 如何避免在數據準備過程中的數據泄漏
如何避免在數據準備過程中的數據泄漏
數據準備是將原始數據轉換為適合建模的形式的過程。 原始的數據準備方法是在評估模型性能之前對整個數據集進行處理。這會導致數據泄漏的問題, 測試集中的數據信息會泄露到訓練集中。那么在對新數據進行預測時,我們會錯誤地估計模型性能。 為了避免數據泄漏,我們需要謹慎使用數據準備技術,同時也要根據所使用的模型評估方案靈活選擇,例如訓練測試集劃分或k折交叉驗證。 在本教程中,您將學習在評估機器學習模型時如何避免在數據準備過程中的數據泄漏。 完成本教程后,您將會知道:
應用于整個數據集的簡單的數據準備方法會導致數據泄漏,從而導致對模型性能的錯誤估計。
為了避免數據泄漏,數據準備應該只在訓練集中進行。
如何在Python中用訓練測試集劃分和k折交叉驗證實現數據準備而又不造成數據泄漏。在我的新書
(https://machinelearningmastery.com/data-preparation-for-machine-learning/)
中了解有關數據清理,特征選擇,數據轉換,降維以及更多內容,包含30個循序漸進的教程和完整的Python源代碼。
讓我們開始吧。 目錄 本教程分為三個部分: 1.原始數據準備方法存在的問題 2.用訓練集和測試集進行數據準備
用原始數據準備方法進行訓練-測試評估
用正確的數據準備方法進行訓練-測試評估
3 .用K折交叉驗證進行數據準備
用原始數據準備方法進行交叉驗證評估
用正確的數據準備方法進行交叉驗證評估
原始數據準備方法的問題 應用數據準備技術處理數據的方式很重要。 一種常見的方法是首先將一個或多個變換應用于整個數據集。然后將數據集分為訓練集和測試集,或使用k折交叉驗證來擬合并評估機器學習模型。 1.準備數據集 2.分割數據 3.評估模型 盡管這是一種常見的方法,但在大多數情況下很可能是不正確的。 在分割數據進行模型評估之前使用數據準備技術可能會導致數據泄漏, 進而可能導致錯誤評估模型的性能。 數據泄漏是指保留數據集(例如測試集或驗證數據集)中的信息出現在訓練數據集中,并被模型使用的問題。這種泄漏通常很小且微妙,但會對性能產生顯著影響。 ‘’…泄漏意味著信息會提供給模型,這給它做出更好的預測帶來了不真實的優勢。當測試數據泄漏到訓練集中時,或者將來的數據泄漏到過去時,可能會發生這種情況。當模型應用到現實世界中進行預測時,只要模型訪問了它不應該訪問的信息,就是泄漏。 —第93頁,機器學習的特征工程,2018年。” 將數據準備技術應用于整個數據集會發生數據泄漏。 數據泄漏的直接形式是指我們在測試數據集上訓練模型。而當前情況是數據泄漏的間接形式,是指訓練過程中,模型可以使用匯總統計方法捕獲到有關測試數據集的一些知識。對于初學者而言很難察覺到第二種類型的數據泄露。 “重采樣的另一個方面與信息泄漏的概念有關,信息泄漏是在訓練過程中(直接或間接)使用測試集數據。這可能會導致過于樂觀的結果,這些結果無法在將來的數據上復現。 —第55頁,特征工程與選擇,2019年。” 例如,在某些情況下我們要對數據進行歸一化,即將輸入變量縮放到0-1范圍。 當我們對輸入變量進行歸一化時,首先要計算每個變量的最大值和最小值, 并利用這些值去縮放變量. 然后將數據集分為訓練數據集和測試數據集,但是這樣的話訓練數據集中的樣本對測試數據集中的數據信息有所了解。數據已按全局最小值和最大值進行了縮放,因此,他們掌握了更多有關變量全局分布的信息。 幾乎所有的數據準備技術都會導致相同類型的泄漏。例如,標準化估計了域的平均值和標準差,以便縮放變量;甚至是估算缺失值的模型或統計方法也會從全部數據集中采樣來填充訓練數據集中的值。 解決方案很簡單。 數據準備工作只能在訓練數據集中進行。也就是說,任何用于數據準備工作的系數或模型都只能使用訓練數據集中的數據行。 一旦擬合完,就可以將數據準備算法或模型應用于訓練數據集和測試數據集。 1.分割數據。 2.在訓練數據集上進行數據準備。 3.將數據準備技術應用于訓練和測試數據集。 4.評估模型。 更普遍的是,僅在訓練數據集上進行整個建模工作來避免數據泄露。這可能包括數據轉換,還包括其他技術,例如特征選擇,降維,特征工程等等。這意味著所謂的“模型評估”實際上應稱為“建模過程評估”。 “為了使任何重采樣方案都能產生可泛化到新數據的性能估算,建模過程中必須包含可能顯著影響模型有效性的所有步驟。
—第54-55頁,特征工程與選擇,2019年。”
既然我們已經熟悉如何應用數據準備以避免數據泄漏,那么讓我們來看一些可行的示例。 準備訓練和測試數據集 在本節中,我們利用合成二進制分類數據集分出訓練集和測試集,并使用這兩個數據集評估邏輯回歸模型, 其中輸入變量已歸一化。 首先,讓我們定義合成數據集。 我們將使用make_classification()函數創建包含1000行數據和20個數值型特征的數據。下面的示例創建了數據集并總結了輸入和輸出變量數組的形狀。

