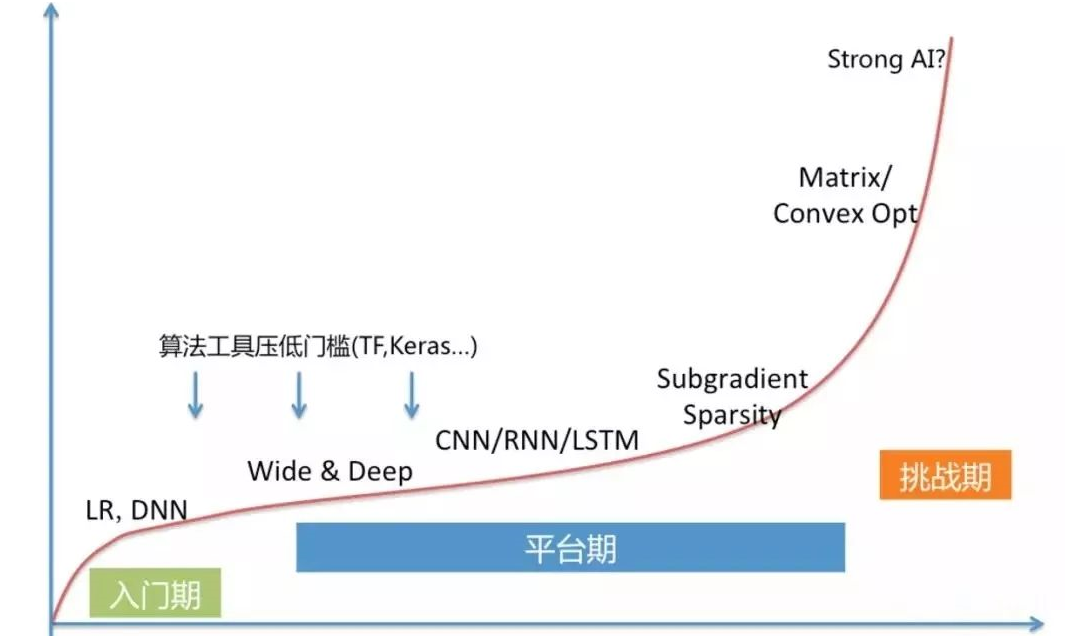
圖注:AI學習曲線
入門容易深入難,這條曲線同時也能描述AI人才的收入水平。而真正處于危機的,莫過于夾在中間的蕓蕓眾人:對理論一知半解,對工具非常依賴。可替代性很強,一旦AI浪潮過去,就知道誰是在裸泳。
市場和業務變化越來越快,能有哪些核心業務,是能讓工程師靜心調個一年半載的呢?
當一個從培訓學校里出來的人都能做模型時,有多少業務能讓公司多花兩三倍的人力成本,而僅帶來1%的性能提升呢?
2.機器都能調參,要你干嗎?
面向大眾AI科普節目,最常討論的便是“AI時代如何不被機器所取代”。很不幸,最容易且最快被取代的反而是算法工程師。
算法崗比工程崗更容易被取代。 在現有技術下,由于業務需求的復雜性, 自動生成一套軟件App或服務幾乎不可能的(否則就已經進入強人工智能時代了),但模型太容易被形式化地定義了。
根據數據性質,自動生成各個領域的端到端(end2end)的模型也逐漸在工業上可用了:圖像語音和廣告推薦的飛速發展,直接套用即可。理論和經驗越來越完善,人變得越來越可替代。
特征可以自動生成和優選,特征工程師失業了; 深度網絡采用經典結構即能滿足一般業務需求,參數搜索在AutoML下變得越來越方便,調參工程師的飯碗也丟了; 以前需要大力氣搭建的數據回流和預測的鏈路,已經成了公司的基礎組件,數據工程師也沒事干了。
此處引用老板經常說的一句話:機器都能干了,要你干嗎?
從目前AI熱門論文的情況看,廣告推薦領域已經逐漸成熟,很多技巧沉淀為一整套方法論,已進入平臺期。
下一個即將被攻陷的領域應該是圖像;而文本由于其內在的抽象性和模糊性,應該是算法工程師最后的一塊凈土,但這個門檻,五年內就會有爆發式的突破。
3.如何最優化職業發展?
人工智能已經火了至少五年,它在未來五年是否火爆我們不能確定,但一定會更加兩極化:偏基礎的功能一般程序員就能搞定,像白開水一樣普通。而針對更復雜模型甚至強人工智能的研究會成為少數人的專利。
在一般的技術公司,傳統意義的軟件開發和產品設計,遠比AI算法的需求來的多。
算法永遠是錦上添花,而非雪中送炭,再好的算法也拯救不了落后的業務和商業模式。一旦經濟下行,企業首要干掉的就是錦上添花且人力成本較高的部分。
如果你是頂級的算法專家,這樣的問題根本不需擔心。但是,對大部分人來說,如何找到自己的梯度上升方向,實現最優的人生優化器呢?
筆者給出一些不成熟的小建議,供讀者拋磚引玉,基本也是往兩頭走:
首先是深入原理和底層,類似TensorFlow的核心代碼至少要讀一遍吧?就算沒有嚴格的理論基礎,最起碼也不能瞎搞啊。
切莫不能被工具帶來的易用性迷惑雙眼。要熟悉工具箱里每種函數的品性,對流動在模型里的數據有足夠的嗅覺,在調參初期就能對不靠譜的參數快速剪枝。
按個人理解,做算法帶來的最大收獲是科學精神和實驗思維,這是做工程很難培養出來的。以前看論文看了introduction和模型設計,草草地讀一下實驗結果就完事兒了。
殊不知AB實驗設計很可能才是論文的核心:實驗樣本是否無偏,實驗設計是否嚴謹,核心效果是否合理,是否能證明論文結論。
也許一行代碼和一個參數的修改,背后是艱辛的思考和實驗,做算法太需要嚴謹和縝密的思維了。即使未來不做算法,這些經驗都會是非常寶貴的財富。
再者是盡早面向領域,面向人和業務。AI本身只是工具,它的抽象性并不能讓其成為各個領域的靈丹妙藥。
如果不能和AI專家在深度上競爭,就在業務領域專精深挖,擁有比業務人員更好的數據敏感度,成為跨界專家。現在已經有大量AI+金融、AI+醫療、AI+體育的成功案例。
人能熟悉領域背后的數據,背后的人性,這是機器短時間內無法代替的,跨界帶來的組合爆炸,也許暗含著危機中的機會吧。
最后感慨一下,同樣是80后,年齡相差無幾,有人已是副總裁,有人帶了幾個人的小團隊,有人還在基層苦苦掙扎,軌跡在畢業時分叉,幾年后早已滄海桑田。
作者簡介:趙一鳴,
-
工程師
+關注
關注
59文章
1570瀏覽量
68513 -
算法
+關注
關注
23文章
4608瀏覽量
92855 -
人工智能
+關注
關注
1791文章
47232瀏覽量
238348
發布評論請先 登錄
相關推薦
圖像算法工程師的利器——SpeedDP深度學習算法開發平臺



FPGA算法工程師、邏輯工程師、原型驗證工程師有什么區別?


嵌入式軟件工程師如何提升自己?

嵌入式軟件工程師和硬件工程師的區別?



fpga工程師前景如何






 工商網監
工商網監
評論