


由單幀彩色圖像恢復多人的三維姿態和人與相機的絕對位置關系是一個具有挑戰性的任務,因為圖像在拍攝過程中損失了深度和尺度信息。在 ECCV2020 上,商湯與浙大聯合實驗室提出了單步多人絕對三維姿態估計網絡和 2.5D 人體姿態表示方法,并且基于所提出的深度已知的關鍵點匹配算法,得到絕對三維人體姿態。該方法結合圖像的全局特征和局部特征,能獲得準確的人體前后關系和人與相機的距離,在 CMU Panoptic 和 MuPoTS-3D 多人三維人體姿態估計數據集上均達到 SOTA(state-of-the-art),并且在未見過的場景中具有很好的泛化能力。
論文名稱:SMAP: Single-Shot Multi-PersonAbsolute 3D Pose Estimation

動機
基于單幀圖像的人體絕對三維姿態估計在混合現實、視頻分析、人機交互等領域有很廣泛的應用。近幾年研究人員多將注意力集中于人體相對三維姿態估計任務上,并且取得了不錯的成果。但是對于多人場景下人體絕對三維姿態估計任務,除了要估計相對人體三維姿態,更重要的是估計人與相機的絕對位置關系。
當前大多數方法對檢測到的人體區域進行裁剪后,分別估計絕對位置。有的方法利用檢測框的大小作為人體尺寸的先驗,通過網絡回歸深度信息,但是這樣的方法忽略了圖像的全局信息;另外一些方法基于一些假設,通過后處理的手段估計人體深度,如地面約束,但是這樣的方法依賴于姿態估計的準確度,而且很多假設在實際場景中無法滿足(比如人腳不可見)。
我們認為要準確地估計人的絕對三維位置需要利用圖像中所有與深度相關的信息,比如人體尺寸、前后遮擋關系、人在場景中的位置等。近年來有很多工作利用卷積神經網絡回歸場景的深度信息,這啟發我們使用網絡直接估計場景中所有人的深度信息,而不是在后處理過程中恢復深度。
綜上,我們提出了新的單步自底向上的方法估計多人場景的人體絕對三維姿態,它可以在一次網絡推理后得到所有人的絕對位置信息和三維姿態信息。另外,我們還提出了基于深度信息的人體關鍵點匹配算法,包括深度優先匹配和自適應骨長約束,進一步優化關鍵點的匹配結果。
方法介紹
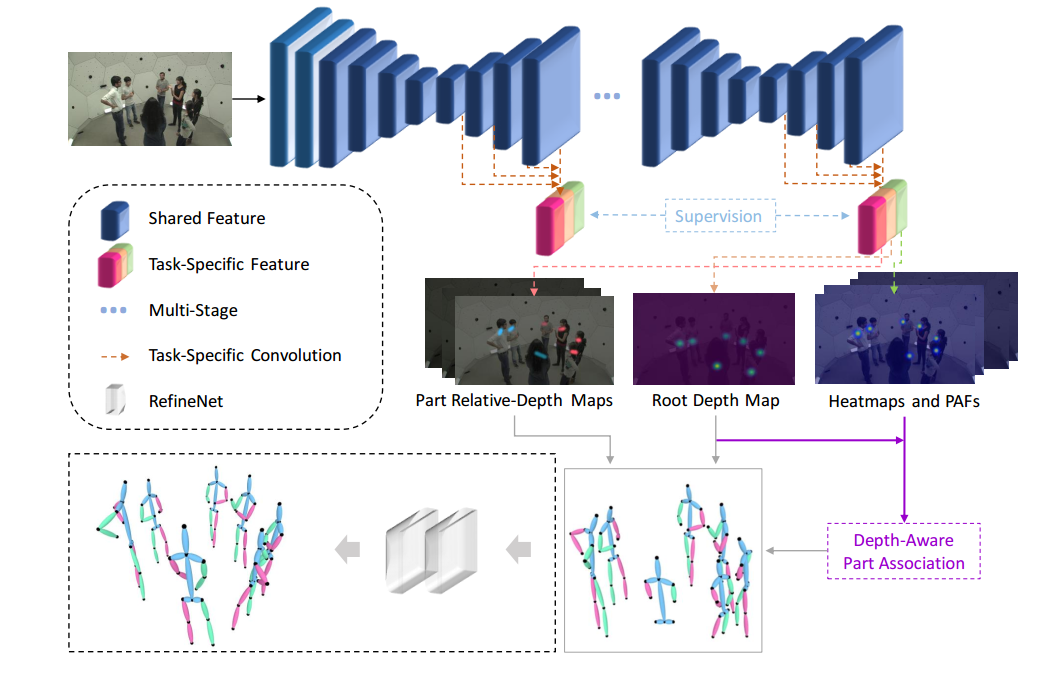
上圖展示了所提出方法的流程,包括 SMAP 網絡,基于深度的關鍵點匹配(Depth-Aware Part Association), 和可選的微型優化網絡(RefineNet)。輸入一張彩色圖像,SMAP 網絡同時輸出人體根節點深度圖(Root Depth Map)、二維關鍵點熱度圖(Heatmaps)、關鍵點連接向量場(PAFs)和骨骼相對深度圖(Part Relative-Depth Maps)。基于以上的 2.5D 特征表示方法,進行關鍵點匹配,然后利用相機模型得到人體絕對三維關鍵點坐標。最后,可以使用微型優化網絡對結果進行補全和優化。
2.12.5D特征表示方式
2.1.1人體根節點深度圖(RootDepthMap)
由于圖像中人體數目是未知的,我們提出了人體根節點深度圖來表示場景中人的絕對深度,根節點深度圖中,每個人根節點(如脖子或腰部)位置的值表示其根節點的絕對深度,在訓練時,只對根節點位置進行監督。其優勢在于,不受圖中人數限制,并且只需要三維人體姿態數據便可以訓練,而不需要整張圖的深度信息。
對于同一個深度下的同一個人,具有不同內參(FoV, field of view)的相機會得到不同的二維圖像,這對建立二維信息(如人體尺寸)和絕對深度之間的映射關系是不利的,所以需要對輸入網絡的深度利用 FoV 進行歸一化:
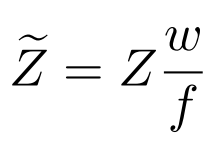

