") 簡(jiǎn)單介紹ACL 2020中有關(guān)對(duì)象級(jí)情感分析的三篇文章
簡(jiǎn)單介紹ACL 2020中有關(guān)對(duì)象級(jí)情感分析的三篇文章
引言
情感分析是文本分類的一種,主要方法是提取文本的表示特征,并基于這些特征進(jìn)行分類。情感分析根據(jù)研究對(duì)象的粒度不同可分為文本級(jí)、句子級(jí)、對(duì)象級(jí)等,分別對(duì)相應(yīng)單位的文本進(jìn)行情感傾向分析。其中,較細(xì)粒度的情感分析為對(duì)象級(jí)情感分析(Aspect-level Sentiment Analysis, ASA),任務(wù)輸入為一段文本和指定的待分析對(duì)象,輸出為針對(duì)該對(duì)象的情感傾向。
對(duì)象級(jí)情感分析任務(wù)的難點(diǎn)在于,文本中表示情感判斷的詞匯與對(duì)應(yīng)對(duì)象的關(guān)系是不確定的,分析工具需要挖掘語(yǔ)意特征和句法結(jié)構(gòu)特征,正確提取制定對(duì)象的情感詞匯,排除其他情感詞匯的干擾;另一方面,情感分析在應(yīng)用中要求工具能解釋做出判斷的依據(jù),這對(duì)模型的可解釋性提出了要求。
ACL 2020中有關(guān)情感分析的文章主要集中在Sentiment Analysis, Stylistic Analysis, and Argument Mining論壇中,內(nèi)容涵蓋了情感分析相關(guān)的數(shù)據(jù)構(gòu)建、基本方法、上下游等任務(wù)。本文將簡(jiǎn)單介紹ACL 2020中有關(guān)對(duì)象級(jí)情感分析的三篇文章。
文章概覽
基于文檔級(jí)情感傾向的對(duì)象級(jí)情感分類模型(Aspect Sentiment Classification with Document-level Sentiment Preference Modeling)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.338.pdf
本文構(gòu)建了句子之間的相關(guān)網(wǎng)絡(luò),其他句子為所預(yù)測(cè)句子的情感分析任務(wù)提供了支持信息。這一方法的假設(shè)是短文本(如商品評(píng)價(jià))中針對(duì)同一問(wèn)題的情感表述較為一致,甚至整個(gè)文本的情感基調(diào)都較連貫,因此其他句子的信息可以提供有益的指導(dǎo)。
面向?qū)ο笄楦蟹治龅膶?duì)象導(dǎo)向型結(jié)構(gòu)化注意力網(wǎng)絡(luò)(Target-Guided Structured Attention Network for Target-Dependent Sentiment Analysis)
論文地址:https://www.mitpressjournals.org/doi/pdf/10.1162/tacl_a_00308
不同于以往將單詞作為基本分析單元的研究,本文提出模型分析(如注意力機(jī)制)的基本單位應(yīng)該是語(yǔ)義群(片段)而非單詞,并基于這個(gè)想法構(gòu)建了針對(duì)對(duì)象的語(yǔ)義群注意力機(jī)制。最終的結(jié)果也表明這樣的方法尤其在復(fù)雜句子中能更準(zhǔn)確地捕捉情感信息。
