 解決Python解釋器讀取的字符集識別問題
解決Python解釋器讀取的字符集識別問題
Python初學者編碼實踐中經常遇到encode error,decode error,如下:
例1:
UnicodeEncodeError: 'ascii' codec can't encode character u'/u5728' in position 1
例2:
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 0-1: invalid continuation byte
1、百度的時候,大家都建議在代碼文件頭加上字符集定義:
# -*- coding: utf-8 -*-
這種方法大部分情況下可以解決大部分的問題。那么它解決的是什么問題呢?
我們需要理解兩個概念:
1)、# -*- coding: utf-8 -*- 的作用是聲明 python源代碼文件的編碼格式。 誰會讀取Python的源代碼呢? 一個是IDE編輯工具,比如pycharm,nodpad++,editpluss等,我們在寫代碼的時候使用。
2)、另一個是Python解釋器,是執行Python程序的時候使用。
當我們使用IDE編輯器打開Python代碼的時候,如果出現亂碼,我們都知道是編輯器的解碼方式和代碼文件的編碼方式不一致導致的。需要修改編輯器的解碼方式。
那么Python解釋執行Python程序的時候使用的是設么解碼方式呢?可以用下面的方式查看:
sys.getdefaultencoding()
可以用下面的方式修改:
reload(sys)
sys.setdefaultencoding('utf-8')
sys.getdefaultencoding()
所以,代碼文件第一行加 字符集定義,解決Python解釋器讀取Python代碼文件時的字符集識別問題
2、在print的時候出現異常,或者寫文件,或者解析網絡報文,或者做str對象處理的時候出現亂碼。
這個時候我們需要理解:
1)、文件讀寫、網絡報文讀寫都可以理解為IO讀寫。是byte處理,所以讀寫前后需要使用同樣的字符編碼方式。
2)、print、str對象的處理涉及到終端的編碼格式。print之后,在pycharm的輸出窗口,或者windows的CMD命令行窗口,或者Linux的shell窗口,需要適配終端的編碼方式
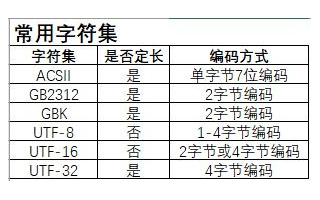
3)、字符編碼基本可分為三大類:起源于美國的ASCII,支持英文字符、數字、標點符號、鍵盤上的特殊字符;國際編碼unicode,支持ascII的字符集外,又支持中文,韓語,日語等。因為unicode占用空間大,所以又出現了utf-8。需要強調的一點是:
unicode:簡單粗暴,所有字符都是2Bytes,優點是字符->數字的轉換速度快,缺點是占用空間大
utf-8:精準,對不同的字符用不同的長度表示,優點是節省空間,缺點是:字符->數字的轉換速度慢,因為每次都需要計算出字符需要多長的Bytes才能夠準確表示
1.內存中使用的編碼是unicode,用空間換時間(程序都需要加載到內存才能運行,因而內存應該是盡可能的保證快)
2.硬盤中或者網絡傳輸用utf-8,網絡I/O延遲或磁盤I/O延遲要遠大與utf-8的轉換延遲,而且I/O應該是盡可能地節省帶寬,保證數據傳輸的穩定性。
下面詳細介紹了unicode和utf-8的使用場景:
在程序執行之前,內存中確實都是unicode編碼的二進制,比如從文件中讀取了一行x="egon",其中的x,等號,引號,地位都一樣,都是普通字符而已,都是以unicode編碼的二進制形式存放與內存中的
但是程序在執行過程中,會申請內存(與程序代碼所存在的內存是倆個空間),可以存放任意編碼格式的數據,比如x="egon",會被python解釋器識別為字符串,會申請內存空間來存放"egon",然后讓x指向該內存地址,此時新申請的該內存地址保存也是unicode編碼的egon,如果代碼換成x="egon".encode('utf-8'),那么新申請的內存空間里存放的就是utf-8編碼的字符串egon了
針對python3如下圖
瀏覽網頁的時候,服務器會把動態生成的Unicode內容轉換為UTF-8再傳輸到瀏覽器
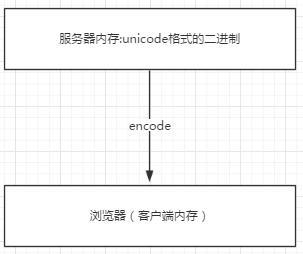
如果服務端encode的編碼格式是utf-8, 客戶端內存中收到的也是utf-8編碼的二進制。
從上面的說明,我們知道了unicode和utf-8的應用場景,就需要用下面的方式進行轉換:
字符串通過編碼轉換為字節碼,字節碼通過解碼轉換為字符串
str--->(encode)--->bytes,bytes--->(decode)--->str
編輯:hfy
-
python
+關注
關注
56文章
4793瀏覽量
84634 -
UTF-8
+關注
關注
0文章
13瀏覽量
7849
發布評論請先 登錄
相關推薦
RISC-V MCU IDE MRS(MounRiver Studio)開發之:設置工程編碼字符集
python正則表達式字符集
SVM在小字符集手寫體漢字識別中的應用研究
信息交換用藏文編碼字符集標準 GB16959-1997

MySQL字符集的設置修改和排序規則





 工商網監
工商網監
評論