") 在語(yǔ)音處理中,通過(guò)使用大數(shù)據(jù)可以輕松解決很多任務(wù)
在語(yǔ)音處理中,通過(guò)使用大數(shù)據(jù)可以輕松解決很多任務(wù)
在語(yǔ)音處理中,通過(guò)使用大量數(shù)據(jù)可以輕松解決很多任務(wù)。例如,將語(yǔ)音轉(zhuǎn)換為文本的 自動(dòng)語(yǔ)音識(shí)別 (Automatic Speech Recognition,ASR)。相比之下,“非語(yǔ)義”任務(wù)側(cè)重于語(yǔ)音中含義以外的其他方面,如“副語(yǔ)言(Paralinguistic)”任務(wù)中包含了語(yǔ)音情感識(shí)別等其他類型的任務(wù),例如發(fā)言者識(shí)別、語(yǔ)言識(shí)別和某些基于語(yǔ)音的醫(yī)療診斷。完成這些任務(wù)的訓(xùn)練系統(tǒng)通常利用盡可能大的數(shù)據(jù)集來(lái)確保良好結(jié)果。然而,直接依賴海量數(shù)據(jù)集的機(jī)器學(xué)習(xí)技術(shù)在小數(shù)據(jù)集上進(jìn)行訓(xùn)練時(shí)往往不太成功。
為了縮小大數(shù)據(jù)集和小數(shù)據(jù)集之間的性能差距,可以在大數(shù)據(jù)集上訓(xùn)練 表征模型 (Representation Model),然后將其轉(zhuǎn)移到小數(shù)據(jù)集的環(huán)境中。表征模型能夠通過(guò)兩種方式提高性能:將高維數(shù)據(jù)(如圖像和音頻)轉(zhuǎn)換到較低維度進(jìn)而訓(xùn)練小模型,而且表征模型還可以用作預(yù)訓(xùn)練。此外,如果表征模型小到可以在設(shè)備端運(yùn)行或訓(xùn)練,就能讓原始數(shù)據(jù)始終保留在設(shè)備中,在為用戶提供個(gè)性化模型好處的同時(shí),以保護(hù)隱私的方式提高性能。雖然表征學(xué)習(xí)已普遍用于文本領(lǐng)域(如 BERT和 ALBERT)和圖像領(lǐng)域(如 Inception 層 和 SimCLR),但這種方法在語(yǔ)音領(lǐng)域尚未得到充分利用。
下:使用大型語(yǔ)音數(shù)據(jù)集訓(xùn)練模型,然后將其推廣到其他環(huán)境;左上:設(shè)備端個(gè)性化 - 個(gè)性化的設(shè)備端模型將安全和隱私相結(jié)合;中上:嵌入向量的小模型 - 通用表征將高維度、少示例的數(shù)據(jù)集轉(zhuǎn)換到低維度,同時(shí)不降低準(zhǔn)確率;較小的模型訓(xùn)練速度更快,并且經(jīng)過(guò)正則化。右上:全模型微調(diào) - 大數(shù)據(jù)集可以使用嵌入向量模型作為預(yù)訓(xùn)練以提高性能
如果沒(méi)有一個(gè)衡量“語(yǔ)音表征有用性”的標(biāo)準(zhǔn)基準(zhǔn),就很難顯著地改進(jìn)通用表征,尤其是對(duì)于非語(yǔ)義語(yǔ)音任務(wù)。盡管 T5框架系統(tǒng)地評(píng)估了文本嵌入向量,并且視覺(jué)領(lǐng)域任務(wù)自適應(yīng)基準(zhǔn) (VTAB) 對(duì)圖像嵌入向量評(píng)估進(jìn)行了標(biāo)準(zhǔn)化,兩者均促進(jìn)了相應(yīng)領(lǐng)域表征學(xué)習(xí)的進(jìn)展,但對(duì)于非語(yǔ)義語(yǔ)音嵌入向量卻沒(méi)有類似基準(zhǔn)。
在“Towards Learning a Universal Non-Semantic Representation of Speech”中,我們對(duì)語(yǔ)音相關(guān)應(yīng)用的表征學(xué)習(xí)做出了三項(xiàng)努力:
提出一個(gè)比較語(yǔ)音表征的非語(yǔ)義語(yǔ)音 (NOn-Semantic Speech,NOSS) 基準(zhǔn),其中包括多樣化的數(shù)據(jù)集和基準(zhǔn)任務(wù),例如語(yǔ)音情感識(shí)別、語(yǔ)言識(shí)別和發(fā)言者識(shí)別。這些數(shù)據(jù)集可在TensorFlow Datasets 的“音頻”部分中找到。
