 PostgreSQL的全局死鎖檢測原理
PostgreSQL的全局死鎖檢測原理
5月26日,一年一度的PG開發者大會PGCon2020如約而至。與往年不同的是,受疫情的影響,今年的PGCon采取了線上會議的方式,雖然沒有了面對面的交流,但在組織者Dan Langille等的精心安排下,會議有了更廣泛的受眾,干貨滿滿。來自Greenplum原廠的Greenplum內核工程師 Hubert Zhang(張桓)與Asim Praveen合作發表了演講《Distributed Snapshot and Global Deadlock Detector》。在演講中Hubert通過理論結合實例的方式講解了Postgres單節點死鎖和Postgres Foreign Server Cluster中實現分布式死鎖檢測的技術路線。
現在讓我們通過本文來回顧一下精彩的演講內容吧!
在大數據時代,隨著數據量的爆發式增長,對于分布式數據庫的需求亦是水漲船高。作為最出色的開源數據庫之一,Postgres也在大力探索和發展分布式解決方案。其中,Postgres Foreign Server Cluster是目前Postgres開發者郵件列表Pghacker中非常活躍的關于分布式Postgres的話題,該方案通過Foreign Data Wrapper和分區表的技術,支持將邏輯分區表,物理的存儲在多個不同的Postgres節點上。為了保證分布式環境中事務的ACID,Postgres社區正在積極開發基于Foreign Server Cluster的分布式事務相關patch(https://commitfest.postgresql.。.。
