 RTX 30 系列顯卡就要發售了 現在該怎么買 GPU?
RTX 30 系列顯卡就要發售了 現在該怎么買 GPU?
黃老板的 RTX 30 系列顯卡 9 月 17 日就要發售了,現在我要怎么買 GPU?很急很關鍵。
在 9 月 2 日 RTX 30 系列發布時,英偉達宣傳了新顯卡在性能上和效率上的優勢,并稱安培可以超過圖靈架構一倍。但另一方面,除了 3090 之外,新一代顯卡的顯存看起來又有點不夠。在做 AI 訓練時,新一代顯卡效果究竟如何?
近日,曾經拿到過斯坦福、UCL、CMU、NYU、UW 博士 offer、目前在華盛頓大學讀博的知名評測博主 Tim Dettmers 發布了一篇新文章,就深度學習從業者如何選擇 GPU 發表了他的看法。
眾所周知,深度學習是一個很吃算力的領域,所以,GPU 選得好不好直接決定了你的煉丹體驗。那么,哪些指標是你在買 GPU 時應該重視的呢?RAM、core 還是 tensor core?如何做出一個高性價比的選擇?文本將重點討論這些問題,同時指出一些選購誤區。
RTX 3070 打 2080Ti,這是真的嗎?不少人已經被這樣一張性能對比圖「改變了信仰」。
選擇 GPU 時你需要知道的東西
在選購 GPU 之前,你需要知道一些指標在深度學習中意味著什么。
首先是 Tensor Core,它可以讓你在計算乘法和加法時將時鐘周期降至 1/16,減少重復共享內存訪問,讓計算不再是整個流程中的瓶頸(瓶頸變成了獲取數據的速度)。現在安培架構一出,更多的人可以用得起帶 Tensor Core 的顯卡了。
因為處理任務方法的特性,顯存是使用 Tensor Core 進行矩陣乘法的周期成本中最重要的部分。具體說來,需要關注的參數是內存帶寬(Bandwidth)。如果可以減少全局內存的延遲,我們可以進一步擁有更快的 GPU。
在一些案例中,我們可以體驗到 Tensor Core 的強大,它是如此之快,以至于總是在等內存傳來的數據——在 BERT Large 的訓練中,Tensor Core 的 TFLOPS 利用率約為 30%,也就是說,70%的時間里 Tensor Core 處于空閑狀態。這意味著在比較兩個具有 Tensor Core 的 GPU 時,最重要的單一指標就是它們的內存帶寬。A100 的內存帶寬為 1555 GB/s,而 V100 的內存帶寬為 900 GB/s,因此 A100 與 V100 的加速比粗略估算為 1555/900 = 1.73x。
我們預計兩代配備 Tensor Core 的 GPU 架構之間的差異主要在于內存帶寬,其他提升來自共享內存 / L1 緩存以及 Tensor Core 中更好的寄存器使用效率,預估的提升范圍約在 1.78-1.87 倍之間。
在實際應用中,通過 NVLink 3.0,Tesla A100 的并聯效率又要比 V100 提升 5%。我們可以根據英偉達提供的直接數據來估算特定深度學習任務上的速度。與 Tesla V100 相比,A100 的速度提升是:
SE-ResNeXt101:1.43 倍
Masked R-CNN:1.47 倍
Transformer(12 層機器翻譯,在 WMT14 en-de 數據集上):1.70 倍
看來對于計算機視覺任務來說,新架構的提升相對不明顯。這可能是因為小張量尺寸、準備矩陣乘法所需的運算無法讓 GPU 滿負載。也可能是由于特定架構(如分組卷積)導致的結果。在 Transformer 上,預估的提升和實際跑起來非常接近,這可能是因為用于大型矩陣的算法非常簡單,我們可以使用這些實際效果來計算 GPU 的成本和效率。
當然,在發布會中英偉達著重指出:安培架構在稀疏網絡的訓練當中速度提升了一倍。稀疏訓練目前應用較少,但是未來的一個趨勢。安培還帶有新的低精度數據類型,這會使低精度更加容易,但不一定比以前的 GPU 更快。
英偉達花費大量精力介紹了新一代 RTX 3090 的風扇設計,它看起來很好,但并聯起來效果如何還要打上問號。在任何情況下水冷都是效果更好的方案,如果想要并聯 4 塊 GPU,你需要注意水冷的解決方案——它們可能會體積過大。解決散熱問題的另一種方法是購買 PCIe 擴展器,并在機箱內原先不可能的位置放 GPU。這非常有效,華盛頓大學的其他博士研究生和作者本人使用這種方法都取得了成功。它看起來不漂亮,但是可以讓你的 GPU 保持涼爽!
