

前言
AI芯片(這里只談FPGA芯片用于神經(jīng)網(wǎng)絡(luò)加速)的優(yōu)化主要有三個(gè)方面:算法優(yōu)化,編譯器優(yōu)化以及硬件優(yōu)化。算法優(yōu)化減少的是神經(jīng)網(wǎng)絡(luò)的算力,它確定了神經(jīng)網(wǎng)絡(luò)部署實(shí)現(xiàn)效率的上限。編譯器優(yōu)化和硬件優(yōu)化在確定了算力的基礎(chǔ)上,盡量最大化硬件的計(jì)算和帶寬性能。經(jīng)歷了一年多的理論學(xué)習(xí),開(kāi)始第一次神經(jīng)網(wǎng)絡(luò)算法優(yōu)化的嘗試。之所以從一個(gè)FPGA開(kāi)發(fā)者轉(zhuǎn)向算法的學(xué)習(xí),有幾個(gè)原因:
第一是神經(jīng)網(wǎng)絡(luò)在AI芯片上的部署離不開(kāi)算法的優(yōu)化。一個(gè)浮點(diǎn)數(shù)的計(jì)算(加法或者乘法)和定點(diǎn)數(shù)的計(jì)算消耗的資源差距很大,對(duì)于FPGA這樣邏輯資源有限的芯片而言,定點(diǎn)計(jì)算更加友好,而且能夠提升幾倍于浮點(diǎn)計(jì)算的性能。
第二是神經(jīng)網(wǎng)絡(luò)量化壓縮需要密切的結(jié)合FPGA硬件的特點(diǎn),需要考慮到FPGA的存儲(chǔ)資源,計(jì)算符號(hào)是否能夠被FPGA友好的實(shí)現(xiàn)等。在AI加速器項(xiàng)目中,算法和FPGA都有各自的開(kāi)發(fā)者,F(xiàn)PGA會(huì)對(duì)算法組提出要求,比如激活函數(shù)量化,normalization如何做等,然后算法組在這些特定要求下去進(jìn)行算法優(yōu)化。如果一個(gè)人對(duì)FPGA和算法都比較熟悉的話(huà),那么就會(huì)更容易發(fā)現(xiàn)算法優(yōu)化的點(diǎn)。
第三是FPGA開(kāi)發(fā)方式的趨勢(shì)是多樣化。使用RTL語(yǔ)言仍然是主要的開(kāi)發(fā)方法,需要一個(gè)人有一定的數(shù)字電路基礎(chǔ)。這種開(kāi)發(fā)方式最底層,所以最靈活,可以更好的去調(diào)優(yōu)。但是同時(shí),F(xiàn)PGA一直渴望去突破固有的開(kāi)發(fā)方式,讓一個(gè)不懂得硬件的軟件開(kāi)發(fā)人員也可以很容易的上手,同時(shí)能夠縮短開(kāi)發(fā)周期,比如HLS。我相信,隨著HLS的發(fā)展和FPGA芯片的演進(jìn),使用這種方式的開(kāi)發(fā)者會(huì)越來(lái)越多。在那些算法復(fù)雜,更新較快的項(xiàng)目中,HLS更有優(yōu)勢(shì),而在一些對(duì)資源,時(shí)序,功耗要求更高的項(xiàng)目中,RTL更有優(yōu)勢(shì)。當(dāng)硬件平臺(tái)逐漸軟件化后,必然會(huì)對(duì)FPGA開(kāi)發(fā)者的算法能力提出更高的要求。
