 CNN大致框架!如何組裝構成CNN?
CNN大致框架!如何組裝構成CNN?
本文重點知識點:
CNN的大致框架
卷積層
池化層
卷積層和池化層的實現
CNN的實現
CNN可視化介紹
如有細節處沒有寫到的,請繼續精讀《深度學習入門:基于Python的理論與實現》,對小白來說真的是非常好的深度學習的入門書籍,通俗易懂。(書中的例子主要是基于CV的)
一、CNN大致框架
神經網絡:就是組裝層的過程。
CNN出現了新的層:卷積層、池化層。
Q:如何組裝構成CNN?
全連接層:用Affine實現的:Affine-ReLU (Affine仿射變換 y = xw+b),如下為基于全連接層的5層神經網絡。
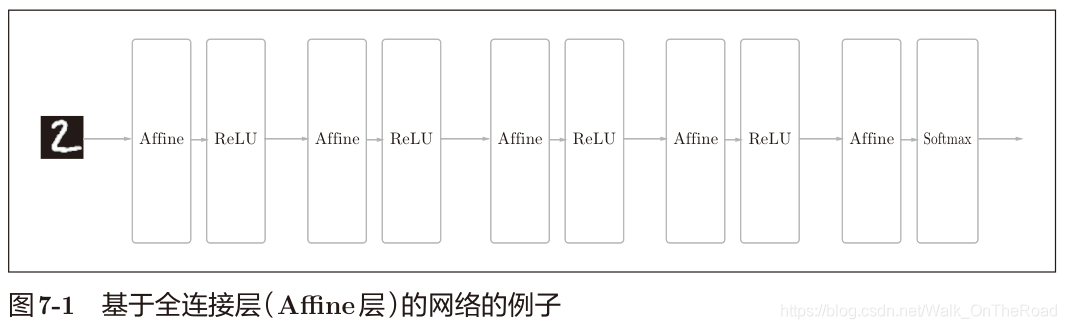
ReLU也可替換成Sigmoid層,這里由4層Affine-ReLU組成,最后由Affine-Softmax輸出最終結果(概率) 常見的CNN:Affine-ReLU 變 Conv-ReLU-(Pooling),如下為基于CNN的五層神經網絡。
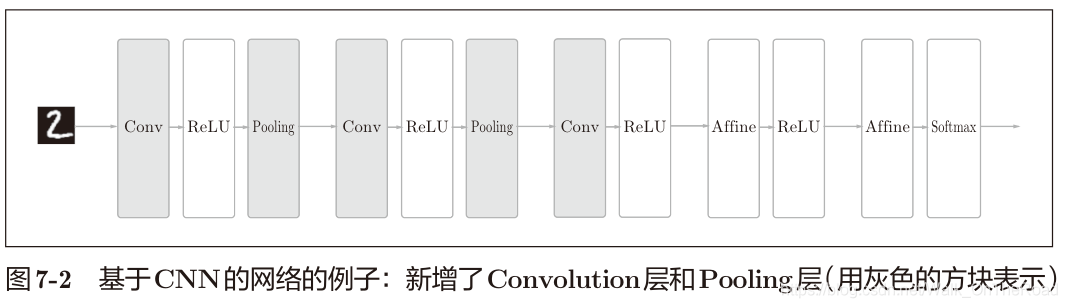
Q:全連接層有什么問題嘛?為什么要改進為Conv層?
全連接層“忽視”了數據的形狀,3維數據被拉平為1維數據;形狀因含有重要的空間信息:①空間臨近的像素為相似的值,相距較遠的像素沒什么關系;②RBG的各個通道之間分別有密切的關聯性等;③3維形狀中可能隱藏有值得提取的本質模式。
而卷積層可以保持形狀不變。可以正確理解圖像等具有形狀的數據。
特征圖:輸入、輸出數據
二、卷積層 2.1 卷積運算
輸入特征圖與卷積核作乘積累加運算,窗口以一定的步長滑動,得到輸出特征圖,也可以加偏置(1*1)
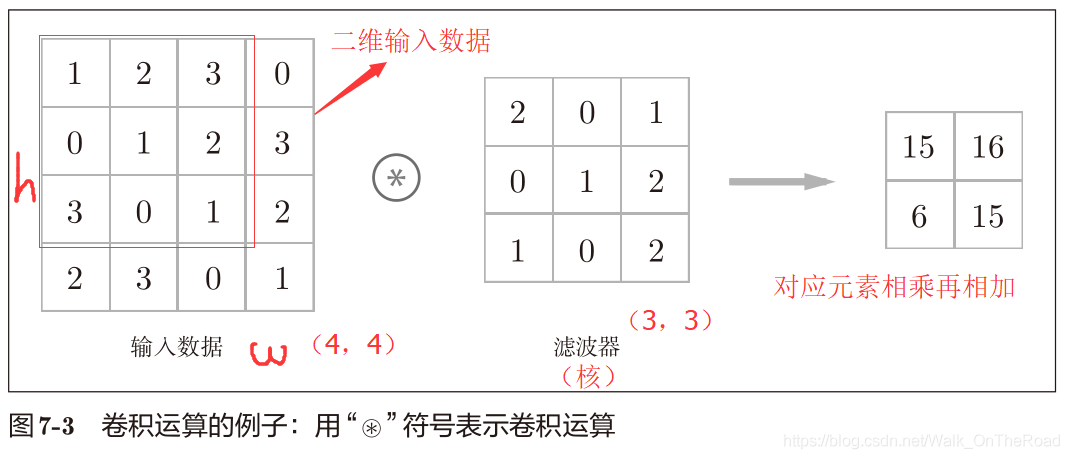
卷積核(濾波器)相當于全連接層中的權重。 卷積完后,偏置將應用于所有數據
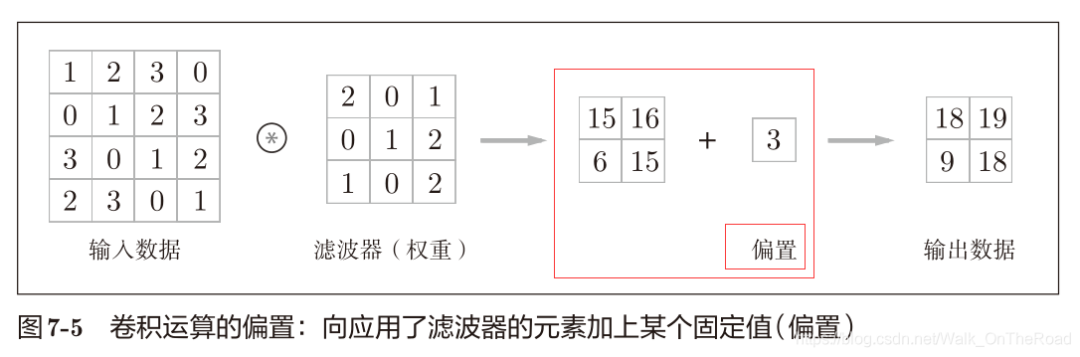
2.2 填充(padding)
向輸入數據的周圍填入固定的數據(比如0等) 填充的目的:調整輸出的大小。擴大輸入特征圖,得到大一些的輸出。一般填充為0。 為什么要調整輸出的大小?因為比如輸入(4×4),卷積核為(3×3),得到輸出為(2×2),隨著層的加深,卷積完的輸出越來越小,直到輸出變1以后將無法再進行卷積運行。為了避免這樣的情況發生,需要用到填充,使輸出至少不會減小。
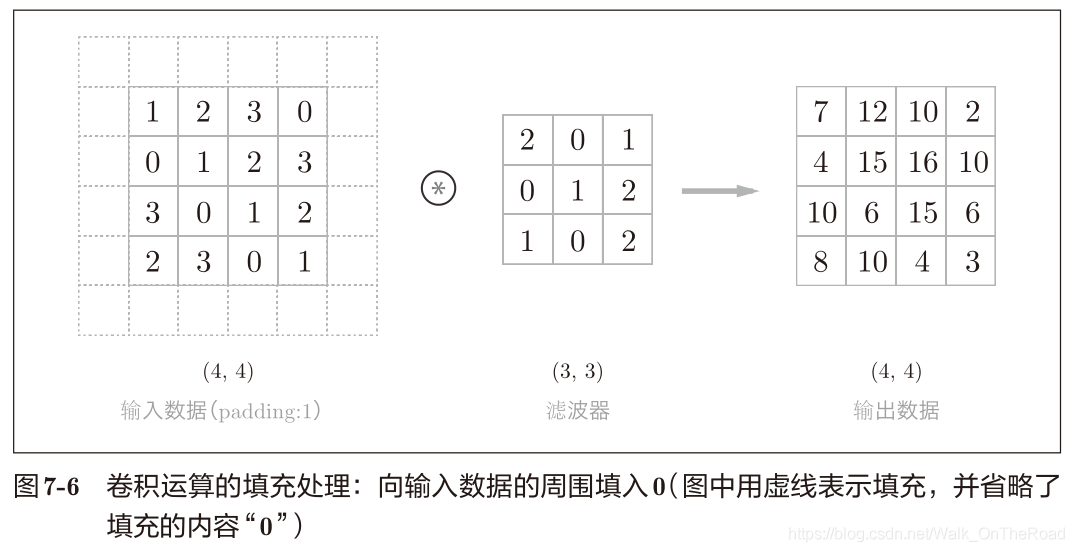