應(yīng)用上下文及句法特征的對(duì)象級(jí)情感分類(Modelling Context and Syntactical Features for Aspect-based Sentiment Analysis)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.293.pdf
本文指出,無(wú)論是從應(yīng)用還是理論角度看,對(duì)象級(jí)情感分析都不應(yīng)單獨(dú)進(jìn)行,而要與對(duì)象抽取任務(wù)結(jié)合起來(lái)進(jìn)行。該文章構(gòu)建了這樣的一體化工具,能充分利用上下文和句法信息,有效地提升了對(duì)象級(jí)情感分類成績(jī)。
論文細(xì)節(jié)
1

簡(jiǎn)介
來(lái)自蘇州大學(xué)和阿里巴巴的幾位研究者提出了參考文檔級(jí)情感傾向信息的對(duì)象級(jí)情感分類方法。作者認(rèn)為,之前的對(duì)象級(jí)情感分類工作都將其視為基于句子的獨(dú)立任務(wù),沒(méi)有充分利用文本隱含的情感信息。而實(shí)際上,無(wú)論是微博等社交文本還是購(gòu)物平臺(tái)的評(píng)價(jià)文本,句子都不是單獨(dú)出現(xiàn),而是幾句含義較為集中、情感較為一致的句子共同出現(xiàn)。另一方面,這些場(chǎng)合下句子構(gòu)成往往較隨意,有時(shí)句子本身無(wú)法提供足夠的信息,必需參考其他句子的內(nèi)容甚至情感傾向才能理解本句的情緒。
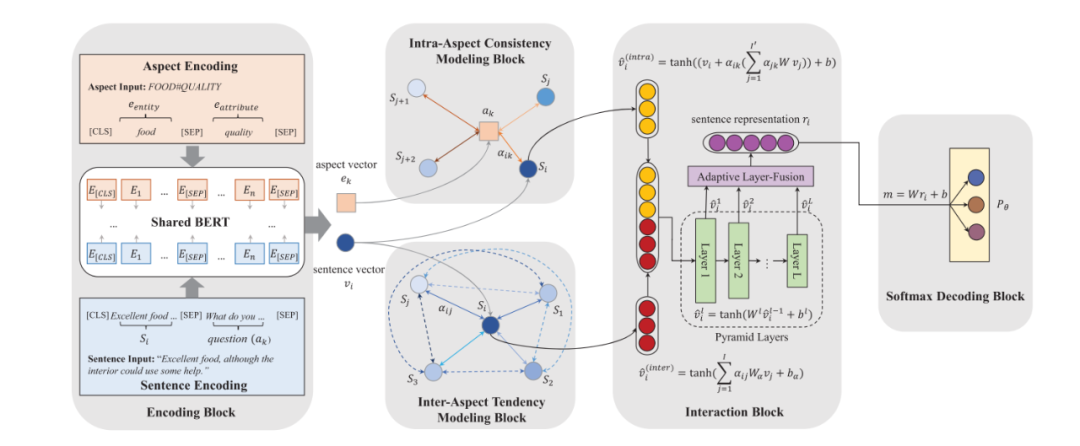
由此,本文提出了一種聯(lián)合圖注意力網(wǎng)絡(luò)(Cooperative Graph Attention Network)方法,分別在對(duì)象內(nèi)和跨對(duì)象兩個(gè)層級(jí)收集情感信息(依次稱為情感一致性和情感傾向性),并將這兩種情感信息在圖注意力網(wǎng)絡(luò)上優(yōu)化,在聯(lián)合分析后得出針對(duì)對(duì)象的情感傾向。
模型

如上圖所示,包含相同對(duì)象的不同句子之間可以互相參照,因文本對(duì)該對(duì)象的情感應(yīng)具有一定的一致性。具體而言,本文構(gòu)建了對(duì)象內(nèi)一致性模型(Intra-Aspect Consistency Modeling),其中包含注意力網(wǎng)絡(luò),即句子Sentence與對(duì)象Aspect之間關(guān)聯(lián)性的網(wǎng)絡(luò);對(duì)句子和對(duì)象, 注意力權(quán)重的計(jì)算公式如下:
于是句子的對(duì)象內(nèi)(情感一致性)表示的計(jì)算公式為
.

類似地,如上圖所示,本文還構(gòu)建了跨對(duì)象傾向性模型(Inter-Aspect Tendency Modeling);其中注意力網(wǎng)絡(luò)為,即句子與之間關(guān)聯(lián)性,其注意力權(quán)重的計(jì)算公式如下:
跨對(duì)象(情感傾向性)表示的計(jì)算公式為:.