但對于分布式系統來講,除了支持分布式事務,還需要考慮全局快照,全局死鎖檢測等問題。Greenplum作為分布式Postgres的先驅者和成功代表,在Postgres分布式執行的諸多領域都擁有成熟、穩定的解決方案。因此,本次演講的作者Hubert借鑒Greenplum中全局死鎖檢測的原理和實現,探討了在Postgres Foreign Server Cluster中如何實現一個高效的分布式死鎖檢測系統。
單節點死鎖原理
首先,讓我們先來看一看單節點死鎖。下圖是一個單節點死鎖的示例。假設有兩個并發的Postgres會話,對應兩個Postgres的后端進程。最初,進程1持有鎖A,進程2持有鎖B。接著,進程1要獲取鎖B,而進程2要獲取鎖A。由于鎖通常在事務結束時才被釋放,因此,本地發生死鎖。
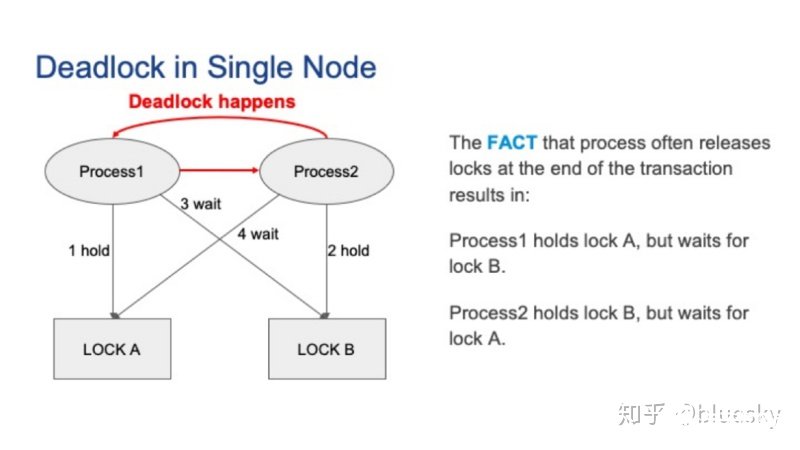
Postgresql 死鎖檢測器
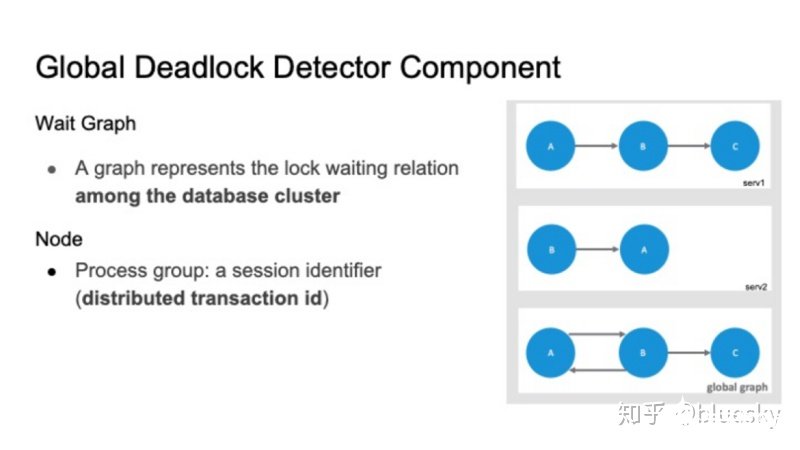
Postgres使用死鎖檢測器來處理死鎖問題。死鎖檢測器負責檢測死鎖并打破死鎖。檢測器使用等待圖(wait-for graph)來為不同后端進程之間的等待關系建模。圖的節點由進程標識符pid標識。節點A到節點B的邊表示節點A正在等待由節點B持有的鎖。
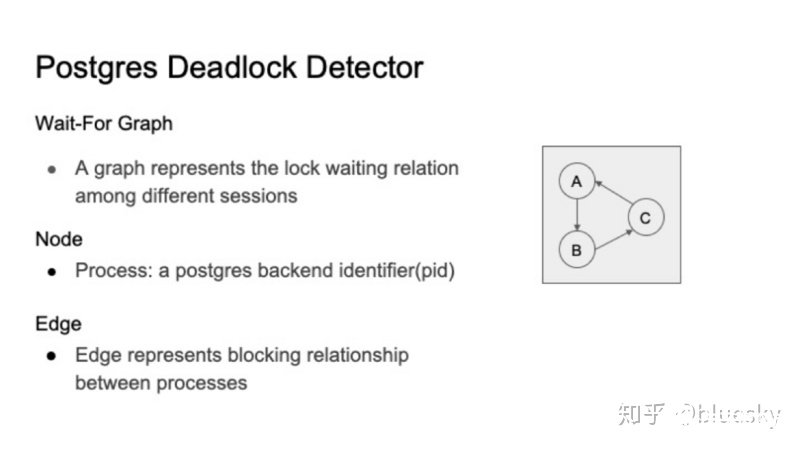
Postgresql死鎖檢測器的基本思想如下:
如果獲取鎖失敗,進程將進入睡眠模式。
SIGALARM處理程序將檢查PROCLOCK共享內存以構建等待圖。以當前進程為起點,檢查是否存在環。環意味著發生死鎖。當前進程會主動退出以打破死鎖。Postgres死鎖檢測器可以處理本地死鎖問題。