4 塊 RTX 2080Ti 創始版 GPU 的裝法:雖然看起來亂作一團,但用了兩年沒出問題。
還有電源問題,RTX 3090 是一個 3 插槽 GPU,因此在采用英偉達默認風扇設計的情況下,你不能在 4x 的主板上使用它。這是合情合理的,因為它的標準功率是 350W,散熱壓力也更大。RTX 3080 的 320W TDP 壓力只是稍稍小一點,想要冷卻 4 塊 RTX 3080 也將非常困難。
在 4x RTX 3090 的情況下,你很難為 4x 350W = 1400W 的系統找到很好的供電方式。1600W 的電源或許可以,但最好選擇超過 1700W 的 PSU——畢竟黃仁勛在發布中希望你給單卡的 RTX 3080 裝上 700W 的電源。然而目前市面上并沒有超過 1600W 的臺式電腦電源,你得考慮服務器或者礦機 PSU 了。
GPU 深度學習性能排行
下圖展示了當前熱門的 Nvidia 顯卡在深度學習方面的性能表現(以 RTX 2080 Ti 為對比基準)。從圖中可以看出,A100(40GB)在深度學習方面表現最為強勁,是 RTX 2080 Ti 兩倍還多;新出的 RTX 3090(24GB)排第二,是 RTX 2080 Ti 的 1.5 倍左右。但比較良心的是,RTX 3090 的價格只漲了 15%。
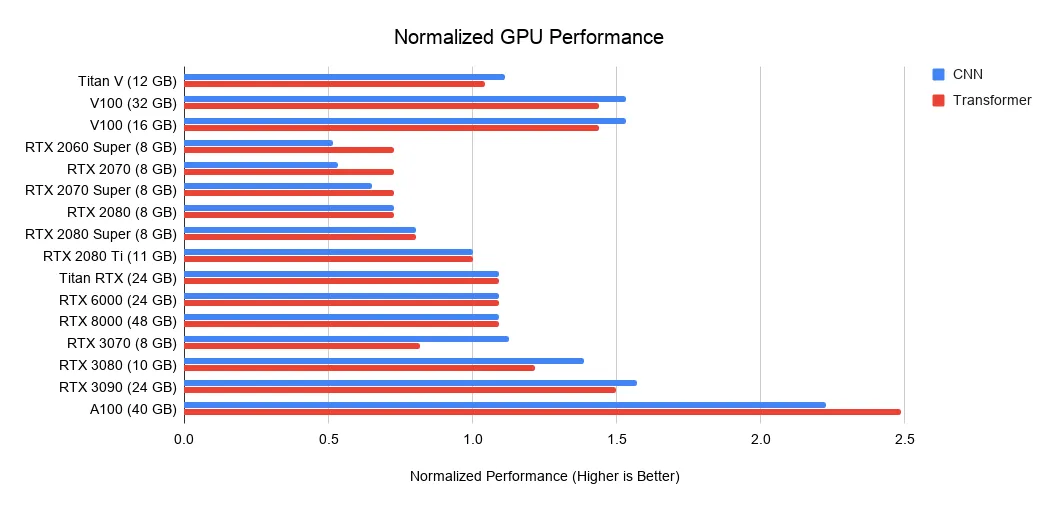
每一美元能買到多少算力?
