 結合阿里云上的EMR JindoFS優化和實踐,數據湖怎么玩“加速”?
結合阿里云上的EMR JindoFS優化和實踐,數據湖怎么玩“加速”?
湖加速即為數據湖加速,是指在數據湖架構中,為了統一支持各種計算,對數據湖存儲提供適配支持,進行優化和緩存加速的中間層技術。那么為什么需要湖加速?數據湖如何實現“加速”?本文將從三個方面來介紹湖加速背后的原因,分享阿里云在湖加速上的實踐經驗和技術方案。
在開源大數據領域,存儲/計算分離已經成為共識和標準做法,數據湖架構成為大數據平臺的首要選擇。基于這一范式,大數據架構師需要考慮三件事情:
第一,選擇什么樣的存儲系統做數據湖(湖存儲)? 第二,計算和存儲分離后,出現了性能瓶頸,計算如何加速和優化(湖加速)? 第三,針對需要的計算場景,選擇什么樣的計算引擎(湖計算)?
湖存儲可以基于我們熟悉的HDFS,在公共云上也可以選擇對象存儲,例如阿里云OSS。在公共云上,基于對象存儲構建數據湖是目前業界最主流的做法,我們這里重點探討第二個問題,結合阿里云上的EMR JindoFS優化和實踐,看看數據湖怎么玩“加速”。
湖加速
在數據湖架構里,湖存儲(HDFS,阿里云OSS)和湖計算(Spark,Presto)都比較清楚。那么什么是湖加速?大家不妨搜索一下…(基本沒有直接的答案)。湖加速是阿里云EMR同學在內部提出來的,顧名思義,湖加速即為數據湖加速,是指在數據湖架構中,為了統一支持各種計算,對數據湖存儲提供適配支持,進行優化和緩存加速的中間層技術。這里面出現較早的社區方案應該是Alluxio,Hadoop社區有S3A Guard,AWS有EMRFS,都適配和支持AWS S3,Snowflake在計算側有SSD緩存,Databricks有DBIO/DBFS,阿里云有EMR JindoFS,大體都可以歸為此類技術。
那么為什么需要湖加速呢?這和數據湖架構分層,以及相關技術演進具有很大關系。接下來,我們從三個方面的介紹來尋找答案。分別是:基礎版,要適配;標配版,做緩存;高配版,深度定制。JindoFS同時涵蓋這三個層次,實現數據湖加速場景全覆蓋。
基礎版:適配對象存儲
以Hadoop為基礎的大數據和在AWS上以EC2/S3為代表的云計算,在它們發展的早期,更像是在平行的兩個世界。等到EMR產品出現后,怎么讓大數據計算(最初主要是MapReduce)對接S3,才成為一個真實的技術命題。對接S3、OSS對象存儲,大數據首先就要適配對象接口。Hadoop生態的開源大數據引擎,比如Hive和Spark,過去主要是支持HDFS,以Hadoop Compatible File System(HCFS)接口適配、并支持其他存儲系統。機器學習生態(Python)以POSIX接口和本地文件系統為主,像TensorFlow這種深度學習框架當然也支持直接使用HDFS 接口。對象存儲產品提供REST API,在主要開發語言上提供封裝好的SDK,但都是對象存儲語義的,因此上述這些流行的計算框架要用,必須加以適配,轉換成HCFS接口或者支持POSIX。這也是為什么隨著云計算的流行,適配和支持云上對象存儲產品成為Hadoop社區開發的一個熱點,比如S3A FileSytem。阿里云EMR團隊則大力打造JindoFS,全面支持阿里云OSS并提供加速優化。如何高效地適配,并不是設計模式上增加一層接口轉換那么簡單,做好的話需要理解兩種系統(對象存儲和文件系統)背后的重要差異。我們稍微展開一下:
第一,海量規模。
對象存儲提供海量低成本存儲,相比文件系統(比如HDFS),阿里云OSS更被用戶認為可無限擴展。同時隨著各種BI技術和AI技術的流行和普及,挖掘數據的價值變得切實可行,用戶便傾向于往數據湖(阿里云OSS)儲存越來越多不同類型的數據,如圖像、語音、日志等等。這在適配層面帶來的挑戰就是,需要處理比傳統文件系統要大許多的數據量和文件數量。千萬級文件數的超大目錄屢見不鮮,甚至包含大量的小文件,面對這種目錄,一般的適配操作就失靈了,不是OOM就是hang在那兒,根本就不可用。JindoFS一路走來積累了很多經驗,我們對大目錄的listing操作和du/count這種統計操作從內存使用和充分并發進行了深度優化,目前達到的效果是,千萬文件數超大目錄,listing操作比社區版本快1倍,du/count快21%,整體表現更為穩定可靠。
第二,文件和對象的映射關系。