創(chuàng)建并開(kāi)源了 TRIpLet Loss 網(wǎng)絡(luò) (TRILL),此全新模型小到可以在設(shè)備端執(zhí)行和微調(diào),同時(shí)仍然優(yōu)于其他表征模型。
進(jìn)行了大規(guī)模研究來(lái)比較不同的表征,并開(kāi)源了用于計(jì)算新表征性能的代碼。
Towards Learning a Universal Non-Semantic Representation of Speech
https://arxiv.org/abs/2002.12764
這些數(shù)據(jù)集
https://tensorflow.google.cn/datasets/catalog/overview#audio
TensorFlow Datasets
https://tensorflow.google.cn/datasets/
TRIpLet Loss 網(wǎng)絡(luò)
https://aihub.cloud.google.com/s?q=nonsemantic-speech-benchmark
開(kāi)源
https://github.com/google-research/google-research/tree/master/non_semantic_speech_benchmark
語(yǔ)音嵌入向量的新基準(zhǔn)
為了能夠有效指導(dǎo)模型開(kāi)發(fā),基準(zhǔn)必須包含具有類似解決方案的任務(wù),并排除存在顯著差異的任務(wù)。既往工作或?yàn)楠?dú)立處理各種潛在語(yǔ)音任務(wù),或?yàn)閷⒄Z(yǔ)義任務(wù)和非語(yǔ)義任務(wù)歸納在一起。我們的工作在一定程度上通過(guò)關(guān)注在語(yǔ)音任務(wù)子集上表現(xiàn)良好的神經(jīng)網(wǎng)絡(luò)架構(gòu),提高了非語(yǔ)義語(yǔ)音任務(wù)的性能。
NOSS 基準(zhǔn)的任務(wù)選擇依據(jù):
多樣性 - 需要覆蓋一系列使用案例;
復(fù)雜性 - 應(yīng)該具有挑戰(zhàn)性;
可用性,特別強(qiáng)調(diào)開(kāi)源任務(wù)。
我們結(jié)合了具有不同規(guī)模和任務(wù)的六個(gè)數(shù)據(jù)集。
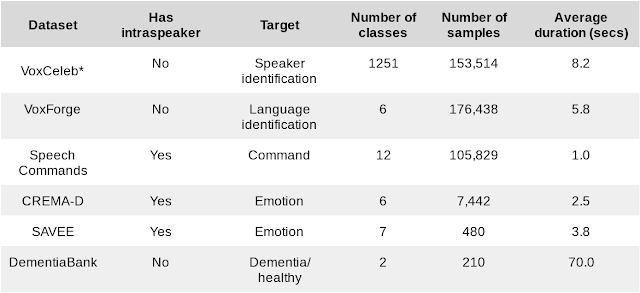
下游基準(zhǔn)任務(wù)的數(shù)據(jù)集
*我們的研究使用根據(jù)內(nèi)部政策篩選的數(shù)據(jù)集子集計(jì)算 VoxCeleb 結(jié)果
我們還引入了三個(gè)額外的演講者內(nèi)部任務(wù),并測(cè)試個(gè)性化場(chǎng)景下的性能。在具有 k 個(gè)演講者的某些數(shù)據(jù)集中,我們可以創(chuàng)建 k 個(gè)不同的任務(wù),只針對(duì)單一演講者進(jìn)行訓(xùn)練和測(cè)試。整體性能是各演講者的平均值。三個(gè)額外的演講者內(nèi)部任務(wù)衡量了嵌入向量適應(yīng)特定演講者的能力,這是個(gè)性化設(shè)備端模型的必要能力。隨著 ML 向智能手機(jī)和物聯(lián)網(wǎng)延伸,這些模型變得越來(lái)越重要。
為了幫助研究人員比較語(yǔ)音嵌入向量,我們已經(jīng)將基準(zhǔn)中的六個(gè)數(shù)據(jù)集添加到 TensorFlow Datasets 中(在“音頻”部分),并開(kāi)源了評(píng)估框架。
將基準(zhǔn)中的六個(gè)數(shù)據(jù)集添加到 TensorFlow Datasets 中
https://tensorflow.google.cn/datasets/catalog/overview#audio
開(kāi)源了評(píng)估框架
https://github.com/google-research/google-research/tree/master/non_semantic_speech_benchmark
TRILL:非語(yǔ)義語(yǔ)音分類的新技術(shù)
