") 探討實(shí)時(shí)機(jī)器學(xué)習(xí)的概念及其應(yīng)用現(xiàn)狀
探討實(shí)時(shí)機(jī)器學(xué)習(xí)的概念及其應(yīng)用現(xiàn)狀
實(shí)時(shí)機(jī)器學(xué)習(xí)正得到越來越廣泛的應(yīng)用和部署。近日,計(jì)算機(jī)科學(xué)家和 AI 領(lǐng)域科技作家 Chip Huyen 在其博客中總結(jié)了實(shí)時(shí)機(jī)器學(xué)習(xí)的概念及其應(yīng)用現(xiàn)狀,并對比了實(shí)時(shí)機(jī)器學(xué)習(xí)在中美兩國的不同發(fā)展現(xiàn)狀。
與美國、歐洲和中國一些大型互聯(lián)網(wǎng)公司的機(jī)器學(xué)習(xí)和基礎(chǔ)設(shè)施工程師聊過之后,我發(fā)現(xiàn)這些公司可以分為兩大類。一類公司重視實(shí)時(shí)機(jī)器學(xué)習(xí)的基礎(chǔ)設(shè)施投資(數(shù)億美元),并且已經(jīng)看到了投資回報(bào)。另一類公司則還在考慮實(shí)時(shí)機(jī)器學(xué)習(xí)是否有價(jià)值。
對于實(shí)時(shí)機(jī)器學(xué)習(xí)的含義,現(xiàn)在似乎還沒有明確的共識,而且也還沒有人深入探討過產(chǎn)業(yè)界該如何做實(shí)時(shí)機(jī)器學(xué)習(xí)。我與數(shù)十家在做實(shí)時(shí)機(jī)器學(xué)習(xí)的公司聊過之后,總結(jié)整理了這篇文章。
本文將實(shí)時(shí)機(jī)器學(xué)習(xí)分為兩個(gè)層級:
層級 1:機(jī)器學(xué)習(xí)系統(tǒng)能實(shí)時(shí)給出預(yù)測結(jié)果(在線預(yù)測)
層級 2:機(jī)器學(xué)習(xí)系統(tǒng)能實(shí)時(shí)整合新數(shù)據(jù)并更新模型(在線學(xué)習(xí))
本文中的「模型」指機(jī)器學(xué)習(xí)模型,「系統(tǒng)」指圍繞模型的基礎(chǔ)設(shè)施,包括數(shù)據(jù)管道和監(jiān)測系統(tǒng)。
層級 1:在線預(yù)測
這里「實(shí)時(shí)」的定義是指毫秒到秒級。
用例
延遲很重要,對于面向用戶的應(yīng)用而言尤其重要。2009 年,谷歌的實(shí)驗(yàn)表明:如果將網(wǎng)絡(luò)搜索的延遲從 100 ms 延長至 400 ms,則平均每用戶的日搜索量會降低 0.2%-0.6%。2019 年,Booking.com 發(fā)現(xiàn)延遲增加 30%,轉(zhuǎn)化率就會降低 0.5% 左右——該公司稱這是「對業(yè)務(wù)有重大影響的成本」。
不管你的機(jī)器學(xué)習(xí)模型有多好,如果它們給出預(yù)測結(jié)果的時(shí)間太長,就算只是毫秒級,用戶也會轉(zhuǎn)而點(diǎn)擊其它東西。
批量預(yù)測的問題
一個(gè)稱不上解決方案的措施是不使用在線預(yù)測。你可以用離線方法批量生成預(yù)測結(jié)果,然后將它們保存起來(比如保存到 SQL 表格中),最后在需要時(shí)拉取已有的預(yù)測結(jié)果。
當(dāng)輸入空間有限時(shí),這種方法是有效的——畢竟你完全知道有多少可能的輸入。舉個(gè)例子,如果你需要為你的用戶推薦電影。你已經(jīng)知道有多少用戶,那么你可以每隔一段時(shí)間(比如每幾個(gè)小時(shí))為每個(gè)用戶生成一組推薦。
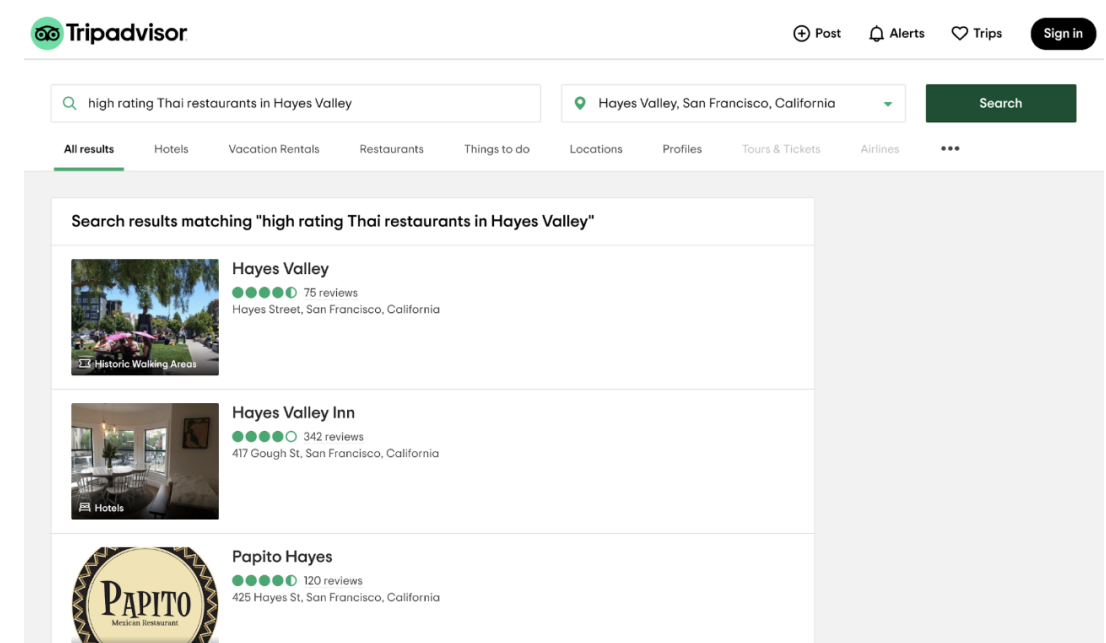
為了讓用戶輸入空間有限,很多應(yīng)用采取的方法是讓用戶從已有類別中選擇,而不是讓用戶輸入查詢。例如,如果你進(jìn)入旅游出行推薦網(wǎng)站 TripAdvisor,你必須首先選擇一個(gè)預(yù)定義的都會區(qū),而無法直接輸入任何位置。
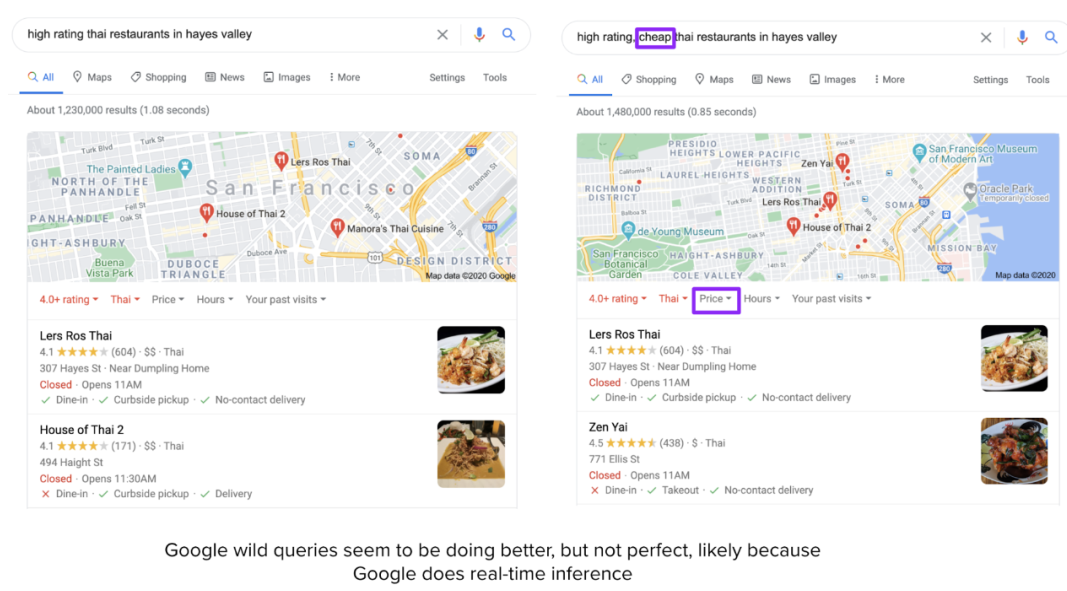