2.3 步幅(stride) 用途:指定濾波器的間隔。 步幅增大,輸出減小;填充增大,輸出增大。 計算輸出的大小:

其中:
(OH,OW) 輸出大小
(H,W) 輸入大小
(FH,FW) 濾波器大小
P 填充
S 步幅
注:式(7.1)中最好可以除盡。if無法除盡,需報錯。或者向最接近的整數四舍五入,不進行報錯而繼續運行。 2.4 三維數據的卷積運算 (通道方向,高,長):比二維數據多了一個:通道方向,特征圖增加了 (Channel,height,width) (C,H,W)
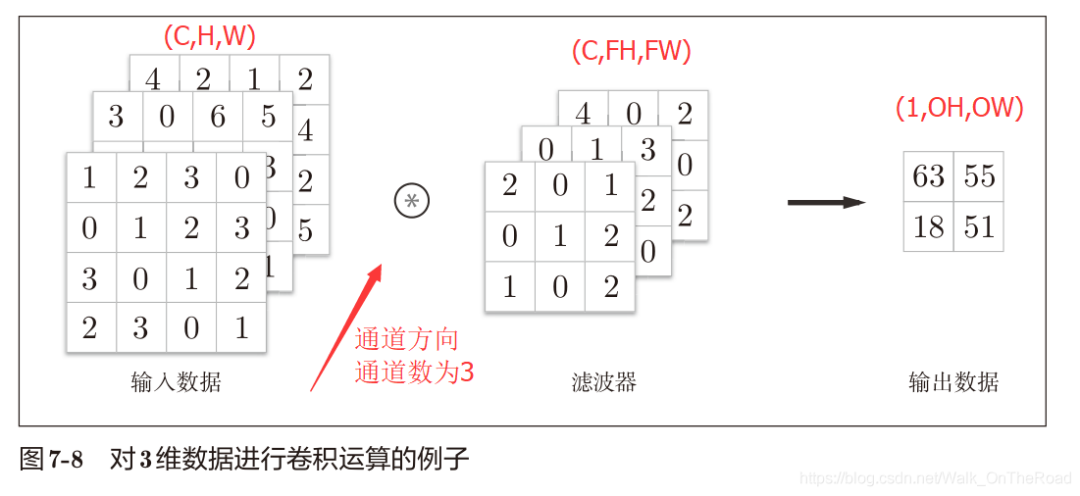
方塊思維,上下兩張圖是一個意思。
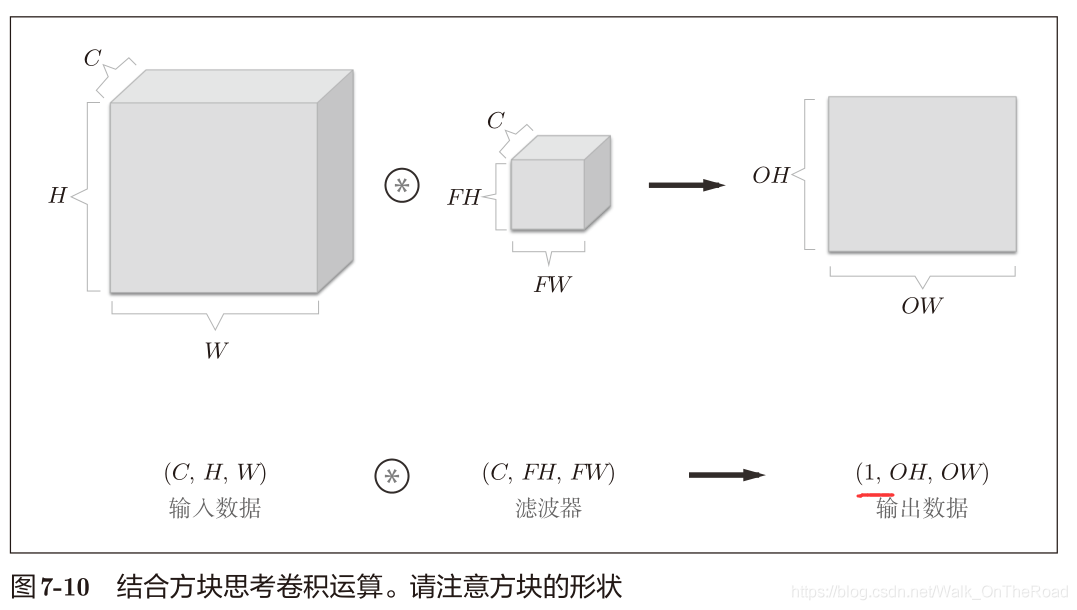
輸入數據和濾波器的通道數是保持一致的。 每個通道分別卷積計算出值,再將各通道的值相加得到最終的一個輸出值。 這樣只能得到一個通道數的輸出,怎樣使得輸出也多通道訥?
應用多個濾波器(權重),比如FN個。如下圖所示。
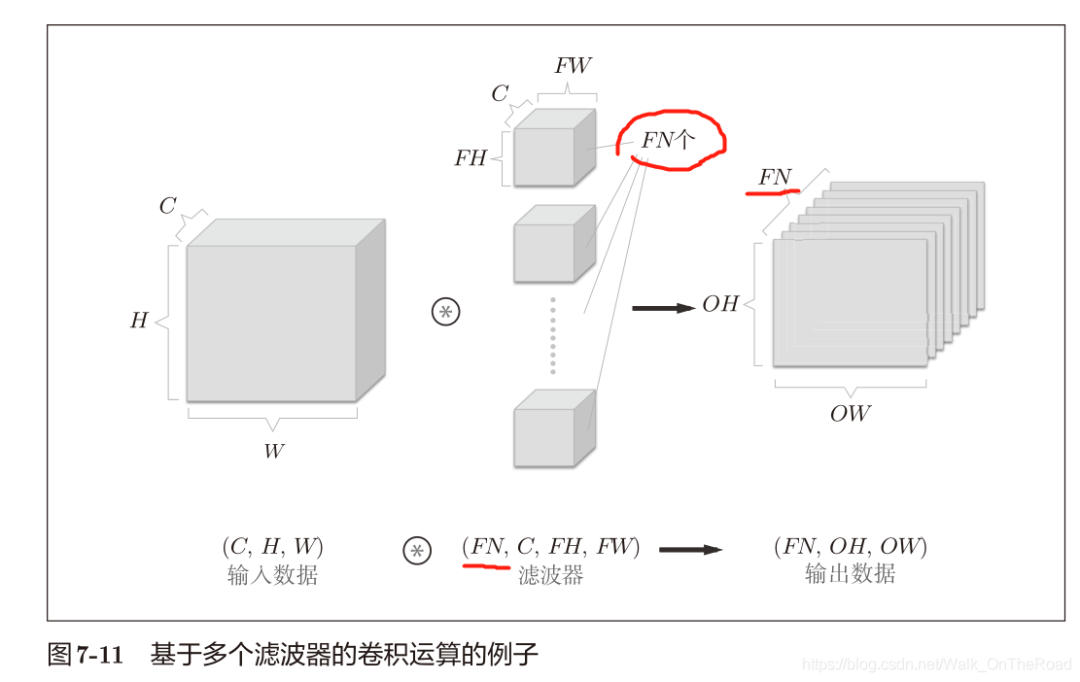
濾波器變四維,一個濾波器對應一個輸出特征圖。還可追加偏置(FN,1,1) 作為4維數據,濾波器按(output_channel, input_channel, height, width) 的順序書寫。 比如,通道數為 3、大小為 5 × 5 的濾波器有20個時,可以寫成(20, 3, 5, 5)。 不同形狀的方塊相加時,可以基于NumPy的廣播功能輕松實現(1.5.5節)。 2.5 批處理
目的:實現數據的高效化,打包N個數據一起處理。即將N次處理匯總為一次
3維——> 4維,即(C,H,W) ——> (N,C,H,W)
三、池化層
目的:縮小H,W方向上的空間的運算。比如將2 × 2區域集約成1個元素來處理,縮小空間大小。
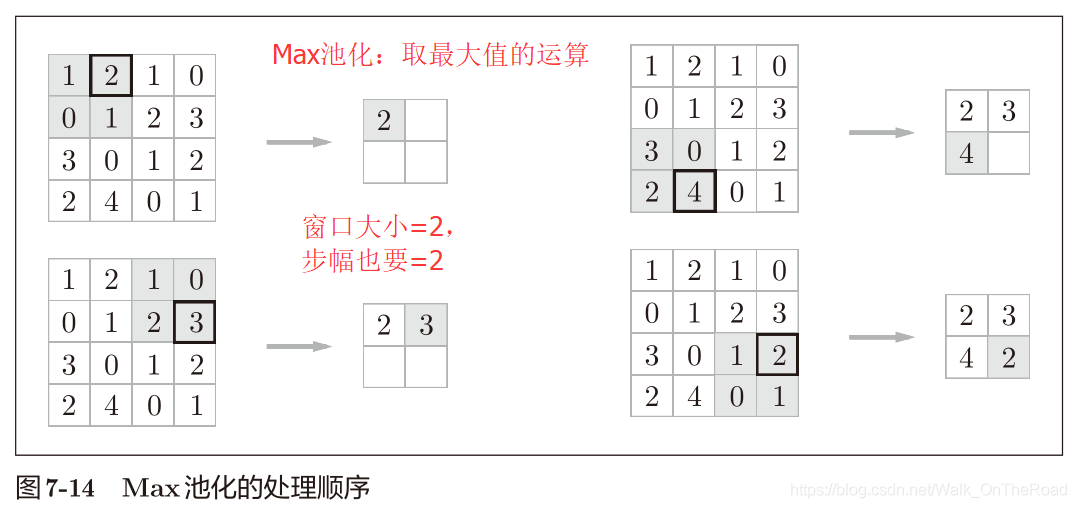
Max池化:獲取最大值的運算 一般設置:池化的窗口大小和步幅設定成相同的值。比如這里都是2。 在圖像識別中,主要用Max池化。 池化層的特征:
沒有要學習的參數;
通道數不發生變化,輸入3張,輸出也是3張;
對微小的位置變化具有魯棒性(健壯),即輸入數據發生微小偏差時,池化也可以返回相同的結果;即池化能吸收輸入數據的偏差。
四、Conv層和Pooling層的實現 4.1 4維數組
例如:隨機生成一個四維數據(10,1,28,28) 10個通道數為1,高長為28的數據
