 KDD2020知識圖譜相關論文分享
KDD2020知識圖譜相關論文分享
論文專欄:KDD2020知識圖譜相關論文分享
論文解讀者:北郵 GAMMA Lab 博士生 閆博
題目:魯棒的跨語言知識圖譜實體對齊
會議:KDD 2020
論文地址:https://dl.acm.org/doi/pdf/10.1145/3394486.3403268
代碼地址:https://github.com/scpei/REA
推薦理由:這篇論文首次提出了跨語言實體對齊中的噪音問題,并提出了一種基于迭代訓練的除噪算法,從而進行魯棒的跨語言知識圖譜實體對齊。本工作對后續跨語言實體對齊的去噪研究具有重要的開創性意義。
跨語言實體對齊旨在將不同知識圖譜中語義相似的實體進行關聯,它是知識融合和知識圖譜連接必不可少的研究問題,現有方法只在有干凈標簽數據的前提下,采用有監督或半監督的機器學習方法進行了研究。但是,來自人類注釋的標簽通常包含錯誤,這可能在很大程度上影響對齊的效果。因此,本文旨在探索魯棒的實體對齊問題,提出的REA模型由兩個部分組成:噪聲檢測和基于噪聲感知的實體對齊。噪聲檢測是根據對抗訓練原理設計的,基于噪聲感知的實體對齊利用圖神經網絡對知識圖譜進行建模。兩個部分迭代進行訓練,從而讓模型去利用干凈的實體對來進行節點的表示學習。在現實世界的幾個數據集上的實驗結果證明了提出的方法的有效性,并且在涉及噪聲的情況下,此模型始終優于最新方法,并且在準確度方面有顯著提高。
1 引言
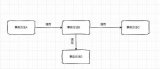
現有方法在進行跨語言實體對齊時沒有考慮噪音問題,而這些噪音可能會損害模型的效果。如圖1所示,(a)中的兩個不同語言的知識圖譜存在實體對噪音(虛線表示的實體對1-4),(b)是理想狀況下節點在特征空間中的表示,可以看出不同語言知識圖譜中具有相似語義的實體在特征空間中也相近。(c)是利用含有噪音的訓練數據得到的節點特征表示,由于噪音的存在,節點的表示存在了一定的偏差。我們希望跨語言實體對齊是魯棒性的,即使訓練數據中存在噪音,模型也能盡量減少噪音的消極影響,得到如圖(b)中的表示。為了克服現有的跨語言實體對齊方法在處理帶噪標簽實體對時存在的局限性,本文探討了如何將噪聲檢測與實體對齊模型結合起來,以及如何共同訓練它們以對齊不同語言知識圖譜中的實體。
圖1噪音對跨語言實體對齊模型效果的影響示意圖
問題定義
噪音檢測和魯棒性圖表示學習:在一個存在噪音的場景下,代表所有的用于訓練的實體對(可能包含噪音),代表中確定的干凈的實體對,代表不確定是否含有噪音的實體對。魯棒性的跨語言實體對齊模型利用給定的和,去對齊知識圖譜中的剩余實體,并且能自動發現中的噪音實體對。
這個問題是不平凡的,主要存在兩方面的挑戰:(1)沒有明顯的噪音知識加以利用,即我們不知道訓練數據中哪些是噪音數據,所以傳統的監督學習方法無法使用,提出的模型需要以一種無監督的方式自動檢測出訓練數據中的噪音實體對。(2)提出一個統一的模型。此模型要既能檢測出訓練數據中的噪音,還能進行有效的跨語言實體對齊。
