") 賽靈思FPGA與VMware vSphere相結(jié)合實現(xiàn)高吞吐量、低時延ML推斷性能
賽靈思FPGA與VMware vSphere相結(jié)合實現(xiàn)高吞吐量、低時延ML推斷性能
硬件加速器已在數(shù)據(jù)中心得到普遍使用,一系列新的工作負載已經(jīng)能夠成熟地發(fā)揮 FPGA 的加速優(yōu)勢及其更優(yōu)異的計算效率。業(yè)界對機器學(xué)習(xí) (ML) 的關(guān)注度不斷提高,推動 FPGA 加速器在私有云、公有云、混合云數(shù)據(jù)中心環(huán)境中日益普及,從而為計算密集型工作負載加速。近期,在推動 IT 基礎(chǔ)設(shè)施向異構(gòu)計算轉(zhuǎn)型的過程中,賽靈思與 VMware 展開協(xié)作,在 VMware 的云計算虛擬化平臺vSphere上測試 FPGA 加速。由于賽靈思 FPGA 越來越廣泛地應(yīng)用于 ML 推斷加速,本文將展示的是如何將賽靈思 FPGA 與 VMware vSphere 相結(jié)合,在虛擬部署和裸機部署上實現(xiàn)基本相同的高吞吐量、低時延 ML 推斷性能。
FPGA 是一種自適應(yīng)計算器件,能夠靈活地進行重新編程,從而滿足目標應(yīng)用不同的處理需求和功能要求。該特性使 FPGA 從 GPU 和 ASIC 等架構(gòu)固定的器件中脫穎而出,更是遠遠優(yōu)于成本不斷飆升的的定制 ASIC。此外,與其他硬件加速器相比,F(xiàn)PGA 還具備高能效、低時延的優(yōu)勢,使 FPGA 特別適用于 ML 推斷工作。與基本依靠大量并行處理核心實現(xiàn)高吞吐量的 GPU 不同的是,F(xiàn)PGA 通過定制化硬件內(nèi)核、數(shù)據(jù)流流水線和互聯(lián),助力 ML 推斷同時實現(xiàn)高吞吐量和低時延。
01. 在 vSphere 上使用 FPGA 開展 ML 推斷
VMware 在其實驗室中使用賽靈思 Alveo U250 數(shù)據(jù)中心卡進行測試。使用在Vitis AI中提供的 Docker 容器——為從邊緣到云端的賽靈思硬件平臺提供的 ML 推斷統(tǒng)一開發(fā)棧,ML 模型可以迅速完成配置。該容器由經(jīng)過優(yōu)化的工具、庫、模型和示例構(gòu)成。Vitis AI 支持含 Caffe 和 TensorFlow 在內(nèi)的主流框架以及能夠執(zhí)行多種深度學(xué)習(xí)任務(wù)的最新模型。此外,Vitis AI 是一種開源應(yīng)用,可通過訪問GitHub獲取。
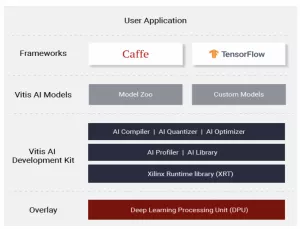
圖 1:Vitis AI 軟件協(xié)議棧
目前,賽靈思 FPGA 通過 DirectPath I/O 模式(直通模式)能在 vSphere 上使用。在這種模式下,我們的 FPGA 能夠由運行在虛擬機內(nèi)部的應(yīng)用直接訪問,繞過程序管理層,從而最大化性能并最大限度降低時延。配置 DirectPath I/O 模式下的 FPGA 只需簡單的兩步流程:首先,在主機層面上啟用 ESXi,然后將器件添加到目標虛擬機。詳細操作方法參見 VMware KB 一文( https://kb.vmware.com/s/article/1010789 )。請注意,如果運行的是 vSphere 7,則不再需要重啟主機。
02. 高吞吐量、低時延 ML 推斷性能
通過與賽靈思合作,VMware 使用四個 CNN 模型執(zhí)行推斷任務(wù),對我們的 Alveo U250 加速器卡在 DirectPath I/O 模式工作下的吞吐量和時延性能進行評估。這四個模型分別為Inception_v1、Inception_v2、Resnet50 和 VGG16。這些模型在模型參數(shù)數(shù)量上不盡相同,因而具備不同的處理復(fù)雜性。