這種方法存在很多局限性。TripAdvisor 在其預(yù)定義的類別內(nèi)表現(xiàn)還算可以,比如「舊金山」的「餐廳」,但如果你想自己輸入「Hayes Valley 的高分泰式餐廳」這樣的查詢,那么結(jié)果會相當(dāng)差。
甚至很多技術(shù)較為激進(jìn)的公司也會使用批量預(yù)測,并由此顯現(xiàn)出其局限性,比如 Netflix。如果你最近看了很多恐怖片,那么當(dāng)你再次登錄 Netflix 時(shí),推薦電影中大部分會是恐怖片。但如果你今天心情愉悅,搜索了「喜劇」開始瀏覽喜劇類別,那么 Netflix 應(yīng)該學(xué)習(xí)并在推薦列表中展示更多喜劇吧?然而,它在生成下一個(gè)批量推薦列表之前并不會更新當(dāng)前列表。
在上面的兩個(gè)例子中,批量預(yù)測會降低用戶體驗(yàn)(這與用戶參與和用戶留存緊密相關(guān)),但不會導(dǎo)致災(zāi)難性的后果。其它這類例子還有廣告排序、Twitter 的熱門趨勢標(biāo)簽排序、Facebook 的新聞訂閱排序、到達(dá)時(shí)間估計(jì)等等。
還有一些應(yīng)用,如果沒有在線預(yù)測會出現(xiàn)災(zāi)難性的后果,甚至變得毫無作用,比如高頻交易、自動駕駛汽車、語音助手、手機(jī)的人臉 / 指紋解鎖、老年人跌倒檢測、欺詐檢測等。雖然在欺詐交易發(fā)生 3 小時(shí)后檢測到比檢測不到要好一些,但如果能實(shí)時(shí)檢測到欺詐,就可以直接防止其發(fā)生了。
如果將批量預(yù)測換成實(shí)時(shí)預(yù)測,我們就可以使用動態(tài)特征來得到更相關(guān)的預(yù)測結(jié)果。靜態(tài)特征是變化緩慢或不變化的信息,比如年齡、性別、工作、鄰居等。動態(tài)特征是基于當(dāng)前狀況的特征,比如你正在看什么節(jié)目、剛剛給什么內(nèi)容點(diǎn)了贊等。如果能知曉用戶現(xiàn)在對什么感興趣,那么系統(tǒng)就能給出更加相關(guān)的推薦。
解決方案
要讓系統(tǒng)具備在線預(yù)測能力,它必須要用兩個(gè)組件:
快速推理:模型要能在毫秒級時(shí)間內(nèi)給出預(yù)測結(jié)果;
實(shí)時(shí)數(shù)據(jù)管道:能夠?qū)崟r(shí)處理數(shù)據(jù)、將其輸入模型和返回預(yù)測結(jié)果的流程管道。
1. 快速推理
當(dāng)模型太大或預(yù)測時(shí)間太長時(shí),可采用的方法有三種:
讓模型更快(推理優(yōu)化)
比如聚合運(yùn)算、分散運(yùn)算、內(nèi)存占用優(yōu)化、針對具體硬件編寫高性能核等。
讓模型更小(模型壓縮)
起初,這類技術(shù)是為了讓模型適用于邊緣設(shè)備,讓模型更小通常能使其運(yùn)行速度更快。最常見的模型壓縮技術(shù)是量化(quantization),比如在表示模型的權(quán)重時(shí),使用 16 位浮點(diǎn)數(shù)(半精度)或 8 位整型數(shù)(定點(diǎn)數(shù)),而不是使用 32 位浮點(diǎn)數(shù)(全精度)。在極端情況下,一些人還嘗試了 1 位表征(二元加權(quán)神經(jīng)網(wǎng)絡(luò)),如 BinaryConnect 和 Xnor-net。Xnor-net 的作者創(chuàng)立了一家專注模型壓縮的創(chuàng)業(yè)公司 Xnor.ai,并已被蘋果公司以 2 億美元收購。
另一種常用的技術(shù)是知識蒸餾,即訓(xùn)練一個(gè)小模型(學(xué)生模型)來模仿更大模型或集成模型(教師模型)。即使學(xué)生模型通常使用教師模型訓(xùn)練得到,但它們也可能同時(shí)訓(xùn)練。在生產(chǎn)環(huán)境中使用蒸餾網(wǎng)絡(luò)的一個(gè)例子是 DistilBERT,它將 BERT 模型減小了 40%,同時(shí)還保留了 BERT 模型 97% 的語言理解能力,速度卻要快 60%。