運行這段代碼會得到一個數據集, 數據集的輸入部分有1000行20列, 20列對應20個輸入變量, 輸出變量包含1000個樣例對應輸入數據,每行一個值。

接下來我們要在縮放后的數據上評估我們的模型, 首先從原始或者說錯誤的方法開始。 用原始方法進行訓練集-測試集評估 原始方法首先對整個數據集應用數據準備方法,其次分割數據集,最后評估模型。 我們可以使用MinMaxScaler類對輸入變量進行歸一化,該類首先使用默認配置將數據縮放到0-1范圍,然后調用fit_transform()函數將變換擬合到數據集并同步應用于數據集。得到歸一化的輸入變量,其中數組中的每一列都分別進行過歸一化(例如,計算出了自己的最小值和最大值)。

下一步,我們使用train_test_split函數將數據集分成訓練集和測試集, 其中67%的數據用作訓練集,剩下的33%用作測試集。

通過LogisticRegression 類定義邏輯回歸算法,使用默認配置, 并擬合訓練數據集。

擬合模型可以對測試集的輸入數據做出預測,然后我們可以將預測值與真實值進行比較,并計算分類準確度得分。

把上述代碼結合在一起,下面列出了完整的示例。
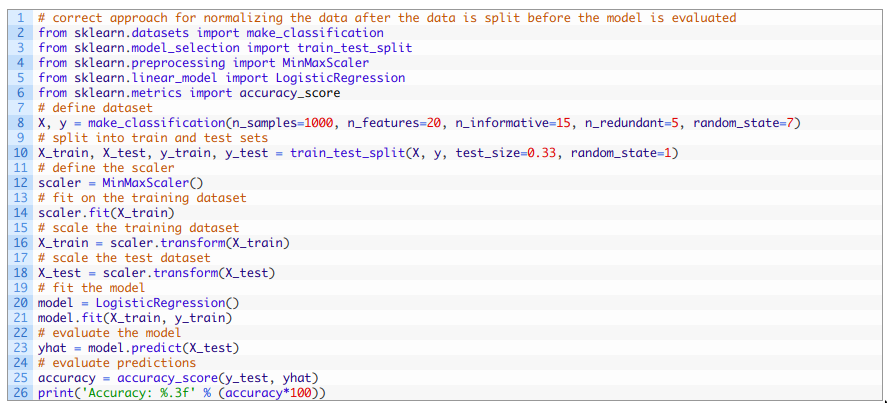
運行上述代碼, 首先會將數據歸一化, 然后把數據分成測試集和訓練集,最后擬合并評估模型。 由于學習算法和評估程序的隨機性,您的具體結果可能會有所不同。 在本例中, 模型在測試集上的準確率為84.848%

我們已經知道上述代碼中存在數據泄露的問題, 所以模型的準確率估算是有誤差的。 接下來,讓我們來學習如何正確的進行數據準備以避免數據泄露。 用正確的數據準備方法進行訓練集-測試集評估 利用訓練集-測試集分割評估來執行數據準備的正確方法是在訓練集上擬合數據準備方法,然后將變換應用于訓練集和測試集。

這要求我們首先將數據分為訓練集和測試集。 然后,我們可以定義MinMaxScaler并在訓練集上調用fit()函數,然后在訓練集和測試集上應用transform()函數來歸一化這兩個數據集。