隨后需要將兩種表示合并:不同于直接將二者簡(jiǎn)單拼合,本文使用了一種融合機(jī)制,包括金字塔形隱藏層設(shè)計(jì)和適應(yīng)性層融合技術(shù),以此使兩種表示之間存在溝通渠道。具體而言,金字塔隱藏層設(shè)計(jì)中,每一層向量的長(zhǎng)度都比上一層縮小一倍,即,其中為當(dāng)前層數(shù);而適應(yīng)性層融合技術(shù)是指將上述金字塔隱藏層的各層表示拼接起來(lái),并經(jīng)過(guò)線性變換和激活從而得到最終的句子表示向量。
模型的整體架構(gòu)請(qǐng)見(jiàn)下圖:
實(shí)驗(yàn)
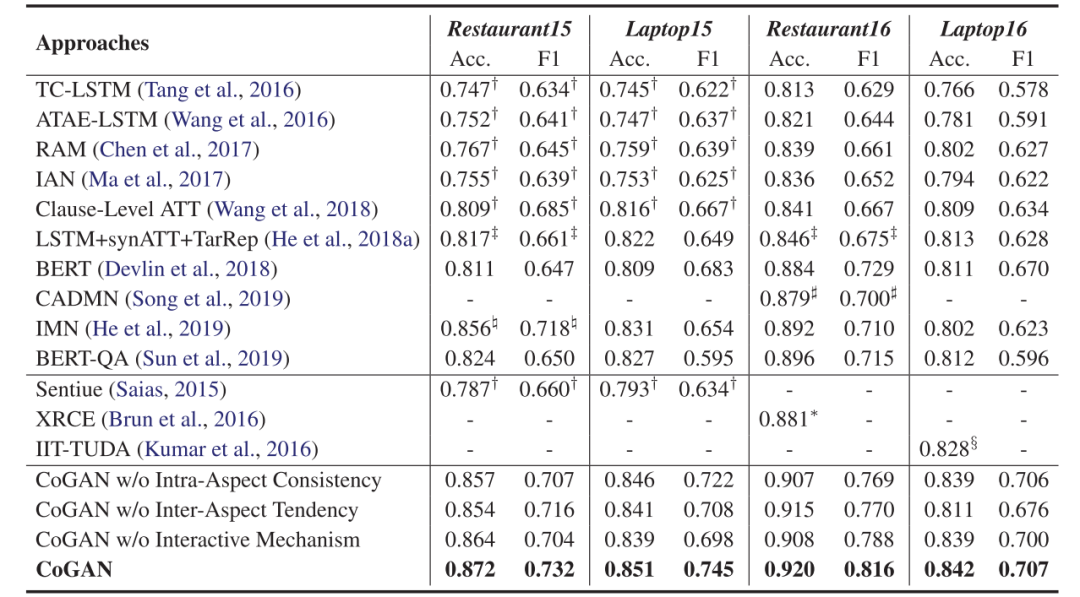
在SemEval-2015 Task12和SemEval-2016 Task5的數(shù)據(jù)集上,本文所用的模型都得到了明顯優(yōu)于其他模型的結(jié)果。
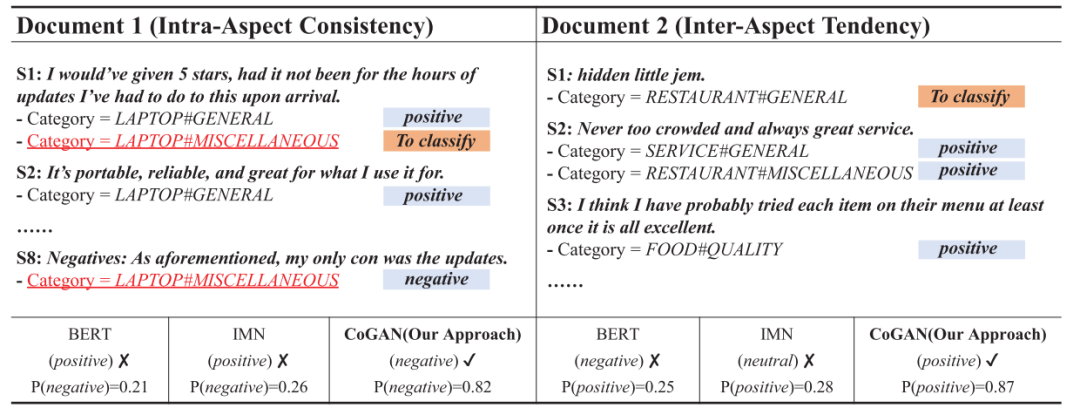
更重要的是,作者隨后做了Case Study,在句內(nèi)含義較為隱晦時(shí),對(duì)象內(nèi)情感一致性可以通過(guò)其他句子給出正確的判斷;而在更為隱晦而難以判斷的文本中,跨對(duì)象情感傾向性可以發(fā)揮作用,通過(guò)整體的情感判斷給出某個(gè)對(duì)象的情感。
2

簡(jiǎn)介
來(lái)自Wisers AI Lab的幾位研究者認(rèn)為,對(duì)象級(jí)情感分類任務(wù)的重點(diǎn)在于挖掘?qū)ο笤~匯和上下文詞匯的關(guān)系,而既有研究都將詞匯看作單獨(dú)的語(yǔ)意單元;本文作者提出,這樣的假設(shè)忽略了句子其實(shí)是由若干語(yǔ)意區(qū)塊構(gòu)成的,在語(yǔ)意區(qū)塊(片段)中幾個(gè)單詞聯(lián)合表達(dá)一個(gè)含義,是不同語(yǔ)意片段(而非單詞)在對(duì)對(duì)象產(chǎn)生著影響。