其它技術(shù)還包括剪枝(尋找對預(yù)測最無用的參數(shù)并將它們設(shè)為 0)、低秩分解(用緊湊型模塊替代過度參數(shù)化的卷積濾波器,從而減少參數(shù)數(shù)量、提升速度)。詳細(xì)分析請參閱 Cheng 等人 2017 年的論文《A Survey of Model Compression and Acceleration for Deep Neural Networks》。
模型壓縮方面的研究論文數(shù)量正在增長,可直接使用的實(shí)用程序也在迅速增多。相關(guān)的開源項(xiàng)目也不少,這里有一份 40 大模型壓縮開源項(xiàng)目列表:https://awesomeopensource.com/projects/model-compression。
讓硬件更快
這是另一個(gè)蓬勃發(fā)展的研究領(lǐng)域。大公司和相關(guān)創(chuàng)業(yè)公司正競相開發(fā)新型硬件,以使大型機(jī)器學(xué)習(xí)模型能在云端和設(shè)備端(尤其是設(shè)備)更快地推理乃至訓(xùn)練。據(jù) IDC 預(yù)測,到 2020 年,執(zhí)行推理的邊緣和移動設(shè)備總數(shù)將達(dá) 37 億臺,另外還有 1.16 億臺被用于執(zhí)行訓(xùn)練。
2. 實(shí)時(shí)數(shù)據(jù)管道
假設(shè)你有一個(gè)駕乘共享應(yīng)用并希望檢測出欺詐交易,比如使用被盜信用卡支付。當(dāng)該信用卡的實(shí)際所有者發(fā)現(xiàn)未授權(quán)支付時(shí),他們會向銀行投訴,你就必須退款。為了最大化利潤,欺詐者可能會連續(xù)多次叫車或使用多個(gè)賬號叫車。2019 年,商家估計(jì)欺詐交易平均占年度網(wǎng)絡(luò)銷售額的 27%。檢測出被盜信用卡的時(shí)間越長,你損失的錢就會越多。
為了檢測一項(xiàng)交易是否為欺詐交易,僅檢查交易本身是不夠的。你至少需要檢查該用戶在該交易方面的近期歷史記錄、他們在應(yīng)用內(nèi)的近期行程和活動、該信用卡的近期交易以及在大約同一時(shí)間發(fā)生的其它交易。
為了快速獲得這類信息,你需要盡可能地將這些信息放在內(nèi)存之中。每當(dāng)一件你關(guān)心的事情發(fā)生時(shí),比如用戶選擇了一個(gè)位置、預(yù)定了一次行程、聯(lián)系了一位司機(jī)、取消了一次行程、添加了一張信用卡、移除了一張信用卡等,關(guān)于該事件的信息都要進(jìn)入你的內(nèi)存庫。只要這些信息還有用,它們就會一直留在內(nèi)存里(通常是幾天內(nèi)的事件),然后再被放入永久存儲庫(比如 S3)或被丟棄。針對該任務(wù),最常用的工具是 Apache Kafka,此外還有 Amazon Kinesis 等替代工具。Kafka 是一種流式存儲,可在數(shù)據(jù)流動時(shí)保存數(shù)據(jù)。
流式數(shù)據(jù)不同于靜態(tài)數(shù)據(jù),靜態(tài)數(shù)據(jù)是已完全存在于某處的數(shù)據(jù),比如 CSV 文件。當(dāng)從 CSV 文件讀取數(shù)據(jù)時(shí),你知道該任務(wù)什么時(shí)候結(jié)束。而流式數(shù)據(jù)不會結(jié)束。
一旦你有了某種管理流式數(shù)據(jù)的方法,你需要將其中的特征提取出來,然后輸入機(jī)器學(xué)習(xí)模型中。在流式數(shù)據(jù)的特征之上,你可能還需要來自靜態(tài)數(shù)據(jù)的特征(當(dāng)該賬號被創(chuàng)建時(shí),該用戶的評分是多少等等)。你需要一種工具來處理流式數(shù)據(jù)和靜態(tài)數(shù)據(jù),以及將來自多個(gè)數(shù)據(jù)源的數(shù)據(jù)組合到一起。
流式處理 vs 批處理