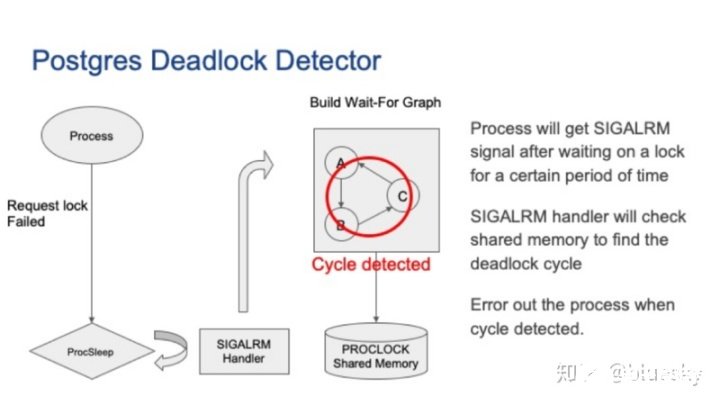
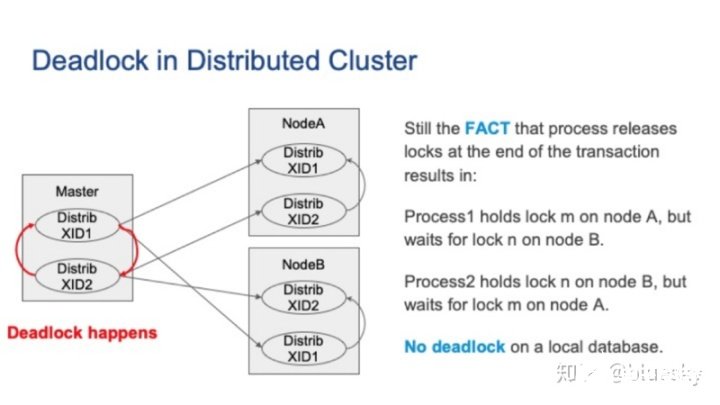
分布式集群中的死鎖
那么分布式集群中的死鎖又是怎么樣的?集群和單節點有什么區別?
讓我們從一個例子開始進行講解。下圖中,我們有包含一個主節點和兩個從節點的集群。假設我們有兩個并發的分布式事務。首先,分布式事務1在節點A上運行,然后事務2在節點B上運行。接著,事務1要在由事務2阻塞的節點B上運行,因此分布式事務1將被掛起。同時,假設事務2也嘗試在被本地事務1阻塞的節點A上運行,則分布式事務2也將掛起。這種情況下就會發生死鎖。
請注意,節點A或節點B上都沒有死鎖,但是死鎖確實出現了。從主節點的角度來看,這就是所謂的全局死鎖。
現在,讓我們看一個更具體的 Postgres Foreign Server Cluster示例。在下圖中,我們有兩個外部服務器,它們充當了在上一張圖中的從節點的角色。在主Postgres服務器上,我們創建一個分區表,在外部服務器A上部署一個分區,在外部服務器B上也部署一個分區。接著我們插入一些行,其中某些行在外部服務器A上,而其他行在外部服務器B上。
分布式系統中的全局死鎖檢測器
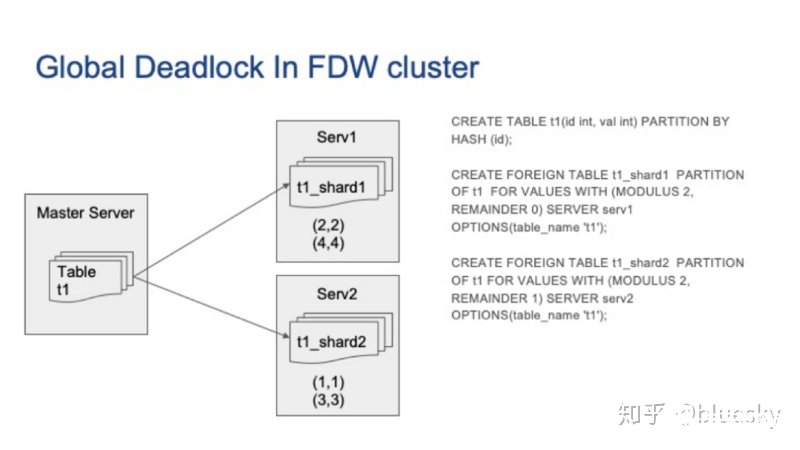
接著,我們在兩個并發會話上運行以下更新查詢,我們可以看到兩個會話都由于死鎖而掛起。但是每個外部服務器上的本地Postgres死鎖檢測器卻無法檢測到它們。
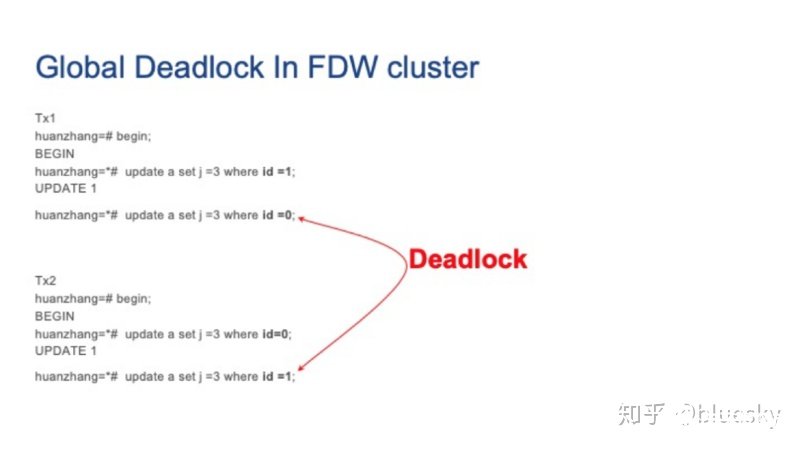