排在天梯圖頂端的顯卡確實是香,但普通人更關心的還是性價比,也就是一塊錢能買到多少算力。在討論這個問題之前,先來看一下各種任務的大致內存需求:
使用預訓練 transformer 和從頭訓練小型 transformer:》= 11GB;
訓練大型 transformer 或卷積網絡:》= 24 GB;
原型神經網絡(transformer 或卷及網絡):》= 10 GB;
Kaggle 比賽:》= 8 GB;
應用計算機視覺:》= 10GB。
下圖是根據各種 GPU 在亞馬遜、eBay 上的價格和上述性能排行榜算出的「每一美元的 GPU 性能」:

圖 3:以 RTX 3080 為基準(設為 1),各種 GPU 的每一美元性能排行(1-2 個 GPU)。

圖 4:以 RTX 3080 為基準(設為 1),各種 GPU 的每一美元性能排行(4 個 GPU)。

圖 5:以 RTX 3080 為基準(設為 1),各種 GPU 的每一美元性能排行(8 個 GPU)。
GPU 購買建議
這里首先強調一點:無論你選哪款 GPU,首先要確保它的內存能滿足你的需求。為此,你要問自己幾個問題:
我要拿 GPU 做什么?是拿來參加 Kaggle 比賽、學深度學習、做 CV/NLP 研究還是玩小項目?
為了實現我的目標,我需要多少內存?
使用上述成本 / 性能圖表來找出最適合你的、滿足內存標準的 GPU;
我選的這款 GPU 有什么額外要求嗎?比如,如果我要買 RTX 3090,我能順利地把它裝進我的計算機里嗎?我的電源瓦數夠嗎?散熱問題能解決嗎?
針對以上問題,作者給出了一些自己的建議:
什么情況下需要的內存 》= 11GB?
上面說過,如果你要使用預訓練 transformer 或從頭訓練小型 transformer,你的內存至少要達到 11GB;如果你要做 transformer 方向的研究,內存最好能達到 24GB。這是因為,之前預訓練好的那些模型大多都對內存有很高的要求,它們的預訓練至少用到了 11GB 的 RTX 2080 Ti。因此,小于 11GB 的 GPU 可能無法運行某些模型。
除此之外,醫學影像和一些 SOTA 計算機視覺模型等包含很多大型圖像的任務(如 GAN、風格遷移)也都對內存有很高的要求。
總之,多留出來一些內存能讓你在競賽、業界、研究中多一絲從容。
什么情況下<11 GB 的內存就夠用了?
RTX 3070 和 RTX 3080 性能都很強大,就是內存有點小。但在很多任務中,你確實不需要那么大的內存。
如果你想學深度學習,RTX 3070 是最佳選擇,因為把模型或輸入圖像縮小一點就能學到大部分架構的基本訓練技巧。
對于原型神經網絡而言,RTX 3080 是迄今為止性價比最高的選擇。在原型神經網絡中,你想用最少的錢買最大的內存。這里的原型神經網絡涉及各個領域:Kaggle 比賽、為初創公司開拓思路 / 模型、以及用研究代碼進行實驗。RTX 3080 是這些場景的最佳選擇。
假設你要領導一個研究實驗室 / 創業公司,你可以把 66-80% 的預算投到 RTX 3080 上,20-33% 用于推出帶有強大水冷裝置的 RTX 3090。這是因為,RTX 3080 性價比更高,而且可以通過一個 slurm 集群設置作為原型機共享。由于原型設計應該以敏捷的方式完成,所以應該使用更小的模型和更小的數據集,RTX 3080 很適合這一點。一旦學生 / 同事有了一個很棒的原型模型,他們就可以在 RTX 3090 機器上推出該模型并將其擴展為更大的模型。
建議匯總
總之,RTX 30 系列是非常強大的,值得大力推薦。選購時還要注意內存、電源要求和散熱問題。如果你在 GPU 之間有一個 PCIe 插槽,散熱是沒有問題的。否則,RTX 30 系列需要水冷、PCIe 擴展器或有效的鼓風機卡。