人們通常使用「批處理」指代靜態(tài)數(shù)據(jù)處理,因?yàn)檫@些數(shù)據(jù)可以分批處理。這與即到即處理的「流式處理」相反。批處理的效率很高——你可以使用 MapReduce 等工具來處理大量數(shù)據(jù)。流式處理的速度很快,因?yàn)槟憧梢栽诿恳环輸?shù)據(jù)到達(dá)時(shí)馬上就完成處理。Apache Flink 的一位 PMC 成員 Robert Metzger 則有不同意見,他認(rèn)為流式處理可以做到像批處理一樣高效,因?yàn)榕幚硎橇魇教幚淼囊环N特殊形式。
處理流數(shù)據(jù)的難度更大,因?yàn)閿?shù)據(jù)量沒有限定,而且數(shù)據(jù)輸入的比率和速度也會變化。比起用批處理器來執(zhí)行流式處理,使用流式處理器來執(zhí)行批處理要更容易。
Apache Kafka 有一些流式處理的能力,某些公司將這些能力置于它們的 Kafka 流式存儲之上,但 Kafka 流式處理在處理不同數(shù)據(jù)源方面的能力比較有限。還有一些擴(kuò)展 SQL 使其支持流數(shù)據(jù)的努力,SQL 是為靜態(tài)數(shù)據(jù)表設(shè)計(jì)的一種常用查詢語言。不過,最常用的流式處理工具還是 Apache Flink,而且它還有原生支持的批處理。
在機(jī)器學(xué)習(xí)生產(chǎn)應(yīng)用的早期,很多公司都是在已有的 MapReduce/Spark/Hadoop 數(shù)據(jù)管道上構(gòu)建自己的機(jī)器學(xué)習(xí)系統(tǒng)。當(dāng)這些公司想做實(shí)時(shí)推理時(shí),它們需要為流式數(shù)據(jù)構(gòu)建一個(gè)單獨(dú)的數(shù)據(jù)管道。
使用兩個(gè)不同的管道來處理數(shù)據(jù)是機(jī)器學(xué)習(xí)生產(chǎn)過程中常見 bug 的來源,比如如果一個(gè)管道沒有正確地復(fù)制到另一個(gè)管道中,那么兩個(gè)管道可能會提取出兩組不同的特征。如果這兩個(gè)管道由不同的團(tuán)隊(duì)維護(hù),那么這會是尤其常見的問題,比如開發(fā)團(tuán)隊(duì)維護(hù)用于訓(xùn)練的批處理管道,而部署團(tuán)隊(duì)則維護(hù)用于推理的流式處理管道。為了將 Flink 整合進(jìn)批處理和流式處理流程中,包括 Uber 和微博在內(nèi)的公司都對它們的基礎(chǔ)設(shè)施進(jìn)行了重大檢修。
事件驅(qū)動型方法 vs 請求驅(qū)動型方法
過去十年,軟件世界已經(jīng)進(jìn)入了微服務(wù)時(shí)代。微服務(wù)的思路是將業(yè)務(wù)邏輯分解成可獨(dú)立維護(hù)的小組件——每個(gè)小組件都是一個(gè)可獨(dú)立運(yùn)行的服務(wù)。每個(gè)組件的維護(hù)者都可以在不咨詢該系統(tǒng)其余部分的情況下快速更新和測試該組件。
微服務(wù)通常與 REST 緊密結(jié)合,這是一套可讓微服務(wù)互相通信的方法。REST API 是需求驅(qū)動型的。客戶端(服務(wù))會通過 POST 和 GET 之類的方法向服務(wù)器發(fā)送明確的請求,然后服務(wù)器返回響應(yīng)結(jié)果。為了注冊請求,服務(wù)器必須監(jiān)聽請求。
因?yàn)樵谡埱篁?qū)動的世界中,數(shù)據(jù)是根據(jù)向不同服務(wù)的請求而處理的,所以沒有一項(xiàng)服務(wù)了解數(shù)據(jù)如何流經(jīng)整個(gè)系統(tǒng)的整體情況。我們來看一個(gè)包含 3 項(xiàng)服務(wù)的簡單系統(tǒng):
A 服務(wù)管理可接單的司機(jī)
B 服務(wù)管理出行需求
C 服務(wù)預(yù)測每次展示給有需求客戶的最佳可能定價(jià)
由于價(jià)格取決于供需關(guān)系,因此服務(wù) C 的輸出取決于服務(wù) A 和 B 的輸出。首先,該系統(tǒng)需要服務(wù)之間的通信:為了執(zhí)行預(yù)測,C 需要查詢 A 和 B;而 A 需要查詢 B 才能知道是否需要移動更多司機(jī),A 還要查詢 C 以了解怎樣的定價(jià)比較合適。其次,我們沒法輕松地監(jiān)控 A 或 B 的邏輯對 C 性能的影響,也沒法在 C 性能突然下降時(shí)輕松地對數(shù)據(jù)流執(zhí)行映射以進(jìn)行調(diào)試。
