 針對碼間干擾以及如何消除碼間干擾的分析
針對碼間干擾以及如何消除碼間干擾的分析
隨著信號速率的提高,信號質量會朝兩個方面惡化。一方面由于時鐘周期變短,固有抖動所帶來的影響變得嚴重,舉例來說,對于1Gbps的信號,1個時鐘周期為1ns,峰值為50ps的隨機抖動不會給系統帶來太大的影響;但是對于10Gbps的信號,1個時鐘周期為100ps,50ps的隨機抖動對系統的影響是致命的。另一方面,速率提升使得通道的損耗變大,碼間干擾會變得更加嚴重。這篇文章主要針對碼間干擾的產生以及如何消除碼間干擾進行分析。
碼間干擾,又稱ISI(Inter symbolinterference),顧名思義是不同信號(碼元)之間的干擾,在說碼間干擾之前,我們先說一下編碼。
1編碼方式
作為一名工程師,我們分析和處理信號,并不僅僅關心信號本身,而是信號中所承載的信息。對于數字信號,最終表現出來的是一連串的二進制(0/1)數據,數據和電平之間有一定的編碼關系,下面列舉幾種常見的編碼方式——NRZ、NRZI、MLT-3。
NRZ即Non-Return to Zero Code, 非歸零碼,是最簡單常見的編碼方式,用0電位和1點位分別二進制的“0”和“1”,編碼后速率不變,有很明顯的直流成份,NRZ編碼的最高頻率基波是波特率的1/2。許多協議都是用的NRZ碼,例如:PCIe、SATA、SAS和USB 3.0SS。
NRZI即Non-Return to Zero Inverted,非歸零反轉碼,編碼不改變信號速率。NRZI的特點是遇到數據“0”電平保持不變,遇到數據“1”電平翻轉,NRZI極性翻轉并不影響數據傳輸。和NRZ一樣,NRZI編碼的最高頻率基波也是波特率的1/2,USB 2.0 HS協議使用的是NRZI編碼。
MLT-3即Multi-Level Transmit -3,多電平傳輸碼,MLT-3碼跟NRZI碼有點類似,其特點都是逢“1”跳變,逢“0”保持不變,并且編碼后不改變信號速率。和NRZ/NRZI不同,MLT-3需要4 bit才完成一次完整周期跳變(NRZ和NRZI是2 bit),相對應的最高頻率基波是波特率的1/4。百兆以太網(FE)使用的就是MLT-3編碼。
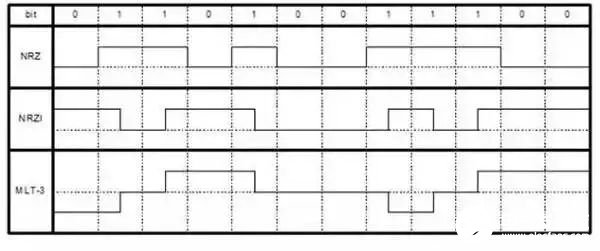
圖1 NRZ NRZI和MLT-3編碼