2 方法
魯棒性的跨語言實體對齊模型(REA)包括兩個部分。一是基于噪音感知的實體對齊模型,這一部分主要是利用圖神經網絡來對不同語言的兩個知識圖譜進行統一建模,學習節點的表示,訓練時只使用。二是噪音檢測模塊,作者采用了基于對抗訓練的方式,利用生成對抗網絡(GAN)來檢測噪音。噪音實體對生成器接受干凈實體對輸入,然后進行采樣生成噪音實體對;噪音判別器以干凈實體對和噪音實體對為輸入,訓練一個能判別噪音的模型,同時對輸入的實體對產生一個信任分數,將信任分數大于閾值的實體對加入,用于實體對齊模塊節點的表示學習。上述兩個模塊迭代進行訓練,直到收斂。下面詳細介紹這兩個模塊。
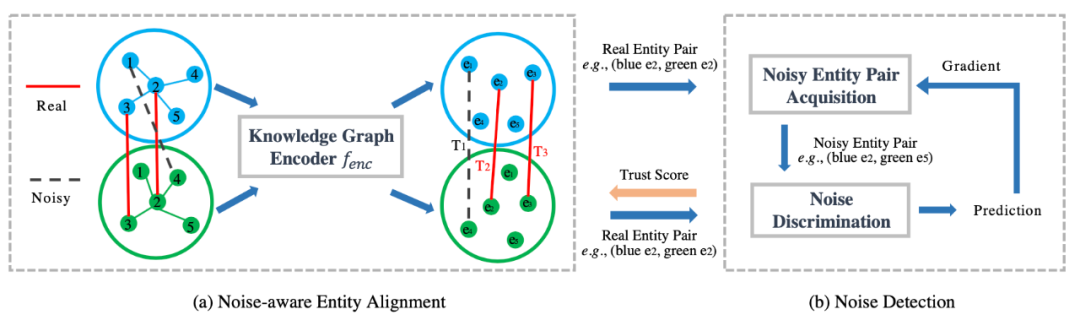
圖2REA模型示意圖
2.1 基于噪音感知的實體對齊模型
這一部分主要是對知識圖譜節點的表示學習。對于知識圖譜中任意的三元組,定義從傳到的信息為:
具體為:
其中和是節點一階鄰居的個數。最終經過圖的信息傳播后節點的表示為:
損失函數采用基于間隔的排序損失(margin-based ranking objective):
這里代表信任分數,又噪音檢測模塊輸出,即當實體對的信任分數超過閾值時,此實體對才被認為是正確的,才會被加入訓練集。代表margin loss,是一個超參數。是一個衡量實體對相似性的函數,由能量函數定義:
負樣本對由隨機替換頭或尾實體得到。
2.2 噪音檢測模塊
噪音檢測模塊分為噪音對生成器和噪音對判別器,由生成對抗網絡實現。與傳統的生成對抗網絡不同的一點是,噪音對生成器不是由模型訓練產生噪音對,而是由采樣生成。噪音對生成器利用實體對齊模塊生成的真實實體對表示作為輸入,然后通過替換掉頭或尾實體采樣得到噪音實體對。噪音實體對的采樣概率如下式所示:
其中是一個簡單的兩層神經網絡,衡量了兩個實體的語義相似性,兩個實體越相似,越不容易被采樣到,這是自然的,因為生成器本來就是用來生成噪音的。為了減少采樣空間過大帶來的計算量代價,采樣只在負樣本空間的一個子空間進行:
此外,由于采樣過程是無法利用傳統的基于梯度下降方法求參數,所以本文采用了基于強化學習的參數求解算法,具體來說:
對所有負樣本的梯度求解近似為對k個采樣的負樣本的梯度求解,可以看作當前的狀態,可以看作策略,看作是動作,代表獎勵。
噪音判別器以實體對作為輸入,輸出實體對為真實實體對的概率:
越大,實體對越有可能為真實實體對,定義實體對的信任得分為:
信任得分為1的實體對將返回給實體對齊模型,繼續訓練。
2.3 算法流程
REA模型采用的是一個迭代的算法,在每次迭代中,算法依次進行三部分的參數訓練。首先是利用干凈的實體對進行節點的表示學習(4-7);然后對噪音實體對判別器進行訓練(8-12);最后對噪音實體對生成器進行訓練(13-17)。一次迭代完成后,更新中實體對的信任得分,將信任得分等于1的實體對加入。具體算法如下所示。