Transformer網(wǎng)絡(luò)結(jié)構(gòu)
Google在《Attention is all your need》的文章中,提出了使用全attention結(jié)構(gòu)替代LSTM的transformer模型,在翻譯任務(wù)上取得了更好的成績(jī)。這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)計(jì)算量大,計(jì)算符號(hào)相對(duì)簡(jiǎn)單,有一定的應(yīng)用,所以適合用于網(wǎng)絡(luò)加速的展示。結(jié)構(gòu)整體模型如下:
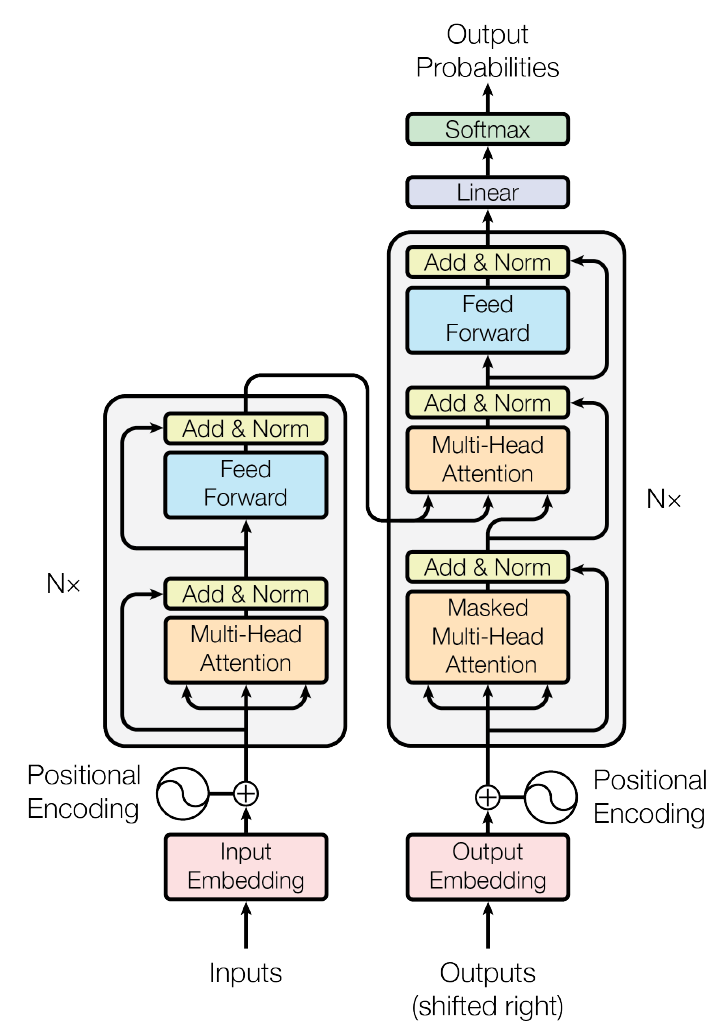
1 embedding
包含了input和output的embedding層,完成詞匯到網(wǎng)絡(luò)輸入向量的轉(zhuǎn)化,embedding的矩陣大小取決于詞匯量的多少,對(duì)于翻譯來(lái)講,通常都是巨大的,所以其不適合放在FPGA上進(jìn)行加速,沒(méi)有量化的必要。Input和output以及softmax前的linear層都共享相同的參數(shù),這樣做的目的,是因?yàn)楣蚕韎nput和output權(quán)重能夠降低word level perplexity,當(dāng)然也降低了參數(shù)存儲(chǔ)量。最后的linear使用embedding的權(quán)重是為了將網(wǎng)絡(luò)向量轉(zhuǎn)化為詞語(yǔ)出現(xiàn)的logits。
2 positional encoding
Transformer是沒(méi)有循環(huán)網(wǎng)絡(luò),為了獲取詞匯位置關(guān)系信息,對(duì)詞匯進(jìn)行位置編碼。其實(shí)就是給每個(gè)詞匯加上位置偏移,位置偏移函數(shù)選擇了sin和cos函數(shù):
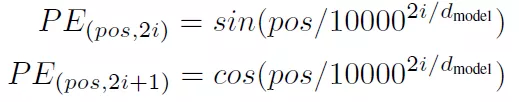
Pos是詞匯位置,i是詞匯向量的維度位置。
3 encoder
由多層的multi-head attention和linear組成,multi-headattention和linear之間由norm和add,add是一個(gè)residual連接。