由于現在高速場景都是使用2電平編碼(PAM4尚未普及),NRZ和NRZI碼型在物理層上面的表現并沒有實質性的區別,所以我們下面以NRZ碼為例。
如圖2所示的鏈路的插損[2]如圖3所示(相當于20inch FR4背板的損耗),從TX發出的10Gbps理想信號經過背板后在圖2中1/2/3所示位置的信號和眼圖如圖4、圖5和圖6所示,圖中左側兩個信號分別為理想信號和圖2中各個不同位置的信號對比,右側為圖2中各個位置的眼圖。
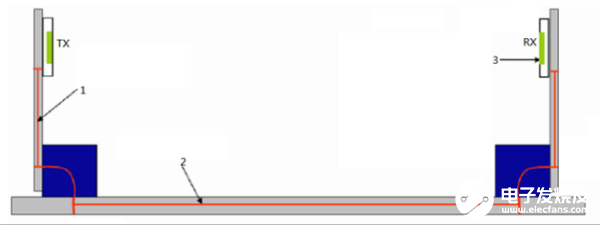
圖2 互連背板鏈路示意圖
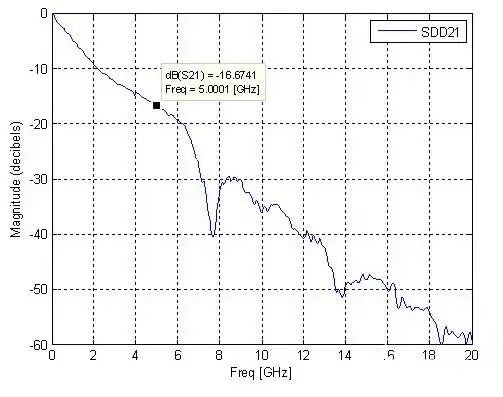
圖3 背板插損
插損:介質損耗或InsertionLoss,簡稱IL,IL =-S21
可以看出,由于ISI的存在,接收端(圖6)的眼圖已經完全模糊,無法從信號中判斷電平的’0’和’1’,如果不經過處理的話,數據從發送端傳送到接收端會出現大量的誤碼。
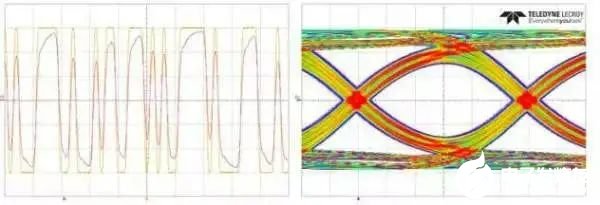
圖4 近端(位置1處)信號和眼圖
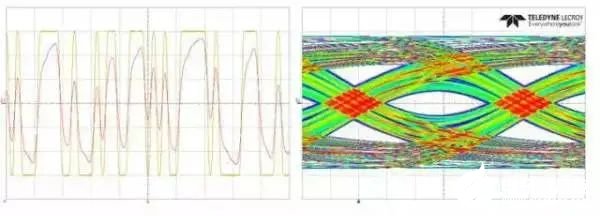
圖5 位置2處信號和眼圖
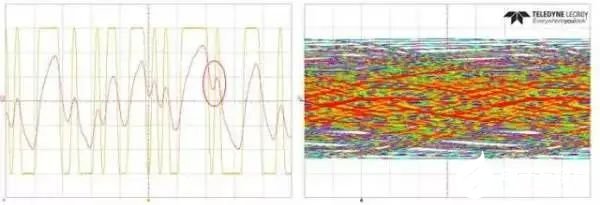
圖6 接收端(位置3處)信號和眼圖
在插損很大時,在低頻信號和高頻信號交界的地方,最容易產生ISI。如圖6中紅圈部位所示,在一串如’11111101’這樣的信號,先出現長串的’1’,然后接著是’01’信號,在長’1’信號向’01’信號切換的時候,由于放電時間不足,使得’0’電平嚴重偏離垂直參考點。所以ISI一般有兩個必備條件:1)插損很大;2)低頻信號和高頻信號切換。消除ISI也需要從這兩個方面來考慮。
減小插損一般來說有兩種辦法:一種是減小走線長度,另一種是使用更好板材的PCB以及更好的連接器,然而減小走線長度的話可能會影響布線,而使用更好的板材和連接器會大大增加系統的成本,所以這種方法本文中不再詳述。
28B/10B編碼
由于數據是隨機的,當反復發送”010101”之類的電平時是信號中能夠出現的最高基波頻率成分,恒定為波特率的一半,但是由于在實際信號中出現連續的’1’或者連續的’0’信號的個數是不確定的,出現連續’0’或者’1’的個數越多,對信號質量的影響越大。圖7為兩種不同碼型信號經過同一鏈路的仿真結果,上邊是PRBS7,下邊是PRBS9[3],可以明顯看出PRBS9的TJ和ISI比PRBS7大。