對象存儲提供key到blob對象的映射,這個key的名字空間是扁平的,本身并不具備文件系統那樣的層次性,因此只能在適配層模擬文件/目錄這種層次結構。正是因為要靠模擬,而不是原生支持,一些關鍵的文件/目錄操作代價昂貴,這里面最為知名的就是rename了。文件rename或者mv操作,在文件系統里面只是需要把該文件的inode在目錄樹上挪動下位置即可,一個原子操作;但是在對象存儲上,往往受限于內部的實現方式和提供出來的標準接口,適配器一般需要先copy該對象到新位置,然后再把老對象delete掉,用兩個獨立的步驟和API調用。對目錄進行rename操作則更為復雜,涉及到該目錄下的所有文件的rename,而每一個都是上述的copy+delete;如果目錄層次很深,這個rename操作還需要遞歸嵌套,涉及到數量巨大的客戶端調用次數。對象的copy通常跟它的size相關,在很多產品上還是個慢活,可以說是雪上加霜。阿里云OSS在這方面做了很多優化,提供Fast Copy能力,JindoFS充分利用這些優化支持,結合客戶端并發,在百萬級大目錄rename操作上,性能比社區版本接近快3X。
第三,一致性。
為了追求超大并發,不少對象存儲產品提供的是最終一致性(S3),而不是文件系統常見的強一致性語義。這帶來的影響就是,舉個栗子,程序明明往一個目錄里面剛剛寫好了10個文件,結果隨后去list,可能只是部分文件可見。這個不是性能問題,而是正確性了,因此在適配層為了滿足大數據計算的需求,Hadoop社區在S3A適配上花了很大力氣處理應對這種問題,AWS自己也類似提供了EMRFS,支持ConsistentView。阿里云OSS提供了強一致性,JindoFS基于這一特性大大簡化,用戶和計算框架使用起來也無須擔心類似的一致性和正確性問題。
第四,原子性。
對象存儲自身沒有目錄概念,目錄是通過適配層模擬出來的。對一個目錄的操作就轉化為對該目錄下所有子目錄和文件的客戶端多次調用操作,因此即使是每次對象調用操作是原子的,但對于用戶來說,對這個目錄的操作并不能真正做到原子性。舉個例子,刪除目錄,對其中任何一個子目錄或文件的刪除操作失敗(包含重試),哪怕其他文件刪除都成功了,這個目錄刪除操作整體上還是失敗。這種情況下該怎么辦?通常只能留下一個處于中間失敗狀態的目錄。JindoFS在適配這些目錄操作(rename,copy,delete and etc)的時候,結合阿里云 OSS 的擴展和優化支持,在客戶端盡可能重試或者回滾,能夠很好地銜接數據湖各種計算,在pipeline 上下游之間保證正確處理。
第五,突破限制。
對象存儲產品是獨立演化發展的,少不了會有自己的一些獨門秘籍,這種特性要充分利用起來可能就得突破HCFS抽象接口的限制。這里重點談下對象存儲的高級特性Concurrent MultiPartUpload (CMPU),該特性允許程序按照分片并發上傳part的方式高效寫入一個大對象,使用起來有兩個好處,一個是可以按照并發甚至是分布式的方式寫入一個大對象,實現高吞吐,充分發揮對象存儲的優勢;另外一個是,所有parts都是先寫入到一個staging區域的,直到complete的時候整個對象才在目標位置出現。利用阿里云OSS這個高級特性,JindoFS開發了一個針對MapReduce模型的Job Committer,用于Hadoop,Spark 和類似框架,其實現機制是各個任務先將計算結果按照part寫入到臨時位置,然后作業commit的時候再complete這些結果對象到最終位置,實現無須rename的效果。我們在Flinkfile sink connector支持上也同樣往計算層透出這方面的額外接口,利用這個特性支持了Exactly-Once的語義。
標配版:緩存加速
數據湖架構對大數據計算的另外一個影響是存/算分離。存儲和計算分離,使得存儲和計算在架構上解耦,存儲朝著大容量低成本規模化供應,計算則向著彈性伸縮,豐富性和多樣化向前發展,在整體上有利于專業化分工和大家把技術做深,客戶價值也可以實現最大化。但是這種分離架構帶來一個重要問題就是,存儲帶寬的供應在一些情況下可能會跟計算對存儲帶寬的需求不相適應。計算要跨網絡訪問存儲,數據本地性消失,訪問帶寬整體上會受限于這個網絡;更重要的是,在數據湖理念下,多種計算,越來越多的計算要同時訪問數據,會競爭這個帶寬,最終使得帶寬供需失衡。