Multi-head attention結(jié)構(gòu)如下:
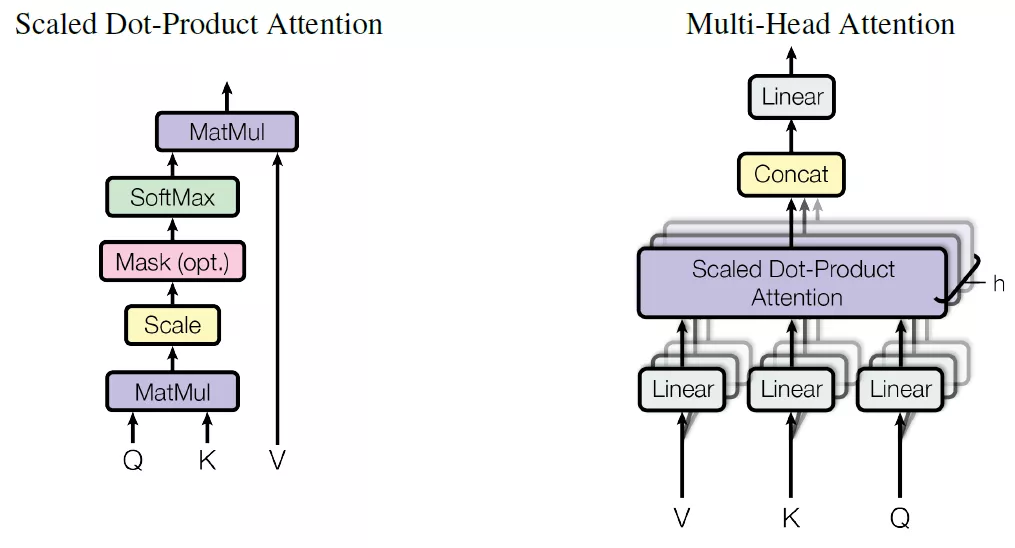
Q,K,V分別是query,key和value,這是attention機(jī)制中抽象出來(lái)的三個(gè)重要變量,通過(guò)計(jì)算q和k的相似度,得到每個(gè)k對(duì)應(yīng)的v的權(quán)重系數(shù),然后對(duì)value進(jìn)行加權(quán)求和就得到了attention值。這個(gè)是attention機(jī)制的本質(zhì)思想。Transformer中使用softmax函數(shù)來(lái)描述相似度,當(dāng)然還有很多其它方法來(lái)描述。
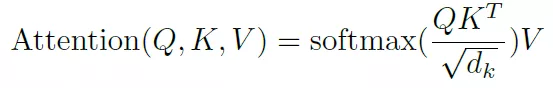
這里添加了一個(gè)scale1/squart(dk),這其實(shí)是一個(gè)參數(shù)的調(diào)節(jié),防止矩陣乘法得到結(jié)果太大而導(dǎo)致softmax函數(shù)的梯度太小。
這里還要注意transformer網(wǎng)絡(luò)沒(méi)有對(duì)Q,K,V直接進(jìn)行單一的attention計(jì)算,而是對(duì)這三個(gè)變量進(jìn)行了拆分,平行計(jì)算拆分后的變量,得到的attention值最后在拼接在一起。
4 decoder
Decoder和encoder也有類(lèi)似的結(jié)構(gòu),不同的是,在decoder中由三層:mask-multi-head attention,multi-head attention以及FC構(gòu)成。帶mask的multi-head是為了屏蔽target句子詞之后的詞,因?yàn)閷?duì)句子的翻譯應(yīng)該是由前向后進(jìn)行的,后邊的詞語(yǔ)不應(yīng)該出現(xiàn)在前邊詞語(yǔ)的預(yù)測(cè)之中。
量化方法
量化實(shí)際是一個(gè)仿射變換:
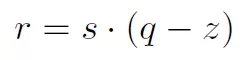
其中s是scale,q是量化后的數(shù)據(jù),z是偏移,如果采用對(duì)稱(chēng)變換,令z為0,那么就有:
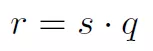
去除中心z,可以消除矩陣計(jì)算中的交叉項(xiàng)。接下來(lái)就是如何獲得q和s。q和s通過(guò)如下方式獲得:
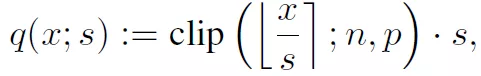
