 一文閑談AI、Bi、大數據、數據科學、邊緣計算等基本概念
一文閑談AI、Bi、大數據、數據科學、邊緣計算等基本概念
01 數據
數據幾乎滲透到我們生活的每一個角落,從我們在手機中留下的數字足跡,到健康記錄,再到購物歷史,以及對資源(如能源)的使用情況。在當今這個數字世界里,脫離數字的生活雖然不是不可接受的,但也需要巨大的犧牲精神和不可思議的毅力才能忍受。
我們不僅是數據制造者,同時也是活躍的數據消費者,例如我們時常檢查自己的在線消費習慣,監測健身程序,或者查看自己的常旅客積分是否夠去加勒比度假,這些行為都是在消費數據。
但數據到底是什么?按最通用的形式來理解,數據就是被儲存起來以備日后使用的信息。最早記錄信息的方式可能是在動物骨頭上刻蝕符號。到了20世紀50年代,人們開始在磁帶上記錄數字信息,然后是打孔卡片,再后來是使用磁盤。現代數據處理開始的時間并不長,但已經奠定了我們如何收集、存儲、管理、使用信息的基礎。
直到最近,我們對那些無法計算的信息(例如,視頻和圖像信息)還只能進行分類處理。但近幾年來,通過大量的技術變革,無法存儲的數據類型變得越來越少了。事實上,存儲的信息,或者數據,就是以一種可用的編碼方式,為了我們可計算的目的而建立的真實世界的模型。
數據是真實世界中所發生事情的持續記錄或“模型”,這一事實是分析學的一個重要特征。被公認為“20世紀最偉大的統計學家之一”的喬治·鮑克斯(George Box)曾經說過:“所有的模型都是錯誤的,但有些模型是有用的。”
很多時候,我們在數據中發現一些沒有意義或者完全錯誤的東西。請記住,數據是從真實的物理世界轉化并抽象為代表真實世界的東西,即喬治所說的“模型”。就像機械速度計是測量速度的標準一樣(也是衡量速率的一個很好的替代物),這個模型(指機械速度計)實際上是測量輪胎的轉速,而不是速度。
總之,數據是存儲的信息,是所有分析的基礎。例如,在可視化分析中,我們利用可視化技術和交互界面對數據進行解析和推理,找出數據本身存在的規律。
02 分析
分析(analytics)可能是商業中使用得最多但卻最難理解的術語之一。對一些人來說,它是一種用來“把數據屈打成招”(找出數據中潛藏規律)的技術或技巧,或者僅僅是商業智能與數據倉庫的延伸;而對另外一些人來說,分析則是用于開發模型的統計、數學或定量方法。
Merriam-Webster字典稱分析是“一種邏輯分析的方法”。Dictionary.com字典將分析定義為“邏輯分析的科學”。不幸的是,兩種定義都直接使用了分析(analysis)這個詞的詞根,似乎存在循環解釋的邏輯錯誤。
分析(analysis)這個詞的起源可以追溯到16世紀80年代的中世紀拉丁語(anal-yticus)和希臘語(anal-ytiks),意思是“分解”(break up)或者“放松”(loosen)。我把分析(analytics)定義為一種解決數據驅動問題的結構化方法:通過對事實(數據)的仔細推敲,幫助我們解決問題的一套方法論。
關于分析的定義有很多爭論。就當前討論的問題而言,我將分析定義為:
一種全面的、基于數據驅動的解決問題的策略與方法。
我有意避免將分析定義為某個“過程”、某種“科學”或“學科”。相反,我將分析定義為一種全面的策略,正如讀者將在本書第二部分中看到的那樣,它是包含過程、規則、可交付物的最佳實踐。
分析通過使用邏輯、歸納推理、演繹推理、批判思維、定量方法(結合數據)等手段,來檢驗和分析現象,從而確定其本質特征。分析植根于科學方法,包括問題的識別和理解、理論生成、假設檢驗和結果交流。
歸納推理
當積累的證據被用來支持一個結論,但結論仍帶有一些不確定性的時候,就會用到歸納推理方法。也就是說,最終的結論有可能(存在一定概率)與給定前提不一致。通過歸納推理,我們基于具體的觀測或數據能夠做出廣泛的、一般意義上的概括和總結。
演繹推理
演繹推理基于某些一般案例提出論斷,然后依靠數據,使用統計推斷或實驗手段證明或證偽提出的論斷。例如,按照演繹推理方法,我們提出一個關于世界運動方式的基本理論,然后(應用數據)去檢驗我們提出的假設的正確性。