如下圖(a)所示,如果關(guān)注語(yǔ)義片段的作用,在預(yù)測(cè)“waiting”的情感傾向時(shí),“so good and so popular”的重要性將整體低于“a nightmare”;但若以單詞為分析單位,因?yàn)榫嚯x和詞性不同,“popular”等詞會(huì)獲得比“nightmare”更多的注意力,因此得出相反(也是錯(cuò)誤的)判斷。因此本文試圖挖掘句中表達(dá)特定含義的上下文片段,并將這些片段根據(jù)與對(duì)象的關(guān)系進(jìn)行融合。

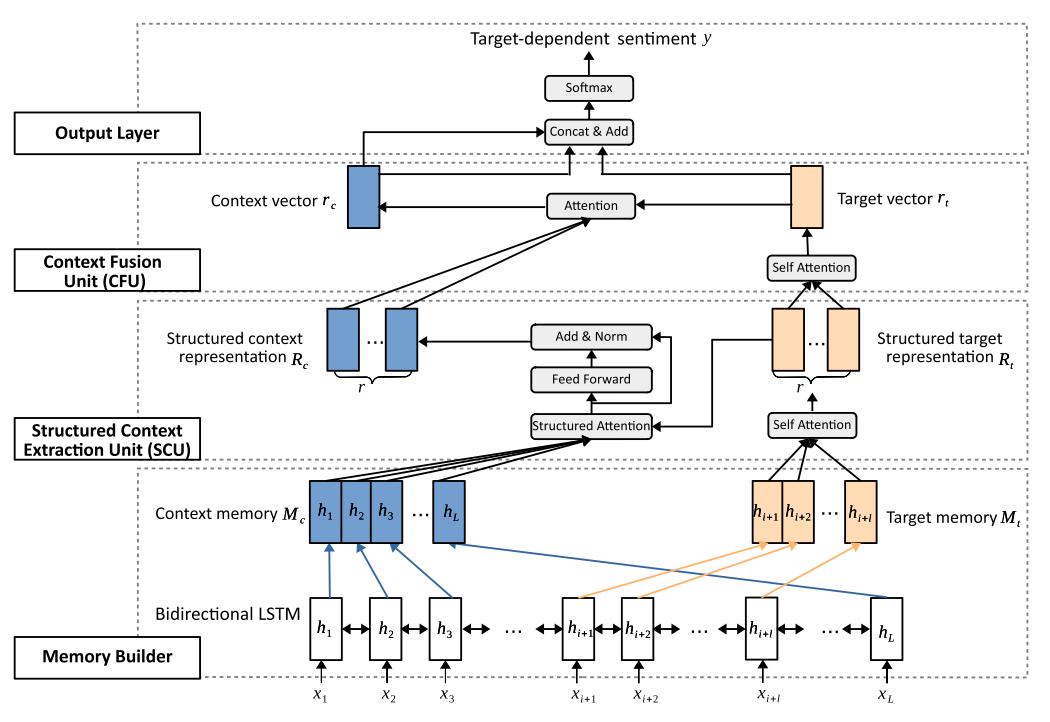
本文構(gòu)建的模型為對(duì)象導(dǎo)向的結(jié)構(gòu)性注意力網(wǎng)絡(luò)(Target-Guided Structured Attention Network, TG-SAN),包括兩個(gè)核心單元,其一是結(jié)構(gòu)性上下文抽取單元(Structured Context Extraction Unit, SCU),其二是上下文融合單元(Context Fusion Unit, CFU),分別承擔(dān)為語(yǔ)意群編碼和將它們(根據(jù)與對(duì)象的關(guān)系)進(jìn)行合并的任務(wù)。
模型
首先本文使用Bi_LSTM構(gòu)建了對(duì)象和上下文的記憶力表示。隨后,SCU模塊的主要任務(wù)是根據(jù)給出的對(duì)象和上下文的記憶表示,抽取出對(duì)象相關(guān)的上下文片段。這分為三個(gè)步驟:第一,結(jié)構(gòu)化對(duì)象表示,使用自注意力機(jī)制,將對(duì)象的記憶單元轉(zhuǎn)為其表示,其公式為和. 其中,為權(quán)重矩陣,為對(duì)象的嵌入表示矩陣,和是兩個(gè)用于自注意力機(jī)制的可學(xué)習(xí)參數(shù)矩陣。第二,對(duì)象導(dǎo)向的上下文提取,其公式為和. 其中,用來(lái)表示對(duì)象和上下文的相關(guān)程度;是上下文矩陣,其每一行可被視為基于對(duì)象的語(yǔ)義片段;是可學(xué)習(xí)的參數(shù)矩陣。最后,將上述表示進(jìn)行變換從而得到結(jié)構(gòu)化上下文表示:,. 其中兩個(gè)和均為可學(xué)習(xí)的參數(shù)。