那么我們應該如何解決這種死鎖問題呢?答案就是——在分布式系統中引入全局死鎖檢測器。
在本演講中,我們將提出一個關于如何在Postgres fdw集群中實現全局死鎖檢測器的想法。但是這個概念很普遍,可以作為對其他Postgres集群實現的參考。實際上,我們參考了Greenplum全局死鎖檢測器的實現。首先,將全局死鎖檢測器實現為Postgres的Background Worker,使其更兼容Postgres,高可用等需求都可以通過Postgres的Background Worker來實現。其次,我們提出使用集中式檢測算法,這意味著我們只需要在主節點上啟動一個工作進程來收集事務等待關系并定期檢測死鎖。請注意,在Postgres的本地死鎖檢測器中,Postgres后端進程以自己為起點檢測死鎖。由于我們使用全局檢測器,因此必須執行完整的等待圖搜索以檢測死鎖。這需要一種更好的算法來檢測死鎖,因為Postgres的基于每個頂點的查找環算法并不高效。

全局死鎖檢測器模塊
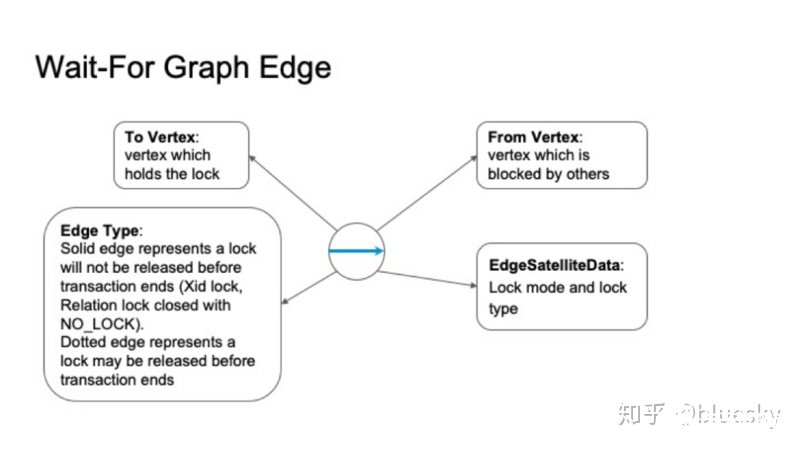
1. 等待圖
全局死鎖檢測器仍會使用等待圖(wait for graph)來為鎖等待關系進行建模。但與Postgres本地死鎖檢測有所不同的是,首先,等待圖是基于整個集群,因此我們需要將每個外部服務器上的本地等待圖進行合并,生成全局圖。此外,該等待圖中的節點并不再是單個Postgres進程ID,而是一個進程組,我們使用分布式事務ID來表示一個等待圖中節點。
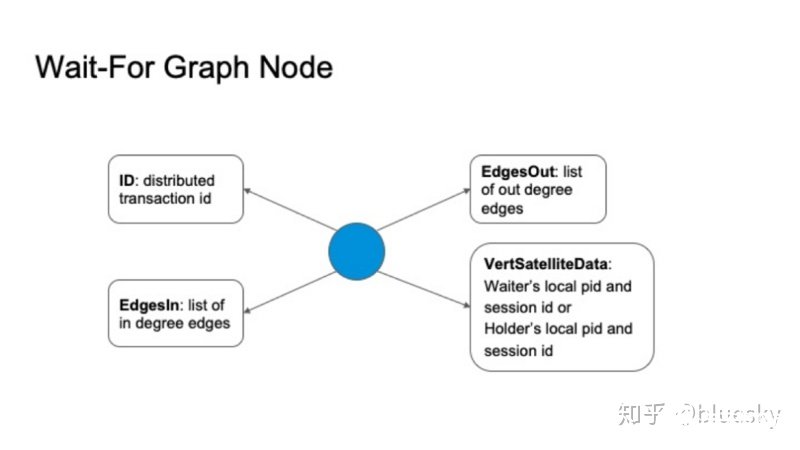
等待圖中的節點具有四個主要屬性:
分布式事務ID。