分析可以用來解決各種各樣的問題。例如,UPS公司應用分析結果而采取優化貨物運輸措施,節省了150多萬加侖(1加侖=3.785 41立方分米)的燃油,減少了14 000噸的二氧化碳排放量 ;克利夫蘭診所利用分析結果優化了手術室的運營時間安排。
有了這些成功案例,對于技術供應商(硬件和軟件)和其他不同支持者來說,“分析”毫無疑問都是極具吸引力的。當然,“分析”這個詞當前存在過度使用危險,這可以從人們把這個術語與其他詞的各種組合中看出。諸如:
大數據分析(big data analytics)
規范性分析(prescriptive analytics)
業務分析(business analytics)
操作分析(operational analytics)
高級分析(advanced analytics)
實時分析(real-time analytics)
邊緣或環境分析(edge or ambient analytics)
雖然以上這些組合與搭配在分析應用的類型和描述上具有獨特性,但也經常造成理解上的混亂,特別是對企業高管(如CXO層次高管)而言,技術供應商總是熱衷于提供最新的分析解決方案,試圖能解決他們的每一個業務痛點。
我的觀點(許多志同道合、理性思考的人也有與我相同的觀點)是,分析并不是一種技術,技術只是在分析活動中起到了推動和賦能作用的策略和方法。
分析通常也指能夠識別數據之間有業務意義的模式和關系的任何解決方案。分析被用于解析不同規模的、不同復雜程度的、結構化和非結構化的、定量或定性的數據,以便從中實現對特定問題的理解、預測或優化的明確目的。
所謂高級分析也是分析的子集,它使用復雜的分析技術來支持基于事實的決策過程,而且這種分析通常是以自動化或半自動化的方式開展的。
高級分析通常包括數據挖掘、計量經濟建模、預測、優化、預測建模、模擬、統計和文本挖掘等技術。
03 商業智能和報表
關于分析與商業智能的區別,幾乎沒有形成過共識。有些人將分析歸類為商業智能的一個子集,而另一些人則把它歸為完全不同的類別。我把商業智能(BI)定義為:
一種管理策略,用來建立一種更有結構性和更有效的決策方法……BI包括報表、查詢、聯機分析處理(OLAP)、儀表盤、記分卡甚至分析等常見要素。綜合性術語BI也可以指獲取、清理、集成和存儲數據的過程。
有些人會將分析和商業智能之間的區別歸納為兩個方面的不同:
所使用量化方法(即算法、數學、統計)的復雜度;
所產生結果是針對歷史已發生的還是未來將發生的。
也就是說,商業智能的重點是使用相對簡單的數學方法來對歷史數據進行展示和呈現,而分析則被認為是采用更復雜的計算邏輯,并且能夠預測一些特定問題、識別因果關系、確定最優解決方案的方法,有時也被用于指明需要采取的行動與措施。
大多數商業智能應用的局限性并不在于技術的限制,而在于分析的深度和為行動提供依據的真正洞察力。例如,告訴我已經發生了什么事情并不能幫助我決定如何行動以改變未來,這樣的結果往往是通過離線分析(offline analysis)得到的。
分析的真正責任是形成可行動的、可操作的洞察力,從而能夠幫助我們了解已經發生的事情(在什么地點發生,為什么會發生,在什么條件下發生),預測出未來可能發生什么,以及我們可以做什么來影響和優化未來的結果。
請注意,圖1-1中描述的BI儀表盤描述了有關過去的事實,如銷售、呼叫量、產品和賬戶,使你很容易獲得組織當前銷售狀態或活動情況的快照。
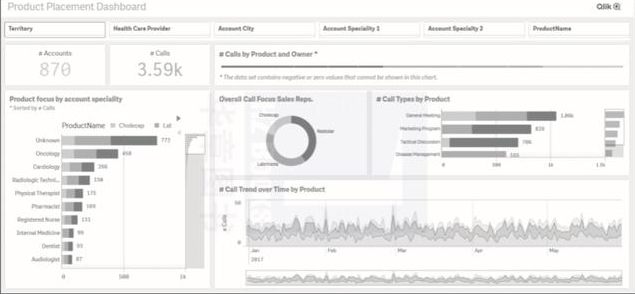
▲圖1-1 商業智能儀表盤
商業智能和它的近鄰“報表”,都是用來描述有關現象的信息展示技術,通常位于數據傳遞管道的尾部,在那里可以直觀地訪問數據和結果。而另一方面,分析則超越了對數據的描述,它真正理解了這個現象的內在規律,從而來預測、優化和預判未來應采取的適當行動。
從傳統上看,商業智能一直存在兩個缺點,這源于它們與這樣的事實有關:
BI通常專注于建立對過去已經發生事實的認識,因為它側重于度量和監視,而不是預測和優化;
