 數據科學的工具數不勝數——你應該選擇哪一個?
數據科學的工具數不勝數——你應該選擇哪一個?
概述
數據科學的工具數不勝數——你應該選擇哪一個?
這里列出了超過20種的數據科學工具,滿足數據科學生命周期不同階段的需求。
引言
執行數據科學任務的最佳工具有哪些?作為數據科學新手,你應該選擇哪些工具? 我相信在你的數據科學之旅的某些時刻中你已經問過(或搜索過)這些問題。這些問題是合理的!雖然在這個行業中并不缺乏數據科學工具,但是為你的數據科學旅程和生涯做出一個選擇可能是一個棘手的決定。
我們得承認——數據科學的范圍龐雜,每一個領域要求處理數據的方式各有不同,這讓許多分析家/數據庫科學家陷入困惑。而如果你是一位商業領袖,你將要選擇你和你的公司所使用的工具,這很關鍵,因為這些工具會產生長期的影響。 同樣地,問題是你應該選擇哪種數據科學工具呢? 在本文中,我將通過羅列出數據科學領域廣泛使用的工具并細分它們的用途和優勢,來幫你解決這些困惑。所以,讓我們開始吧!
目錄
深入大數據– 處理大數據的工具
體量
種類
速度
數據科學的工具
報告和商業智能
預測建模和機器學習
大數據的數據科學工具
為了真正了解大數據背后的深刻意義,我們需要了解給大數據下定義所的基本原理。他們被稱為大數據的3V而廣為人知。
體量
種類
速度
處理大數據體量的工具
顧名思義,體量是指數據的規模和數量。要了解我在說的數據規模,你需要知道,世界上超過90%的數據是在最近兩年內創建的! 十年來,隨著數據量的增加,該技術也變得越來越好。計算和存儲成本的降低使收集和存儲大量數據變得更加容易。 數據體量定義了它是否符合大數據的條件。 當我們的數據范圍在1Gb到10Gb左右時,傳統的數據科學工具就可以很好地工作。那么這些工具有哪些呢?
Microsoft Excel–Excel是處理少量數據的最簡單,最受歡迎的工具。它支持的最大行數只剛剛超過一百萬,一張表一次最多只能處理16,380列。當數據量很大時,這些根本不夠用。
Microsoft Excel:
https://www.analyticsvidhya.com/blog/category/excel/?utm_source=blog&utm_medium=22-tools-data-science-machine-learning
Microsoft Access –它是Microsoft流行的用于數據存儲的工具。使用此工具可以平穩順暢地處理高達2Gb的較小數據庫,但超過這個數字,Access會開始崩潰。
SQL – SQL是自1970年代以來最流行的數據管理系統之一。幾十年來,它一直是主要的數據庫解決方案。SQL仍然很流行,但有一個缺點——隨著數據庫的不斷增長,很難對其進行擴展。
到目前為止我們已經介紹了一些基本工具。現在該放大招了!如果你的數據大于10Gb,甚至超過1Tb+,那么需要使用我在下面提到的工具:
Hadoop –它是一個開源的分布式框架,用于管理大數據的數據處理和存儲。當你從零開始構建機器學習項目時,很可能會使用此工具。
Hive –它是建立在Hadoop之上的數據倉庫。Hive提供了一個類似于SQL的接口來查詢存儲在與Hadoop集成的各種數據庫和文件系統中的數據。
處理大數據種類的工具