才不過三項(xiàng)服務(wù),情況就已經(jīng)很復(fù)雜了。想象一下,如果有成百上千項(xiàng)服務(wù)——就像現(xiàn)在的主流互聯(lián)網(wǎng)公司那樣,服務(wù)間的通信將多得難以實(shí)現(xiàn)。通過 HTTP 以 JSON blob 形式發(fā)送數(shù)據(jù)是 REST 請求的常用模式,但這種方法的速度很慢。服務(wù)間的數(shù)據(jù)傳輸可能會變成瓶頸,拖慢整個(gè)系統(tǒng)的速度。
如果我們不再讓 20 項(xiàng)服務(wù)向 A 發(fā)送請求,而是每當(dāng) A 中有事件發(fā)生時(shí),該事件都被廣播到一個(gè)數(shù)據(jù)流中,這樣無論哪個(gè)服務(wù)需要 A 的數(shù)據(jù),都可以訂閱該數(shù)據(jù)流,然后選擇其所需的部分?如果有一個(gè)所有服務(wù)都可以廣播事件并且訂閱的數(shù)據(jù)流呢?該模式被稱為 pub/sub:發(fā)布和訂閱。Kafka 等解決方案都支持這樣的操作。由于所有數(shù)據(jù)都會流經(jīng)一個(gè)數(shù)據(jù)流,因此你可以設(shè)置一個(gè)儀表盤來監(jiān)控?cái)?shù)據(jù)及其在系統(tǒng)中的變化情況。因?yàn)檫@種架構(gòu)基于服務(wù)的事件廣播,因此被稱為事件驅(qū)動型方法。
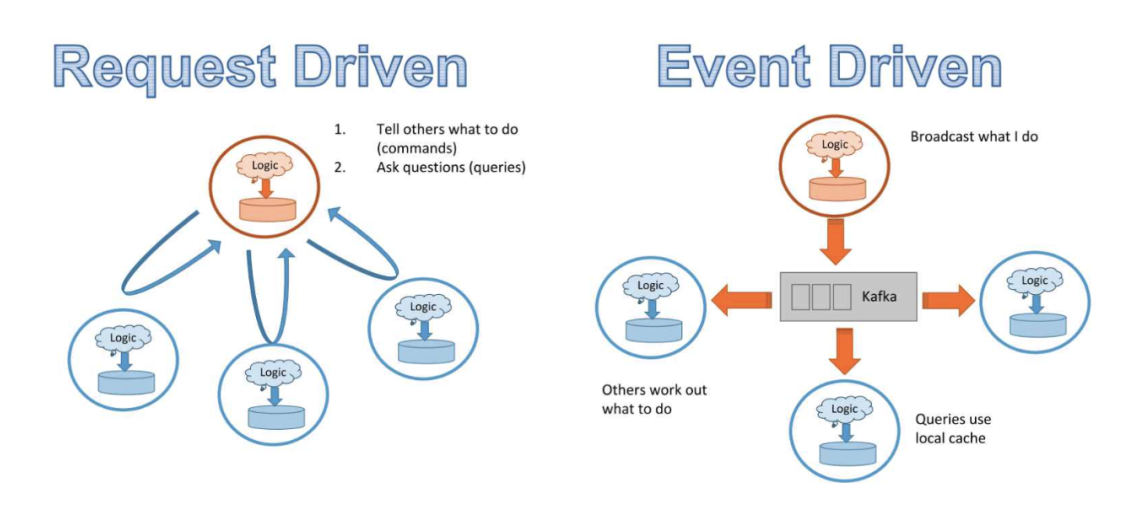
請求驅(qū)動型和事件驅(qū)動型架構(gòu)對比。(圖源:https://www.infoq.com/presentations/microservices-streams-state-scalability/)
請求驅(qū)動型架構(gòu)適用于更依賴邏輯而非數(shù)據(jù)的系統(tǒng),事件驅(qū)動型架構(gòu)則更適合數(shù)據(jù)量大的系統(tǒng)。
挑戰(zhàn)
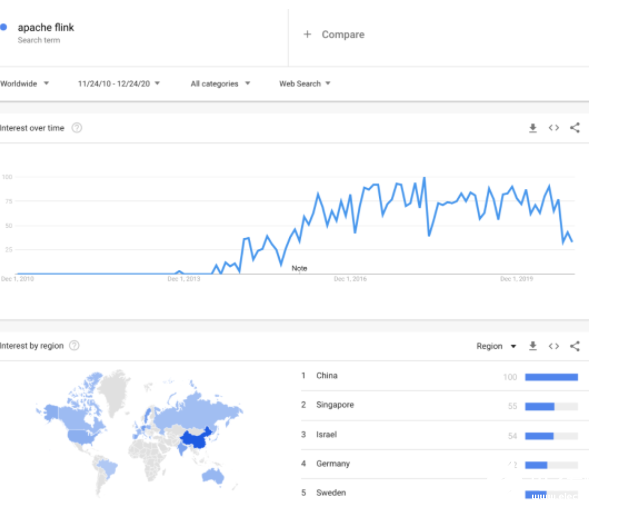
很多公司在從批處理轉(zhuǎn)向流式處理,從請求驅(qū)動型架構(gòu)轉(zhuǎn)向事件驅(qū)動型架構(gòu)。在與美國和中國的主要互聯(lián)網(wǎng)公司談過之后,我的感覺是美國這種轉(zhuǎn)變速度要慢一些,而中國的則快得多。流式架構(gòu)的采用與 Kafka 和 Flink 的流行程度緊密相關(guān)。Robert Metzger 告訴我,他觀察到亞洲使用 Flink 的機(jī)器學(xué)習(xí)負(fù)載比美國的多。「Apache Flink」這個(gè)關(guān)鍵詞的谷歌搜索趨勢與這一觀察一致。
流式架構(gòu)沒有更受歡迎的原因有很多:
1. 公司沒有看到流式架構(gòu)的優(yōu)勢。
這些公司的系統(tǒng)規(guī)模還沒有達(dá)到服務(wù)間通信會造成瓶頸的程度。
它們沒有能受益于在線預(yù)測的應(yīng)用。
它們有能受益于在線預(yù)測的應(yīng)用,但還不知道這一點(diǎn),因?yàn)樗鼈冎皬奈催M(jìn)行過在線預(yù)測。
2. 基礎(chǔ)設(shè)施所需的前期投資較高。
基礎(chǔ)設(shè)施更新的成本較高并且可能損害已有應(yīng)用,管理者不愿意投資升級支持在線預(yù)測的基礎(chǔ)設(shè)施。
3. 思維轉(zhuǎn)換
從批處理轉(zhuǎn)向流式處理需要轉(zhuǎn)換思維。使用批處理,你知道任務(wù)會在何時(shí)完成。使用流式處理,則無法知曉。你可以制定一些規(guī)則,比如獲得之前 2 分鐘內(nèi)所有數(shù)據(jù)點(diǎn)的平均,但如果一個(gè)發(fā)生在 2 分鐘之前的事件被延遲了,還沒有進(jìn)入數(shù)據(jù)流呢?使用批處理,你可以合并處理定義良好的表格,但在流式處理模式下,不存在可以合并的表格,那么合并兩個(gè)數(shù)據(jù)流的操作是什么意思呢?