其計量分析往往不夠復雜,無法建立足以產生精確洞察力的有意義的改變(雖然正確的報表或可視化展現也可以對改變產生影響,但還不夠精確)。
如果把商業智能與深入的“分析”恰當地結合在一起,而不僅僅停留在對事實的認識,它就更接近分析,但它又往往缺乏高級分析解決方案中經常用到的復雜統計、數學或者“機器學習”方法。
因此,我認為分析是商業智能總體框架內所包含的概念的一種自然演變。它更加強調充分開展必要的各種活動,以形成能促進行動的真知灼見。分析遠遠不止于在自助操作儀表盤或報表界面中所使用的、預先定義的可視化元素。
04 大數據
大數據(big data)是一種描述不和諧信息的方法,在將數據轉化為洞察力的過程中,組織必須處理這些難以處理的信息。1997年,Michael Cox和David Ellsworth首次使用了大數據這一表述,他們當時提到的“問題”如下:
可視化為計算機系統提供了一個有趣的挑戰:數據集通常相當大,占用了大量主內存、本地磁盤甚至遠程磁盤的容量。我們稱之為大數據問題。當數據集大到無法存放在主內存(核心存儲器),或者甚至無法存儲在本地磁盤上時,最常見的解決方案是擴充并獲取更多的資源。
將大數據視為一個概念,它突出了這樣一種挑戰:數據的規模和復雜性超出了傳統數據分析方法能夠處理的范圍。我們將大數據與傳統的“小”數據進行對比,包括其容量(我們擁有多少數據)、速度(產生與獲得數據的快慢)和多樣性(包括數字、文本、圖像、視頻等多種數據形態)。
如果大數據是用來描述當今信息復雜性的概念,那么分析就可以幫助我們以主動的方式(預測性和規范性)來分析復雜性,而不是以被動的方式(即商業智能的范疇)來應對。
05 數據科學
與大數據相比,定義數據科學顯得不是一件輕而易舉的工作,因為在數據科學的眾多定義中,很少發現一致的描述。關于數據科學意味著什么,以及它是否與分析完全不同,目前存在很多爭論。
還有一些人,甚至試圖通過討論數據科學家的工作來定義數據科學:數據科學家所需要的技能,他們所扮演的角色,他們所使用的工具和技術,他們工作的地方,以及他們的教育背景,等等。但這些并沒有對數據科學給出一個有意義的定義。
與其按照人(數據科學家)或他們所處理的問題來定義數據科學,不如將其定義如下:
數據科學是一門科學學科,它利用統計和數學等領域的定量方法以及現代技術,開發出用于發現模式、預測結果和為復雜問題找到最佳解決方案的算法。
數據科學和分析的區別在于,數據科學可以幫助甚至支持自動化實現對數據的分析,但是分析是一種以人為中心的策略,它充分利用各種工具,包括那些在數據科學中發現的工具,來理解事物現象之間的真正本質。
數據科學可能是這些概念中涉及面最廣泛的,因為它關系到處理“數據”的整個科學和實踐。我認為數據科學是由計算機科學家設計的分析學,但在實踐中,數據科學往往側重于對一般性宏觀問題的研究,而分析往往側重于解決特定行業或具體問題的挑戰。
06 邊緣(和環境)分析
在很多現代企業,分析是它們的一種核心業務活動,這些企業通過數據驅動和以人為中心的業務運營與管理流程實現了數據的大眾化(democratize data)。
而邊緣分析(edge analytics)一般指的是分布式分析,在這種場景下,分析被內置到一些機器或系統中,通過這種內置的方式,信息的生成與收集已經成為企業“下意識”的自主活動。
邊緣分析通常與智能設備相關,這種情況下,分析計算是在數據收集點(例如設備、傳感器、網絡交換機或其他設備)開展的,與傳統的數據管道傳輸方式(即采集數據、傳輸數據、清洗數據、集成數據、存儲數據)不同,邊緣分析把分析嵌入到收集數據的設備中完成或就近實現。
數據大眾化
所謂數據大眾化,指的是數據開放,使每個能夠而且應該能夠獲得數據的人都有權通過工具來探索獲取這些數據,而不是將數據局限于少數特權群體。
例如,傳統的信用卡欺詐檢測依賴于機器(例如讀卡器),并通過與授權“代理”的連接發送請求來驗證一個交易,算法需要在極短的時間內(百分之一毫秒)對此交易完成授權或打上欺詐標簽,最后,讀卡設備接收授權指令后完成或拒絕交易操作。在邊緣分析中,算法將運行在儀器本身上(比如帶有嵌入式分析的智能芯片讀卡器)。
