 深度圖像實時檢測識別系統對比
深度圖像實時檢測識別系統對比
重磅干貨,第一時間送達
一. R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation
技術路線:selective search + CNN + SVMs
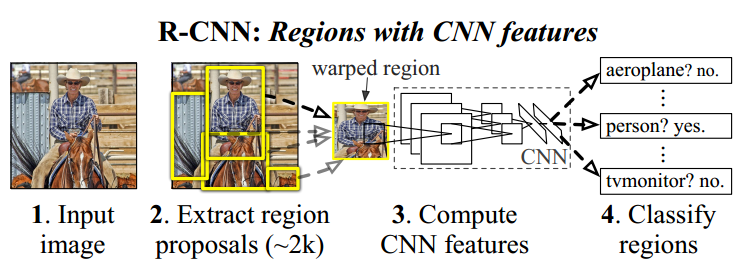
Step1:候選框提取(selectivesearch)
訓練:給定一張圖片,利用seletive search方法從中提取出2000個候選框。由于候選框大小不一,考慮到后續CNN要求輸入的圖片大小統一,將2000個候選框全部resize到227*227分辨率(為了避免圖像扭曲嚴重,中間可以采取一些技巧減少圖像扭曲)。
測試:給定一張圖片,利用seletive search方法從中提取出2000個候選框。由于候選框大小不一,考慮到后續CNN要求輸入的圖片大小統一,將2000個候選框全部resize到227*227分辨率(為了避免圖像扭曲嚴重,中間可以采取一些技巧減少圖像扭曲)。
Step2:特征提取(CNN)
訓練:提取特征的CNN模型需要預先訓練得到。訓練CNN模型時,對訓練數據標定要求比較寬松,即SS方法提取的proposal只包含部分目標區域時,我們也將該proposal標定為特定物體類別。這樣做的主要原因在于,CNN訓練需要大規模的數據,如果標定要求極其嚴格(即只有完全包含目標區域且不屬于目標的區域不能超過一個小的閾值),那么用于CNN訓練的樣本數量會很少。因此,寬松標定條件下訓練得到的CNN模型只能用于特征提取。
測試:得到統一分辨率227*227的proposal后,帶入訓練得到的CNN模型,最后一個全連接層的輸出結果---4096*1維度向量即用于最終測試的特征。
Step3:分類器(SVMs)
訓練:對于所有proposal進行嚴格的標定(可以這樣理解,當且僅當一個候選框完全包含ground truth區域且不屬于ground truth部分不超過e.g,候選框區域的5%時認為該候選框標定結果為目標,否則位背景),然后將所有proposal經過CNN處理得到的特征和SVM新標定結果輸入到SVMs分類器進行訓練得到分類器預測模型。
測試:對于一副測試圖像,提取得到的2000個proposal經過CNN特征提取后輸入到SVM分類器預測模型中,可以給出特定類別評分結果。
結果生成:得到SVMs對于所有Proposal的評分結果,將一些分數較低的proposal去掉后,剩下的proposal中會出現候選框相交的情況。采用非極大值抑制技術,對于相交的兩個框或若干個框,找到最能代表最終檢測結果的候選框(非極大值抑制方法可以參考:http://blog.csdn.net/pb09013037/article/details/45477591)
R-CNN需要對SS提取得到的每個proposal進行一次前向CNN實現特征提取,因此計算量很大,無法實時。此外,由于全連接層的存在,需要嚴格保證輸入的proposal最終resize到相同尺度大小,這在一定程度造成圖像畸變,影響最終結果。
二. SPP-Net : Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
傳統CNN和SPP-Net流程對比如下圖所示(引自http://www.image-net.org/challenges/LSVRC/2014/slides/sppnet_ilsvrc2014.pdf)
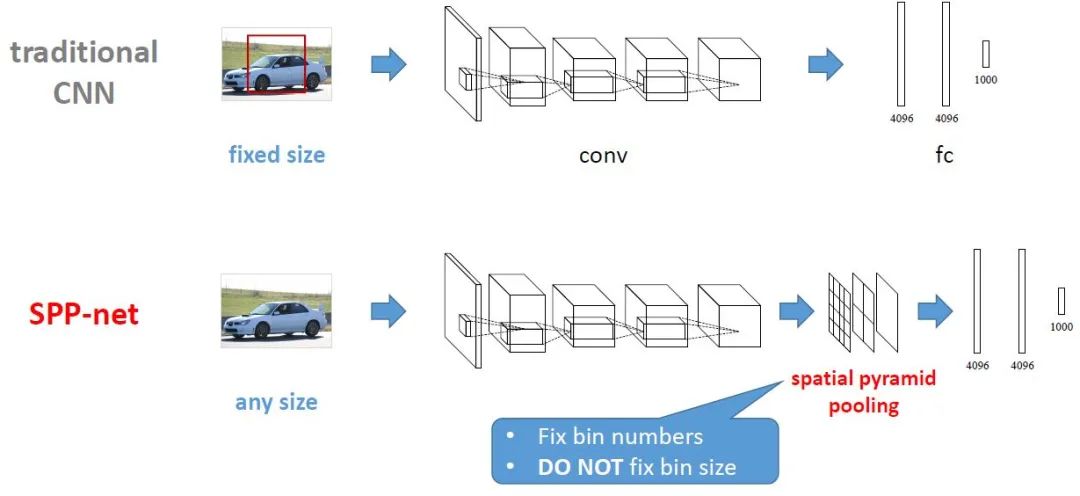
SPP-net具有以下特點:
1.傳統CNN網絡中,卷積層對輸入圖像大小不作特別要求,但全連接層要求輸入圖像具有統一尺寸大小。因此,在R-CNN中,對于selective search方法提出的不同大小的proposal需要先通過Crop操作或Wrap操作將proposal區域裁剪為統一大小,然后用CNN提取proposal特征。相比之下,SPP-net在最后一個卷積層與其后的全連接層之間添加了一個SPP(spatial pyramid pooling)layer,從而避免對propsal進行Crop或Warp操作。總而言之,SPP-layer適用于不同尺寸的輸入圖像,通過SPP-layer對最后一個卷積層特征進行pool操作并產生固定大小feature map,進而匹配后續的全連接層。
2.由于SPP-net支持不同尺寸輸入圖像,因此SPP-net提取得到的圖像特征具有更好的尺度不變性,降低了訓練過程中的過擬合可能性。
3.R-CNN在訓練和測試是需要對每一個圖像中每一個proposal進行一遍CNN前向特征提取,如果是2000個propsal,需要2000次前向CNN特征提取。但SPP-net只需要進行一次前向CNN特征提取,即對整圖進行CNN特征提取,得到最后一個卷積層的feature map,然后采用SPP-layer根據空間對應關系得到相應proposal的特征。SPP-net速度可以比R-CNN速度快24~102倍,且準確率比R-CNN更高(下圖引自SPP-net原作論文,可以看到SPP-net中spp-layer前有5個卷積層,第5個卷積層的輸出特征在位置上可以對應到原來的圖像,例如第一個圖中左下角車輪在其conv5的圖中顯示為“^”的激活區域,因此基于此特性,SPP-net只需要對整圖進行一遍前向卷積,在得到的conv5特征后,然后用SPP-net分別提取相應proposal的特征)。

SPP-Layer原理:
在RNN中,conv5后是pool5;在SPP-net中,用SPP-layer替代原來的pool5,其目標是為了使不同大小輸入圖像在經過SPP-Layer后得到的特征向量長度相同。其原理如圖如下所示
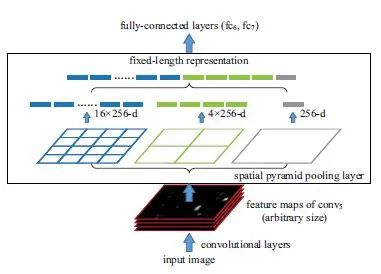
