 多種內存一致性模型的特性分析
多種內存一致性模型的特性分析
早期的CPU是通過提高主頻來提升CPU的性能,但是隨著頻率“紅利”越來越困難的情況下,廠商開始用多核來提高CPU的計算能力。多核是指一個CPU里有多個核心,在同一時間一個CPU能夠同時運行多個線程,通過這樣提高CPU的并發能力。
內存一致性模型(memory consistency model)就是用來描述多線程對共享存儲器的訪問行為,在不同的內存一致性模型里,多線程對共享存儲器的訪問行為有非常大的差別。這些差別會嚴重影響程序的執行邏輯,甚至會造成軟件邏輯問題。在后面的介紹中,我們將分析不同的一致性模型里,多線程的內存訪問亂序問題。
目前有多種內存一致性模型:
順序存儲模型(sequential consistency model)
完全存儲定序(total store order)
部分存儲定序(part store order)
寬松存儲模型(relax memory order)
在后面我們會分析這幾個一致性模型的特性
在分析之前,我們先定義一個基本的內存模型,以這個內存模型為基礎進行分析

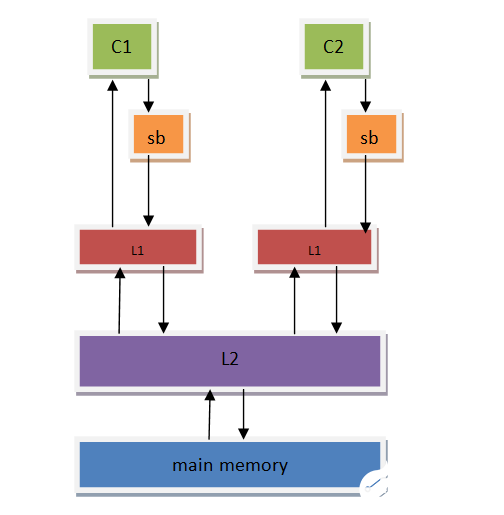
上圖是現代CPU的基本內存模型,CPU內部有多級緩存來提高CPU的load/store訪問速度(因為對于CPU而言,主存的訪問速度太慢了,上百個時鐘周期的內存訪問延遲會極大的降低CPU的使用效率,所以CPU內部往往使用多級緩存來提升內存訪問效率。)
C1與C2是CPU的2個核心,這兩個核心有私有緩存L1,以及共享緩存L2。最后一級存儲器才是主存。后面的順序一致性模型(SC)中,我們會以這個為基礎進行描述(在完全存儲定序、部分存儲定序和寬松內存模型里會有所區別,后面會描述相關的部分)
為了簡化描述的復雜性,在下面的內存一致性模型描述里,會先將緩存一致性(cache coherence)簡單化,認為緩存一致性是完美的(假設多核cache間的數據同步與單核cache一樣,沒有cache引起的數據一致性問題),以減少描述的復雜性。
順序存儲模型是最簡單的存儲模型,也稱為強定序模型。CPU會按照代碼來執行所有的load與store動作,即按照它們在程序的順序流中出現的次序來執行。從主存儲器和CPU的角度來看,load和store是順序地對主存儲器進行訪問。
下面分析這段代碼的執行結果

在順序存儲器模型里,MP(多核)會嚴格嚴格按照代碼指令流來執行代碼
所以上面代碼在主存里的訪問順序是:
S1 S2 L1 L2
通過上面的訪問順序我們可以看出來,雖然C1與C2的指令雖然在不同的CORE上運行,但是C1發出來的訪問指令是順序的,同時C2的指令也是順序的。雖然這兩個線程跑在不同的CPU上,但是在順序存儲模型上,其訪問行為與UP(單核)上是一致的。
我們最終看到r2的數據會是NEW,與期望的執行情況是一致的,所以在順序存儲模型上是不會出現內存訪問亂序的情況
3完全存儲定序
為了提高CPU的性能,芯片設計人員在CPU中包含了一個存儲緩存區(store buffer),它的作用是為store指令提供緩沖,使得CPU不用等待存儲器的響應。所以對于寫而言,只要store buffer里還有空間,寫就只需要1個時鐘周期(哪怕是ARM-A76的L1 cache,訪問一次也需要3個cycles,所以store buffer的存在可以很好的減少寫開銷),但這也引入了一個訪問亂序的問題。
首先我們需要對上面的基礎內存模型做一些修改,表示這種新的內存模型
相比于以前的內存模型而言,store的時候數據會先被放到store buffer里面,然后再被寫到L1 cache里。
首先我們思考單核上的兩條指令:
S1:store flag= set
S2:load r1=data
S3:store b=set
如果在順序存儲模型中,S1肯定會比S2先執行。但是如果在加入了store buffer之后,S1將指令放到了store buffer后會立刻返回,這個時候會立刻執行S2。S2是read指令,CPU必須等到數據讀取到r1后才會繼續執行。這樣很可能S1的store flag=set指令還在store buffer上,而S2的load指令可能已經執行完(特別是data在cache上存在,而flag沒在cache中的時候。這個時候CPU往往會先執行S2,這樣可以減少等待時間)
這里就可以看出再加入了store buffer之后,內存一致性模型就發生了改變。
如果我們定義store buffer必須嚴格按照FIFO的次序將數據發送到主存(所謂的FIFO表示先進入store buffer的指令數據必須先于后面的指令數據寫到存儲器中),這樣S3必須要在S1之后執行,CPU能夠保證store指令的存儲順序,這種內存模型就叫做完全存儲定序(TSO)。
我們繼續看下面的一段代碼