2.1.2Heatmaps和 PAFs
對于二維信息,我們采用與 OpenPose 相同的表示方式。關鍵點熱度圖(Heatmaps)表示關鍵點位于某個像素的概率,關鍵點連接向量場(PAFs)表示關鍵點之間相連的方向和概率。
2.1.3骨骼相對深度圖(PartRelative-DepthMaps)
骨骼相對深度圖生成方式與 PAFs 相同,區別在于它的值表示的是關鍵點之間的深度差。
2.2基于深度的關鍵點匹配算法
由關鍵點熱度圖(Heatmap)得到人體根節點位置后,便可以從根節點深度圖(Root DepthMap)中讀取每個人的深度信息,我們利用深度信息進一步優化人體關鍵點匹配算法,以解決二維關鍵點匹配算法中存在的歧義性問題。
如圖第一行所示,我們提出深度優先匹配,當兩個人存在遮擋時,如果同一個關鍵點有所重疊,單純基于二維信息的匹配方式無法確定該關鍵點的所屬關系,有可能導致大部分關鍵點的錯連,如第三列所示。而重疊的關鍵點在絕大多數場景中應該屬于前一個人,所以基于網絡推斷的深度信息,我們給予靠近相機的人更大的連接優先級,如第四列所示。 另外,我們還提出了自適應骨長距離約束。在二維匹配算法中,一般設置圖像寬度的一半為關鍵點匹配的距離約束,但是由于人與相機距離不同,在二維圖像中呈現的尺寸不同,固定的約束無法起到很好的效果,如圖中第二行第三列所示。對于每個骨骼,我們使用訓練集中該骨骼的平均長度作為其實際長度,然后利用網絡輸出的深度計算其在二維圖像中的最大長度如下:
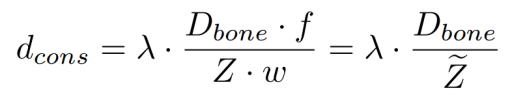