SPP與金字塔pooling類似,即我們先確定最終pooling得到的featuremap大小,例如4*4 bins,3*3 bins,2*2 bins,1*1 bins。那么我們已知conv5輸出的featuremap大小(例如,256個13*13的feature map).那么,對于一個13*13的feature map,我們可以通過spatial pyramid pooling (SPP)的方式得到輸出結果:當window=ceil(13/4)=4, stride=floor(13/4)=3,可以得到的4*4 bins;當window=ceil(13/3)=5, stride=floor(13/3)=4,可以得到的3*3 bins;當window=ceil(13/2)=7, stride=floor(13/2)=6,可以得到的2*2 bins;當window=ceil(13/1)=13, stride=floor(13/1)=13,可以得到的1*1 bins.因此SPP-layer后的輸出是256*(4*4+3*3+2*2+1*1)=256*30長度的向量。不難看出,SPP的關鍵實現在于通過conv5輸出的feature map寬高和SPP目標輸出bin的寬高計算spatial pyramid pooling中不同分辨率Bins對應的pooling window和pool stride尺寸。
原作者在訓練時采用兩種不同的方式,即1.采用相同尺寸的圖像訓練SPP-net 2.采用不同尺寸的圖像訓練SPP-net。實驗結果表明:使用不同尺寸輸入圖像訓練得到的SPP-Net效果更好。
SPP-Net +SVM訓練:
采用selective search可以提取到一系列proposals,由于已經訓練完成SPP-Net,那么我們先將整圖代入到SPP-Net中,得到的conv5的輸出。接下來,區別于R-CNN,新方法不需要對不同尺寸的proposals進行Crop或Wrap,直接根據proposal在圖中的相對位置關系計算得到proposal在整圖conv5輸出中的映射輸出結果。這樣,對于2000個proposal,我們事實上從conv1--->conv5只做了一遍前向,然后進行2000次conv5 featuremap的集合映射,再通過SPP-Layer,就可以得到的2000組長度相同的SPP-Layer輸出向量,進而通過全連接層生成最終2000個proposal的卷積神經網絡特征。接下來就和R-CNN類似,訓練SVMs時對于所有proposal進行嚴格的標定(可以這樣理解,當且僅當一個候選框完全包含ground truth區域且不屬于ground truth部分不超過e.g,候選框區域的5%時認為該候選框標定結果為目標,否則位背景),然后將所有proposal經過CNN處理得到的特征和SVM新標定結果輸入到SVMs分類器進行訓練得到分類器預測模型。
當然,如果覺得SVM訓練很麻煩,可以直接在SPP-Net后再加一個softmax層,用好的標定結果去訓練最后的softmax層參數。
三. Fast-R-CNN
基于R-CNN和SPP-Net思想,RBG提出了Fast-R-CNN算法。如果選用VGG16網絡進行特征提取,在訓練階段,Fast-R-CNN的速度相比RCNN和SPP-Net可以分別提升9倍和3倍;在測試階段,Fast-R-CNN的速度相比RCNN和SPP-Net可以分別提升213倍和10倍。
R-CNN和SPP-Net缺點:
1.R-CNN和SPP-Net的訓練過程類似,分多個階段進行,實現過程較復雜。這兩種方法首先選用Selective Search方法提取proposals,然后用CNN實現特征提取,最后基于SVMs算法訓練分類器,在此基礎上還可以進一步學習檢測目標的boulding box。
2.R-CNN和SPP-Net的時間成本和空間代價較高。SPP-Net在特征提取階段只需要對整圖做一遍前向CNN計算,然后通過空間映射方式計算得到每一個proposal相應的CNN特征;區別于前者,RCNN在特征提取階段對每一個proposal均需要做一遍前向CNN計算,考慮到proposal數量較多(~2000個),因此RCNN特征提取的時間成本很高。R-CNN和SPP-Net用于訓練SVMs分類器的特征需要提前保存在磁盤,考慮到2000個proposal的CNN特征總量還是比較大,因此造成空間代價較高。
3.R-CNN檢測速度很慢。RCNN在特征提取階段對每一個proposal均需要做一遍前向CNN計算,如果用VGG進行特征提取,處理一幅圖像的所有proposal需要47s。
4.特征提取CNN的訓練和SVMs分類器的訓練在時間上是先后順序,兩者的訓練方式獨立,因此SVMs的訓練Loss無法更新SPP-Layer之前的卷積層參數,因此即使采用更深的CNN網絡進行特征提取,也無法保證SVMs分類器的準確率一定能夠提升。
Fast-R-CNN亮點:
1.Fast-R-CNN檢測效果優于R-CNN和SPP-Net
2.訓練方式簡單,基于多任務Loss,不需要SVM訓練分類器。
3.Fast-R-CNN可以更新所有層的網絡參數(采用ROI Layer將不再需要使用SVM分類器,從而可以實現整個網絡端到端訓練)。
4.不需要將特征緩存到磁盤。
Fast-R-CNN架構:
Fast-R-CNN的架構如下圖所示(https://github.com/rbgirshick/fast-rcnn/blob/master/models/VGG16/train.prototxt,可以參考此鏈接理解網絡模型):輸入一幅圖像和Selective Search方法生成的一系列Proposals,通過一系列卷積層和Pooling層生成feature map,然后用RoI(region of ineterst)層處理最后一個卷積層得到的feature map為每一個proposal生成一個定長的特征向量roi_pool5。RoI層的輸出roi_pool5接著輸入到全連接層產生最終用于多任務學習的特征并用于計算多任務Loss。全連接輸出包括兩個分支:1.SoftMax Loss:計算K+1類的分類Loss函數,其中K表示K個目標類別,1表示背景;2.Regression Loss:即K+1的分類結果相應的Proposal的Bounding Box四個角點坐標值。最終將所有結果通過非極大抑制處理產生最終的目標檢測和識別結果。