>>> x = np.random.rand(10, 1, 28, 28) # 隨機生成10個通道數為1,高長為28的輸入數據>>> x.shape(10,1,28,28)
>>> x[0].shape # (1, 28, 28) x[0]:第一個數據(第一個方塊)>>> x[1].shape # (1, 28, 28) x[1]:第二個數據>>> x[0, 0] # 或者x[0][0] 第一個數據的第一個通道>>>x[1,0]#或者x[1][0]第二個數據的第一個通道 4.2 基于im2col的展開
問題:實現卷積運行,需要重復好幾層for,麻煩,而且numPy訪問元素最好不要用 for(慢)
解決:用im2col函數(image to column 從圖像到矩陣):將輸入數據展開以合適濾波器(權重)
將4維數據 ——> 2維數據
(N,C,H,W),即(批處理器,通道數,高,長)
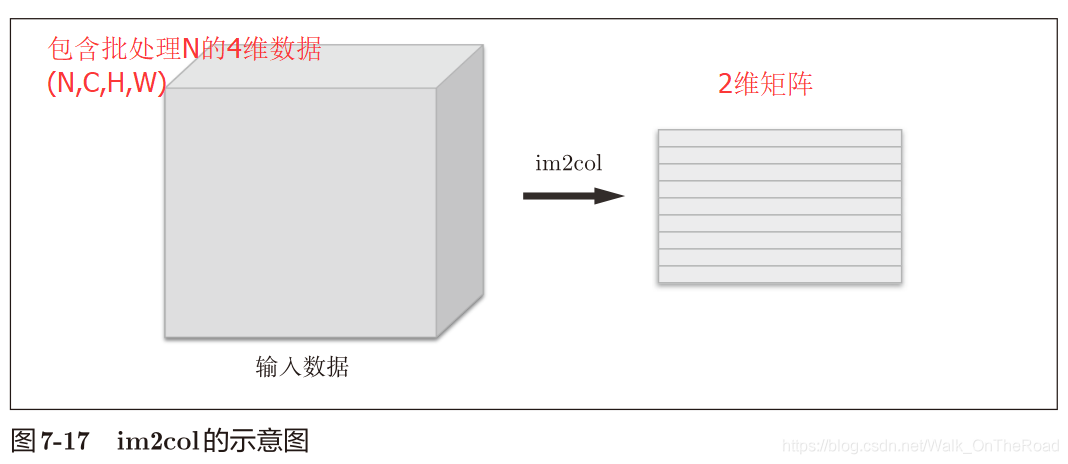
使用im2col更消耗內存,但轉換為矩陣運算更高效,可有效利用線性代數庫。
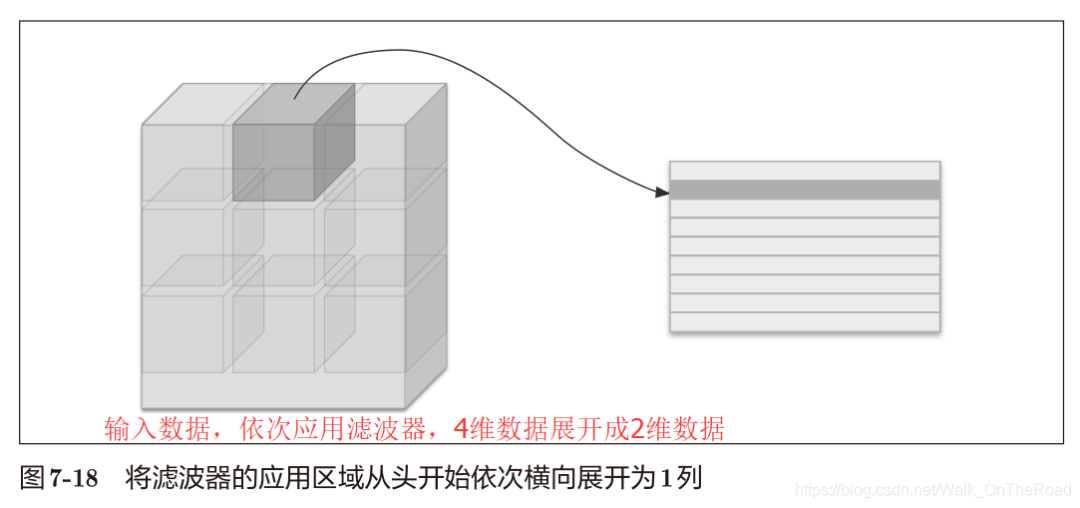
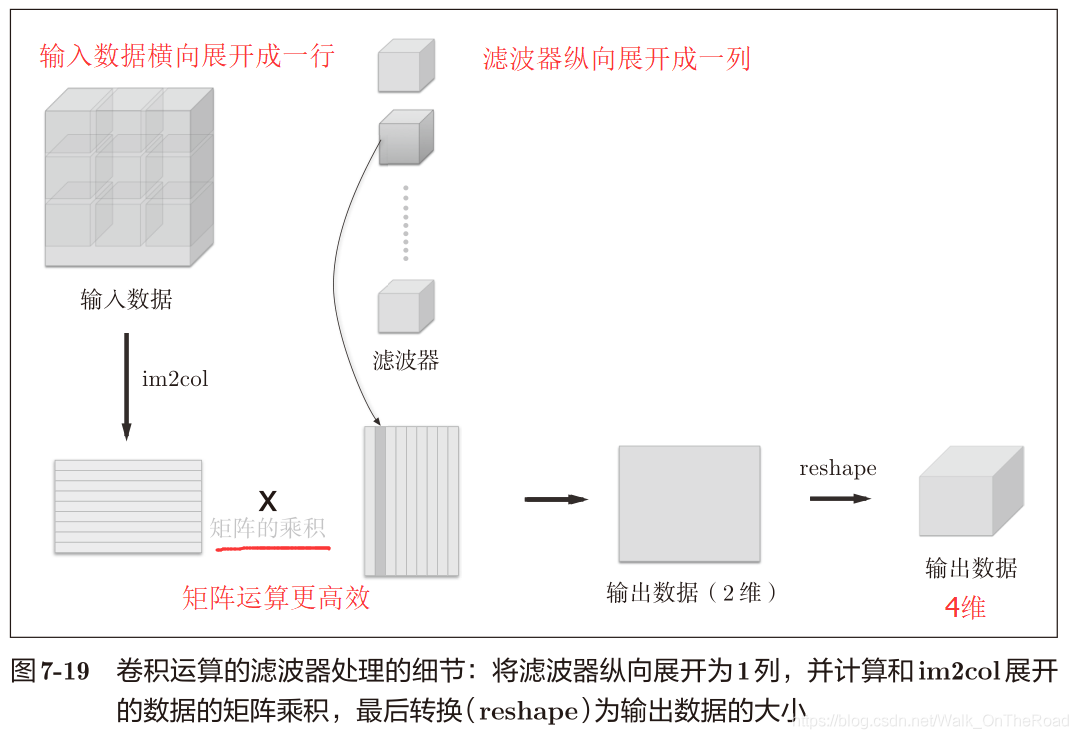
4.3 卷積層的實現
im2col函數:將4維數據輸入——> 2維數據輸入
x 輸入 4維——> 2維矩陣
W 濾波器 4維——> 2維矩陣
矩陣乘積 X*W + b ——> 輸出2維 —(reshape)—> 輸出4維
im2col(input_data,filter_h,filter_w,stride=1,pad=0)
卷積層forward的代碼實現
import sys, ossys.path.append(os.pardir)from common.util import im2col x1 = np.random.rand(1, 3, 7, 7) # 批大小為1、通道為3的7 × 7的數據col1 = im2col(x1, 5, 5, stride=1, pad=0)print(col1.shape) # (9, 75) x2 = np.random.rand(10, 3, 7, 7) # 批大小為10、通道為3的7 × 7的數據col2 = im2col(x2, 5, 5, stride=1, pad=0)print(col2.shape) # (90, 75) # 卷積層類class Convolution: def __init__(self, W, b, stride=1, pad=0): self.W = W self.b = b self.stride = stride self.pad = pad # 正向傳播 def forward(self, x): FN, C, FH, FW = self.W.shape N, C, H, W = x.shape out_h = int(1 + (H + 2*self.pad - FH) / self.stride) out_w = int(1 + (W + 2*self.pad - FW) / self.stride) col = im2col(x, FH, FW, self.stride, self.pad) col_W = self.W.reshape(FN, -1).T # 濾波器的展開 out = np.dot(col, col_W) + self.b out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2) return out #反向傳播在common/layer.py中,必須進行im2col的逆處理——>col2im(矩陣轉圖像)
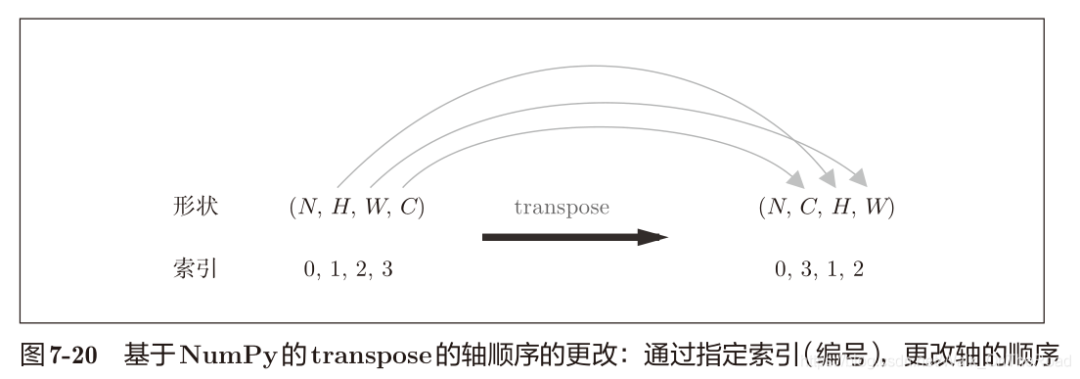
4.4 池化層的實現
使用im2col函數
在通道方向獨立,按通道單獨展開(卷積層是最后各個通道相加)
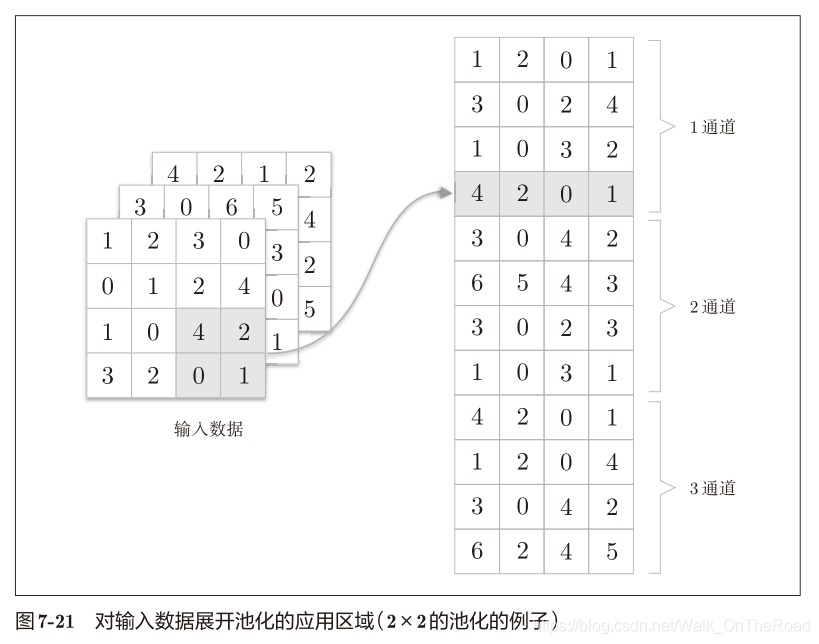
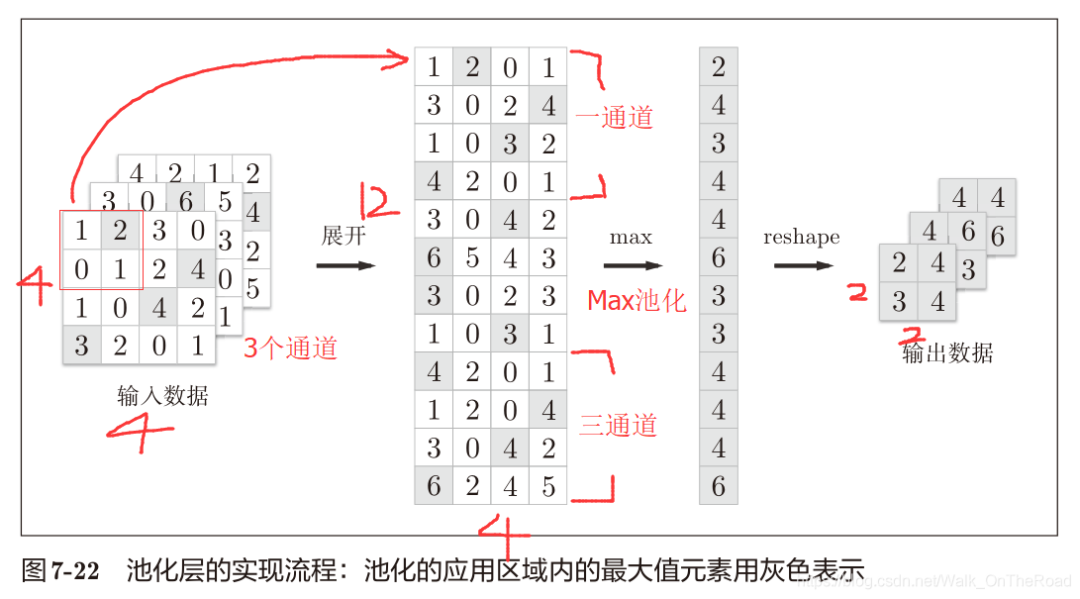
池化層的forward實現代碼
class Pooling: def __init__(self, pool_h, pool_w, stride=1, pad=0): self.pool_h = pool_h self.pool_w = pool_w self.stride = stride self.pad = pad def forward(self, x): N, C, H, W = x.shape # 計算輸出大小 out_h = int(1 + (H - self.pool_h) / self.stride) out_w = int(1 + (W - self.pool_w) / self.stride) # 展開(1) 1.展開輸入數據 col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad) col = col.reshape(-1, self.pool_h*self.pool_w) # 最大值(2) 2.求各行的最大值 out = np.max(col, axis=1) # 轉換(3) 3.轉換為合適的輸出大小 out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2) return out