2.3絕對三維姿態恢復
由基于深度的匹配算法獲得人體關鍵點匹配結果后,可以由根節點絕對深度和骨骼相對深度得到每一個關鍵點的絕對深度,然后利用如下公式
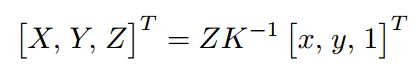
反投影得到人體關鍵點絕對三維坐標。其中 K 是相機內參矩陣,在絕大部分應用中都是已知的,如果未知,可以使用估計值。
由上述步驟恢復的結果可能會引入兩種誤差:由于骨架是以級聯的方式表示的,在恢復末端關節點深度時,會有累計誤差;另外,嚴重的遮擋和圖像截斷會導致人體某些關鍵點的缺失。對此,我們提出了微型補全網絡 RefineNet,輸入估計的相對二維和三維關鍵點坐標,輸出優化和補全后的相對三維關鍵點坐標。RefinNet 并不會對人體根節點絕對深度進行優化。
實驗結果 我們提出的方法在 CMU Panoptic 和 MuPoTS-3D 多人三維人體姿態估計數據集上均達到 SOTA。
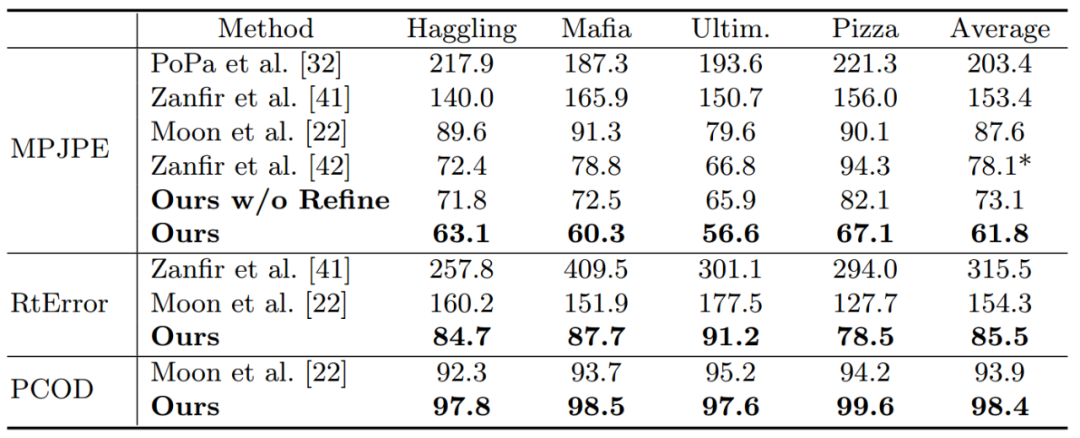
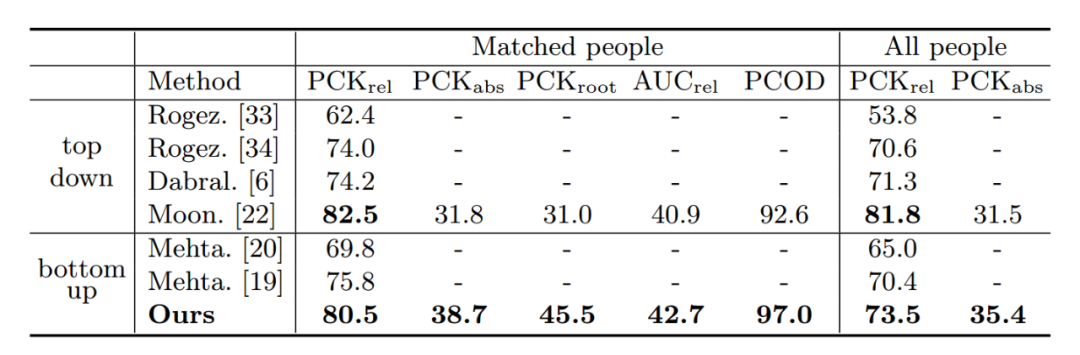
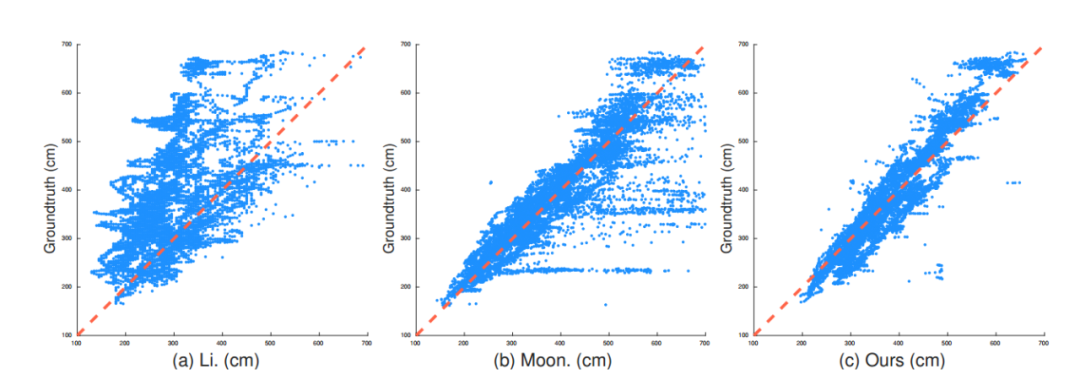
另外,我們對不同可選的深度估計方法進行了對比。第一種,回歸全圖的深度[1],如圖第一列;第二種,根據檢測框的尺寸回歸人體深度[2],如圖第二列。散點圖的橫坐標為人體深度估計值,縱坐標為實際值,散點越靠近 x=y 直線說明回歸的深度越準確。可以看出,我們提出的方法(Root Depth Map)具有更好的深度一致性和泛化能力。
為了體現單步自底向上網絡相對于自頂向下網絡[2]的優勢,我們進行了定性分析。圖中左邊為自頂向下網絡的結果,可見自頂向下的方法會受到姿態變化、人體遮擋、人體截斷的影響,而我們提出的自底向上的方法可以利用全局信息緩解這個問題。
-
三維
+關注
關注
1文章
518瀏覽量
29586 -
匹配算法
+關注
關注
0文章
24瀏覽量
9482 -
SMAP
+關注
關注
0文章
4瀏覽量
8929
原文標題:ECCV2020 | SMAP: 單步多人絕對三維姿態估計
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于OpenGL 的汽車轉向三維模型設計
三維快速建模技術與三維掃描建模的應用
三維模型的空間匹配與拼接

利用并查集的多視匹配點提取算法

彩色分割立體匹配的三維目標快速重建
圖像匹配應用及方法

什么樣的點可以稱為三維點云中的關鍵點呢?
總結!三維點云基礎知識





 工商網監
工商網監

評論