作者表示,他會向所有買得起 RTX 3090 的人推薦這款 GPU,因為在未來 3-7 年內,這是一款將始終保持強大性能的顯卡。他認為,HBM 內存在未來的三年之內似乎不會降價,因此下一代 GPU 只會比 RTX 3090 的性能提升 25% 左右。未來 5-7 年有望看到 HBM 內存降價,但那時你也該換顯卡了。
對于那些算力需求沒那么高的人(做研究、參加 Kaggle、做初創公司),作者推薦使用 RTX 3080。這是一個高性價比的解決方案,而且可以確保多數網絡的快速訓練。
RTX 3070 適合用來學深度學習和訓練原型網絡,比 RTX 3080 便宜 200 美元。
如果你覺得 RTX 3070 還是太貴了,可以選擇一個二手 RTX 2070。現在還不清楚會不會有 RTX 3060,但如果你確實預算有限,可以選擇再等等。
GPU 集群建議
GPU 集群的設計高度依賴于你的應用場景。對于一個 + 1024 GPU 的系統,網絡是最重要的;但如果用戶的系統一次只用 32 個 GPU,那大手筆投資網絡基礎設置就是一種浪費。
一般情況下,RTX 顯卡被禁止通過 CUDA 許可協議接入數據中心,但通常高校例外。你可以與英偉達取得聯系,以尋求豁免。
如果你被允許使用 RTX 顯卡,作者推薦使用裝有 RTX 3080 或 RTX 3090 的標準 Supermicro 8 GPU 系統(如果散熱沒問題的話)。一小組 8x A100 節點就可以保證原型的 rollout,特別是在無法保證 8x RTX 3090 服務器能夠有效冷卻的情況下。在這種情況下,作者推薦使用 A100,而不是 RTX 6000 / RTX 8000,因為 A100 性價比很高,也頗有潛力。
如果你想在 GPU 集群上訓練非常大的網絡,作者推薦裝備了 A100 的 NVIDIA DGX SuperPOD 系統。在 +256 GPU 的規模下,網絡變得非常重要。如果你想擴展到 256 個 GPU 以上,你就需要一個高度優化的系統。
如果到了 + 1024 GPU 的規模,市場上唯一有競爭力的方案就只剩下 Google TPU Pod 和 NVIDIA DGX SuperPod。在這個級別上,作者更推薦 Google TPU Pod,因為它們定制的網絡基礎設施似乎優于 NVIDIA DGX SuperPod 系統,盡管兩個系統非常接近。
與 TPU 系統相比,GPU 系統可以為深度學習模型和應用提供更大的靈活性,但 TPU 系統也有優勢,它可以支持更大的模型并提供更好的擴展。
這些 GPU 別買
不建議買 RTX Founders Edition(任何一個)或 RTX Titan,除非你有 PCIec 擴展器能解決散熱問題。
不建議買 Tesla V100 或 A100,因為性價比不高,除非你被逼無奈或者想在龐大的 GPU 群集上訓練非常大的網絡。
不建議買 GTX 16 系列,這些卡沒有張量核心,因此在深度學習方面性能較差,不如選 RTX 2070 / RTX 2060 / RTX 2060 Super。
什么時候不要入手新的 GPU?
如果已經擁有 RTX 2080 Ti 或更好的 GPU,升級到 RTX 3090 可能沒什么意義。相比于 RTX 30 系列的 PSU 和散熱問題,性能提升所帶來的好處有些微不足道。從 4x RTX 2080 Ti 升級到 4x RTX 3090 的唯一原因可能是,在做 Transformer 或其他高度依賴算力去訓練網絡的研究。
如果你有一個或多個 RTX 2070 GPU,這也已經相當不錯了。但如果常常受到 8GB 內存的限制,那么轉讓這些再入手新的 RTX 3090 是值得的。
一言以蔽之,如果內存不夠,升級 GPU 還是很有意義的。
GPU 相關疑難問題解答
用戶關于 GPU 肯定有很多不了解甚至是誤解的地方,本文作者做出了以下相關問答總結,主要涉及 PCle 4.0、RTX3090/3080 以及 NVLink 等等。
我需要 PCle 4.0 嗎?