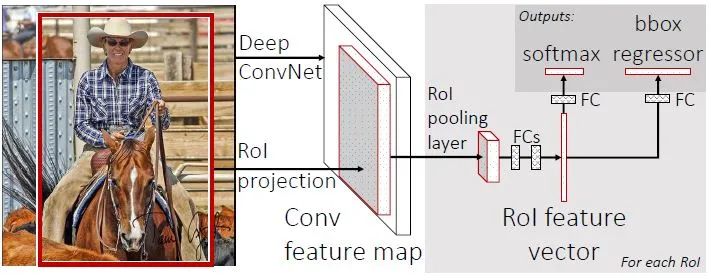
3.1 RoI Pooling Layer
事實上,RoI Pooling Layer是SPP-Layer的簡化形式。SPP-Layer是空間金字塔Pooling層,包括不同的尺度;RoI Layer只包含一種尺度,如論文中所述7*7。這樣對于RoI Layer的輸入(r,c,h,w),RoI Layer首先產生7*7個r*c*(h/7)*(w/7)的Block(塊),然后用Max-Pool方式求出每一個Block的最大值,這樣RoI Layer的輸出是r*c*7*7。
ROIs Pooling顧名思義,是Pooling層的一種,而且是針對RoIs的Pooling,他的特點是輸入特征圖尺寸不固定,但是輸出特征圖尺寸固定;
什么是ROI呢?
ROI是Region of Interest的簡寫,指的是在“特征圖上的框”;
1)在Fast RCNN中, RoI是指Selective Search完成后得到的“候選框”在特征圖上的映射,如下圖所示;
2)在Faster RCNN中,候選框是經過RPN產生的,然后再把各個“候選框”映射到特征圖上,得到RoIs。
3.2 預訓練網絡初始化
RBG復用了VGG訓練ImageNet得到的網絡模型,即VGG16模型以初始化Fast-R-CNN中RoI Layer以前的所有層。Fast R-CNN的網絡結構整體可以總結如下:13個convolution layers + 4個pooling layers+RoI layer+2個fc layer+兩個parrel層(即SoftmaxLoss layer和SmoothL1Loss layer)。在Fast R-CNN中,原來VGG16中第5個pooling layer被新的ROI layer替換掉。
3.3 Finetuning for detection
3.3.1 fast r-cnn在網絡訓練階段采用了一些trick,每個minibatch是由N幅圖片(N=2)中提取得到的R個proposal(R=128)組成的。這種minibatch的構造方式比從128張不同圖片中提取1個proposal的構造方式快64倍。雖然minibatch的構造速度加快,但也在一定程度上造成收斂速度減慢。此外,fast-r-cnn摒棄了之前svm訓練分類器的方式,而是選用softmax classifer和bounding-box regressors聯合訓練的方式更新cnn網絡所有層參數。注意:在每2張圖中選取128個proposals時,需要嚴格保證至少25%的正樣本類(proposals與groundtruth的IoU超過0.5),剩下的可全部視作背景類。在訓練網絡模型時,不需要任何其他形式的數據擴增操作。
3.3.2 multi-task loss:fast r-cnn包括兩個同等水平的sub-layer,分別用于classification和regression。其中,softmax loss對應于classification,smoothL1Loss對應于regression. 兩種Loss的權重比例為1:1
3.3.3 SGD hyer-parameters:用于softmax分類任務和bounding-box回歸的fc層參數用標準差介于0.01~0.001之間的高斯分布初始化。
3.4 Truncated SVD快速檢測
在檢測段,RBG使用truncated SVD優化較大的FC層,這樣RoI數目較大時檢測端速度會得到的加速。
Fast-R-CNN實驗結論:
1.multi-task loss訓練方式能提高算法準確度
2.multi-scale圖像訓練fast r-cnn相比較single-scale圖像訓練相比對mAP的提升幅度很小,但是卻增加了很高的時間成本。因此,綜合考慮訓練時間和mAP,作者建議直接用single尺度的圖像訓練fast-r-cnn。
3.用于訓練的圖像越多,訓練得到的模型準確率也會越高。
4.SoftmaxLoss訓練方式比SVMs訓練得到的結果略好一點,因此無法證明SoftmaxLoss在效果上一定比svm強,但是簡化了訓練流程,無需分步驟訓練模型。
5.proposal并不是提取的越多效果越好,太多proposal反而導致mAP下降。
四. Faster-R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
在之前介紹的Fast-R-CNN中,第一步需要先使用Selective Search方法提取圖像中的proposals。基于CPU實現的Selective Search提取一幅圖像的所有Proposals需要約2s的時間。在不計入proposal提取情況下,Fast-R-CNN基本可以實時進行目標檢測。但是,如果從端到端的角度考慮,顯然proposal提取成為影響端到端算法性能的瓶頸。目前最新的EdgeBoxes算法雖然在一定程度提高了候選框提取的準確率和效率,但是處理一幅圖像仍然需要0.2s。因此,Ren Shaoqing提出新的Faster-R-CNN算法,該算法引入了RPN網絡(Region Proposal Network)提取proposals。RPN網絡是一個全卷積神經網絡,通過共享卷積層特征可以實現proposal的提取,RPN提取一幅像的proposal只需要10ms.