Clip操作是在最小值n和最大值p之間獲得x/s的向下整數(shù)值,如果x/s向下整數(shù)值超過(guò)n或者p就取n和p。
S的值通過(guò)訓(xùn)練獲得,為了保證能夠很好的在FPGA上計(jì)算,s的值最好可以取得2的冪次。
由于s和x都是需要訓(xùn)練的參數(shù),所以我們需要求得他們的梯度值,梯度值比較簡(jiǎn)單,對(duì)q(x, s)的x和x進(jìn)行求導(dǎo),有:
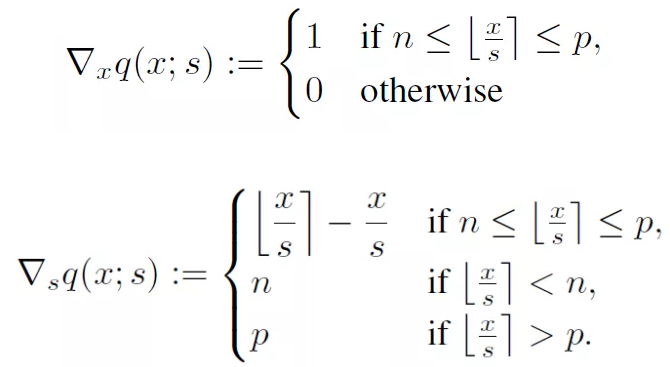
對(duì)x的梯度使用的是hinton提出的strait-through estimator,這樣做是因?yàn)榭梢韵炕氲脑肼暎斓挠?xùn)練。
實(shí)踐
transformer中有dense,matmul等操作,需要量化的數(shù)據(jù)有dense中的權(quán)重,matmul中的Q,V,K變量。第一次沒(méi)有什么經(jīng)驗(yàn),還是一點(diǎn)點(diǎn)來(lái)。首先選擇其中一個(gè)dense進(jìn)行量化。從github上下載了一個(gè)transformer的實(shí)現(xiàn)源碼https://github.com/Kyubyong/transformer,這個(gè)代碼寫(xiě)的很簡(jiǎn)潔,容易看懂。官方的實(shí)現(xiàn)代碼比較復(fù)雜,需要安裝的庫(kù)較多,曾經(jīng)也嘗試過(guò),因?yàn)槟承?kù)無(wú)法安裝成功,所以放棄了。在使用Kyubyong的transformer的時(shí)候,也遇到了一個(gè)問(wèn)題,訓(xùn)練可以完成,但是在eval的時(shí)候,報(bào)了維度的錯(cuò)誤,后來(lái)找到是在positional encoding的embedding中,經(jīng)過(guò)查找,源碼中存在一個(gè)bug,就是eval的數(shù)據(jù)集的maxlen是設(shè)置了10000,但是在embedding中傳入的查找表維度是從hparams傳入的,兩者不相同。不知道作者為什么會(huì)有這個(gè)bug。經(jīng)過(guò)改正可以正常完成eval了。
量化第一步是需要將量化插入到tensorflow的圖結(jié)構(gòu)中,即在要量化的權(quán)重?cái)?shù)據(jù)之后。這需要重新定義op和梯度,tensorflow中提供了tf.custom_gradient裝飾函數(shù)來(lái)對(duì)梯度和op進(jìn)行定義,所以我定義了如下梯度:
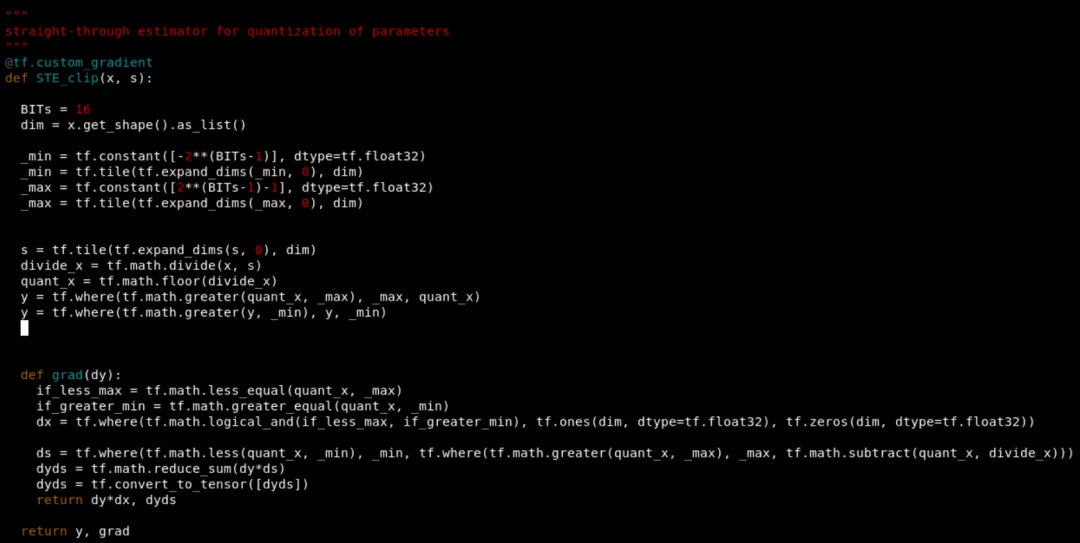