4. Python 不兼容
Python 算得上是機(jī)器學(xué)習(xí)的通用語言,但 Kafka 和 Flink 基于 Java 和 Scala 運(yùn)行。引入流式處理可能會導(dǎo)致工作流程中的語言不兼容。Apache Beam 在 Flink 之上提供了一個(gè)用于與數(shù)據(jù)流通信的 Python 接口,但你仍然需要能用 Java/Scala 開發(fā)的人。
5. 更高的處理成本
批處理意味著你可以更加高效地使用計(jì)算資源。如果你的硬件能夠一次處理 1000 個(gè)數(shù)據(jù)點(diǎn),那么使用它來一次處理 1 個(gè)數(shù)據(jù)點(diǎn)就顯得有些浪費(fèi)了。
層級 2:在線學(xué)習(xí)
這里的「實(shí)時(shí)」定義在分鐘級。
定義「在線學(xué)習(xí)」
我使用的詞語是「在線學(xué)習(xí)」而非「在線訓(xùn)練」,原因是后者存在爭議。根據(jù)定義,在線訓(xùn)練的意思是基于每個(gè)輸入的數(shù)據(jù)點(diǎn)進(jìn)行學(xué)習(xí)。非常少的公司會真正這么做,原因包括:
這種方法存在災(zāi)難性遺忘的問題——神經(jīng)網(wǎng)絡(luò)在學(xué)習(xí)到新信息時(shí)會突然遺忘之前學(xué)習(xí)的信息。
基于單個(gè)數(shù)據(jù)點(diǎn)的學(xué)習(xí)流程比基于批量數(shù)據(jù)的學(xué)習(xí)流程成本更高(通過降低硬件的規(guī)格,使之降到僅能處理單個(gè)數(shù)據(jù)點(diǎn)的水平,這個(gè)問題可以得到一定緩解)。
即使一個(gè)模型能使用每個(gè)輸入的數(shù)據(jù)點(diǎn)進(jìn)行學(xué)習(xí),這也不意味著在每個(gè)數(shù)據(jù)點(diǎn)之后都會部署新的權(quán)重。由于我們目前對機(jī)器學(xué)習(xí)算法學(xué)習(xí)方式的理解還很有限,因此模型更新后,我們還需要對其進(jìn)行評估,查看表現(xiàn)如何。
對大多數(shù)執(zhí)行所謂的在線訓(xùn)練的公司而言,它們的模型都是以微批量學(xué)習(xí)的,并且會在一段時(shí)間之后進(jìn)行評估。在評估之后,只有該模型的表現(xiàn)讓人滿意時(shí)才會得到更廣泛的部署。微博從學(xué)習(xí)到部署的模型更新迭代周期為 10 分鐘。
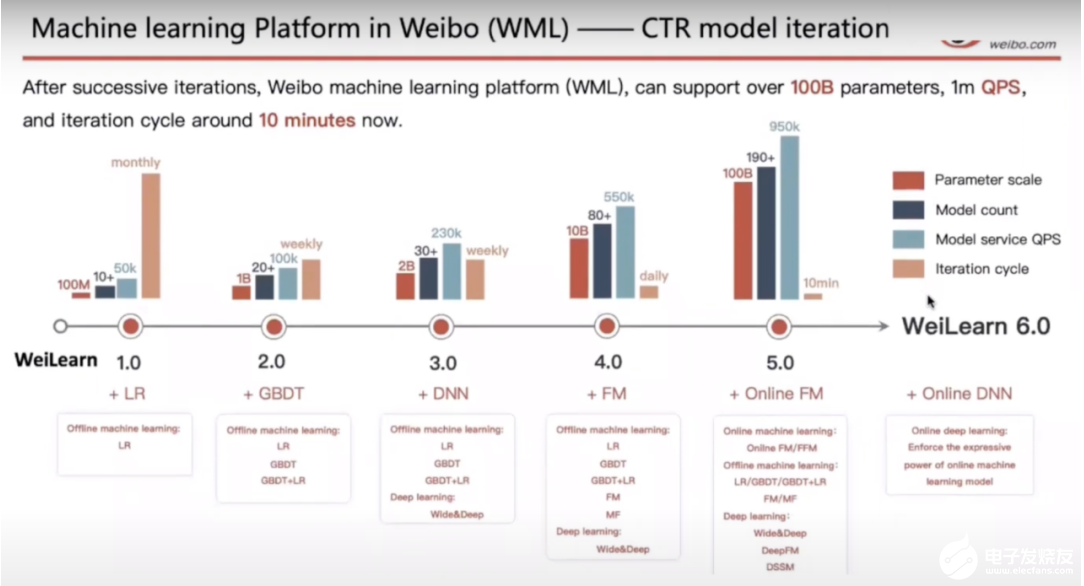
微博使用 Flink 的機(jī)器學(xué)習(xí)(圖源:https://www.youtube.com/watch?v=WQ520rWgd9A)
用例
TikTok 讓人上癮。它的秘訣在于推薦系統(tǒng),其能快速學(xué)習(xí)你的偏好并推薦你可能會接著看下去的視頻,從而為用戶提供一個(gè)不斷刷新視頻的體驗(yàn)。TikTok 能做到這一點(diǎn)的原因是其母公司字節(jié)跳動建立了一套成熟的基礎(chǔ)設(shè)施,使其推薦系統(tǒng)能夠?qū)崟r(shí)地學(xué)習(xí)用戶偏好。
推薦系統(tǒng)是在線學(xué)習(xí)的理想應(yīng)用之一。推薦系統(tǒng)有很自然的標(biāo)簽——如果一位用戶點(diǎn)擊一個(gè)推薦,那么這個(gè)預(yù)測就是正確的。并非所有推薦系統(tǒng)都需要在線預(yù)測。用戶對房子、汽車、航班和酒店的偏好不太可能過一分鐘就變了,因此對于這樣的系統(tǒng),持續(xù)學(xué)習(xí)并不太合理。但是,用戶對在線內(nèi)容的偏好卻會很快改變,比如視頻、文章、新聞、推文、帖子和貼圖。(比如我剛讀到章魚有時(shí)會毫無緣由地?fù)舸螋~,現(xiàn)在我想看看相關(guān)視頻。)由于用戶對在線內(nèi)容的偏好會實(shí)時(shí)變化,因此廣告系統(tǒng)也需要實(shí)時(shí)更新以展示相關(guān)廣告。