Faster-R-CNN算法由兩大模塊組成:1.PRN候選框提取模塊 2.Fast R-CNN檢測模塊。其中,RPN是全卷積神經網絡,用于提取候選框;Fast R-CNN基于RPN提取的proposal檢測并識別proposal中的目標。
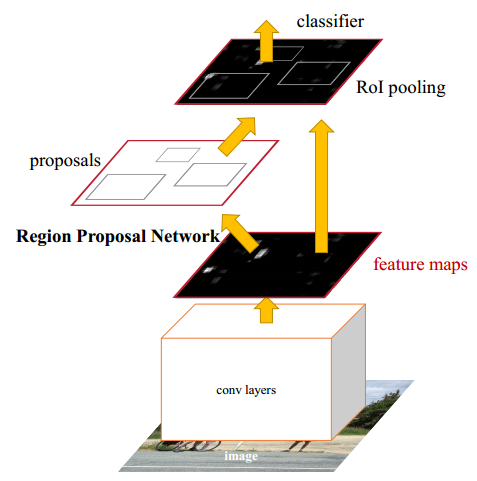
4.1 Region Proposal Network (RPN)
RPN網絡的輸入可以是任意大小(但還是有最小分辨率要求的,例如VGG是228*228)的圖片。如果用VGG16進行特征提取,那么RPN網絡的組成形式可以表示為VGG16+RPN。
VGG16:參考https://github.com/rbgirshick/py-faster-rcnn/blob/master/models/pascal_voc/VGG16/faster_rcnn_end2end/train.prototxt,可以看出VGG16中用于特征提取的部分是13個卷積層(conv1_1---->conv5.3),不包括pool5及pool5后的網絡層次結構。
RPN:RPN是作者重點介紹的一種網絡,如下圖所示。RPN的實現方式:在conv5-3的卷積feature map上用一個n*n的滑窗(論文中作者選用了n=3,即3*3的滑窗)生成一個長度為256(對應于ZF網絡)或512(對應于VGG網絡)維長度的全連接特征。然后在這個256維或512維的特征后產生兩個分支的全連接層:1.reg-layer,用于預測proposal的中心錨點對應的proposal的坐標x,y和寬高w,h;2.cls-layer,用于判定該proposal是前景還是背景。sliding window的處理方式保證reg-layer和cls-layer關聯了conv5-3的全部特征空間。事實上,作者用全連接層實現方式介紹RPN層實現容易幫助我們理解這一過程,但在實現時作者選用了卷積層實現全連接層的功能。個人理解:全連接層本來就是特殊的卷積層,如果產生256或512維的fc特征,事實上可以用Num_out=256或512, kernel_size=3*3, stride=1的卷積層實現conv5-3到第一個全連接特征的映射。然后再用兩個Num_out分別為2*9=18和4*9=36,kernel_size=1*1,stride=1的卷積層實現上一層特征到兩個分支cls層和reg層的特征映射。注意:這里2*9中的2指cls層的分類結果包括前后背景兩類,4*9的4表示一個Proposal的中心點坐標x,y和寬高w,h四個參數。采用卷積的方式實現全連接處理并不會減少參數的數量,但是使得輸入圖像的尺寸可以更加靈活。在RPN網絡中,我們需要重點理解其中的anchors概念,Loss fucntions計算方式和RPN層訓練數據生成的具體細節。
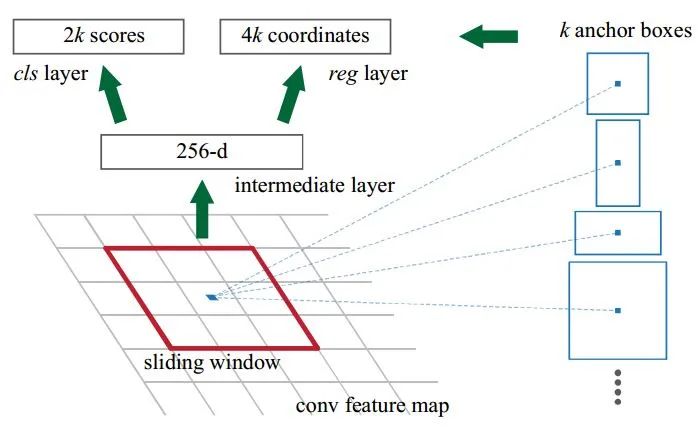
Anchors:字面上可以理解為錨點,位于之前提到的n*n的sliding window的中心處。對于一個sliding window,我們可以同時預測多個proposal,假定有k個。k個proposal即k個reference boxes,每一個reference box又可以用一個scale,一個aspect_ratio和sliding window中的錨點唯一確定。所以,我們在后面說一個anchor,你就理解成一個anchor box 或一個reference box.作者在論文中定義k=9,即3種scales和3種aspect_ratio確定出當前sliding window位置處對應的9個reference boxes, 4*k個reg-layer的輸出和2*k個cls-layer的score輸出。對于一幅W*H的feature map,對應W*H*k個錨點。所有的錨點都具有尺度不變性。
Loss functions:在計算Loss值之前,作者設置了anchors的標定方法。正樣本標定規則:1.如果Anchor對應的reference box與ground truth的IoU值最大,標記為正樣本;2.如果Anchor對應的reference box與ground truth的IoU>0.7,標記為正樣本。事實上,采用第2個規則基本上可以找到足夠的正樣本,但是對于一些極端情況,例如所有的Anchor對應的reference box與groud truth的IoU不大于0.7,可以采用第一種規則生成。負樣本標定規則:如果Anchor對應的reference box與ground truth的IoU<0.3,標記為負樣本。剩下的既不是正樣本也不是負樣本,不用于最終訓練。訓練RPN的Loss是有classification loss (即softmax loss)和regression loss (即L1 loss)按一定比重組成的。計算softmax loss需要的是anchors對應的groundtruth標定結果和預測結果,計算regression loss需要三組信息:1.預測框,即RPN網絡預測出的proposal的中心位置坐標x,y和寬高w,h;2.錨點reference box:之前的9個錨點對應9個不同scale和aspect_ratio的reference boxes,每一個reference boxes都有一個中心點位置坐標x_a,y_a和寬高w_a,h_a。3.ground truth:標定的框也對應一個中心點位置坐標x*,y*和寬高w*,h*。因此計算regression loss和總Loss方式如下:
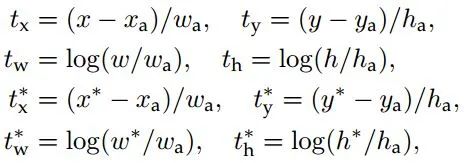
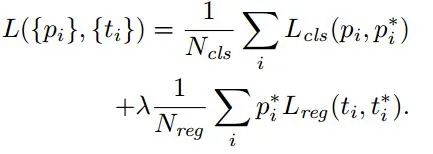
RPN訓練設置:在訓練RPN時,一個Mini-batch是由一幅圖像中任意選取的256個proposal組成的,其中正負樣本的比例為1:1。如果正樣本不足128,則多用一些負樣本以滿足有256個Proposal可以用于訓練,反之亦然。訓練RPN時,與VGG共有的層參數可以直接拷貝經ImageNet訓練得到的模型中的參數;剩下沒有的層參數用標準差=0.01的高斯分布初始化。
4.2 RPN與Faster-R-CNN特征共享
RPN在提取得到proposals后,作者選擇使用Fast-R-CNN實現最終目標的檢測和識別。RPN和Fast-R-CNN共用了13個VGG的卷積層,顯然將這兩個網絡完全孤立訓練不是明智的選擇,作者采用交替訓練階段卷積層特征共享:
交替訓練(Alternating training): Step1:訓練RPN;Step2:用RPN提取得到的proposal訓練Fast R-CNN;Step3:用Faster R-CNN初始化RPN網絡中共用的卷積層。迭代執行Step1,2,3,直到訓練結束為止。論文中采用的就是這種訓練方式,注意:第一次迭代時,用ImageNet得到的模型初始化RPN和Fast-R-CNN中卷積層的參數;從第二次迭代開始,訓練RPN時,用Fast-R-CNN的共享卷積層參數初始化RPN中的共享卷積層參數,然后只Fine-tune不共享的卷積層和其他層的相應參數。訓練Fast-RCNN時,保持其與RPN共享的卷積層參數不變,只Fine-tune不共享的層對應的參數。這樣就可以實現兩個網絡卷積層特征共享訓練。相應的網絡模型請參考https://github.com/rbgirshick/py-faster-rcnn/tree/master/models/pascal_voc/VGG16/faster_rcnn_alt_opt
4.3 深度挖掘
1.由于Selective Search提取得到的Proposal尺度不一,因此Fast-RCNN或SPP-Net生成的RoI也是尺度不一,最后分別用RoI Pooling Layer或SPP-Layer處理得到固定尺寸金字塔特征,在這一過程中,回歸最終proposal的坐標網絡的權重事實上共享了整個FeatureMap,因此其訓練的網絡精度也會更高。但是,RPN方式提取的ROI由k個錨點生成,具有k種不同分辨率,因此在訓練過程中學習到了k種獨立的回歸方式。這種方式并沒有共享整個FeatureMap,但其訓練得到的網絡精度也很高。這,我竟然無言以對。有什么問題,請找Anchors同學。
2.采用不同分辨率圖像在一定程度可以提高準確率,但是也會導致訓練速度下降。采用VGG16訓練RPN雖然使得第13個卷積層特征尺寸至少縮小到原圖尺寸的1/16(事實上,考慮到kernel_size作用,會更小一些),然并卵,最終的檢測和識別效果仍然好到令我無言以對。
3.三種scale(128*128,256*256,512*512),三種寬高比(1:2,1:1,2:1),雖然scale區間很大,總感覺這樣會很奇怪,但最終結果依然表現的很出色。
4.訓練時(例如600*1000的輸入圖像),如果reference box (即anchor box)的邊界超過了圖像邊界,這樣的anchors對訓練Loss不產生影響,即忽略掉這樣的Loss.一幅600*1000的圖經過VGG16大約為40*60,那么anchors的數量大約為40*60*9,約等于20000個anchor boxes.去除掉與圖像邊界相交的anchor boxes后,剩下約6000個anchor boxes,這么多數量的anchor boxes之間會有很多重疊區域,因此使用非極值抑制方法將IoU>0.7的區域全部合并,剩下2000個anchor boxes(同理,在最終檢測端,可以設置規則將概率大于某閾值P且IoU大于某閾值T的預測框(注意,和前面不同,不是anchor boxes)采用非極大抑制方法合并)。在每一個epoch訓練過程中,隨機從一幅圖最終剩余的這些anchors采樣256個anchor box作為一個Mini-batch訓練RPN網絡。
4.3 實驗
1.PASCAL VOC 2007:使用ZF-Net訓練RPN和Fast-R-CNN,那么SelectiveSearch+Fast-R-CNN, EdgeBox+Fast-R-CNN, RPN+Fast-R-CNN的準確率分別為:58.7%,58.6%,59.9%.SeletiveSeach和EdgeBox方法提取2000個proposal,RPN最多提取300個proposal,因此卷積特征共享方式提取特征的RPN顯然在效率是更具有優勢。
2.采用VGG以特征不共享方式和特征共享方式訓練RPN+Fast-R-CNN,可以分別得到68.5%和69.9%的準確率(VOC2007)。此外,采用VGG訓練RCNN時,需要花320ms提取2000個proposal,加入SVD優化后需要223ms,而Faster-RCNN整個前向過程(包括RPN+Fast-R-CNN)總共只要198ms.