限制信號中最長的連續’0’和’1’的個數可以改善ISI,8B/10B編碼就是其中最常用的一種編碼方式,8B/10B編碼將8位數據分解成兩組,一組3位、一組5位,經過編碼之后變成一組4位和一組6位的10位數據,經過編碼后的數據中連續’0’和’1’的個數不超過5個,另外,經過8B/10B編碼后的數據’0’和’1’數量基本保持相等,使得信號的DC平衡。USB3.0、PCIe1.0、PCIe2.0和SATA等協議都使用8B/10B編碼。類似的還有64B/66B、128B/130B編碼等,同時在使用NRZI的USB 2.0中,為了限制連續高或者連續低電平的長度,規定在數據中連續出現6個’1’之后自動插入1個’0’,這也是這個目的。但是8B/10B編碼會影響信號的有效帶寬,每10比特信號中只傳遞8比特有效信號,先當于20%的帶寬是浪費的。從PCIe2.0到PCIe3.0的演進中,就放棄了8B/10B編碼,線速率從5Gbps到8Gbps但是實際的帶寬卻翻了一倍
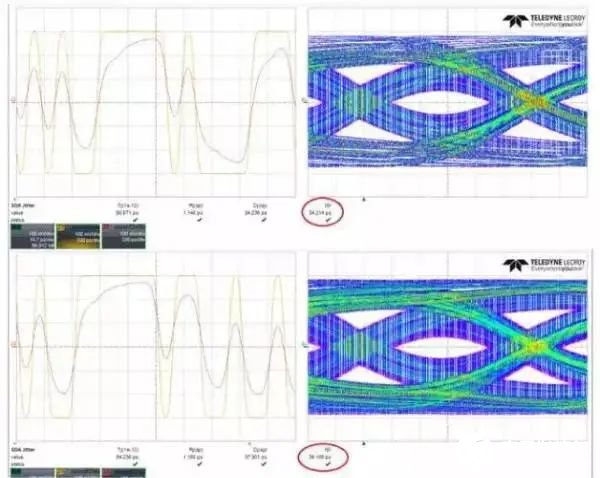
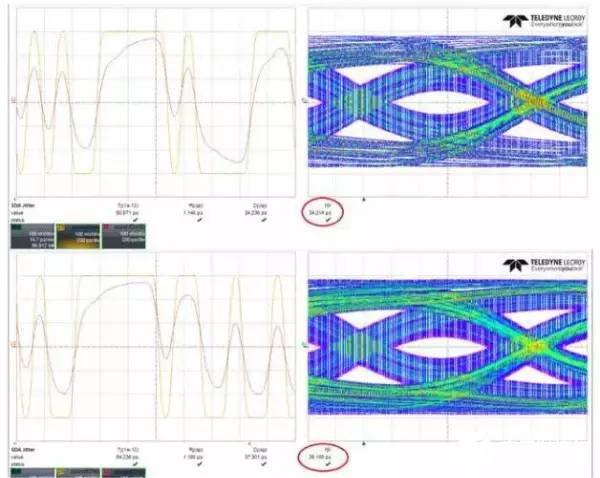
圖7 PRBS7和PRBS9的ISI
PRBS:偽隨機碼,PRBS后面的數字越大,出現的連續的’0’和’1’信號的個數就越長
3加重和均衡
均衡可以分為發送端均衡和接收端均衡,發送端均衡稱為加重或者FFE,接收端的均衡有CTLE和DFE兩種。
FFE:FFE是Feed forward equalizers的縮寫,它可以分為預加重(Pre-Emphasis)和去加重(De-Emphasis)的方法類似,都是通過在TX改變高、低頻成分(如圖8所示),區別是預加重是增加高頻成分,去加重是減少低頻成分,經過TX端的均衡后能夠改善信號質量,現在一般都使用去加重的方式,常用的有2種——Pre cursor和Post cursor,Pre和Post如圖9所示。一般情況下Post cursor使用較多,在鏈路較惡劣的時候加一些Pre cursor可以使眼圖的“眼皮”變薄。