3 實驗
作者在兩個數據集DBP15K和DWY100K包含的5個跨語言知識圖譜上進行了實驗。采用Hits@1,Hits@5,MRR做為評價指標。實驗結果如下圖所示,其中REA-KE是去掉噪音檢測模塊得到的結果。
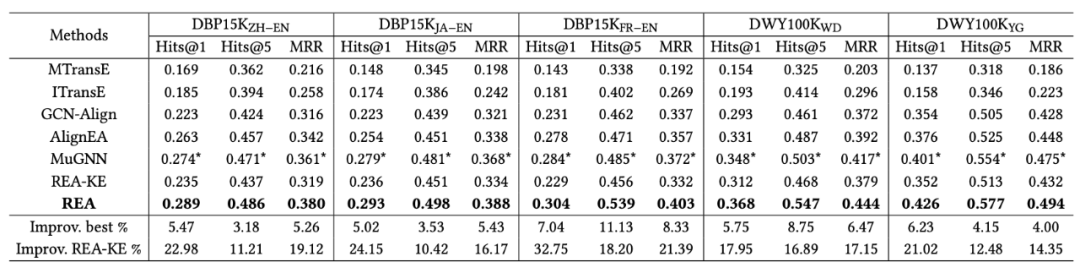
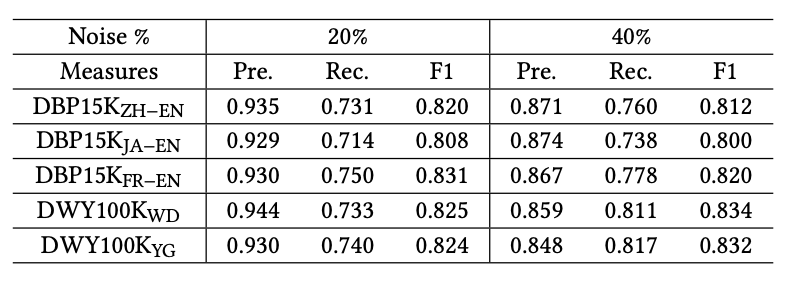
本模型中,噪音實體對判別器的檢測能力至關重要,所以作者也測試了噪音判別器對噪音數據的檢測能力。如下所示,噪音數據的比例為20%和40%時,判別器都有一個較好的檢測噪音的效果。但是由于知識圖譜的不完整性,仍有大量真實實體對被檢測為噪音。
當干凈的實體對數據()增加的時候,模型效果也會變好;而當噪音數據增加的時候,模型效果就會降低。而REA在有噪音的情況下表現是最好的。這也說明了噪音對跨語言實體對齊有很大的影響,REA能有效地處理噪音問題。如圖3和圖4所示。
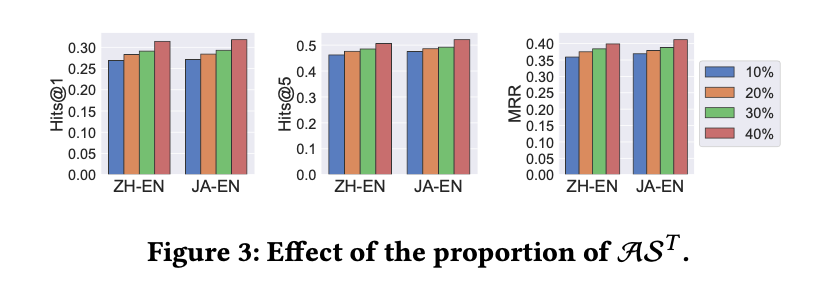
圖3干凈實體對的數量對實驗結果的影響
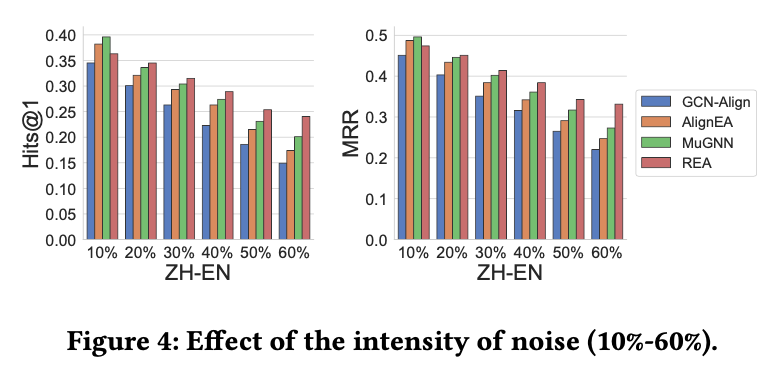
圖4噪音實體對的數量對實驗結果的影響
最后,作者還測試了不同類型的噪音對實驗結果的影響。噪音的不同類型由它們采樣時離真實實體的距離所定。圖5分別測試了噪音實體離真實實體距離為10,50,100和全局的情形下模型的效果。
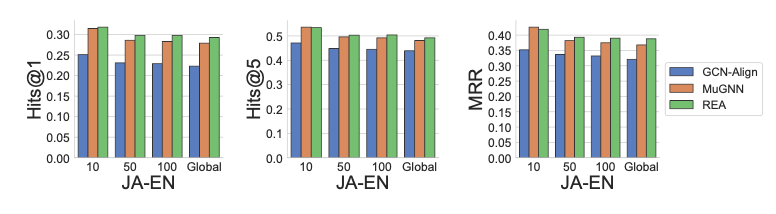
圖5噪音類型對實驗結果的影響
從圖5可以看出,噪音離真實實體越遠,即與真實實體的語義差別越大時,模型效果降低越多。當距離大于50后,模型效果幾乎不再變化,這也說明了離真實實體大于一定距離時,噪音對模型的負面效果趨于穩定。而當噪音實體離真實數據越近,模型效果越好,這是顯而易見的,因為這樣越接近干凈的標注數據。在所有的4種情況下,REA均取得了最好的效果。