出度邊列表
入度邊列表
鎖等待者或持有者的pid和sessionid信息。
從節點出發的是等待鎖的,指向節點的是持鎖者。
2. 等待圖邊
等待圖中的邊表示任何節點上的鎖等待關系。邊同樣具有四個主要屬性:
出度節點,持有鎖。
入度節點,等待鎖。
邊類型:并非所有鎖在事務結束時都被釋放,例如,xidlock可以提前釋放,而無需等待分布式事務提交。我們將這種提前結束的等待關系使用虛邊表示。與之對應的是實邊,事務結束使才釋放的鎖等待關系。稍后,我們將展示全局死鎖檢測算法中對這兩種邊的不同處理。
鎖等待關系中的鎖模式和鎖類型。
全局死鎖檢測器工作原理
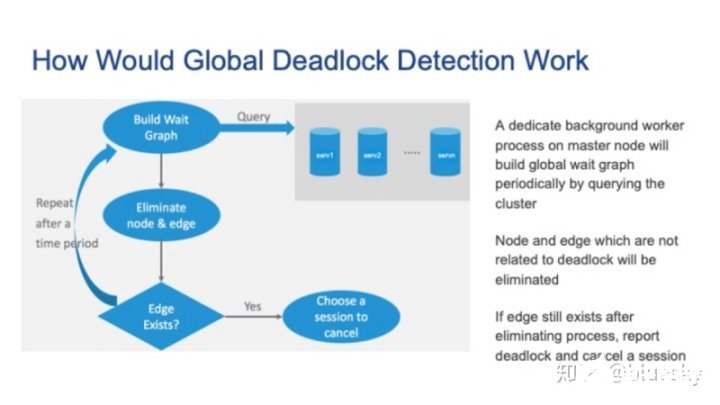
下面,通過全局等待圖,讓我們看看集群是如何處理全局死鎖的。
基本思路如下:主節點上的Background Worker進程通過查詢集群來定期建立全局等待圖。接著,刪除與死鎖無關的節點和邊。重復此過程,直到無法刪除任何節點或邊。如果仍然存在邊,則也存在全局死鎖,我們需要選擇一個會話來取消。
接下來,讓我們詳細介紹上述步驟。
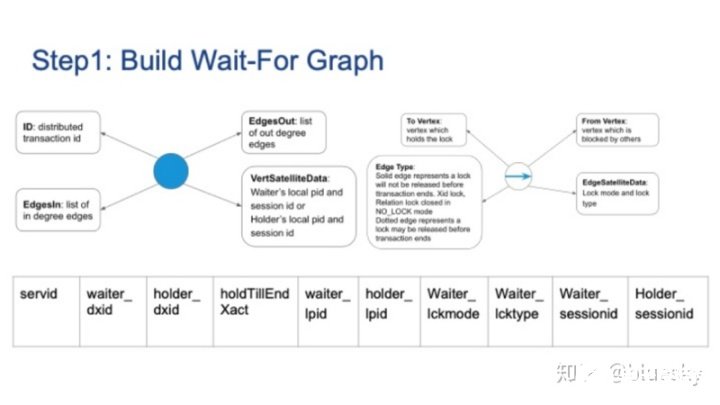
要構建等待圖,我們需要在每個Segment上收集鎖信息。這是一個兩階段過程。
1. 構建全局圖
首先,它使用Postgres內部函數GetLockStatusData從PROCLOCK共享內存中獲取鎖等待關系。我們需要擴展lockInstanceData結構,以涵蓋分布式事務ID和holdTillEndXact標志。之后,Background Worker進程需要從每個Foreign Server收集本地鎖信息,并形成一個全局鎖等待圖。