數據種類是指存在的不同類型的數據。數據類型可以是以下之一:結構化和非結構化數據。 讓我們看一下不同數據類型的示例:
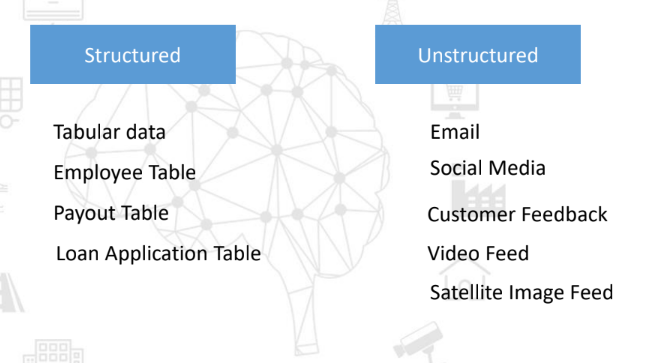
花一點時間去觀察這些示例,并且將它們與你的真實數據關聯起來。 你可能在結構化數據中觀察到,這種類型的數據有固定的順序和結構,而非結構化數據相反,這些示例并不遵循任何趨勢或者模式。例如,顧客反饋在長度、情感和其他方面有所不同。另外,這類數據巨大并且種類繁多。 處理這類數據可能非常具有挑戰性,那么市場上用于管理和處理這些不同數據類型的數據科學工具有哪些呢? 兩個最常見的數據庫是SQL和NoSQL。在NoSQL出現前,SQL多年來一直是市場主導者。
SQL的一些例子是Oracle,MySQL,SQLite,而NoSQL由諸如MongoDB,Cassandra等流行的數據庫組成。這些NoSQL數據庫由于具有擴展和處理動態數據的能力而被廣泛地應用。
處理大數據速度的工具
第三個,也是最后一個V代表了速度。這是捕獲數據時的速度,包括實時和非實時數據。我們在這里將主要討論實時數據。 我們周圍有許多捕獲和處理實時數據的示例。最復雜的是自動駕駛汽車收集的傳感器數據。想象一下,在自動駕駛汽車中,汽車必須同時動態地收集和處理有關車道、與其他車輛的距離等數據! 其他正在收集的實時數據的例子包括:
閉路電視
股票交易
信用卡交易欺詐檢測
網絡數據——社交媒體(Facebook、Twitter等)
“你知道嗎? 在紐約證券交易所的每個交易時段中,都會生成超過1TB的數據!” 現在,讓我們來看看處理實時數據的一些常用數據科學工具:
Apache Kafka – Kafka是Apache的開源工具。它用于創建實時數據管道。Kafka的一些優點在于——它具有容錯性、速度很快,并且被大量機構投入生產使用。
Apache Storm – Apache的該工具幾乎可用于所有編程語言。它每秒可處理多達100萬個元組,并具有高度的可擴展性。對于高數據速率來說,這是個好工具。
Amazon Kinesis – 亞馬遜提供的此工具類似于Kafka,但需要付費。然而,它提供的是開箱即用的解決方案,這使其成為組織機構的強勢的備選方案。
Apache Flink – Flink是Apache另一種可用于實時數據的工具。Flink的優點在于它的高性能、容錯能力和有效的內存管理。
現在,我們已經掌握了通常用于處理大數據的各種工具,接下來將介紹使用高級機器學習技術和算法來利用數據的部分。
廣泛使用的數據科學工具
如果你要建立一個全新的數據科學項目,那么腦海中會浮現很多問題,這與你的水平無關——無論你是數據科學家,數據分析師,項目經理還是高級數據科學主管,都是如此。 你將面對的一些問題是: ?在數據科學的不同領域中應該使用哪些工具? ?應該購買這些工具的許可證還是選擇開源工具?等等。 在本節中,我們將根據不同領域討論行業中使用的一些受歡迎的數據科學工具。 數據科學本身就是一個廣義術語,它由各種不同的領域組成,每個領域都有它自己的業務重要性和復雜性,正如下圖所示:
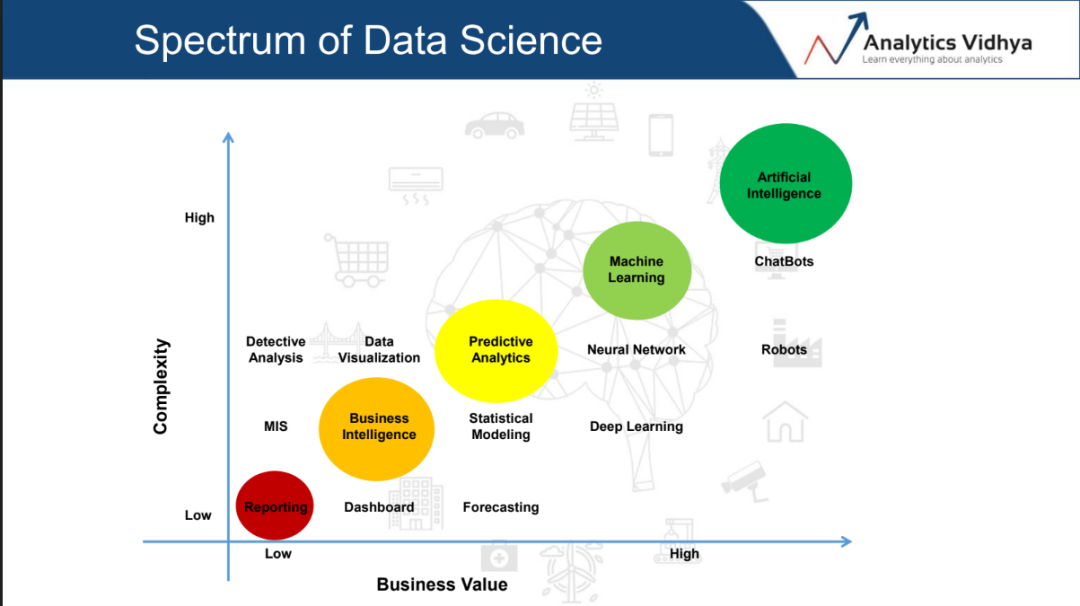
數據科學的范圍包含了各種領域,上圖表示了這些領域的相對復雜性和它們提供的業務價值。讓我們討論一下以上頻譜中顯示的每一個點。
報告和商業智能