一般來說不需要。如果你有一個 GPU 集群,那么擁有 PCle 4.0 棒極了。如果你有一個 8x GPU 機器,那么擁有 PCle 4.0 也挺好的。但除此之外,PCle 4.0 就沒什么用。
PCle 4.0 可以實現更好的并行化處理以及更快的數據傳輸。但是數據傳輸不會成為任何應用中的瓶頸。在計算機視覺領域,數據存儲可以成為數據傳輸 pipeline 的瓶頸,但從 CPU 到 GPU 的 PCle 傳輸卻不會成為瓶頸。
所以對于大多數人來說,PCle 4.0 是沒有必要的。在 4 個 GPU 設置下,PCle 4.0 只能實現 1%-7% 的并行化提升。
我需要 8x/16x PCle 通路嗎?
與 PCle 4.0 一樣,一般來說不需要。
在 4x 通路上運行 GPU 就挺好的,特別是當你只有 2 個 GPU 時。在 4 個 GPU 設置下,作者傾向于每個 GPU 上有 8x 通路,但如果你在全部 4 個 GPU 上進行并行化處理,則在 4x 通路上運行可能僅降低大約 5%-10% 的性能。
如果 4x RTX 3090 每個都占用 3 個 PCle 插槽,如何把它們塞進機箱?
你需要一個雙插槽變體或者嘗試使用 PCle 擴展器。除了空間外,還應該考慮冷卻和合適的 PSU。所以最可行的解決方案是獲取帶有自定義水冷回路的 4x RTX 3090 EVGA Hydro Copper。
PCle 擴展器或許也可以同時解決空間和冷卻問題,但你需要確保有足夠的空間來擴展 GPU。
我可以使用多個不同型號的 GPU 嗎?
當然可以。
也許你想要使用多個不同型號的 GPU 的原因是:想要利用舊的 GPU。這種情況下正常運行是沒問題的,但這些 GPU 上的并行化處理將會非常低效,因為速度最快的 GPU 需要等待最慢的 GPU 來趕上一個同步點(通常是梯度更新)。
什么是 NVLink,它有用嗎?
一般來說沒有用。NVLink 是 GPU 之間的高速互連,當你擁有一個配備 128 個 GPU 以上的 GPU 集群時,它才有用。否則相較于標準 PCle 傳輸來說,NVLink 幾乎沒有任何益處。
即使是最便宜的 GPU,我也買不起,怎么辦?
買二手 GPU 也沒問題。二手的 RTX 2070(400 美元)和 RTX 2060(300 美元)都很棒,如果還是買不起,可以試試二手的 GTX 1070(220 美元)或 GTX 1070 Ti(230 美元),以及 GTX 980 Ti(6GB,150 美元)或 GTX 1650 Super(190 美元)。
實在不行,你還可以薅羊毛,去使用免費的 GPU 云服務。這種通常會有時間、賬戶等限制,超過之后需要付費。那么,就在不同賬戶之間切換使用吧,直到你買得起 GPU。
如何跨計算機并行化?
這樣的話,需要 + 50Gbits/s 的網卡才能加快速度,之前作者寫過一篇文章專門論述這件事(https://timdettmers.com/2014/09/21/how-to-build-and-use-a-multi-gpu-system-for-deep-learning/)。現在的建議是至少要上 EDR Infiniband,也就是至少 50 GBit / s 帶寬的網卡,價格大概在 500 美元左右。
我需要一塊英特爾 CPU 來支持多 GPU 設置嗎?
不建議使用英特爾 CPU,除非你要在 Kaggle 競賽中大量使用 CPU。即便如此,使用 AMD CPU 也很棒。就深度學習而言,AMD CPU 通常比 Intel CPU 更便宜且更好。
對于內置的 4x GPU,作者的首選是 Threadripper。在大學期間作者曾使用 Threadripper 搭建了數十個系統,它們都運行良好。對于 8x GPU 系統,CPU 和 PCIe / 系統的可靠性比直接的性能或性價比更重要。
我要等等 RTX 3090 Ti 嗎?