池化層的實現按下面3個階段進行:
展開輸入數據
求各行的最大值
轉換為合適的輸出大小
四、CNN實現
class SimpleConvNet: """簡單的ConvNet conv - relu - pool - affine - relu - affine - softmax Parameters ---------- input_size : 輸入大小(MNIST的情況下為784,三維(1, 28, 28)) hidden_size_list : 隱藏層的神經元數量的列表(e.g. [100, 100, 100]) output_size : 輸出大小(MNIST的情況下為10,十種輸出可能) activation : 'relu' or 'sigmoid' weight_init_std : 指定權重的標準差(e.g. 0.01) 指定'relu'或'he'的情況下設定“He的初始值” 指定'sigmoid'或'xavier'的情況下設定“Xavier的初始值” """ def __init__(self, input_dim=(1, 28, 28), conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1}, hidden_size=100, output_size=10, weight_init_std=0.01): # 30個5*5的濾波器 # 取濾波器參數到conv_param字典中,備用 filter_num = conv_param['filter_num'] filter_size = conv_param['filter_size'] filter_pad = conv_param['pad'] filter_stride = conv_param['stride'] input_size = input_dim[1] # 28 conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1 pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2)) # 池化層輸出,H,W減半 # 初始化權重,三層 self.params = {} # 濾波器就是第一層的權重 W1 = (30,1,5,5)(四維數據),即30個高、長為5,通道數為1的數據 self.params['W1'] = weight_init_std * np.random.randn(filter_num, input_dim[0], filter_size, filter_size) # 每一個濾波器都加一個偏置b1,有30個 self.params['b1'] = np.zeros(filter_num) self.params['W2'] = weight_init_std * np.random.randn(pool_output_size, hidden_size) self.params['b2'] = np.zeros(hidden_size) self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size) self.params['b3'] = np.zeros(output_size) # 生成層,用以調用 self.layers = OrderedDict() # 有序字典 self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'], conv_param['stride'], conv_param['pad']) self.layers['Relu1'] = Relu() self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2) self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2']) self.layers['Relu2'] = Relu() self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3']) self.last_layer = SoftmaxWithLoss() # 前向傳播,從頭開始依次調用層,并將結果傳給下一層 def predict(self, x): for layer in self.layers.values(): x = layer.forward(x) return x # 除了使用predict,還要進行forward,直到到達最后的SoftmaxWithLoss層 def