讓我們從這個范圍的底端開始。報告和商業智能使一個機構能夠識別出數據的趨勢和模式,從而制定關鍵的戰略決策。這種分析的類型包括MIS、數據分析和儀表板。 這些領域中常用的工具有:
Excel – 它提供了多種選擇,包括了數據透視表和圖表,使你可以快速分析數據。簡而言之,它是數據科學/分析工具中的“瑞士軍刀”。
QlikView – 您只需單擊幾下即可合并,搜索,可視化和分析所有數據資源。這是一種易于學習的直觀的工具,因此非常受歡迎。
Tableau – 它是當今市場上最受歡迎的數據可視化工具之一。它能夠處理大量數據,甚至提供類似于Excel的計算功能和參數。Tableau因其整潔的儀表板和故事界面而倍受贊譽.
https://courses.analyticsvidhya.com/courses/tableau-2-0?utm_source=blog&utm_medium=22-tools-data-science-machine-learning
Microstrategy – 它是另一個BI工具,支持儀表板、自動分發和其他關鍵數據分析任務。
PowerBI – 它是商業智能(BI)領域中的Microsoft產品。PowerBI旨在與Microsoft技術進行集成。因此,如果你的組織有Sharepoint或SQL數據庫用戶,那么你和你的團隊將會喜歡這個工具。
Google Analytics – 想知道Google Analytics如何進入此名單的嗎?嗯……數字營銷在業務轉型中起著重要作用,沒有比它更好的工具可以用來分析你的數字化工作。
預測分析和機器學習工具
順著前面那個圖再往上走,其復雜性和商業價值也變高了!這是大多數數據科學家賴以生存的領域。你將要解決的問題類型是統計建模,預測,神經網絡和深度學習。 讓我們了解一些該領域的常用工具:
Python – 由于其易用性,靈活性和開源特性,Python是當今行業數據科學中最主要的語言之一。它已經在ML社區中迅速普及并被廣泛接受。
https://courses.analyticsvidhya.com/courses/introduction-to-data-science?utm_source=blog&utm_medium=22-tools-data-science-machine-learning
R – 它是數據科學中另一種非常常用且受人尊敬的語言。R有一個蓬勃發展且被極大支持的社區,附帶了許多軟件包和庫,支持大多數的機器學習任務。
Apache Spark – Spark由加州大學伯克利分校于2010年開源,此后已成為最大的大數據社區之一。它被稱為大數據分析的“瑞士軍刀”,因為它具有多種優勢,例如靈活性、速度、計算能力等。
Julia – 它是一種即將到來的語言,被捧為Python的繼承者。目前它仍處于起步階段,觀察其在未來的表現將會是一件有趣的事。
Jupyter Notebooks – 這些筆記本廣泛用于Python編程。盡管它主要用于Python,但它也支持其他語言,例如Julia,R等。
到目前為止,我們討論的工具都是真正的開源工具。你無需支付費用或購買任何額外的許可證。它們擁有活躍的社區,可以定期維護和發布更新。 現在,我們將看一些在某些特定行業中通用的收費工具:
SAS – 這是一個非常受歡迎且功能強大的工具。在銀行和金融部門中被普遍使用。它的使用在美國運通,摩根大通,西格瑪,蘇格蘭皇家銀行等私人組織中占有很高的份額。
SPSS – SPSS是“社會科學統計軟件包”的縮寫,在2009年被IBM收購。它提供高級統計分析、龐大的機器學習算法庫、文本分析等。
Matlab – Matlab在組織機構的領域里確實被低估了,但在學術界和研究部門中得到了廣泛的使用。最近相較于Python,R和SAS,Matlab已經陣地失守,但是大學(尤其在美國)仍在使用Matlab教授許多本科課程。
深度學習的通用框架
深度學習需要大量的計算資源,并且需要特殊的框架才能有效地利用這些資源。因此,你很可能需要GPU或TPU。 讓我們看看本節中用于深度學習的一些框架。
TensorFlow – 它很容易成為當今行業中使用最廣泛的工具。Google可能與此有關!
PyTorch – 這種超級靈活的深度學習框架正在成為TensorFlow的強勢競爭對手。PyTorch最近受到一些關注,它的開發者是Facebook的研究人員。
Keras和Caffe是廣泛用于構建深度學習應用程序的其他框架。
人工智能工具
AutoML的時代就在這里。如果還沒有聽說過這些工具,那么這是一個自我學習的好機會!作為數據科學家,你很可能會在不久的將來與他們合作。
列舉一些最受歡迎的AutoML工具,包括AutoKeras,Google Cloud AutoML,IBM Watson,DataRobot,H20的無人駕駛AI和亞馬遜的Lex。AutoML有望成為AI / ML社區中的下一個大事件。它旨在消除或減少技術性,以便商業領導者可以使用它來制定戰略決策。 這些工具將推動整個數據分析流程自動化!
尾注
我們已經討論了數據收集引擎以及完成檢索、處理和存儲,這一整個流水線所需的工具。數據科學的眾多領域中每個領域都有自己的一套工具和框架。 選擇數據科學工具通常取決于你的個人選擇、你的領域或項目,當然也取決于你的機構。 在評論中讓我知道你喜歡使用的最喜歡的數據科學工具或框架!
-
機器學習
+關注
關注
66文章
8422瀏覽量
132710 -
大數據
+關注
關注
64文章
8894瀏覽量
137477 -
數據科學
+關注
關注
0文章
165瀏覽量
10070
發布評論請先 登錄
相關推薦
TLV320ADC3101使用的時候ADC工作的順序是怎么樣的?是ADC三個通道輪流打開輪流使用ADC嗎?
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
freertos和rtthread哪一個更好
數據選擇器是時序邏輯電路嗎
ESP32-S3-Korvo-2 voip使用的是哪一個microphone?
Ardunio IDE如何選擇ESP32板類型?
ESP-IDF4.2.2兩個路徑下的結構&內容一樣,如何選擇?
stm32f746-disco怎么添加外置FLASH?如何選擇?
STM32F429是有雙BANK的,BFB2如何設置從哪一個BANK啟動?
Psoc4 4247LQI483如何判斷產生的中斷是由兩個比較器中的哪一個輸出的上升沿觸發的呢?
ACEMAGIC S1測評:一款有屏幕+雙網口的迷你主機





 工商網監
工商網監
評論