每個本地鎖等待圖包括以下屬性:Segment ID,鎖等待者和鎖持有者的分布式事務ID,標注其為實邊或虛邊,以及其他屬性,例如pid,sessionid,鎖類型和鎖模式,涵蓋了之前介紹的節點和邊的四個主要屬性。
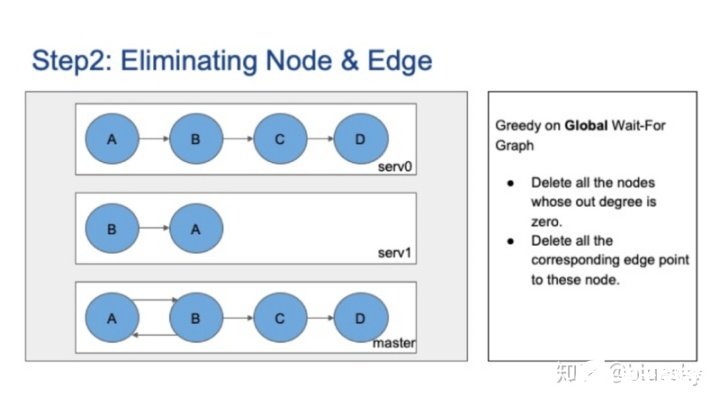
2. 消除節點和邊
下一步是消除不相關的節點和邊。我們使用啟發式貪婪算法。
有兩種策略。一種是對全局圖的貪婪,這意味著刪除所有出節點度為零的節點,并刪除其相應邊。這是一個示例,在全局圖上,節點D沒有出度,因此將其刪除。然后,節點C的出站度也更改為零,因此也刪除了節點C。
另一種策略是在局部圖上貪婪,這意味著找到每個局部圖上的所有虛邊。如果虛邊指向節點的出度為零,則該虛線邊表示的阻塞關系可能在事務結束之前消失,因此我們也可以消除這種虛邊。
下圖的示例中,節點C在全局圖上的出度為1,但是在Server0的局部圖上,出度為0,因此我們可以將從節點A到C的虛邊刪除。
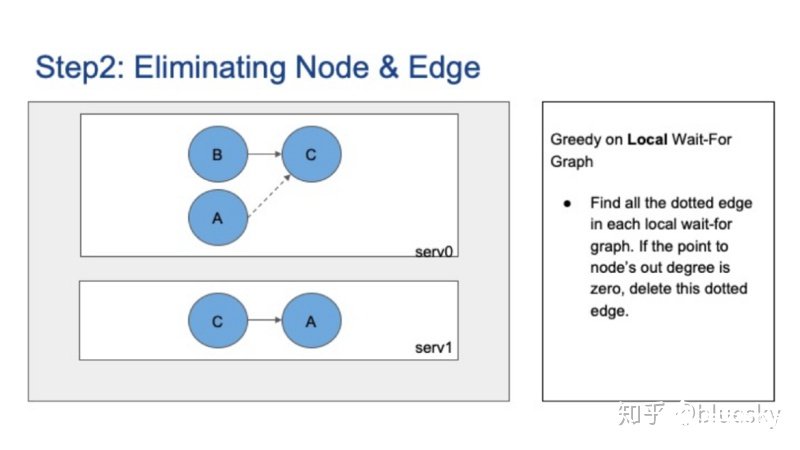
全局死鎖檢測器的最后一步是打破死鎖。集中式檢測器不同于Postgres本地死鎖檢測器,后者只能退出當前進程,前者可以根據策略選擇取消任何會話。通用策略包括取消最新的會話或基于CPU、內存等資源占用量的策略等等。
實例分析
至此,我們已經介紹了全局死鎖檢測器的概述和算法。最后,讓我們看看另外兩種實例,以便更好地了解全局死鎖檢測器的工作原理。
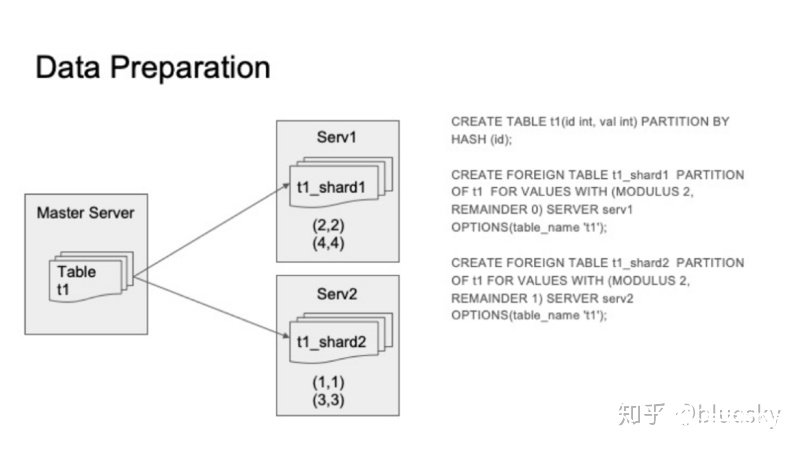
首先是數據準備工作,如下圖所示。