我們在大量的實踐中發現,同一個OSS bucket,Hive/Spark數倉要進行ETL,Presto要交互式分析,機器學習也要抽取訓練數據,這個在數據湖時代之前不可想象,那個時候也許最多的就是MapReduce作業了。這些多樣化的計算,對數據訪問性能和吞吐的需求卻不遑多讓甚至是變本加厲。常駐的集群希望完成更多的計算;彈性伸縮的集群則希望盡快完成作業,把大量節點給釋放掉節省成本;像Presto這種交互式分析業務方希望是越快越好,穩定亞秒級返回不受任何其他計算影響;而GPU訓練程序則是期望數據完全本地化一樣的極大吞吐。像這種局面該如何破呢?無限地增加存儲側的吞吐是不現實的,因為整體上受限于和計算集群之間的網絡。有效地保證豐富的計算對存儲帶寬的需求,業界早已給出的答案是計算側的緩存。Alluxio一直在做這方面的事情,JindoFS核心定位是數據湖加速層,其思路也同出一轍。下面是它在緩存場景上的架構圖。
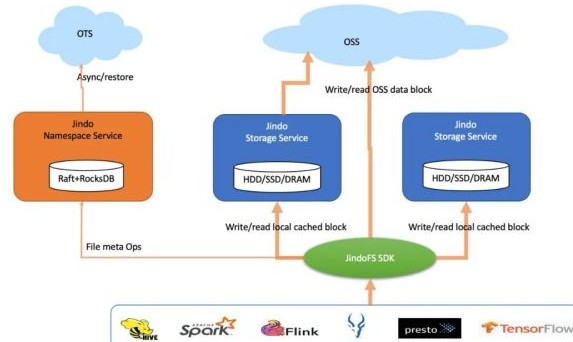
JindoFS在對阿里云OSS適配優化的同時,提供分布式緩存和計算加速,剛剛寫出去的和重復訪問的數據可以緩存在本地設備上,包括HDD,SSD和內存,我們都分別專門優化過。這種緩存加速是對用戶透明的,本身并不需要計算額外的感知和作業修改,在使用上只需要在OSS適配的基礎上打開一個配置開關,開啟數據緩存。疊加我們在適配上的優化,跟業界某開源緩存方案相比,我們在多個計算場景上都具有顯著的性能領先優勢。基于磁盤緩存,受益于我們能夠更好地balance多塊磁盤負載和高效精細化的緩存塊管理,我們用TPC-DS 1TB進行對比測試,SparkSQL性能快27%;Presto大幅領先93%;在HiveETL場景上,性能領先42%。JindoFS 的 FUSE支持完全采用 native 代碼開發而沒有 JVM 的負擔,基于SSD緩存,我們用TensorFlow程序通過JindoFuse來讀取JindoFS上緩存的OSS數據來做訓練,相較該開源方案性能快40%。
在數據湖架構下在計算側部署緩存設備引入緩存,可以實現計算加速的好處,計算效率的提升則意味著更少的彈性計算資源使用和成本支出,但另一方面毋庸諱言也會給用戶帶來額外的緩存成本和負擔。如何衡量這個成本和收益,確定是否引入緩存,需要結合實際的計算場景進行測試評估,不能一概而論。
高配版:深度定制,自己管理文件元數據
我們在JindoFS上優化好OSS適配,把Jindo分布式緩存性能做到效能最大化,能滿足絕大多數大規模分析和機器學習訓練這些計算。現有的JindoFS大量部署和使用表明,無論Hive/Spark/Impala這種數倉作業,Presto交互式分析,還是TensorFlow訓練,我們都可以在計算側通過使用阿里云緩存定制機型,來達到多種計算高效訪問OSS數據湖的吞吐要求。可是故事并沒有完,數據湖的架構決定了計算上的開放性和更加多樣性,上面這些計算可能是最主要的,但并不是全部,JindoFS在設計之初就希望實現一套部署,即能覆蓋各種主要場景。一個典型情況是,有不少用戶希望JindoFS能夠完全替代HDFS,而不只是Hive/Spark夠用就可以了,用戶也不希望在數據湖架構下還要混合使用其他存儲系統。整理一下大概有下面幾種情況需要我們進一步考慮。
第一、上面討論對象存儲適配的時候我們提到,一些文件/目錄操作的原子性需求在本質上是解決不了的,比如文件的rename,目錄的copy,rename和delete。徹底解決這些問題,完全滿足文件系統語義,根本上需要自己實現文件元數據管理,像HDFS NameNode那樣。
第二、HDFS有不少比較高級的特性和接口,比如支持truncate,append,concat,hsync,snapshot和Xattributes。像HBase依賴hsync/snapshot,Flink依賴truncate。數據湖架構的開放性也決定了還會有更多的引擎要對接上來,對這些高級接口有更多需求。
第三、HDFS重度用戶希望能夠平遷上云,或者在存儲方案選擇上進行微調,原有基于HDFS的應用,運維和治理仍然能夠繼續使用。在功能上提供Xattributes支持,文件權限支持,Ranger集成支持,甚至是auditlog支持;在性能上希望不低于HDFS,最好比HDFS還好,還不需要對NameNode調優。為了也能夠享受到數據湖架構帶來的各種好處,該如何幫助這類用戶基于OSS進行架構升級呢?