De-Emphasis的大小是由高頻部分和低頻部分的比值決定的,高頻部分電壓和低頻部分電壓的比值越大,對抗鏈路差損的能力也就越強。下圖的Pre cursor和Post cursor都是6dB,也就是高頻電壓是低頻的兩倍。FFE的優點是不會放大信號的噪聲,另外,在惡劣的鏈路環境下,如果光依靠RX的均衡無法使得眼圖睜開,在這種情況下我們推薦使用FFE。
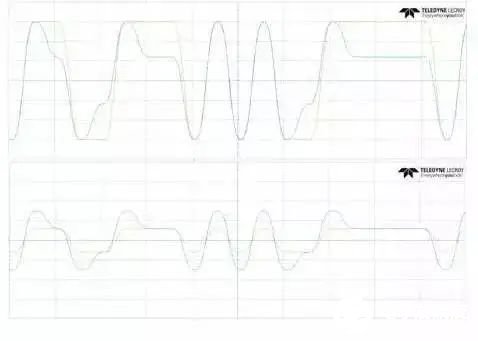
圖8 De-Emphasis上和Pre-Emphasis下
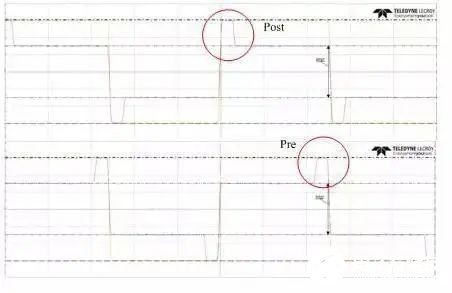
圖9 Post cursor和Pre cursor
圖10是鏈路中接收端經過加重后的眼圖,經過8dB的Post cursor去加重后,眼圖已經睜開。
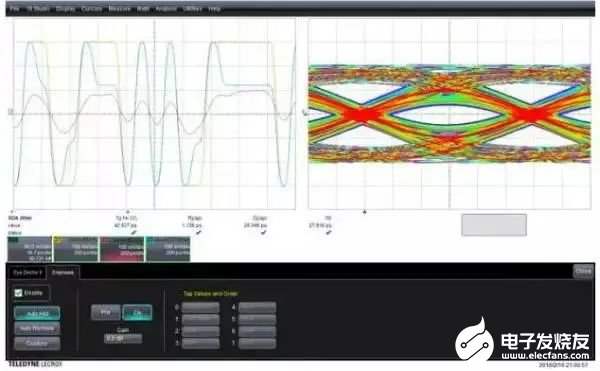
圖10 鏈路中接收端經過加重后的眼圖
圖11是加上8dB 去加重后鏈路中各個位置的眼圖。從圖11可以看出,在鏈路中芯片發送端以及位置1/2處的眼圖都有嚴重的overshoot,這就是FFE的不足之處,由于在發送端增加了高頻成分,在多Lane系統中會增加串擾,并且可能會導致EMC超標,在現在的高速系統中,會將較多的均衡的權重分配在接收端。
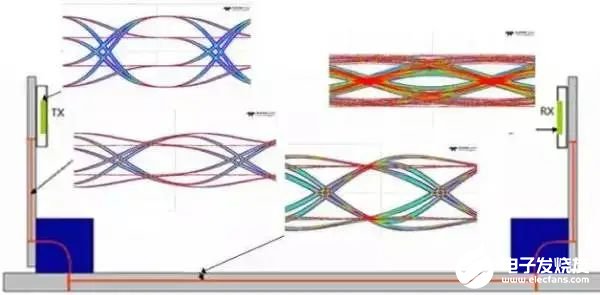
圖11 經過加重后鏈路中各個位置的眼圖
CTLE:CTLE是Continuous-time linearequalizer的縮寫,它是有如圖12頻響曲線的放大電路,它們會對高頻信號進行放大,對低頻信號進行衰減,以補償通道的插損。對待不同的鏈路,我們可以調節CTLE電路的參數(如增益、boost、零點、peak點等)獲得恰當的頻響曲線來進行補償(如圖13所示)。通常來說,CTLE電路各參數相互配合組成的組合越多,芯片應對不同場景鏈路的能力也就會越強,這種芯片通常還會集成CTLE的自適應算法,根據鏈路自動調節CTLE的參數以獲得最優的參數。
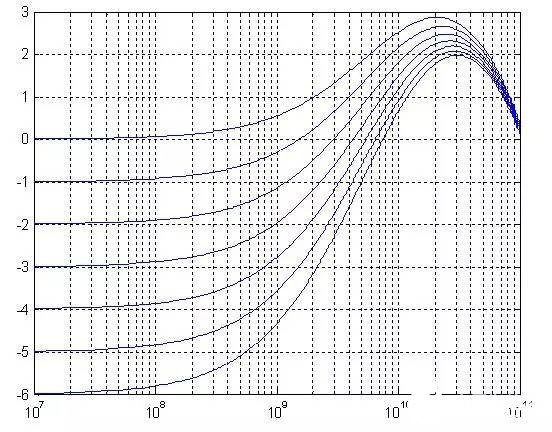
圖12 CTLE頻響曲線示意圖
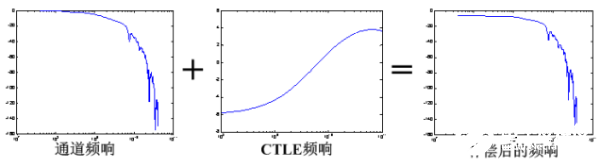
圖13 經過CTLE補償的鏈路頻響