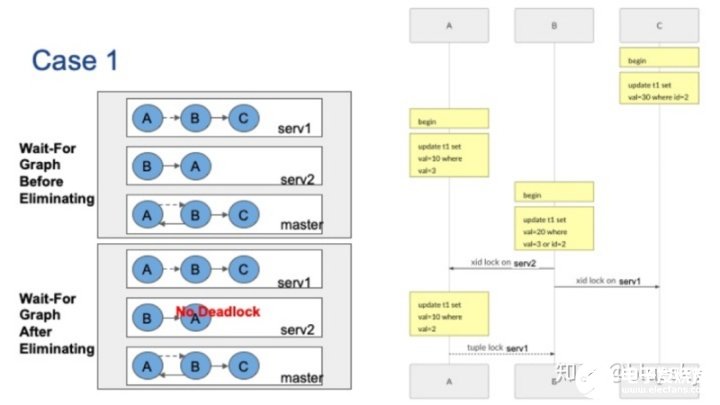
案例一
第一種例子中,有三個并發會話。會話C首先更新ID=2的元組,這將使server1上持有xid鎖。會話A更新val=3的元組,它將在server2上持有xid鎖。接著,會話B要更新val=3或id=2的元組,它將分別被server1和server2上的會話A和會話C阻塞。最后,會話A要更新server1上val=2的元組。
請注意,當會話B無法獲取server1上的xid鎖時,它將持有元組鎖,以確保在會話C釋放xid鎖之后可以拿到鎖。會話A將在元組鎖上被會話B阻塞。請注意,元組鎖在分布式事務結束之前就會被釋放,因此這是一個虛邊。原始的全局等待圖在左上角,可以看到全局等待圖存在循環。
現在,讓我們看看如何消除不相關的節點。首先,節點C的出度為零,我們可以刪除該節點和相應的邊。現在在Server1的本地等待圖上,指向B點的虛邊沒有出度,因此也可以刪除該虛邊。刪除虛邊后,節點A的出度變為零,可以刪除,最后也可以刪除節點B。沒有邊,因此在這種情況下沒有全局死鎖。
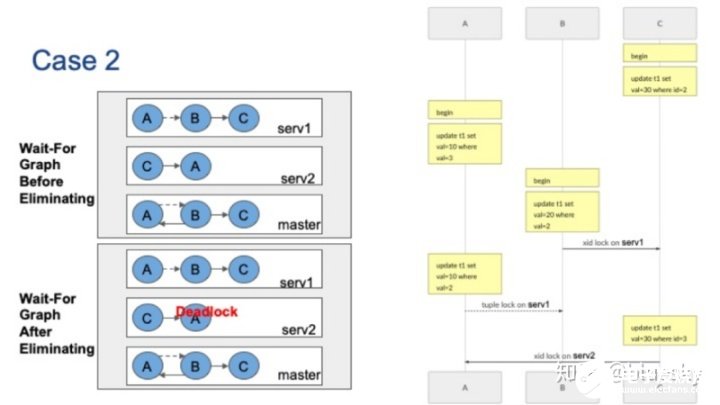
案例二
下圖的第二個例子中,包括三個并發會話。會話C首先將更新ID=2的元組,這將在server1上持有xid鎖。然后,會話A將更新val=3的元組,它將在server2上持有xid鎖。會話B要更新val=2的元組,它將被server1上的會話C阻止。
接著,會話A想要更新server1上val=2的元組。像上圖的案例1一樣,會話A在元組鎖上被會話B阻塞,并形成虛邊。最后,會話C要更新ID=3的元組,它將被Server2上持有xid鎖的會話A阻止。原始全局等待圖在左上角,全局等待圖同樣包含循環。
