 基于機器學習方法的網絡流量解析
基于機器學習方法的網絡流量解析
隨著大眾網絡安全意識的穩步提升,對于數據保護的意識也愈加強烈。根據Google的報告,2019年10月,Chrome加載網頁中啟用加密的比例已經達到了95%。對于特定類型的流量,加密甚至已成為法律的強制性要求,加密在保護隱私的同時也給網絡安全帶來了新的隱患。攻擊者將加密作為隱藏活動的工具,加密流量給攻擊者隱藏其命令與控制活動提供了可乘之機。在面臨日益嚴重的網絡安全威脅和攻擊時,需要提出有效的識別方法。實現加密流量精細化管理,保障計算機和終端設備安全運行,維護健康綠色的網絡環境。
01、相關研究
當前對于加密網絡流識別的研究主要集中在機器學習相關的方法上。使用機器學習方法對網絡流量進行解析時,按使用的機器學習算法不同可以分為傳統機器學習算法(淺層學習)和深度學習。傳統機器學習算法對加密網絡流量解析主要存在兩個問題:一個是需要對待分類的報文人工設計一個可以普遍反映流量特征的特征集;另一個就是傳統機器學習方法有很大的局限性,例如對復雜函數難以表示、容易陷入局部最優解等。
由于以上兩個原因,導致傳統機器學習方法對加密網絡流量解析的準確率不是很高。隨著計算方法的發展和計算能力的提高,深度學習的引入可以有效解決機器學習設計特征的問題。深度學習通過特征學習和分層特征提取的方法來替代手工獲取特征。深度神經網絡擁有很高的擬合能力,可以逼近許多復雜的函數,不易陷入局部最優解。解決了傳統機器學習在加密網絡流量解析時存在的兩個關鍵問題。
深度學習是基于表示學習的眾多機器學習算法中的一員。目前使用最多的深度學習方法包括DBN(Deep Belief Nets)、CNN(Convolutional Neural Networks)、深度自編碼器(AutoEncoder,AE)和循環神經網絡(Recurrent Neural Network,RNN)以及基于RNN的長短期記憶網絡(Long Short-Term Memory,LSTM),近年來這些方法被廣泛地應用在加密流量解析中,并取得了不錯的成果。王偉等人提出一種基于CNN的異常流量檢測方法,該方法利用CNN特征學習能力,準確地對流量的特征進行提取,將提取到的特征用于流量分類并取得了良好的結果,最終將該模型用于異常流量檢測。
J.Ran等人提出了一種將三維卷積神經網絡應用于無線網絡流量分類的方法,實驗結果表明該方法優于一維和二維卷積神經網絡。Jain研究了由不同優化器訓練的卷積神經網絡對協議識別的影響,實驗結果表明,隨機梯度下降(Stochastic Gradient Descent,SGD)優化器產生的識別效果最好。陳雪嬌等利用卷積神經網絡的識別準確率高和自主進行特征選擇的優勢,將其應用于加密流量的識別,測試結果表明該方法優于DPI方法。
王勇等設計了基于LeNet-5深度卷積神經網絡的分類方法,通過不斷調整參數產生最優分類模型,測試結果表明該方法優于主成分分析、稀疏隨機映射等方法。Wu,Kehe等人將網絡流量數據的121個流統計特征作為數據集,并對比了一維和二維CNN網絡、CNN網絡與傳統機器學習算法、CNN網絡與RNN網絡的分類準確性與計算量。