首先,我們不確定會不會有 RTX 3080 Ti / RTX 3090 Ti / RTX Ampere Titan。
GTX XX90 的名稱通常會留給雙 GPU 卡,現在英偉達算是打破了這個規則。從價格和性能上看,RTX 3090 似乎取代了 RTX 3080 Ti。
如果你感興趣,可以在幾個月內密切關注一下相關消息。如果沒有什么進展,也就意味著不太可能有 RTX 3080 Ti / RTX 3090 Ti / RTX Ampere Titan 了。
電腦機箱的設計對于散熱是否重要?
并不。
如果 GPU 之間存在間隙的話,通常能夠很好地冷卻。機箱的設計會帶來 1-3 攝氏度的效果提升,但 GPU 之間的空間將帶來 10-30 攝氏度的效果提升,所以說只要 GPU 之間留有空間,散熱就不成問題。但如果 GPU 之間沒有空間,則需要好的散熱器設計(風扇)和其他解決方案(水冷、PCIe 擴展)。
總而言之,散熱與機箱設計和機箱風扇都沒關系。
AMD GPU + ROCm 是否會趕上 NVIDIA GPU + CUDA?
在未來 1 到 2 年內不會。這個問題分三方面:張量核心、軟件和社區。
就純硅芯片來說,AMD 的 GPU 非常優秀:出色的 FP16 性能和內存帶寬。但與英偉達 GPU 相比,在缺少張量核心或等效條件下,AMD 的深度學習性能更差。大量的低精度數學運算也未能解決這個問題。達不到這種硬件功能,AMD GPU 將永遠無法與之競爭。有傳言表明,一些與張量核心等效的 AMD 數據中心卡計劃于 2020 年推出,但估計很少有人會買吧。
即便假設 AMD 將來會推出類似張量核心的硬件功能,但很多人也會說:「可是沒有適用于 AMD GPU 的軟件,我該如何使用它?」這里存在一些誤解,AMD ROCm 平臺日漸成熟,并且對 PyTorch 也實現了原生支持,大可不必擔心。
如果你解決了軟件和不具有張量核心的問題,還會意識到另外一個問題:AMD 的社區不成熟。如果你在使用英偉達 GPU 時遇到了什么問題,可以 Google 一下找到解決方案,而且還能了解到很多的使用技巧和專業人士的經驗帖。AMD 在這方面就不那么盡如人意了。
拿編程語言來舉例的話,就像是 Python 和 Julia 的關系。Julia 被認為潛力巨大,而且是科學計算領域的高級編程語言,但其使用者數量與 Python 完全無法相提并論。歸根結底是因為 Python 社區非常完善。
綜上所述,在深度學習領域,英偉達至少還可以壟斷兩年。
與專用 GPU 臺式機 / 服務器相比,何時使用云計算更好?