3.Anchors的scales和aspect_ratio的數量雖然不會對結果產生明顯影響,但是為了算法穩定性,建議兩個參數都設置為合適的數值。
4.當Selective Search和EdgeBox提取的proposal數目由2000減少到300時,Faste-R-CNN的Recallvs. IoU overlap ratio圖中recall值會明顯下降;但RPN提取的proposal數目由2000減少到300時,Recallvs. IoU overlap ratio圖中recall值會比較穩定。
4.4 總結
特征共享方式訓練RPN+Fast-R-CNN能夠實現極佳的檢測效果,特征共享訓練實現了買一送一,RPN在提取Proposal時不僅沒有時間成本,還提高了proposal質量。因此Faster-R-CNN中交替訓練RPN+Fast-R-CNN方式比原來的SlectiveSeach+Fast-R-CNN更上一層樓。
5.YOLO: You Only Look Once:Unified, Real-Time Object Detection
YOLO是一個可以一次性預測多個Box位置和類別的卷積神經網絡,能夠實現端到端的目標檢測和識別,其最大的優勢就是速度快。事實上,目標檢測的本質就是回歸,因此一個實現回歸功能的CNN并不需要復雜的設計過程。YOLO沒有選擇滑窗或提取proposal的方式訓練網絡,而是直接選用整圖訓練模型。這樣做的好處在于可以更好的區分目標和背景區域,相比之下,采用proposal訓練方式的Fast-R-CNN常常把背景區域誤檢為特定目標。當然,YOLO在提升檢測速度的同時犧牲了一些精度。下圖所示是YOLO檢測系統流程:1.將圖像Resize到448*448;2.運行CNN;3.非極大抑制優化檢測結果。有興趣的童鞋可以按照http://pjreddie.com/darknet/install/的說明安裝測試一下YOLO的scoring流程,非常容易上手。接下來將重點介紹YOLO的原理。
5.1 一體化檢測方案
YOLO的設計理念遵循端到端訓練和實時檢測。YOLO將輸入圖像劃分為S*S個網絡,如果一個物體的中心落在某網格(cell)內,則相應網格負責檢測該物體。在訓練和測試時,每個網絡預測B個bounding boxes,每個bounding box對應5個預測參數,即bounding box的中心點坐標(x,y),寬高(w,h),和置信度評分。這里的置信度評分(Pr(Object)*IOU(pred|truth))綜合反映基于當前模型bounding box內存在目標的可能性Pr(Object)和bounding box預測目標位置的準確性IOU(pred|truth)。如果bouding box內不存在物體,則Pr(Object)=0。如果存在物體,則根據預測的bounding box和真實的bounding box計算IOU,同時會預測存在物體的情況下該物體屬于某一類的后驗概率Pr(Class_i|Object)。假定一共有C類物體,那么每一個網格只預測一次C類物體的條件類概率Pr(Class_i|Object), i=1,2,...,C;每一個網格預測B個bounding box的位置。即這B個bounding box共享一套條件類概率Pr(Class_i|Object), i=1,2,...,C。基于計算得到的Pr(Class_i|Object),在測試時可以計算某個bounding box類相關置信度:Pr(Class_i|Object)*Pr(Object)*IOU(pred|truth)=Pr(Class_i)*IOU(pred|truth)。如果將輸入圖像劃分為7*7網格(S=7),每個網格預測2個bounding box (B=2),有20類待檢測的目標(C=20),則相當于最終預測一個長度為S*S*(B*5+C)=7*7*30的向量,從而完成檢測+識別任務,整個流程可以通過下圖理解。
5.1.1 網絡設計
