 分析四種自動化的機器學習工具包,更好地建立網絡模型
分析四種自動化的機器學習工具包,更好地建立網絡模型
AutoML 是當前深度學習領域的熱門話題。只需要很少的工作,AutoML 就能通過快速有效的方式,為你的 ML 任務構建好網絡模型,并實現高準確率。簡單有效!數據預處理、特征工程、特征提取和特征選擇等任務皆可通過 AutoML 自動構建。
自動機器學習(Automated Machine Learning, AutoML)是一個新興的領域,在這個領域中,建立機器學習模型來建模數據的過程是自動化的。AutoML 使得建模更容易,并且每個人都更容易掌握。
在本文中,作者詳細介紹了四種自動化的 ML 工具包,分別是 auto-sklearn、TPOT、HyperOpt 以及 AutoKeras。如果你對 AutoML 感興趣,這四個 Python 庫是最好的選擇。作者還在文章結尾文章對這四個工具包進行了比較。
auto-sklearn
auto-sklearn 是一個自動機器學習工具包,它與標準 sklearn 接口無縫集成,因此社區中很多人都很熟悉該工具。通過使用最近的一些方法,比如貝葉斯優化,該庫被用來導航模型的可能空間,并學習推理特定配置是否能很好地完成給定任務。
該庫由 Matthias Feurer 等人提出,技術細節請查閱論文《Efficient and Robust Machine Learning》。Feurer 在這篇論文中寫道:
我們提出了一個新的、基于 scikit-learn 的魯棒 AutoML 系統,其中使用 15 個分類器、14 種特征預處理方法和 4 種數據預處理方法,生成了一個具有 110 個超參數的結構化假設空間。
auto-sklearn 可能最適合剛接觸 AutoML 的用戶。除了發現數據集的數據準備和模型選擇之外,該庫還可以從在類似數據集上表現良好的模型中學習。表現最好的模型聚集在一個集合中。