其中STE_clip中的y計(jì)算了對(duì)x的量化值,grad函數(shù)是對(duì)x和s進(jìn)行梯度計(jì)算。X和s分別是傳入的(d, d)權(quán)重和scale。dy是傳入的上一個(gè)節(jié)點(diǎn)的梯度,所以完成和STE_cllip節(jié)點(diǎn)梯度的乘積,這是由函數(shù)梯度計(jì)算的傳遞性質(zhì)決定的。這里需要注意的是,s是一個(gè)標(biāo)量,q(x,s)對(duì)s梯度是一個(gè)矩陣向量,需要和dy進(jìn)行點(diǎn)積和。
在tensorflow圖構(gòu)建中,將這個(gè)節(jié)點(diǎn)插入如下:
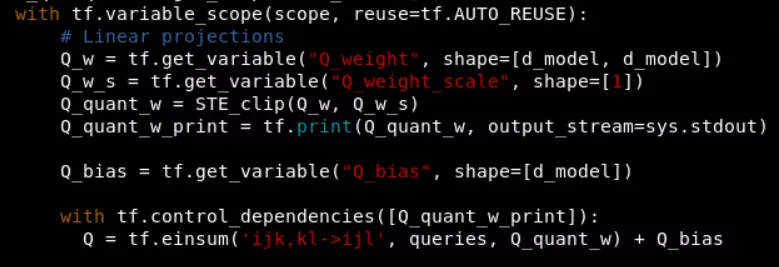
這里還添加了tf.print用于打印量化后的數(shù)據(jù)。
語(yǔ)法錯(cuò)誤修正:
1 定義的custom_gradient函數(shù)中報(bào)NoneType object is not iterable,因?yàn)楹瘮?shù)沒(méi)有返回值,默認(rèn)返回none。
2 TypeError: Input 'e' of 'Select' Op has type float32 that does not match type int32 of argument 't'. 因?yàn)槭褂胻f.greater(x, y)x和y應(yīng)該有相同數(shù)據(jù)類(lèi)型。
3 ValueError: Shapes must be equal rank,tf.greater中數(shù)據(jù)必須具有相同的rank,即維度。
4 ValueError: Shape must be rank 1 but is rank 2,tf.tile(x, axis)中x必須是具有維度的,不能夠是0維。
5 ValueError: Shape must be rank 2 but is rank 3,tf.matmul中兩個(gè)矩陣維度必須相同。
6 TypeError: Failed to convert object of type
7 TypeError: Expected int32, got None of type '_Message' instead. 這是因?yàn)檩斎霝閇N, T, d_model],其中N開(kāi)始是none的,所以當(dāng)使用tf.constant([N,1,1])的時(shí)候就會(huì)出現(xiàn)錯(cuò)誤,因?yàn)镹是none類(lèi)型。
8 Incompatible shapes between op input and calculated input gradient。輸入的數(shù)據(jù)和對(duì)該輸入數(shù)據(jù)的梯度維度不一致。