之后是上下文融合單元。該模塊的目的是學(xué)習(xí)被抽取出的上下文關(guān)于對(duì)象的貢獻(xiàn)度,使用的工具為自注意力機(jī)制。所用到的計(jì)算公式為:
本文模型的整體架構(gòu)請(qǐng)見(jiàn)下圖:
實(shí)驗(yàn)
在推特?cái)?shù)據(jù)集和SemEval-2014的筆記本電腦、餐館數(shù)據(jù)集上,本文的模型都取得了較好的成果,且銷熔實(shí)驗(yàn)也證明兩個(gè)核心模塊都對(duì)實(shí)驗(yàn)結(jié)果有一定的提升。在Case Study部分,作者分別針對(duì)多對(duì)象、同對(duì)象多次出現(xiàn)、單對(duì)象的句子做了分析,發(fā)現(xiàn)本文的方法不但能比基線方法的判斷正確率更高,且能準(zhǔn)確定位到做出判斷的詞匯,權(quán)重分配較鮮明,證明該方法能學(xué)習(xí)到句中有關(guān)情感判斷的知識(shí)。
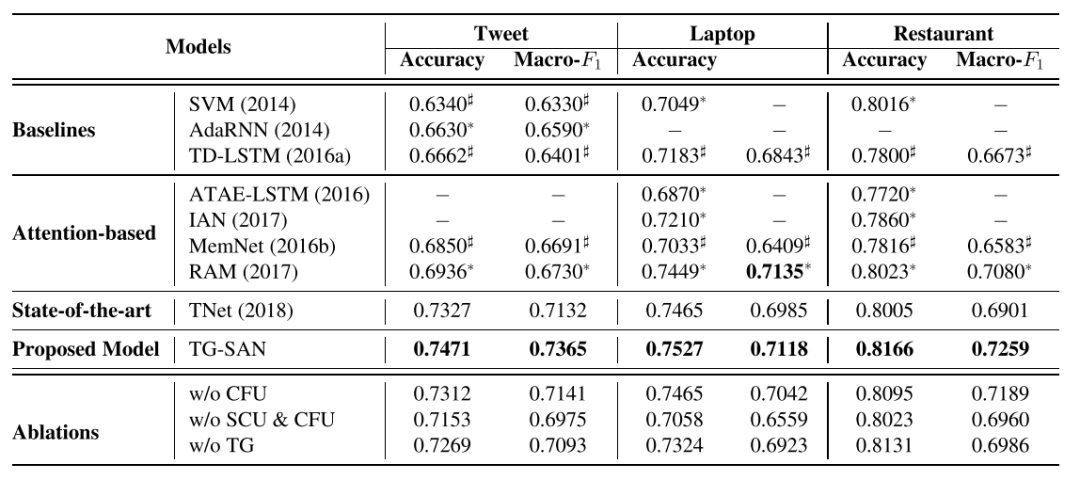
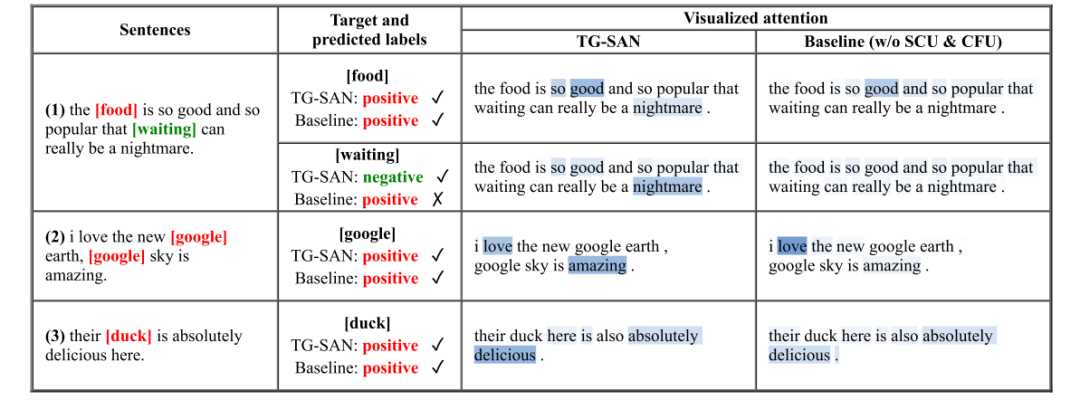
3

簡(jiǎn)介
來(lái)自伍倫貢大學(xué)的兩位研究者提出,從流程上看,對(duì)象級(jí)情感分析任務(wù)(Aspect-based Sentiment Analysis,ABSA)其實(shí)包括兩個(gè)部分,即對(duì)象抽取和情感分類;既有的研究大都將二者分離開(kāi),隱藏在句法結(jié)構(gòu)中的信息就無(wú)法被充分利用。針對(duì)這個(gè)問(wèn)題,本文構(gòu)建了一種端到端的對(duì)象級(jí)情感分析方法,可以充分利用語(yǔ)法信息,并使用自注意力機(jī)制充分挖掘句法結(jié)構(gòu)。在操作上,本文使用了part-of-speech表示、依存表示和上下文嵌入(如BERT,RoBERTa),還使用了句法距離來(lái)降低非相關(guān)單詞的影響力。