在語(yǔ)音領(lǐng)域中,從一個(gè)數(shù)據(jù)集學(xué)習(xí)嵌入向量并將其應(yīng)用到其他任務(wù)不如其他模式中那樣普遍。然而,使用一項(xiàng)任務(wù)的數(shù)據(jù)幫助另一項(xiàng)任務(wù)(不一定是嵌入向量)的遷移學(xué)習(xí),作為一種更為通用的技術(shù),具有一些引人注目的應(yīng)用,例如個(gè)性化語(yǔ)音識(shí)別器和少量樣本的語(yǔ)音模仿:文本到語(yǔ)音的轉(zhuǎn)換。過(guò)去已經(jīng)有多種語(yǔ)音表征,但其中大多是在較小規(guī)模和較低多樣性的數(shù)據(jù)上進(jìn)行訓(xùn)練,或主要在語(yǔ)音識(shí)別上進(jìn)行測(cè)試,或兩者皆有。
我們基于約 2500 小時(shí)語(yǔ)音的大型多樣化數(shù)據(jù)集 AudioSet 為起點(diǎn),創(chuàng)建跨環(huán)境和任務(wù)的實(shí)用數(shù)據(jù)衍生語(yǔ)音表征。我們通過(guò)先前的度量學(xué)習(xí)工作得出簡(jiǎn)單的自監(jiān)督標(biāo)準(zhǔn),在此標(biāo)準(zhǔn)上訓(xùn)練嵌入向量模型 - 來(lái)自相同音頻的嵌入向量在嵌入向量空間中應(yīng)該比來(lái)自不同音頻的嵌入向量更為接近。與 BERT 和其他文本嵌入向量類似,自監(jiān)督損失函數(shù)不需要標(biāo)簽,只依賴于數(shù)據(jù)本身的結(jié)構(gòu)。這種自監(jiān)督形式最適合非語(yǔ)義語(yǔ)音,因?yàn)榉钦Z(yǔ)義現(xiàn)象在時(shí)間上比 ASR 和其他亞秒級(jí)語(yǔ)音特征更穩(wěn)定。這種簡(jiǎn)單的自監(jiān)督標(biāo)準(zhǔn)捕獲了下游任務(wù)所用的大量聲學(xué)特性。
AudioSet
https://research.google.com/audioset/
TRILL 損失:來(lái)自相同音頻的嵌入向量在嵌入空間中比來(lái)自不同音頻的嵌入向量更為接近
TRILL 架構(gòu)基于 MobileNet,其速度適合在移動(dòng)設(shè)備上運(yùn)行。為了在這種小架構(gòu)上實(shí)現(xiàn)高準(zhǔn)確率,我們?cè)诓唤档托阅艿耐瑫r(shí)從更大的 ResNet50 模型中提取出嵌入向量。
基準(zhǔn)結(jié)果
我們首先比較了 TRILL 與其他深度學(xué)習(xí)表征的性能。這些表征并不局限于語(yǔ)音識(shí)別,并在類似的不同數(shù)據(jù)集上進(jìn)行訓(xùn)練。此外,我們還將 TRILL 與熱門的 OpenSMILE 特征提取器進(jìn)行比較。OpenSMILE 使用預(yù)深度學(xué)習(xí)技術(shù)(如:傅里葉變換系數(shù)、使用基音測(cè)量的時(shí)間序列的“基音跟蹤”等)以及隨機(jī)初始化網(wǎng)絡(luò),這些技術(shù)已被證明是強(qiáng)大的基線。
為了對(duì)不同性能特征的任務(wù)進(jìn)行性能匯總,我們首先針對(duì)給定的任務(wù)和嵌入向量訓(xùn)練少量的簡(jiǎn)單模型,選擇最佳結(jié)果。然后,為了了解特定嵌入向量對(duì)所有任務(wù)的影響,我們以模型和任務(wù)為解釋變量,對(duì)觀察到的精度進(jìn)行了線性回歸計(jì)算。模型對(duì)準(zhǔn)確率的影響即為回歸模型中的相關(guān)系數(shù)。對(duì)于給定任務(wù),從一種模型切換到另一種模型時(shí),產(chǎn)生的準(zhǔn)確率變化的差異預(yù)計(jì)為下圖中 y 值。
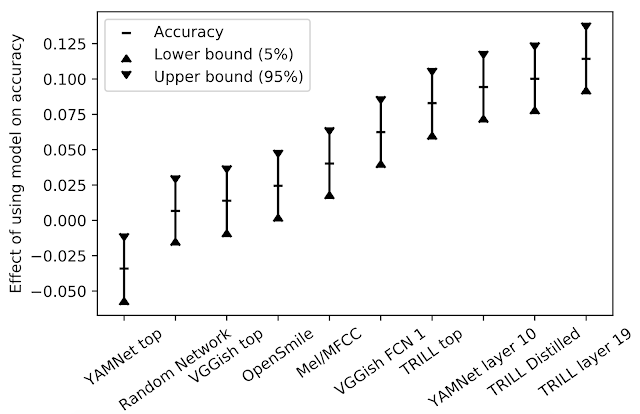
對(duì)模型準(zhǔn)確率的影響
在我們的研究中,TRILL 性能優(yōu)于其他表征。TRILL 的成功在于訓(xùn)練數(shù)據(jù)集的多樣性、網(wǎng)絡(luò)的上下文大窗口以及 TRILL 訓(xùn)練損失的通用性,最后一項(xiàng)因素保留了大量聲學(xué)特征,而不是過(guò)早地關(guān)注特定方面。需要注意的是,來(lái)自網(wǎng)絡(luò)層的中間表征往往更具有通用性。中間表征更大,時(shí)間粒度更細(xì),在分類網(wǎng)絡(luò)的情況下,它們保留了更通用的信息,而不像訓(xùn)練它們的類那樣具體。