測試在搭載兩顆 10 核 Intel Xeon Silver 4114 CPU 和 192GB DDR4 存儲器的 Dell PowerEdge R740 服務(wù)器上進行。我們使用 ESXi 7.0 虛擬機程序管理器,將每種模型的端到端性能結(jié)果與作為基線的裸機性能進行對比。Ubuntu 16.04(內(nèi)核版本 4.4.0-116)用作客戶端操作系統(tǒng)和本地操作系統(tǒng)。此外,在整個測試過程中將 Vitis AI v1.1 與 Docker CE 19.03.4 結(jié)合使用。同時使用源于 ImageNet2012 的 50k 圖像數(shù)據(jù)集。為進一步避免圖像讀取過程中遭遇磁盤瓶頸,還創(chuàng)建了一個 RAM 磁盤用于存儲 50k 圖像。
完成這些設(shè)置后,虛擬測試和裸機測試之間的性能比較可從下面的兩個圖中進行觀察。一個針對吞吐量,另一個針對時延。y 軸代表虛擬測試和裸機測試間的吞吐量性能比值。y=1.0 代表虛擬測試和裸機測試的吞吐量性能結(jié)果相同。
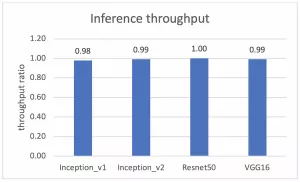
圖 2:在 Alveo U250 FPGA 上運行 ML 推斷時裸機測試和虛擬測試的吞吐量性能比較
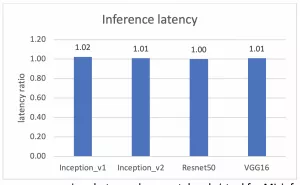
圖 3:在 Alveo U250 FPGA 上運行 ML 推斷時裸機測試和虛擬測試的時延性能比較
測試證明,虛擬環(huán)境和裸機間在吞吐量和時延兩方面的性能差距最大不超過 2%。這說明在虛擬環(huán)境中運行在 vSphere 上的 Alveo U250 的 ML 性能與作為基線的裸機性能極為相近。
03. 云端的 FPGA 性能
在數(shù)據(jù)中心中采用 FPGA 加速器已成為普遍現(xiàn)象,而且為滿足對異構(gòu)計算和性能提升的需求,F(xiàn)PGA 加速器的應(yīng)用還將繼續(xù)增長。我們非常高興能夠與 VMware 展開合作,共同確保客戶能充分發(fā)揮運行在 vSphere 平臺上的賽靈思 FPGA 加速的全部優(yōu)勢。我們在 vSphere 上對我們的 Alveo U250 加速器卡進行 ML 推斷性能測試,成功地向客戶證明了該器件在 DirectPath I/O 模式下能夠?qū)崿F(xiàn)接近裸機的性能。
編輯:hfy
-
FPGA
+關(guān)注
關(guān)注
1629文章
21729瀏覽量
603041 -
賽靈思
+關(guān)注
關(guān)注
32文章
1794瀏覽量
131253 -
云計算
+關(guān)注
關(guān)注
39文章
7776瀏覽量
137362 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8408瀏覽量
132573
發(fā)布評論請先 登錄
相關(guān)推薦
ADC芯片的采樣率為100MSPS,位寬16位,那么吞吐量是多少?
易靈思FPGA產(chǎn)品的主要特點

TMS320VC5510 HPI吞吐量和優(yōu)化

TMS320C6474通用總線架構(gòu)(CBA)吞吐量
TMS320DM36x SoC架構(gòu)和吞吐量
TMS320C6472/TMS320TCI6486的吞吐量應(yīng)用程序報告
ASP4644在FPGA SERDES供電中的應(yīng)用
求助,關(guān)于使用iperf測量mesh節(jié)點吞吐量問題求解
用Iperf例程測試ESP32-C6的TCP通信,吞吐量很低的原因?
給我一個FPGA,可以撬起所有顯示的接口和面板
如何提高CYBT-243053-02吞吐量?
Lattice Insights 簡化FPGA設(shè)計和開發(fā)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論