我們只用了訓練集而非整個數據集中的數據來對每個輸入變量計算最大值和最小值, 這樣就可以避免數據泄露的風險。 然后可以按照之前的評估過程對模型評估。 整合之后, 完整代碼如下:
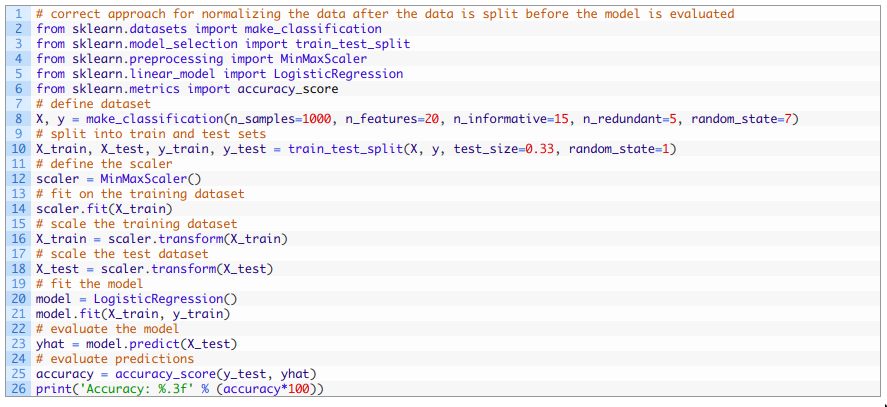
運行示例會將數據分為訓練集和測試集,對數據進行正確的歸一化,然后擬合并評估模型。 由于學習算法和評估程序的隨機性,您的具體結果可能會有所不同。 在本例中,我們可以看到該模型在測試集上預測準確率約為85.455%,這比上一節中由于數據泄漏達到84.848%的準確性更高。 我們預期數據泄漏會導致對模型性能的錯誤估計,并以為數據泄漏會樂觀估計,例如有更好的性能。然而在示例中,我們可以看到數據泄漏導致性能更差了。這可能是由于預測任務的難度。

用K折交叉驗證進行數據準備 在本節中,我們將在合成的二分類數據集上使用K折交叉驗證評估邏輯回歸模型, 其中輸入變量均已歸一化。 您可能還記得k折交叉驗證涉及到將數據集分成k個不重疊的數據組。然后我們只用一組數據作為測試集, 其余的數據都作為訓練集對模型進行訓練。將此過程重復K次,以便每組數據都有機會用作保留測試集。最后輸出所有評估結果的均值。 k折交叉驗證過程通常比訓練測試集劃分更可靠地估計了模型性能,但由于反復擬合和評估,它在計算成本上更加昂貴。 我們首先來看一下使用k折交叉驗證的原始數據準備。 用K折交叉驗證進行原始數據準備 具有交叉驗證的原始數據準備首先要對數據進行變換,然后再進行交叉驗證過程。 我們將使用上一節中準備的合成數據集并直接將數據標準化。

首先要定義k折交叉驗證步驟。我們將使用重復分層的10折交叉驗證,這是分類問題的最佳實踐。重復是指整個交叉驗證過程要重復多次,在本例中要重復三次。分層意味著每組樣本各類別樣本的比例與原始數據集中相同。我們將使用k = 10的10折交叉驗證。 我們可以使用RepeatedStratifiedKFold(設置三次重復以及10折)來實現上述方案,然后使用cross_val_score()函數執行該過程,傳入定義好的模型,交叉驗證對象和要計算的度量(在本例中使用的是準確率 )。

然后,我們可以記錄所有重復和折疊的平均準確度。 綜上,下面列出了使用帶有數據泄漏的數據準備進行交叉驗證評估模型的完整示例。
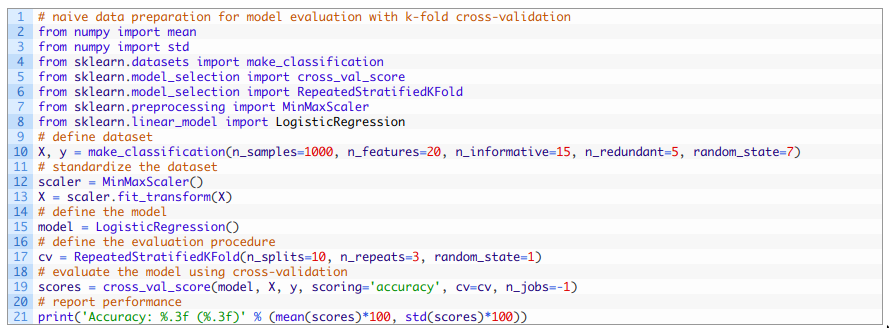
運行上述代碼, 首先對數據進行歸一化,然后使用重復分層交叉驗證對模型進行評估。 由于學習算法和評估程序的隨機性,您的具體結果可能會有所不同。 在本例中,我們可以看到該模型達到了約85.300%的估計準確度,由于數據準備過程中存在數據泄漏,我們知道該估計準確度是不正確的。