在SC模型里,C1與C2是嚴格按照順序執行的
代碼可能的執行順序如下:
S1 S2 L1 L2
S1 L1 S2 L2
S1 L1 L2 S2
L1 L2 S1 S2
L1 S1 S2 L2
L1 S1 L2 S2
由于SC會嚴格按照順序進行,最終我們看到的結果是至少有一個CORE的r1值為NEW,或者都為NEW。
在TSO模型里,由于store buffer的存在,L1和S1的store指令會被先放到store buffer里面,然后CPU會繼續執行后面的load指令。Store buffer中的數據可能還沒有來得及往存儲器中寫,這個時候我們可能看到C1和C2的r1都為0的情況。
所以,我們可以看到,在store buffer被引入之后,內存一致性模型已經發生了變化(從SC模型變為了TSO模型),會出現store-load亂序的情況,這就造成了代碼執行邏輯與我們預先設想不相同的情況。而且隨著內存一致性模型越寬松(通過允許更多形式的亂序讀寫訪問),這種情況會越劇烈,會給多線程編程帶來很大的挑戰。
4部分存儲定序
芯片設計人員并不滿足TSO帶來的性能提升,于是他們在TSO模型的基礎上繼續放寬內存訪問限制,允許CPU以非FIFO來處理store buffer緩沖區中的指令。CPU只保證地址相關指令在store buffer中才會以FIFO的形式進行處理,而其他的則可以亂序處理,所以這被稱為部分存儲定序(PSO)。
那我們繼續分析下面的代碼

S1與S2是地址無關的store指令,cpu執行的時候都會將其推到store buffer中。如果這個時候flag在C1的cahe中存在,那么CPU會優先將S2的store執行完,然后等data緩存到C1的cache之后,再執行store data=NEW指令。
這個時候可能的執行順序:
S2 L1 L2 S1
這樣在C1將data設置為NEW之前,C2已經執行完,r2最終的結果會為0,而不是我們期望的NEW,這樣PSO帶來的store-store亂序將會對我們的代碼邏輯造成致命影響。
從這里可以看到,store-store亂序的時候就會將我們的多線程代碼完全擊潰。所以在PSO內存模型的架構上編程的時候,要特別注意這些問題。
5寬松內存模型
喪心病狂的芯片研發人員為了榨取更多的性能,在PSO的模型的基礎上,更進一步的放寬了內存一致性模型,不僅允許store-load,store-store亂序。還進一步允許load-load,load-store亂序, 只要是地址無關的指令,在讀寫訪問的時候都可以打亂所有load/store的順序,這就是寬松內存模型(RMO)。
我們再看看上面分析過的代碼

在PSO模型里,由于S2可能會比S1先執行,從而會導致C2的r2寄存器獲取到的data值為0。在RMO模型里,不僅會出現PSO的store-store亂序,C2本身執行指令的時候,由于L1與L2是地址無關的,所以L2可能先比L1執行,這樣即使C1沒有出現store-store亂序,C2本身的load-load亂序也會導致我們看到的r2為0。從上面的分析可以看出,RMO內存模型里亂序出現的可能性會非常大,這是一種亂序隨可見的內存一致性模型。
6內存屏障
芯片設計人員為了盡可能的榨取CPU的性能,引入了亂序的內存一致性模型,這些內存模型在多線程的情況下很可能引起軟件邏輯問題。為了解決在有些一致性模型上可能出現的內存訪問亂序問題,芯片設計人員提供給了內存屏障指令,用來解決這些問題。
內存屏障的最根本的作用就是提供一個機制,要求CPU在這個時候必須以順序存儲一致性模型的方式來處理load與store指令,這樣才不會出現內存訪問不一致的情況。
對于TSO和PSO模型,內存屏障只需要在store-load/store-store時需要(寫內存屏障),最簡單的一種方式就是內存屏障指令必須保證store buffer數據全部被清空的時候才繼續往后面執行,這樣就能保證其與SC模型的執行順序一致。
而對于RMO,在PSO的基礎上又引入了load-load與load-store亂序。RMO的讀內存屏障就要保證前面的load指令必須先于后面的load/store指令先執行,不允許將其訪問提前執行。
我們繼續看下面的例子:

例如C1執行S1與S2的時候,我們在S1與S2之間加上寫屏障指令,要求C1按照順序存儲模型來進行store的執行,而在C2端的L1與L2之間加入讀內存屏障,要求C2也按照順序存儲模型來進行load操作,這樣就能夠實現內存數據的一致性,從而解決亂序的問題。
ARM的很多微架構就是使用RMO模型,所以我們可以看到ARM提供的dmb內存指令有多個選項:
LD load-load/load-store
ST store-store/store-load
SY any-any
這些選項就是用來應對不同情況下的亂序,讓其回歸到順序一致性模型的執行順序上去
-
存儲器
+關注
關注
38文章
7494瀏覽量
163915 -
cpu
+關注
關注
68文章
10872瀏覽量
211997 -
內存
+關注
關注
8文章
3028瀏覽量
74098
發布評論請先 登錄
相關推薦
一致性測試系統的技術原理和也應用場景
異構計算下緩存一致性的重要性
LMK05318的ITU-T G.8262一致性測試結果

電感值和直流電阻的一致性如何提高?
新品發布 | 同星智能正式推出CAN總線一致性測試系統

銅線鍵合焊接一致性:如何突破技術瓶頸?

為什么主機廠愈來愈重視CAN一致性測試?

鋰電池組裝及維修的關鍵:電芯一致性的重要性

QSFP一致性測試的專業測試設備
銅線鍵合焊接一致性:微電子封裝的新挑戰

企業數據備份體系化方法論的七大原則:深入理解數據備份的關鍵原則:應用一致性與崩潰一致性的區別

深入理解數據備份的關鍵原則:應用一致性與崩潰一致性的區別






 工商網監
工商網監
評論