回想上一張圖,案例1的全局等待圖與案例2相同,唯一的不同是局部圖。
現在讓我們看看如何消除不相關的節點。首先,讓我們檢查全局圖:沒有出節點度數為零的節點,因此沒有可以刪除的節點。接下來,我們檢查局部圖上的虛邊。從節點A到節點B,我們有一條虛邊,但是節點B的出度不為零,因此無法刪除該虛邊。我們無法刪除任何節點或邊,因此在這種情況下消除失敗,全局死鎖存在。
從以上情況可以得出結論,即使全局等待圖相同,它們的全局死鎖檢測結果也會有所不同。
總結
以上就是本次PGCon演講的主要內容。回顧一下,本次演講首先討論Postgres本地死鎖檢測器的實現,并通過實例說明本地死鎖檢測器無法解決全局死鎖問題,并進一步提出了在Postgres Foreign Server Cluster中實現全局死鎖檢測的思路和需要注意的問題。
-
檢測器
+關注
關注
1文章
863瀏覽量
47679 -
建模
+關注
關注
1文章
304瀏覽量
60765 -
進程
+關注
關注
0文章
203瀏覽量
13960
發布評論請先 登錄
相關推薦
onsemi全局快門圖像傳感器—了解圖像傳感器的選型要點

PostgreSQL將不再支持MD5密碼
MySQL還能跟上PostgreSQL的步伐嗎

求助,是否有自帶timeout機制的EEPROM?
HarmonyOS實戰開發-全局狀態保留能力彈窗
你是不是也沒躲過這個坑?用了太多全局變量......

全局變量太多有哪些弊端?
縱觀全局:YOLO助力實時物體檢測原理及代碼
淺談MySQL常見死鎖場景






 工商網監
工商網監
評論