在實(shí)際的應(yīng)用任務(wù)(例如商品評(píng)價(jià)分析)中,文本中的對(duì)象并不是可使用數(shù)據(jù),而需要研究者同時(shí)完成對(duì)象抽取(Aspect Extraction,AE)和細(xì)粒度的對(duì)象級(jí)情感分類(Aspect Sentiment Classification,ASC)任務(wù)。當(dāng)前研究將二者分離開(kāi),這就丟失了很多上下文的句法信息,既不現(xiàn)實(shí)也不經(jīng)濟(jì)。而本文的方法將句法信息整合到上下文表示中,最終形成了包括對(duì)象抽取和情感分類的對(duì)象級(jí)情感分類工具(AE+ASC=ABSA)。
方法
本文的構(gòu)建的方法包括兩個(gè)核心單元,其一是對(duì)象抽取(AE),該單元的主要目標(biāo)是標(biāo)識(shí)句中每一個(gè)單詞是否屬于對(duì)象詞匯。本文的對(duì)象抽取模塊稱為“基于句法的結(jié)構(gòu)化對(duì)象抽取器”(contextualized syntax-based aspect extraction,CSAE),包含part-of-speech表示、依存表示和上下文嵌入(如BERT,RoBERTa),其中前兩者還加入了自注意力機(jī)制。具體而言,POS標(biāo)簽來(lái)自Universal POS tags工具,之后有自注意力層負(fù)責(zé)抽取整個(gè)句子的語(yǔ)法依存關(guān)系。依存表示模塊使用了基于句法關(guān)系的依存表示,首先要對(duì)每個(gè)目標(biāo)詞匯及其修飾詞建立上下文集合,隨后的依存關(guān)系學(xué)習(xí)可以延伸到距離較遠(yuǎn)的上下文,還能將不相關(guān)詞匯(即使距離很近)的重要性降低。該單元的架構(gòu)圖如下所示:
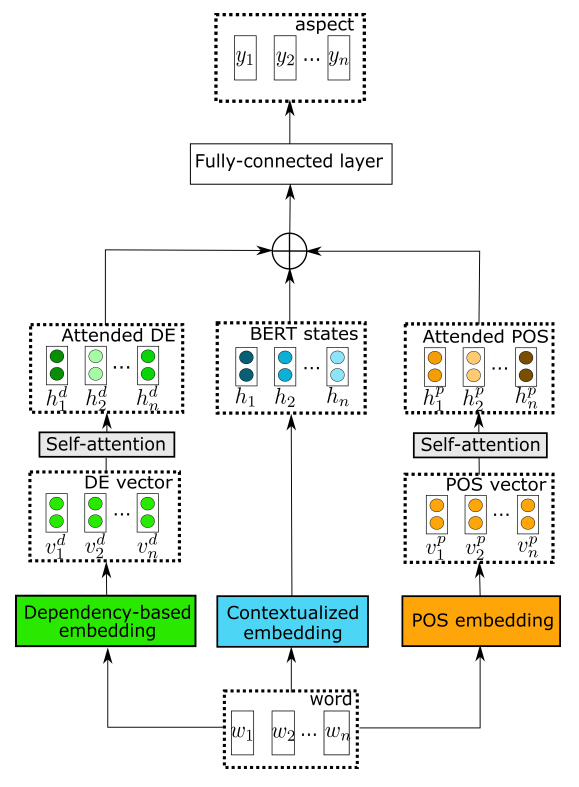