YOLO網絡設計遵循了GoogleNet的思想,但與之有所區別。YOLO使用了24個級聯的卷積(conv)層和2個全連接(fc)層,其中conv層包括3*3和1*1兩種Kernel,最后一個fc層即YOLO網絡的輸出,長度為S*S*(B*5+C)=7*7*30.此外,作者還設計了一個簡化版的YOLO-small網絡,包括9個級聯的conv層和2個fc層,由于conv層的數量少了很多,因此YOLO-small速度比YOLO快很多。如下圖所示我們給出了YOLO網絡的架構。
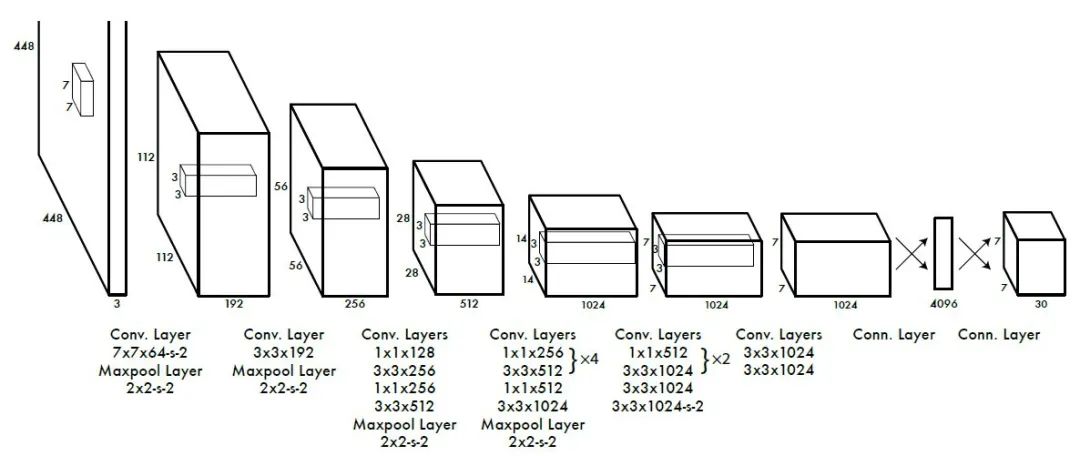
5.1.2 訓練
作者訓練YOLO網絡是分步驟進行的:首先,作者從上圖網絡中取出前20個conv層,然后自己添加了一個average pooling層和一個fc層,用1000類的ImageNet數據與訓練。在ImageNet2012上用224*224d的圖像訓練后得到的top5準確率是88%。然后,作者在20個預訓練好的conv層后添加了4個新的conv層和2個fc層,并采用隨即參數初始化這些新添加的層,在fine-tune新層時,作者選用448*448圖像訓練。最后一個fc層可以預測物體屬于不同類的概率和bounding box中心點坐標x,y和寬高w,h。Boundingbox的寬高是相對于圖像寬高歸一化后得到的,Bounding box的中心位置坐標是相對于某一個網格的位置坐標進行過歸一化,因此x,y,w,h均介于0到1之間。
在設計Loss函數時,有兩個主要的問題:1.對于最后一層長度為7*7*30長度預測結果,計算預測loss通常會選用平方和誤差。然而這種Loss函數的位置誤差和分類誤差是1:1的關系。2.整個圖有7*7個網格,大多數網格實際不包含物體(當物體的中心位于網格內才算包含物體),如果只計算Pr(Class_i),很多網格的分類概率為0,網格loss呈現出稀疏矩陣的特性,使得Loss收斂效果變差,模型不穩定。為了解決上述問題,作者采用了一系列方案:
1.增加bounding box坐標預測的loss權重,降低bounding box分類的loss權重。坐標預測和分類預測的權重分別是λcoord=5,λnoobj=0.5.
2.平方和誤差對于大和小的bounding box的權重是相同的,作者為了降低不同大小bounding box寬高預測的方差,采用了平方根形式計算寬高預測loss,即sqrt(w)和sqrt(h)。
訓練Loss組成形式較為復雜,這里不作列舉,如有興趣可以參考作者原文慢慢理解體會。
5.1.3 測試
作者選用PASAL VOC圖像測試訓練得到的YOLO網絡,每幅圖會預測得到98個(7*7*2)個bouding box及相應的類概率。通常一個cell可以直接預測出一個物體對應的bounding box,但是對于某些尺寸較大或靠近圖像邊界的物體,需要多個網格預測的結果通過非極大抑制處理生成。雖然YOLO對于非極大抑制的依賴不及R-CNN和DPM,但非極大抑制確實可以將mAP提高2到3個點。
5.2 方法對比
作者將YOLO目標檢測與識別方法與其他幾種經典方案進行比較可知:
DPM(Deformable parts models):DPM是一種基于滑窗方式的目標檢測方法,基本流程包括幾個獨立的環節:特征提取,區域劃分,基于高分值區域預測bounding box。YOLO采用端到端的訓練方式,將特征提取、候選框預測,非極大抑制及目標識別連接在一起,實現了更快更準的檢測模型。
R-CNN:R-CNN方案分需要先用SeletiveSearch方法提取proposal,然后用CNN進行特征提取,最后用SVM訓練分類器。如此方案,誠繁瑣也!YOLO精髓思想與其類似,但是通過共享卷積特征的方式提取proposal和目標識別。另外,YOLO用網格對proposal進行空間約束,避免在一些區域重復提取Proposal,相較于SeletiveSearch提取2000個proposal進行R-CNN訓練,YOLO只需要提取98個proposal,這樣訓練和測試速度怎能不快?