loss(self, x, t): """求損失函數 參數x是輸入數據、t是教師標簽 """ y = self.predict(x) return self.last_layer.forward(y, t) def accuracy(self, x, t, batch_size=100): if t.ndim != 1 : t = np.argmax(t, axis=1) acc = 0.0 for i in range(int(x.shape[0] / batch_size)): tx = x[i*batch_size:(i+1)*batch_size] tt = t[i*batch_size:(i+1)*batch_size] y = self.predict(tx) y = np.argmax(y, axis=1) acc += np.sum(y == tt) return acc / x.shape[0] def numerical_gradient(self, x, t): """求梯度(數值微分) Parameters ---------- x : 輸入數據 t : 教師標簽 Returns ------- 具有各層的梯度的字典變量 grads['W1']、grads['W2']、...是各層的權重 grads['b1']、grads['b2']、...是各層的偏置 """ loss_w = lambda w: self.loss(x, t) grads = {} for idx in (1, 2, 3): grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)]) grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)]) return grads # 調用各層的backward,并把權重參數的梯度存到grads字典中 def gradient(self, x, t): """求梯度(誤差反向傳播法)(二選一) Parameters ---------- x : 輸入數據 t : 教師標簽 Returns ------- 具有各層的梯度的字典變量 grads['W1']、grads['W2']、...是各層的權重 grads['b1']、grads['b2']、...是各層的偏置 """ # forward self.loss(x, t) # backward dout = 1 dout = self.last_layer.backward(dout) layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout) # 設定 grads = {} grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