4 總結
在標注跨語言實體對齊語料過程中不可避免地會引入噪音。現有方法沒有考慮噪音問題,損害了實體對齊的效果。針對這一問題,本文提出了魯棒性的跨語言實體對齊模型REA。REA通過一種迭代訓練的方式,在每一輪訓練過程中,通過圖神經網絡建模知識圖譜中的實體對,得到噪聲感知的實體對齊模塊,然乎利用生成對抗網絡來生成噪音實體對并訓練一個噪音判別器,噪音判別器識別出干凈的實體對加入訓練集繼續訓練。大量的實驗證明了REA在魯棒性跨語言實體對齊任務上的有效性。
責任編輯:xj
原文標題:【KDD20】魯棒的跨語言知識圖譜實體對齊
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
自然語言
+關注
關注
1文章
287瀏覽量
13347 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7703
原文標題:【KDD20】魯棒的跨語言知識圖譜實體對齊
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
傳音旗下人工智能項目榮獲2024年“上海產學研合作優秀項目獎”一等獎

傳音旗下小語種AI技術榮獲2024年“上海產學研合作優秀項目獎”一等獎

接口測試理論、疑問收錄與擴展相關知識點
58大新質生產力產業鏈圖譜

三星自主研發知識圖譜技術,強化Galaxy AI用戶體驗與數據安全
三星電子成功收購英國初創公司,致力開發AI核心技術
三星電子將收購英國知識圖譜技術初創企業
知識圖譜與大模型之間的關系
Al大模型機器人
利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(下)

利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(上)

知識圖譜基礎知識應用和學術前沿趨勢





 工商網監
工商網監
評論