J.Ren等提出了一種針對無線通信網絡的協議識別方法,首先利用一維卷積神經網絡進行自動化的特征提取,然后基于SVM對應用層協議進行分類。H.Lim等提出了使用深度學習的基于數據包的網絡流量分類,該方法提取網絡會話中的前幾個數據包處理成等長的向量,然后利用CNN和ResNet進行訓練,進行流量分類。
在以往的基于深度學習的加密網絡流量解析研究中,數據預處理都是只針對原始的網絡流量數據進行變換處理,而忽略了數據包在傳輸過程中的時間特征。因此,在本研究中,將對加密網絡流量中的原始報文數據及數據包傳輸時間間隔進行綜合預處理,并采用CNN網絡模型進行實驗驗證。
02、基于CNN的加密網絡流量識別方法
本節將從流量采集、數據預處理、加密網絡流量識別模型等環節詳細介紹本文提出的基于深度學習的加密網絡流量解析方法。
2.1流量采集
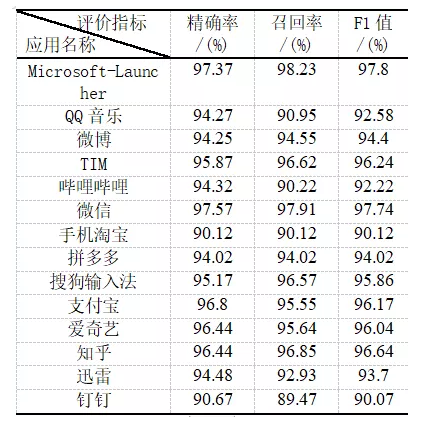
為了獲得更加接近實際使用場景下的網絡流量,我們在手機終端安裝了代理軟件,采集日常真實使用環境下的應用網絡流量,并按照應用名稱分別保存為不同的文件,共計14類,16.81GB。
2.2數據預處理
采集的網絡流量存儲為Pcap格式的文件,該格式的文件除了流量數據外,還有該文件協議額外添加的其他信息,而這些信息有可能干擾分類結果。因此需要對該文件的格式進行解析,提取出有用的數據部分。
2.2.1 Pcap格式介紹
Pcap文件格式如圖1所示,最開始的24個字節為文件頭(Global Header),后面是抓取的包頭(Packet Header)和包數據(Packet Data)。此處的包頭為Pcap文件格式的固定部分,描述了后面緊跟著的包數據的捕獲時間、捕獲長度等信息,原始網絡數據流量中不包含此部分信息。包數據為數據鏈路層到應用層的所有數據,包括每一層的包頭。

圖1 Pcap文件格式
圖2描述了Global Header的具體內容以及每部分的長度。
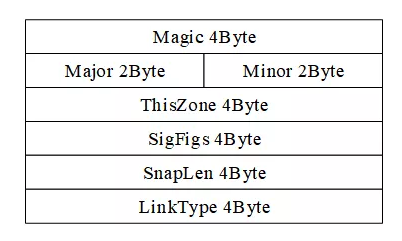
圖2 Global Header格式
每個字段的含義如下:
(1)Magic:4Byte,標記文件開始,并用來識別文件自己和字節順序。0xa1b2c3d4用來表示按照原來的順序讀取,0xd4c3b2a1表示下面的字節都要交換順序讀取。考慮到計算機內存的存儲結構,一般會采用0xd4c3b2a1,即所有字節都需要交換順序讀取。
(2)Major:2Byte,當前文件主要的版本號。
(3)Minor:2Byte,當前文件次要的版本號。
(4)ThisZone:4Byte,當地的標準時間。
(5)SigFigs:4Byte,時間戳的精度。
(6)SnapLen:4Byte,最大的存儲長度。
(7)LinkType:4Byte,數據鏈路類型。
圖3描述了Packet Header的具體內容以及每部分的長度。

圖3 Packet Header格式
每個字段的含義如下:
(1)Timestamp:捕獲時間的高位,單位為秒。
(2)Timestamp:捕獲時間的低位,單位為微秒。
(3)Caplen:當前數據區的長度,單位為字節。
(4)Len:離線數據長度,網絡中實際數據幀的長度。
2.2.2預處理方法