接下來,讓我們看看如何使用交叉驗證評估模型同時避免數據泄漏。 具有正確數據準備的交叉驗證評估 使用交叉驗證時,沒有數據泄漏的數據準備工作更具挑戰性。 它要求在訓練集上進行數據準備,并在交叉驗證過程中將其應用于訓練集和測試集,例如行的折疊組。 我們可以通過定義一個建模流程來實現此目的,在要擬合和評估的模型中該流程定義了要執行的數據準備步驟的順序和結束條件。 “ 為了提供可靠的方法,我們應該限制自己僅在訓練集上開發一系列預處理技術,然后將這些技術應用于將來的數據(包括測試集)。
—第55頁,特征工程與選擇,2019年。”
評估過程從錯誤地僅評估模型變為正確地將模型和整個數據準備流程作為一個整體單元一起評估。 這可以使用Pipeline類來實現。 此類使用一個包含定義流程的步驟的列表。列表中的每個步驟都是一個包含兩個元素的元組。第一個元素是步驟的名稱(字符串),第二個元素是步驟的配置對象,例如變換或模型。盡管我們可以在序列中使用任意數量的轉換,但是僅在最后一步才應用到模型。

之后我們把配置好的對象傳入cross_val_score()函數進行評估。

綜上所述,下面列出了使用交叉驗證時正確執行數據準備而不會造成數據泄漏的完整示例。
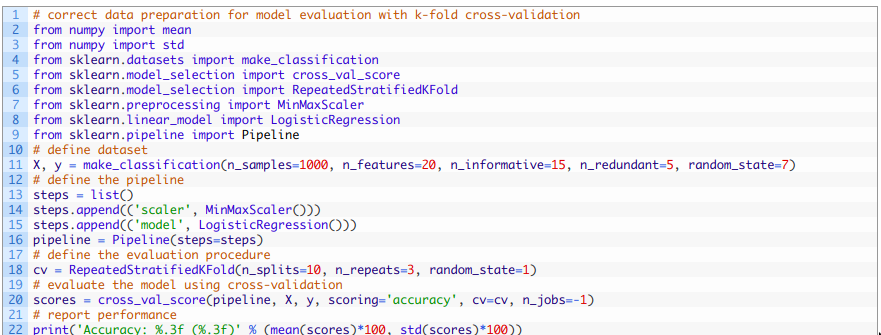
運行該示例可在評估過程進行交叉驗證時正確地歸一化數據,以避免數據泄漏。 由于學習算法和評估程序的隨機性,您的具體結果可能會有所不同。 本例中,我們可以看到該模型的估計準確性約為85.433%,而數據泄漏方法的準確性約為85.300%。 與上一節中的訓練測試集劃分示例一樣,消除數據泄露帶來了性能上的一點提高, 雖然直覺上我們會認為它應該會帶來下降, 以為數據泄漏會導致對模型性能的樂觀估計。但是,這些示例清楚地表明了數據泄漏確實會影響模型性能的估計以及在拆分數據后通過正確執行數據準備來糾正數據泄漏的方法。

總結 在本教程中,您學習了評估機器學習模型時如何避免在數據準備期間出現數據泄露的問題。 具體來說,您了解到:
直接將數據準備方法應用于整個數據集會導致數據泄漏,從而導致對模型性能的錯誤估計。
為了避免數據泄漏,必須僅在訓練集中進行數據準備。
如何在Python中為訓練集-測試集分割和k折交叉驗證實現數據準備而又不會造成數據泄漏。
-
python
+關注
關注
56文章
4797瀏覽量
84745 -
數據集
+關注
關注
4文章
1208瀏覽量
24719
原文標題:準備數據時如何避免數據泄漏
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論