圖源:《Efficient and Robust Automated Machine Learning》
在高效實現方面,auto-sklearn 需要的用戶交互最少。使用 pip install auto-sklearn 即可安裝庫。
該庫可以使用的兩個主要類是 AutoSklearnClassifier 和 AutoSklearnRegressor,它們分別用來做分類和回歸任務。兩者具有相同的用戶指定參數,其中最重要的是時間約束和集合大小。
更多 AutoSklearn 相關文檔請查閱:https://automl.github.io/auto-sklearn/master/。
TPOT
TPOT 是另一種基于 Python 的自動機器學習開發工具,該工具更關注數據準備、建模算法和模型超參數。它通過一種基于進化樹的結,即自動設計和優化機器學習 pipelie 的樹表示工作流優化(Tree-based Pipeline Optimization Tool, TPOT),從而實現特征選擇、預處理和構建的自動化。
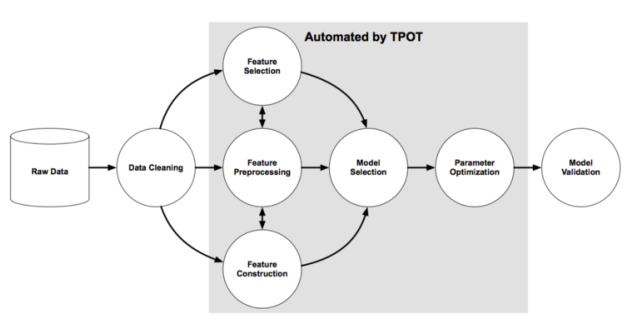
圖源:《Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science》 。
程序或 pipeline 用樹表示。遺傳編程(Genetic Program, GP)選擇并演化某些程序,以最大化每個自動化機器學習管道的最終結果。
正如 Pedro Domingos 所說,「數據量大的愚蠢算法勝過數據有限的聰明算法」。事實就是這樣:TPOT 可以生成復雜的數據預處理 pipeline。
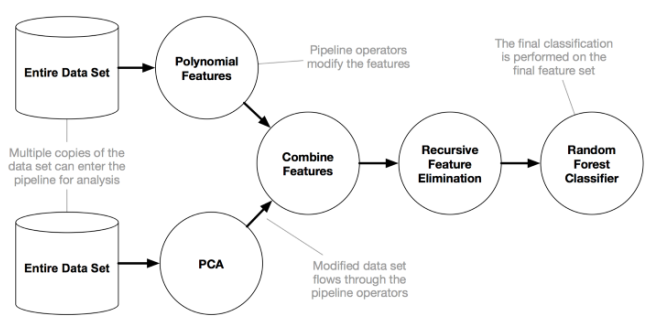
潛在的 pipelie(圖源:TPOT 文檔)。
TPOT pipeline 優化器可能需要幾個小時才能產生很好的結果,就像很多 AutoML 算法一樣(除非數據集很小)。用戶可以在 Kaggle commits 或 Google Colab 中運行這些耗時的程序。
也許 TPOT 最好的特性是它將模型導出為 Python 代碼文件,后續可以使用它。具體文檔和教程示例參見以下兩個鏈接:
TPOT 文檔地址:https://epistasislab.github.io/tpot/。
TPOT 的教程示例地址:https://epistasislab.github.io/tpot/examples/
HyperOpt
HyperOpt 是一個用于貝葉斯優化的 Python 庫,由 James Bergstra 開發。該庫專為大規模優化具有數百個參數的模型而設計,顯式地用于優化機器學習 pipeline,并可選擇在多個核心和機器上擴展優化過程。
但是,HyperOpt 很難直接使用,因為它非常具有技術性,需要仔細指定優化程序和參數。相反,作者建議使用 HyperOpt-sklearn,這是一個融合了 sklearn 庫的 HyperOpt 包裝器。
具體來說,HyperOpt 雖然支持預處理,但非常關注進入特定模型的幾十個超參數。就一次 HyperOpt sklearn 搜索的結果來說,它生成了一個沒有預處理的梯度提升分類器:
如何構建 HyperOpt-sklearn 模型可以查看源文檔。它比 auto-sklearn 復雜得多,也比 TPOT 復雜一點。但是如果超參數很重要的話,它可能是值得的。
文檔地址:http://hyperopt.github.io/hyperopt-sklearn/
AutoKeras
與標準機器學習庫相比,神經網絡和深度學習功能更強大,因此更難實現自動化。AutoKeras 庫有哪些功效呢?具體如下:
通過 AutoKeras,神經框架搜索算法可以找到最佳架構,如單個網絡層中的神經元數量、層數量、要合并的層、以及濾波器大小或 Dropout 中丟失神經元百分比等特定于層的參數。一旦搜索完成,用戶可以將其作為普通的 TF/Keras 模型使用;
通過 AutoKeras,用戶可以構建一個包含嵌入和空間縮減等復雜元素的模型,這些元素對于學習深度學習過程中的人來說是不太容易訪問的;
當使用 AutoKeras 創建模型時,向量化或清除文本數據等許多預處理操作都能完成并進行優化;
初始化和訓練一次搜索需要兩行代碼。AutoKeras 擁有一個類似于 keras 的界面,所以它并不難記憶和使用。
AutoKeras 支持文本、圖像和結構化數據,為初學者和尋求更多參與技術知識的人提供界面。AutoKeras 使用進化神經網絡架構搜索方法來減輕研究人員的繁重和模棱兩可的工作。
盡管 AutoKeras 的運行需要很長時間,但用戶可以指定參數來控制運行時間、探索模型的數量以及搜索空間大小等。
AutoKeras 的相關內容參閱以下兩個鏈接:
文檔地址:https://autokeras.com/
教程地址:https://towardsdatascience.com/automl-creating-top-performing-neural-networks-without-defining-architecture-c7d3b08cddc
四個庫各有特色,應該選哪個?
用戶可以根據自己的需求選擇合適的 Python 庫,作者給出了以下幾個建議:
如果你的首要任務是獲取一個干凈、簡單的界面和相對快速的結果,選擇 auto-sklearn。另外:該庫與 sklearn 自然集成,可以使用常用的模型和方法,能很好地控制時間;
如果你的首要任務是實現高準確率,并且不需要考慮長時間的訓練,則使用 TPOT。額外收獲:為最佳模型輸出 Python 代碼;
如果你的首要任務是實現高準確率,依然不需要考慮長時間的訓練,也可選擇使用 HyperOpt-sklearn。該庫強調模型的超參數優化,是否富有成效取決于數據集和算法;
如果你需要神經網絡(警告:不要高估它們的能力),就使用 AutoKeras,尤其是以文本或圖像形式出現時。訓練確實需要很長時間,但有很多措施可以控制時間和搜索空間大小。
責編AJX
-
自動化
+關注
關注
29文章
5592瀏覽量
79387 -
模型
+關注
關注
1文章
3255瀏覽量
48905 -
機器學習
+關注
關注
66文章
8423瀏覽量
132752
發布評論請先 登錄
相關推薦
語言模型自動化的優點
AI大模型與深度學習的關系
labview字符串的四種表示各有什么特點
matlab神經網絡工具箱結果分析
如何使用PyTorch建立網絡模型
機械自動化是自動化的一種嗎
藍牙模塊在工業自動化中的應用
機器視覺技術在工業自動化中的應用
機器視覺檢測技術在工業自動化中的應用
一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
QE for Motor V1.3.0:汽車開發輔助工具解決方案工具包

晶泰科技攜手ABB機器人打造柔性智能自動化的實驗室
利用ProfiShark 構建便攜式網絡取證工具包






 工商網監
工商網監
評論