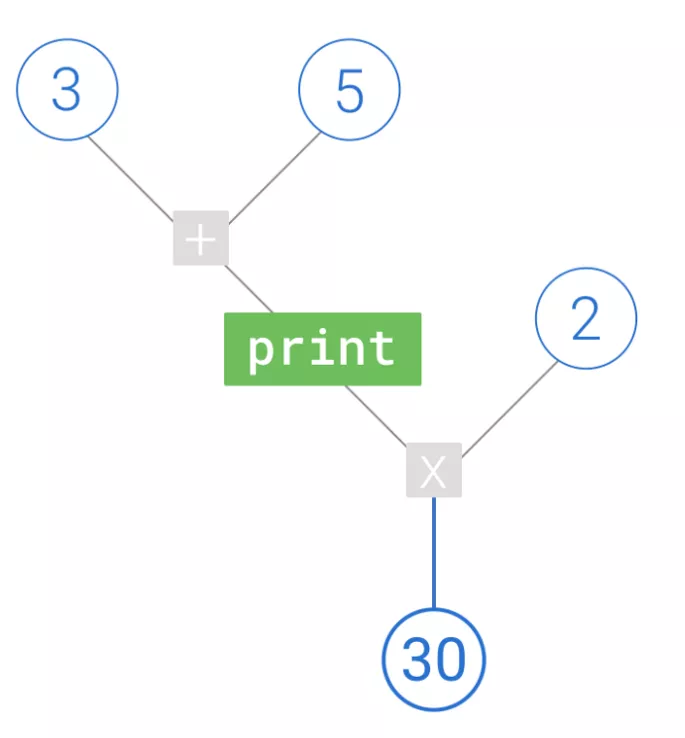
9 使用tf.print無(wú)法打印出數(shù)據(jù)。這是因?yàn)閜rint是tensorflow中的一個(gè)節(jié)點(diǎn),需要將這個(gè)節(jié)點(diǎn)加入圖中,然后才能輸出。而且只有計(jì)算流經(jīng)這個(gè)print節(jié)點(diǎn),其才會(huì)發(fā)揮作用。形象的描述應(yīng)該是:
功能問(wèn)題:
1 首先就是發(fā)現(xiàn)在訓(xùn)練過(guò)程中scale和量化數(shù)據(jù)都沒(méi)有更新,一直保持不變,而且量化值和權(quán)重?cái)?shù)據(jù)以及scale計(jì)算的數(shù)據(jù)不相同。目前還在查找當(dāng)中。
引用文獻(xiàn)
1 Learning Accurate Integer Transformer Machine-Translation Models,Ephrem Wu
2 Trained uniform quantization for accurate and efficient neural network inference on fixedpoint hardware,Sambhav R. Jain, Albert Gural, Michael Wu, and Chris Dick
3 Attention Is All You Need,Ashish Vaswani,Noam Shazeer,Niki Parmar
4 Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations,Itay Hubara,Matthieu Courbariaux,Daniel Soudry
-
FPGA
+關(guān)注
關(guān)注
1643文章
21983瀏覽量
614576 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102918 -
算法優(yōu)化
+關(guān)注
關(guān)注
0文章
4瀏覽量
6330 -
AI芯片
+關(guān)注
關(guān)注
17文章
1971瀏覽量
35709
發(fā)布評(píng)論請(qǐng)先 登錄
什么是BP神經(jīng)網(wǎng)絡(luò)的反向傳播算法
分享幾個(gè)用FPGA實(shí)現(xiàn)的小型神經(jīng)網(wǎng)絡(luò)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論