Fast-R-CNN、Faster-R-CNN、Fast-DPM: Fast-R-CNN和Faster-R-CNN分別替換了SVMs訓練和SelectiveSeach提取proposal的方式,在一定程度上加速了訓練和測試速度,但其速度依然無法和YOLO相比。同理,將DPM優化在GPU上實現也無出YOLO之右。
5.3 實驗
5.3.1 實時檢測識別系統對比
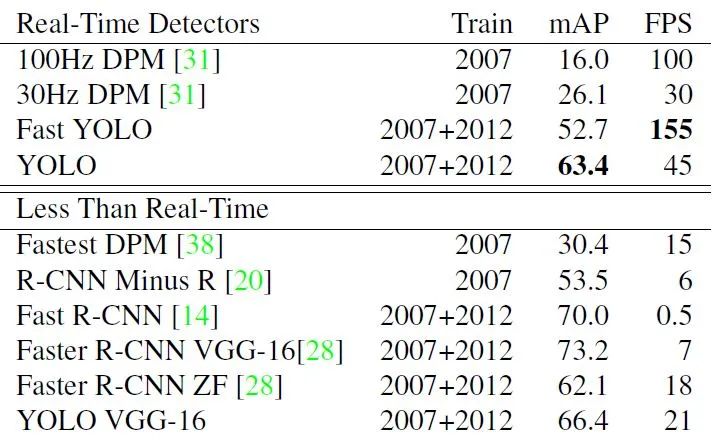
5.3.2 VOC2007準確率比較
5.3.3 Fast-R-CNN和YOLO錯誤分析
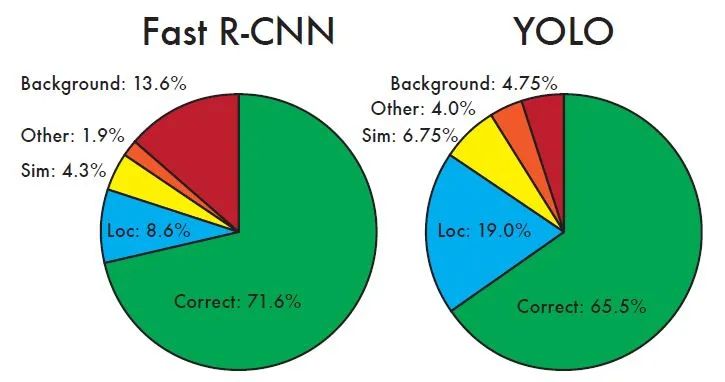
如圖所示,不同區域分別表示不同的指標:
Correct:正確檢測和識別的比例,即分類正確且IOU>0.5
Localization:分類正確,但0.1
Similar:類別相似,IOU>0.1
Other:分類錯誤,IOU>0.1
Background: 對于任何目標IOU<0.1
可以看出,YOLO在定位目標位置時準確度不及Fast-R-CNN。YOLO的error中,目標定位錯誤占據的比例最大,比Fast-R-CNN高出了10個點。但是,YOLO在定位識別背景時準確率更高,可以看出Fast-R-CNN假陽性很高(Background=13.6%,即認為某個框是目標,但是實際里面不含任何物體)。
5.3.4 VOC2012準確率比較
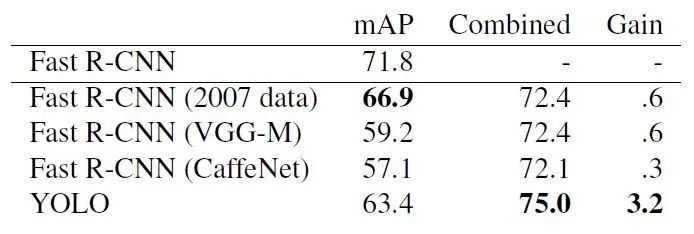
由于YOLO在目標檢測和識別是處理背景部分優勢更明顯,因此作者設計了Fast-R-CNN+YOLO檢測識別模式,即先用R-CNN提取得到一組bounding box,然后用YOLO處理圖像也得到一組bounding box。對比這兩組bounding box是否基本一致,如果一致就用YOLO計算得到的概率對目標分類,最終的bouding box的區域選取二者的相交區域。Fast-R-CNN的最高準確率可以達到71.8%,采用Fast-R-CNN+YOLO可以將準確率提升至75.0%。這種準確率的提升是基于YOLO在測試端出錯的情況不同于Fast-R-CNN。雖然Fast-R-CNN_YOLO提升了準確率,但是相應的檢測識別速度大大降低,因此導致其無法實時檢測。
使用VOC2012測試不同算法的mean Average Precision,YOLO的mAP=57.9%,該數值與基于VGG16的RCNN檢測算法準確率相當。對于不同大小圖像的測試效果進行研究,作者發現:YOLO在檢測小目標時準確率比R-CNN低大約8~10%,在檢測大目標是準確率高于R-CNN。采用Fast-R-CNN+YOLO的方式準確率最高,比Fast-R-CNN的準確率高了2.3%。
5.4 總結
YOLO是一種支持端到端訓練和測試的卷積神經網絡,在保證一定準確率的前提下能圖像中多目標的檢測與識別。
作者為博客園博主賞月齋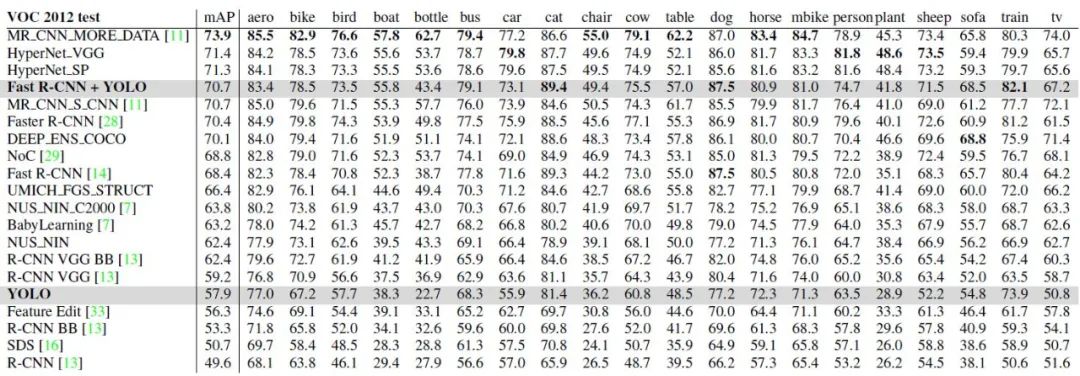
-
深度圖像
+關注
關注
0文章
19瀏覽量
3506 -
卷積神經網絡
+關注
關注
4文章
367瀏覽量
11863
原文標題:深度圖像檢測算法總結與對比
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
開源項目 ! 利用邊緣計算打造便攜式視覺識別系統
RFID識別系統





 工商網監
工商網監
評論