在線學(xué)習(xí)對系統(tǒng)適應(yīng)罕見事件至關(guān)重要。以黑色星期五在線購物為例,由于黑色星期五一年僅發(fā)生一次,因此亞馬遜和其它電商網(wǎng)站不可能有足夠多的歷史數(shù)據(jù)來學(xué)習(xí)用戶在那天的行為,因此它們的系統(tǒng)需要持續(xù)學(xué)習(xí)那天的狀況以應(yīng)對變化。
再以 Twitter 的搜索為例,有時(shí)候某些名人會發(fā)布一些愚蠢的內(nèi)容。舉個(gè)例子,當(dāng)關(guān)于「Four Seasons Total Landscaping(直譯為:四季完全景觀美化)」的新聞上線時(shí),很多人會去搜索「total landscaping」。如果你的系統(tǒng)沒有立即學(xué)習(xí)到這里的「total landscaping」是指特朗普的一場新聞發(fā)布會,那么用戶就會看到大量關(guān)于園藝的推薦。
在線學(xué)習(xí)還可以幫助解決冷啟動(cold start)問題。冷啟動是指新用戶加入你的應(yīng)用時(shí),你還沒有他們的信息。如果沒有任何形式的在線學(xué)習(xí),你就只能向新用戶推薦一般性內(nèi)容,直到你下一次以離線方式訓(xùn)練好模型。
解決方案
因?yàn)樵诰€學(xué)習(xí)相對較為新穎,大多數(shù)做在線學(xué)習(xí)的公司也不會公開談?wù)撈浼?xì)節(jié),因此目前還不存在標(biāo)準(zhǔn)解決方案。
在線學(xué)習(xí)并不意味著「無批量學(xué)習(xí)」。在在線學(xué)習(xí)方面最成功的公司也會同時(shí)以離線方式訓(xùn)練其模型,然后再將在線版本與離線版本組合起來。
挑戰(zhàn)
無論是理論上還是實(shí)踐中,在線學(xué)習(xí)都面臨著諸多挑戰(zhàn)。
理論挑戰(zhàn)
在線學(xué)習(xí)顛覆了我們對機(jī)器學(xué)習(xí)的許多已有認(rèn)知。在入門級機(jī)器學(xué)習(xí)課程中,學(xué)生學(xué)到的東西雖然細(xì)節(jié)有所不同,但核心都是「使用足夠多 epoch 訓(xùn)練你的模型直到收斂」。而在線學(xué)習(xí)沒有 epoch——你的模型只會看見每個(gè)數(shù)據(jù)一次。在線學(xué)習(xí)也不存在收斂這個(gè)說法,基礎(chǔ)數(shù)據(jù)分布會不斷變化,沒有什么可以收斂到的靜態(tài)分布。
在線學(xué)習(xí)的另一大理論挑戰(zhàn)是模型評估。在傳統(tǒng)的批訓(xùn)練中,你會在靜態(tài)的留出測試集上評估模型。如果新模型在同一個(gè)測試集上優(yōu)于現(xiàn)有模型,那我們就說新模型更好。但是,在線學(xué)習(xí)的目標(biāo)是讓模型適應(yīng)不斷變化的數(shù)據(jù)。如果更新后的模型是在現(xiàn)在的數(shù)據(jù)上訓(xùn)練的,而且我們知道現(xiàn)在的數(shù)據(jù)不同于過去的數(shù)據(jù),那么再在舊有數(shù)據(jù)集上測試更新后的模型是不合理的。
那么,我們該怎么知道在前 10 分鐘的數(shù)據(jù)上訓(xùn)練的模型優(yōu)于使用前 20 分鐘的數(shù)據(jù)訓(xùn)練的模型呢?答案是必須在當(dāng)前數(shù)據(jù)上比較兩個(gè)模型。在線學(xué)習(xí)需要在線評估,但是向用戶提供還未測試的模型聽起來簡直是災(zāi)難。