邊緣分析通常與物聯網(IoT)聯系在一起。最近IDC在針對物聯網IoT未來視界(FutureScape)的一份報告中提出,到2018年,40%的物聯網數據將在網絡中產生數據的邊緣完成數據的存儲、處理、分析和響應。
隨著物聯網的發展,我們很可能會看到未來對所謂的“萬物分析”(Analytics of Things,AoT)有更多的關注,它指的是分析將給物聯網數據帶來獨特價值的機會。
環境分析(ambient analytics)是另一個相關的術語,它的名字意味著“分析無處不在”。就像房間的燈光或音響常常不被注意,但卻為舞臺構建了氛圍一樣,環境分析也會影響我們工作和娛樂的環境。
我們看到環境智能正在日常生活場景中發揮作用,比如檢測血糖水平和注射胰島素。同樣,當你回到住家附近時,家居自動化設備檢測到相應信息,會自動調整溫度和打開照明。環境分析超越了基于簡單規則的決策,它利用算法來決定合適的行動路線。
毫無疑問,邊緣和環境分析將繼續挑戰傳統的以人為中心的管理方式與流程,傳統管理方式下,使用分析結果(如對分析的理解、決策和采取的行動)以人為主,而在邊緣和環境分析中會有越來越多的(不需要人工介入的)自主決策與執行。
07 信息學
信息學(informatics)是信息技術和信息管理的交叉學科。在實踐中,信息學涉及用于數據存儲和檢索的處理技術。從本質上講,信息學討論信息是如何管理的,指的是支持流程化工作流的系統和數據生態系統,而不是對其中發現的數據進行分析。
在信息科學中經常談到的健康信息學,它專門用于保健醫療研究,是介于健康信息技術和健康信息管理之間的一種專業技術,它將信息技術、通信和保健融合起來,以提高病人護理的質量和安全性。它位于人、信息和技術三者交匯處的中心。
保健政策是指在一個社會中為實現特定的保健目標而采取的決定、計劃和行動。保健政策制定者希望看到醫療保健變得更經濟、更安全、更高質量,信息技術和健康信息技術往往是實現這一目標的重要手段。
事實上,其中一項最必不可少的工作是正確定位數據資源,使之能提供每個患者360度的完整健康狀況信息視圖,只有數據共享才能做到這一點(見圖1-2)。
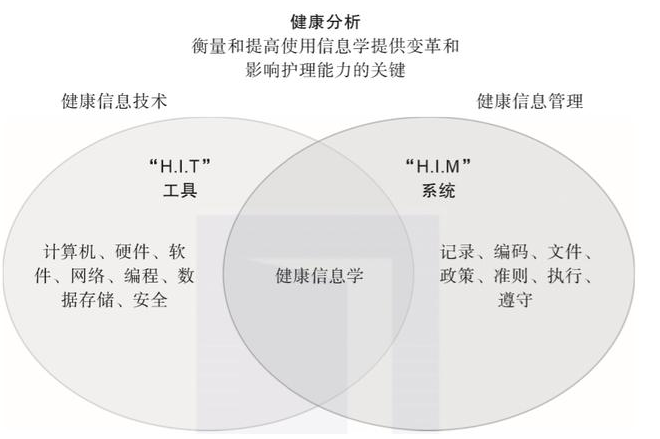
▲圖1-2 健康信息管理、健康信息技術和信息學之間的區別
分析集成了所有這些概念,并依賴于底層數據、支持技術和信息管理過程來實現這一目標。
08 人工智能與認知計算
人工智能(AI)是一門“讓計算機做需要人類智能才能做的事情的科學”。
人工智能和機器學習的區別在于,人工智能是指利用計算機完成模式的識別與探索這類“智能”工作的廣義概念,而機器學習是人工智能的子集,它主要指利用計算機從數據中學習的概念。
機器學習是人工智能的一個子集,它可以根據數據進行學習和預測,不是僅僅根據特定的一組規則或指令完成事先規劃好的操作,而是利用算法訓練來自主識別大量數據中的模式。
人工智能(和機器學習)可以在分析生命周期中使用,以支持發現和探索(例如,數據是如何構造的,存在什么模式等)。人工智能在分析中的應用通常以機器學習(如上文所述)或認知計算的形式出現。
認知計算是一種獨特的應用,它將人工智能和機器學習算法結合在一起,試圖復制(或模仿)人腦的行為。
認知計算系統被設計為像人一樣通過思考、推理和記憶等方式來解決問題。這種設計方法使認知計算系統具有一個優勢,使得它們能夠“隨著新數據的到來而學習和適應”并“探索和發現那些你永遠不會知道去問的東西”。
-
AI
+關注
關注
87文章
30763瀏覽量
268909 -
大數據
+關注
關注
64文章
8884瀏覽量
137409 -
邊緣計算
+關注
關注
22文章
3085瀏覽量
48904
發布評論請先 登錄
相關推薦
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
邊緣AI需求爆發,邊緣計算網關亟待革新
邊緣AI網關,將具備更強大的計算和學習能力

英特爾發布全新邊緣計算平臺,解決AI邊緣落地難題

邊緣計算網關與邊緣計算的融合之道






 工商網監
工商網監
評論