五、CNN可視化
濾波器會提取邊緣或斑塊等原始信息。隨著層的加深,提取的信息也愈加復雜。
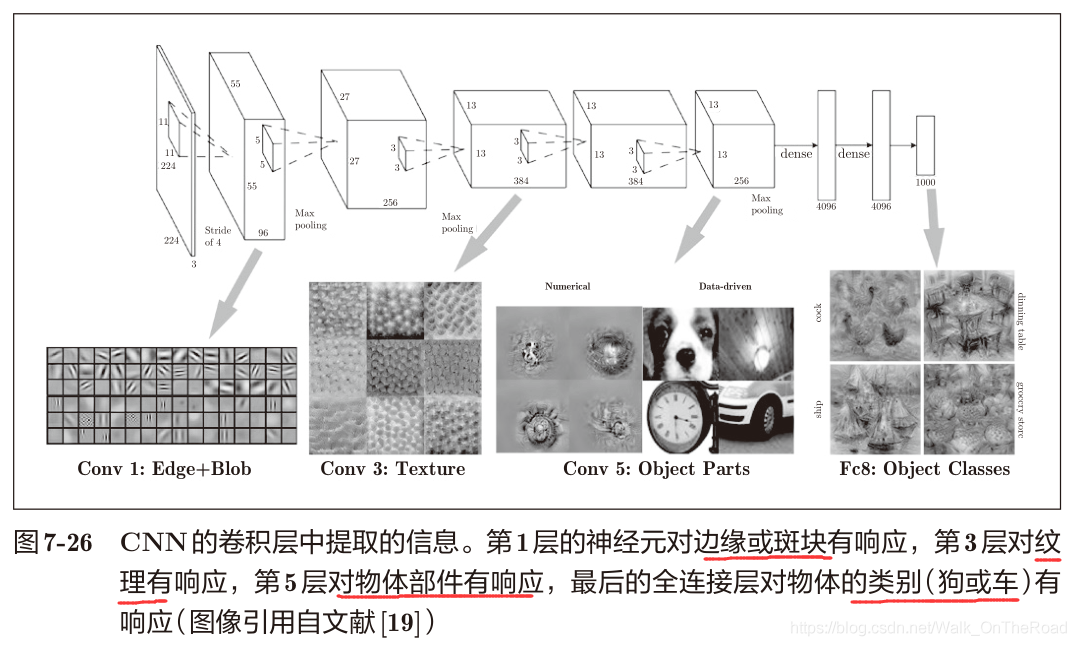
提取信息愈加復雜:
邊緣——> 紋理——> 物體部件——> 分類
1998年,CNN元祖:LeNet——> 比如手寫數字識別
2012年:深度學習 AlexNet
他們都是疊加多個卷積層,池化層,最后經由全連接層輸出
LeNet:
激活函數用sigmoid (現主要使用ReLU )
通過子采樣來縮小數據(現主要使用Max池化)
AlexNet:
激活函數用ReLU
使用進行局部正規化的LRN層(local responce normalization)
使用dropout
關于網絡結構,LeNet和AlexNet沒太大差別,現如今大數據和GPU的快速發展推動了深度學習的發展。 注:如有細節處沒有寫到的,請繼續精讀《深度學習入門》,對小白來說真的是非常通俗易懂的深度學習入門書籍。(書中的例子主要是基于CV的)
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100715 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113 -
cnn
+關注
關注
3文章
352瀏覽量
22203
原文標題:【基礎詳解】手磕實現 CNN卷積神經網絡!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TF之CNN:CNN實現mnist數據集預測
如何利用PyTorch API構建CNN?
如何在嵌入式平臺實現CNN
如何將DS_CNN_S.pb轉換為ds_cnn_s.tflite?
一文詳解CNN
基于FPGA的通用CNN加速設計

手把手教你操作Faster R-CNN和Mask R-CNN
自己動手寫CNN Inference框架之 (三) dense

自己動手寫CNN Inference框架之 (一) 開篇
PyTorch教程14.8之基于區域的CNN(R-CNN)
PyTorch教程-14.8。基于區域的 CNN (R-CNN)






 工商網監
工商網監
評論