不過,很多公司都這么做。新模型首先要進(jìn)行離線測試,以確保它們不會造成災(zāi)難性后果,然后再通過復(fù)雜的 A/B 測試系統(tǒng),與現(xiàn)有模型并行地進(jìn)行在線評估。只有當(dāng)新模型在該公司關(guān)心的某個(gè)指標(biāo)上的表現(xiàn)優(yōu)于現(xiàn)有模型時(shí),它才能得到更廣泛的部署。(本文不再討論如何選擇在線評估的指標(biāo)。)
實(shí)踐挑戰(zhàn)
在線訓(xùn)練目前還沒有標(biāo)準(zhǔn)的基礎(chǔ)設(shè)施。一些公司選擇使用參數(shù)服務(wù)器的流式架構(gòu),但除此之外,我了解過的公司都不得不構(gòu)建許多自己的基礎(chǔ)設(shè)施。此處不再詳細(xì)討論,因?yàn)橐恍┕疽笪覍@些信息保密,因?yàn)樗麄儤?gòu)建的方案是為自己服務(wù)的——這是他們的競爭優(yōu)勢。
美國和中國的 MLOps 競賽
我讀過許多有關(guān)美國和中國 AI 競賽的文章,但大多數(shù)比較關(guān)注研究論文、專利、引用和投資。但當(dāng)我與美國和中國公司聊過實(shí)時(shí)機(jī)器學(xué)習(xí)的話題之后,我才注意到他們的 MLOps 基礎(chǔ)設(shè)施有著驚人的差距。
美國很少互聯(lián)網(wǎng)公司嘗試過在線學(xué)習(xí),而即使是使用在線學(xué)習(xí)的公司,也不過是將其用于簡單的模型,比如 Logistic 回歸。而不管是與中國公司直接談,還是與曾在兩個(gè)國家的公司工作過的人談,給我的印象都是在線學(xué)習(xí)在中國公司里更常見,而且中國的工程師也更愿意嘗試在線學(xué)習(xí)。下圖是一些對話截圖。
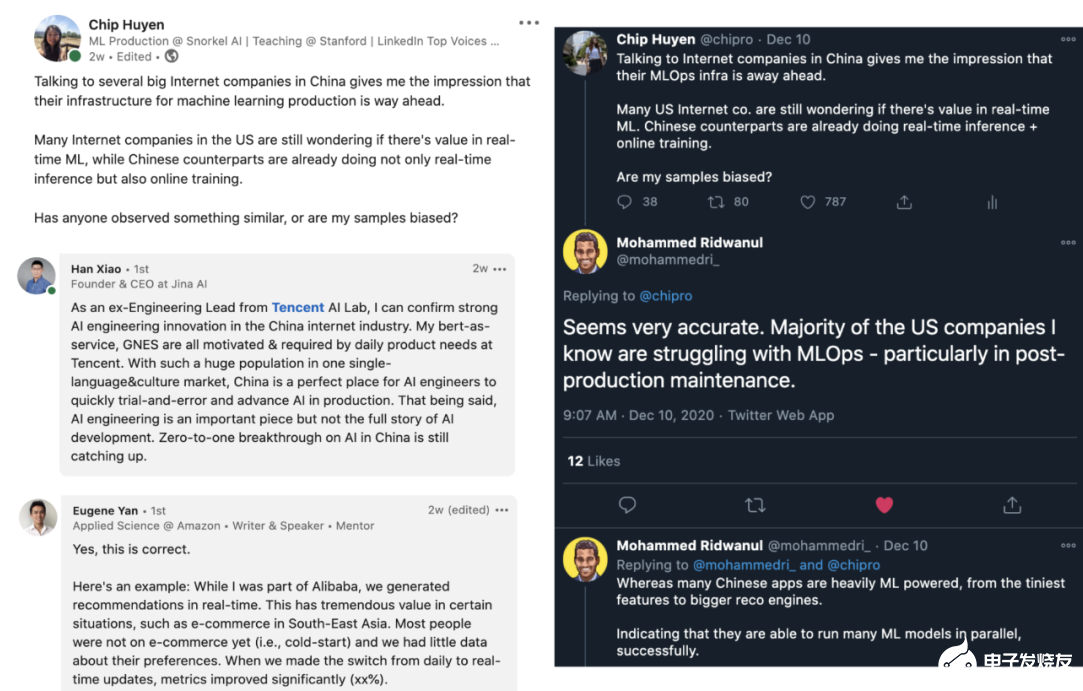
總結(jié)
實(shí)時(shí)機(jī)器學(xué)習(xí)發(fā)展正盛,不管你是否已經(jīng)準(zhǔn)備好。盡管大多數(shù)公司還在爭論在線推理和在線學(xué)習(xí)是否有價(jià)值,但某些正確部署的公司已經(jīng)看到了投資回報(bào),它們的實(shí)時(shí)算法可能將成為它們保持競爭優(yōu)勢的重要因素。
編輯:hfy
-
FPGA
+關(guān)注
關(guān)注
1629文章
21748瀏覽量
603805 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8421瀏覽量
132710
發(fā)布評論請先 登錄
相關(guān)推薦
如何選擇云原生機(jī)器學(xué)習(xí)平臺
自然語言處理與機(jī)器學(xué)習(xí)的關(guān)系 自然語言處理的基本概念及步驟
S參數(shù)的概念及應(yīng)用
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】+ 簡單建議
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】全書概覽與時(shí)間序列概述
如何理解機(jī)器學(xué)習(xí)中的訓(xùn)練集、驗(yàn)證集和測試集
機(jī)器學(xué)習(xí)中的數(shù)據(jù)預(yù)處理與特征工程
人工智能、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)是什么
機(jī)器學(xué)習(xí)算法原理詳解
機(jī)器學(xué)習(xí)在數(shù)據(jù)分析中的應(yīng)用
名單公布!【書籍評測活動NO.35】如何用「時(shí)間序列與機(jī)器學(xué)習(xí)」解鎖未來?
圖機(jī)器學(xué)習(xí)入門:基本概念介紹

深入探討機(jī)器學(xué)習(xí)的可視化技術(shù)

視覺機(jī)器人焊接的研究現(xiàn)狀






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論