第四、為了突破S3這類對象存儲產品的局限,大數據業界也在針對數據湖深度定制新的數據存儲格式,比如Delta,Hudi,和Iceberg。如何兼容支持和有力優化這類格式,也需要進一步考慮。
基于這些因素,我們進一步開發和推出JindoFS block模式,在OSS對象存儲的基礎上針對大數據計算進行深度定制,仍然提供標準的HCFS接口,因為我們堅信,即使同樣走深度定制路線,遵循現有標準與使用習慣對用戶和計算引擎來說更加容易推廣和使用,也更加符合湖加速的定位和使命。JindoFS block模式對標HDFS,不同的是采取云原生的架構,依托云平臺我們做了大量簡化,使得整個系統具有彈性,輕量和易于運維的特點和優勢。
如上圖示,是JindoFS在block模式下的系統架構,整體上重用了JindoFS緩存系統。在這種模式下,文件數據是分塊存放在OSS上,保證可靠和可用;同時借助于本地集群上的緩存備份,可以實現緩存加速。文件元數據異步寫入到阿里云OTS數據庫防止本地誤操作,同時方便JindoFS集群重建恢復;元數據在正常讀寫時走本地RocksDB,內存做LRU緩存,因此支撐的文件數在億級;結合元數據服務的文件/目錄級別細粒度鎖實現,JindoFS在大規模高并發作業高峰的時候表現比HDFS更穩定,吞吐也更高。我們用HDFS NNBench做并發測試,對于最關鍵的open和create操作,JindoFS的IOPS比HDFS高60%。在千萬級超大目錄測試上,文件listing操作比HDFS快130%;文件統計du/count操作比HDFS快1X。借助于分布式Raft協議,JindoFS支持HA和多namespaces,整體上部署和維護比HDFS簡化太多。在IO吞吐上,因為除了本地磁盤,還可以同時使用OSS帶寬來讀,因此在同樣的集群配置下用DFSIO實測下來,讀吞吐JindoFS比HDFS快33%。
JindoFS在湖加速整體解決方案上進一步支持block模式,為我們拓寬數據湖使用場景和支持更多的引擎帶來更大的想象空間。目前我們已經支持不少客戶使用HBase,為了受益于這種存/算分離的架構同時借助于本地管理的存儲設備進行緩存加速,我們也在探索將更多的開源引擎對接上來。比如像Kafka,Kudu甚至OLAP新貴ClickHouse,能不能讓這些引擎專注在它們的場景上,將它們從壞盤處理和如何伸縮這類事情上徹底解放出來。原本一些堅持使用HDFS的客戶也被block模式這種輕運維,有彈性,低成本和高性能的優勢吸引,通過這種方式也轉到數據湖架構上來。如同對OSS的適配支持和緩存模式,JindoFS這種新模式仍然提供完全兼容的HCFS和FUSE支持,大量的數據湖引擎在使用上并不需要增加額外的負擔。
總結
行文至此,我們做個回顧和總結。基于數據湖對大數據平臺進行架構升級是業界顯著趨勢,數據湖架構包括湖存儲、湖加速和湖分析,在阿里云上我們通過 JindoFS 針對各種場景提供多種數據湖加速解決方案。阿里云推出的專門支持數據湖管理的Data Lake Formation,可全面支持數據湖。
責任編輯:pj
-
帶寬
+關注
關注
3文章
939瀏覽量
40967 -
阿里云
+關注
關注
3文章
965瀏覽量
43116 -
大數據
+關注
關注
64文章
8896瀏覽量
137517
發布評論請先 登錄
相關推薦
華為云 FlexusX 實例下的 Kafka 集群部署實踐與性能優化
阿里云代理有哪些?
Share Boom第12期:云終端2.0時代-無影隨行,且玩好贏沙龍圓滿落幕
云計算與邊緣計算的結合
阿里云設備的物模型數據里面始終沒有值是為什么?
阿里云關閉澳大利亞和印度數據中心
ESP32S3連接阿里云物聯網平臺LinkSDK報錯怎么解決?
LPS完成戰略性收購 增強數據實踐和營銷云能力

阿里云加速全球布局,五國新建數據中心
阿里云多云成本優化暫停新用戶購買與續訂
阿里云全面降價,釋放了什么信號?






 工商網監
工商網監
評論