通用模型的另一個(gè)優(yōu)勢(shì)是可以在新任務(wù)上初始化模型。當(dāng)新任務(wù)的樣本量較小時(shí),相較于從頭訓(xùn)練模型,對(duì)現(xiàn)有模型進(jìn)行微調(diào)可能會(huì)獲得更好的結(jié)果。盡管沒(méi)有針對(duì)特定數(shù)據(jù)集進(jìn)行超參數(shù)調(diào)整,但使用此技術(shù),我們?nèi)匀辉诹鶄€(gè)基準(zhǔn)任務(wù)的三個(gè)任務(wù)上取得了新的 SOTA 結(jié)果。
為了更新的表征,我們還在Interspeech 2020 Computational Paralinguistics Challenge (ComParE) 的口罩賽道中進(jìn)行了測(cè)試。在挑戰(zhàn)中,模型必須預(yù)測(cè)發(fā)言者是否佩戴口罩,因?yàn)榭谡謺?huì)影響語(yǔ)音。口罩的影響有時(shí)微乎其微,并且音頻片段只有一秒。TRILL 線性模型表現(xiàn)比基線模型更好的性能,該模型融合了許多不同模型的特征,如傳統(tǒng)的光譜和深度學(xué)習(xí)特征。
Interspeech 2020 Computational Paralinguistics Challenge (ComParE)
http://www.compare.openaudio.eu/compare2020/
基線模型
http://compare.openaudio.eu/wp-content/uploads/2020/05/INTERSPEECH_2020_ComParE.pdf
總結(jié)
評(píng)估 NOSS 的代碼位于 GitHub,數(shù)據(jù)集位于 TensorFlow Datasets,TRILL 模型位于 AI Hub。
GitHub
https://github.com/google-research/google-research/tree/master/non_semantic_speech_benchmark
TensorFlow Datasets
https://tensorflow.google.cn/datasets/catalog/overview#audio
AI Hub
https://aihub.cloud.google.com/s?q=nonsemantic-speech-benchmark
非語(yǔ)義語(yǔ)音基準(zhǔn)可幫助研究人員創(chuàng)建語(yǔ)音嵌入向量,適用于包括個(gè)性化和小數(shù)據(jù)集問(wèn)題的各種環(huán)境。我們將 TRILL 模型提供給研究界,作為等待超越的基線嵌入向量。
致謝
這項(xiàng)工作的核心團(tuán)隊(duì)包括 Joel Shor、Aren Jansen、Ronnie Maor、Oran Lang、Omry Tuval、Felix de Chaumont Quitry、Marco Tagliasacchi、Ira Shavitt、Dotan Emanuel 和 Yinnon Haviv。我們還要感謝 Avinatan Hassidim 和 Yossi Matias 的技術(shù)指導(dǎo)。
原文標(biāo)題:通過(guò)自監(jiān)督學(xué)習(xí)對(duì)語(yǔ)音表征與個(gè)性化模型進(jìn)行改善
文章出處:【微信公眾號(hào):TensorFlow】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8884瀏覽量
137408 -
語(yǔ)言識(shí)別
+關(guān)注
關(guān)注
0文章
15瀏覽量
4824
原文標(biāo)題:通過(guò)自監(jiān)督學(xué)習(xí)對(duì)語(yǔ)音表征與個(gè)性化模型進(jìn)行改善
文章出處:【微信號(hào):tensorflowers,微信公眾號(hào):Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論