1 個建議:如果你從事深度學習超過一年,請使用臺式機 GPU。
一般來說,臺式機 GPU 的利用率如下:
博士生個人臺式機:《15%;
博士生 slurm GPU 集群:》35%;
企業級 slurm 研究集群:》60%。
在前沿研究重要性高于開發實體產品的行業,專用 GPU 的利用率較低。從研究領域上看,一些領域的利用率很低(可解釋性研究),另一些領域的利用率則高得多(機器翻譯、語言建模)。通常人們都會高估個人計算機的利用率,所以作者強烈建議研究小組和企業使用 slurm GPU 集群,但個人的話就不必了。
長求總
現在最好的 GPU:RTX 3080 和 RTX 3090。
對于個人來說,這些 GPU 不要買:任何 Tesla 卡、任何 Quadro 卡、任何「創始版」GPU,還有包括 Titan RTX 的所有型號泰坦。
性價比高,但比較貴的:RTX 3080。
性價比高,且較便宜的:RTX 3070 和 RTX 2060 Super。
還想再便宜點?推薦度依次遞減:RTX 2070 ($400)、RTX 2060 ($300)、GTX 1070 ($220)、GTX 1070 Ti ($230)、GTX 1650 Super ($190) 和 GTX 980 Ti (6GB $150)。
什么也別說了,我沒有錢:請使用各家云服務的免費額度,直到你買得起 GPU。
我要搞 Kaggle:RTX 3070。
我是一個高端的計算機視覺、預訓練模型或者機器翻譯研究人員:四塊 RTX 3090 并聯,但請等散熱壓得住的版本出現,而且也要考慮電源負載(作者還會繼續更新這篇文章,可以等待未來的評測)。
我是普通 NLP 研究者:如果不研究機器翻譯、語言模型、預訓練等,一塊 RTX 3080 應該就夠了。
我要入門深度學習,不開玩笑:你可以從購買一塊 RTX 3070 開始,如果半年之后仍然熱情不減,你可以把 RTX 3070 出售,購買四塊 RTX 3080。再遠的未來,隨著你選擇路線不同,需求也會出現變化。
我想試試深度學習:RTX 2060 Super 非常出色,但你可能需要為它更換電源。如果你的主板有 PCIe×16 卡槽,電源有 300W,一塊 GTX 1050Ti 是最適合的。
我們組要搭建一百塊 GPU 的集群:66% 的八塊 RTX 3080 并聯和 33% 的八塊 RTX 3090 并聯是最好選擇,但如果 RTX 3090 的冷卻真的有問題,你可能需要買 RTX 3080 或 Tesla A100 作為代替。
128 塊以上的 GPU 集群:在這個規模上,8 塊成組的 Tesla A100 效率更高。如果超過 512 塊 GPU,你應該使用 DGX A100 SuperPOD 系統。
本文作者 Tim Dettmers 目前是華盛頓大學在讀博士,他碩士畢業于瑞士盧加諾大學。 對于 DIY 深度學習「煉丹爐」的人來說,這個名字應該不會陌生。 他撰寫并更新的深度學習 GPU 評測文章一直受人關注,Tim 的 AI 技術文章也時常被英偉達的開發博客所收錄。
值得一提的是,Tim Dettmers 在申請讀博方面也頗有心得,他拿到了斯坦福大學、華盛頓大學、倫敦大學學院、卡內基梅隆大學以及紐約大學的 offer 并最終選擇了華盛頓大學。
作者:Tim Dettmers
編譯:機器之心
-
gpu
+關注
關注
28文章
4830瀏覽量
129778 -
顯卡
+關注
關注
16文章
2487瀏覽量
68562 -
英偉達
+關注
關注
22文章
3872瀏覽量
92452
發布評論請先 登錄
相關推薦
英偉達RTX 50系列顯卡面臨供應瓶頸
英偉達RTX 4060系列顯卡供應將大幅縮減
GPU-Z迎來2.62 版本的更新發布
英偉達RTX 5070顯卡獲Vulkan1.4認證
技嘉RTX 5090 D和 5080系列顯卡開售,性能猛獸降臨
技嘉科技發布GeForce RTX 5090 D 和RTX 5080系列顯卡

微星RTX 50系列顯卡 異色電源線護航供電安全
技嘉CES 2025發布RTX 50系列顯卡,升級散熱縮小體積
英偉達發布Blackwell架構RTX 50系列顯卡
技嘉于 CES 2025 首度亮相升級散熱設計與精實體積的 NVIDIA GeForce RTX 50 系列顯卡
RTX 5090顯卡即將量產 配置細節曝光
英偉達RTX 50系列顯卡價格揭曉:高端版高價引發熱議
英偉達為提升RTX 50系列顯卡良率,推遲上市計劃
新款Nvidia Titan GPU正在開發中?或將擊敗未發布的RTX 5090

Nvidia 再推出特供版顯卡 GeForce RTX 5090D





 工商網監
工商網監
評論