圖14是圖13中信號經過CTLE均衡后得到的眼圖。可以看出,CTLE補償的效果和去加重相比要好一些。
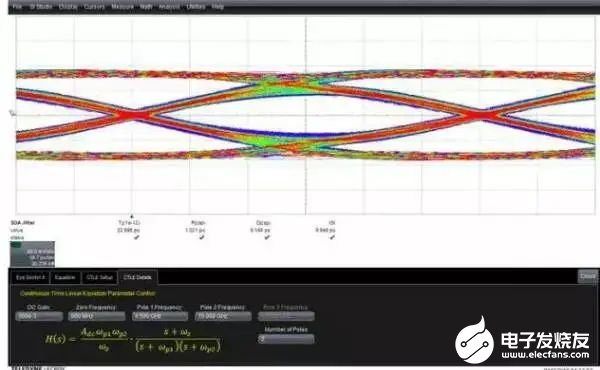
圖14 經過CTLE均衡后的眼圖
但是在鏈路很長(鏈路插損很大)時,CTLE為了補償鏈路的插損,通常會將高頻進行放大,這樣一方面會將高頻噪聲放大,降低系統的信噪比;另一方面,CTLE的溫度特性相對較差,高溫下的增益比低溫小,所以在溫度變化時不利于系統的穩定,在這個時候我們需要DFE的幫助。
DFE:DFE是Decisionfeedback equalizer的縮寫,電路中DFE一般在CTLE之后。DFE的實現方式和FFE類似。DFE可以輔助CTLE改善信號質量,另外DFE可以實時地根據眼圖的情況進行自適應調節,它可以用來補償由于溫度或者其他條件變化帶來的鏈路和芯片(如CTLE)的變化,增加系統的穩定性。
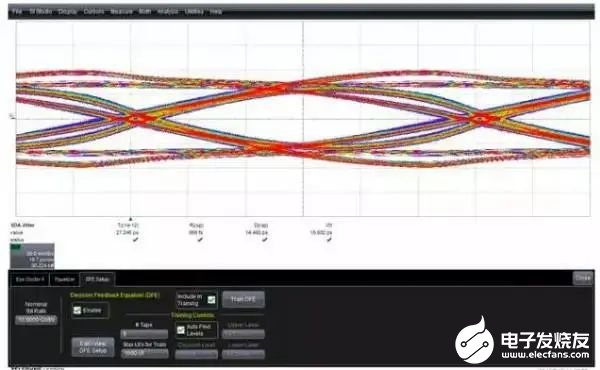
圖15 經過CTLE和DFE均衡后的眼圖
在實際的使用過程中,需要FFE、CTLE和DFE三者相互配合使用,尤其是在鏈路條件相對復雜的情況下。下面是一個比較惡劣的線路,在5GHz處,鏈路的插損達到了約33dB(相當于40inch FR4 背板的損耗)。這個時候單純靠FFE或者CTLE、DFE已經無法實現將眼圖張開,這時候需要使用FFE+CTLE+DFE相互配合,使得在接收端的采樣點處眼圖能夠完全張開,確保達到目標誤碼率。
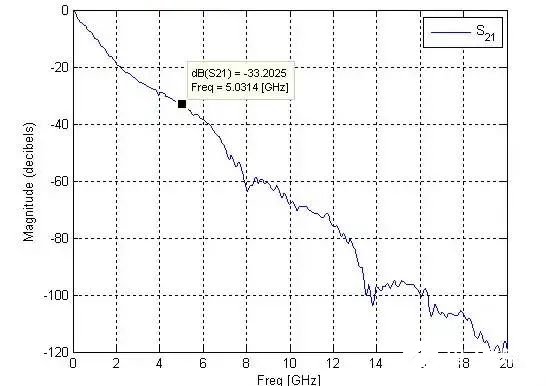
圖16 更惡劣的背板差損
-
信號完整性
+關注
關注
68文章
1405瀏覽量
95458 -
碼間串擾
+關注
關注
0文章
5瀏覽量
2616
發布評論請先 登錄
相關推薦
讀碼專家創新“防抖技術”,輕松克服干擾難題

電磁干擾是怎么產生的
電路中怎樣消除高頻干擾
用CD4052做多路開關,通道間會相互干擾怎么解決?
消除共模干擾用什么器件
固定讀碼器怎么選型 工業二維碼讀碼器推薦

高抗干擾段碼LCD液晶顯示屏驅動控制電路(芯片)-VK2C22A/B
如何消除伺服電機的電磁干擾
軟件功能碼中設置的的濾波原理
sim卡pin碼怎么設置 pin碼和puk碼有什么區別
基于相機技術的工業級多碼讀碼器——DC200讀碼器





 工商網監
工商網監
評論