另一個(gè)核心單元負(fù)責(zé)對(duì)象級(jí)情感分析(ASC),將挖掘局部上下文注意力的信息,負(fù)責(zé)將上文得到的上下文表示和對(duì)象術(shù)語(yǔ)轉(zhuǎn)換為情感分類標(biāo)簽,具體思路是將相關(guān)性較小的信息的權(quán)重降低。該單元主要有兩個(gè)組成部分,其一是局部上下文特征,通過(guò)將局部上下文向量送入上下文特征權(quán)重動(dòng)態(tài)遮罩工具和動(dòng)態(tài)調(diào)整工具,分別可以調(diào)整距離對(duì)象較遠(yuǎn)的詞匯的權(quán)重(去除和降低):在特征權(quán)重動(dòng)態(tài)遮罩工具中,若當(dāng)前詞的相對(duì)距離大于預(yù)設(shè)的閾值,重要性矩陣對(duì)應(yīng)該詞的一列為,否則該列為,即全0或全1向量;在特征權(quán)重動(dòng)態(tài)調(diào)整工具中,若當(dāng)前詞的相對(duì)距離大于預(yù)設(shè)的閾值,重要性矩陣對(duì)應(yīng)該詞的一列為;否則,該列為。另一組成部分為全局上下文特征。該單元的架構(gòu)圖如下所示:
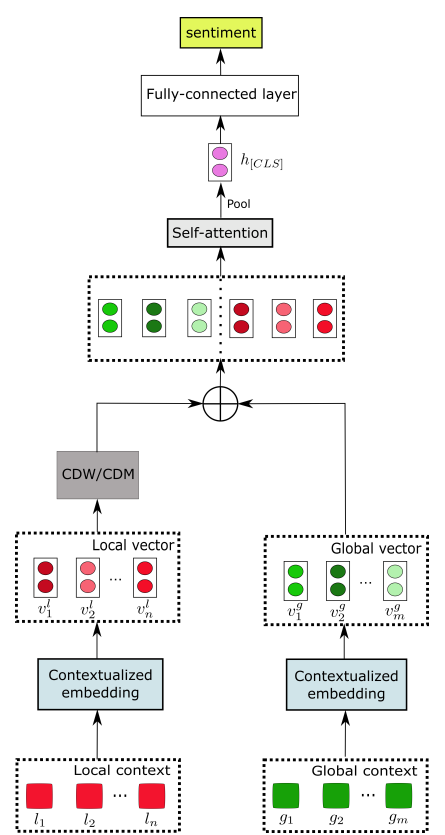
實(shí)驗(yàn)
在SemEval-2014 Task4數(shù)據(jù)集上,本文的方法取得了較好的結(jié)果,且銷熔實(shí)驗(yàn)也證明各部分都有一定的增益。首先是對(duì)象抽取任務(wù),作者比較了本文的模型和其他模型的表現(xiàn),發(fā)現(xiàn)本文模型能取得最好或接近最好的成績(jī);之后又從單純RoBERTa開(kāi)始進(jìn)行銷熔實(shí)驗(yàn),發(fā)現(xiàn)模型各組件都有一定的效果。具體結(jié)果請(qǐng)見(jiàn)下表:
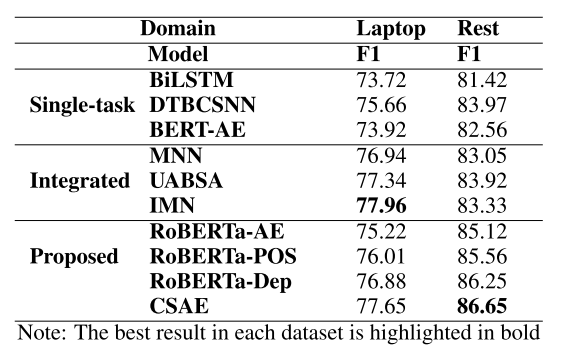
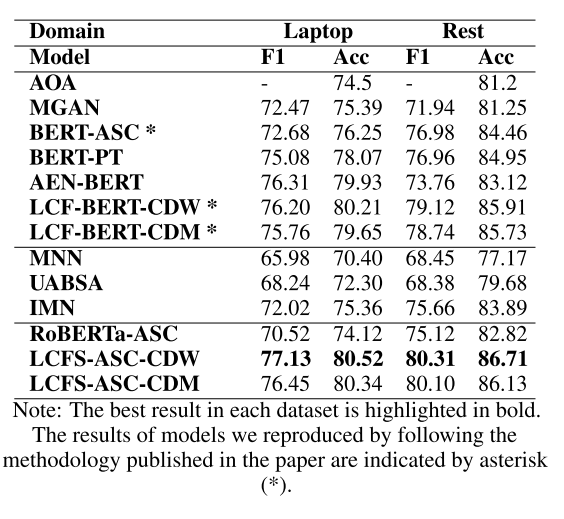
在對(duì)象級(jí)情感分類任務(wù)上,本文的方法均取得了最佳效果,且沒(méi)有使用外部詞庫(kù)。結(jié)果證明本文的設(shè)想的確有足夠的合理性。具體結(jié)果請(qǐng)見(jiàn)下表:
-
計(jì)算公式
+關(guān)注
關(guān)注
3文章
58瀏覽量
25212 -
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48809 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24689
原文標(biāo)題:【論文分享】ACL 2020 細(xì)粒度情感分析方法
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
RoCE與IB對(duì)比分析(二):功能應(yīng)用篇
基于LSTM神經(jīng)網(wǎng)絡(luò)的情感分析方法
迅為iTOP-RK3568開(kāi)發(fā)板驅(qū)動(dòng)開(kāi)發(fā)指南-第十八篇 PWM
嵌入式學(xué)習(xí)-飛凌嵌入式ElfBoard ELF 1板卡-應(yīng)用編程示例控制LED燈之sysfs文件系統(tǒng)
飛凌嵌入式ElfBoard ELF 1板卡-應(yīng)用編程示例控制LED燈之sysfs文件系統(tǒng)
什么是ACL訪問(wèn)控制列表
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)篇
OTA自動(dòng)化測(cè)試解決方案——實(shí)車級(jí)OTA測(cè)試系統(tǒng)PAVELINK.OTABOX

工業(yè)級(jí)POE交換機(jī)的ACL

MCSDK 5.4生產(chǎn)的工程文件中有關(guān)電機(jī)類的.C文件是空的,為什么?
訪問(wèn)控制列表什么?ACL的功能特點(diǎn)
CYW43455帶有7ACL 路的設(shè)備有什么作用嗎?
三防平板是指哪三防,淺談三防工業(yè)級(jí)平板電腦
如何在循環(huán)中斷中創(chuàng)建工藝對(duì)象PID控制器?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論