通過圖3對Pcap文件格式的介紹,我們發現,Pcap文件中除了原始流量數據之外還有Global Header和Packet Header這兩部分原始數據流量中不存在的部分。因此,在接下來的數據處理環節中,我們將剔除這部分數據或者對這部分數據進行轉換。預處理流程如下:
首先對采集到的Pcap文件按協議進行過濾,提取出經過加密的網絡流量,然后對提取出的流量按五元組進行劃分。劃分出來的每一個文件將在后續流程中轉化為一張圖片。對劃分出來的每一個Pcap文件做如下處理。
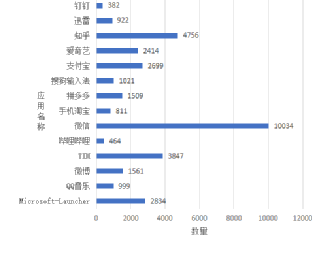
圖4每種應用的對應的圖片數量
設最后返回的字節數組為A,需要的長度為LEN。
(1)首先忽略前24個字節。
(2)然后讀取16個字節的Packet Header,將其中的時間轉換為整數,利用其中的捕獲長度讀取Packet data,忽略掉數據鏈路層和網絡層的包頭,將傳輸層的包頭和payload加入字節數組A。
(3)如果不是第一個數據包,則利用本數據包的捕獲時間減去上一個數據包的捕獲時間,得到時間差Δt,利用本數據包的捕獲長度L除以Δt,向上取整得到N,向字節數組A中加入N個0xFF字節。
(4)重復(2)(3)直到文件尾,或者A的長度大于等于LEN。
(5)若讀取到文件尾之前,A的長度大于等于LEN,則截斷到LEN返回;若讀到文件尾,A的長度仍小于LEN,則在末尾填充0x00直到長度為LEN。
(6)將A數組轉化為長、寬相同的單通道灰度圖片。
最終將生成好的圖片存儲為TFRecoder格式,以便于后面的實驗驗證。預處理后每種應用得到的圖片數目如圖4所示。
2.3加密網絡流量識別模型
本文采用了二維CNN模型進行流量分類,為了對比不同輸入對實驗結果的影響,分別嘗試了圖片長寬為32、40、48、56、64,其中當長寬為32時效果最佳。下面介紹本文最終采用的CNN模型。
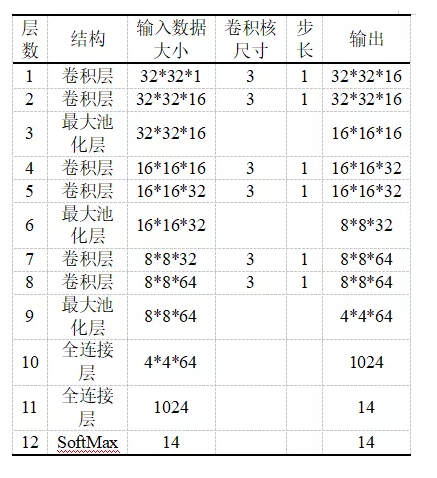
在卷積神經網絡中,大尺寸的卷積核可以帶來更大的感受視野,獲取更多的信息,但也會產生更多的參數,從而增加網絡的復雜度。為了減少模型的參數,本文采用兩個連續的3*3卷積層來代替單個的5*5卷積層,可以在保持感受視野范圍的同時減少參數量。卷積層的Padding方式使用SAME方式,激活函數使用RELU,每一層的參數如表1所示。
表1網絡模型參數
03、實驗與結果分析
為了對上述加密網絡流量識別模型進行驗證,采用TensorFlow深度學習框架,在NVIDIA TESLA K80上進行了實驗驗證。
3.1評價指標
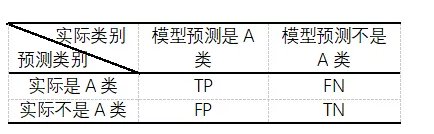
本文采用準確率(accuracy)、精準率(precision)、召回率(recall)和F1-Measure值(以下簡稱F1值)四個評價指標來對實驗結果進行評估,其中準確率是對整體的評價指標,精準率和召回率是用來對某種類別流量識別的評價指標,而F1值是對于精準率和召回率兩個指標的綜合評估。為了計算這四個指標,需要引入TP、FP、FN、TN四個參數,每個參數的意義如表2混淆矩陣所示。
表2混淆矩陣
每個指標的計算方法如公式(1)~(4)所示。

3.2實驗結果
將處理好的數據按4:1的比例分為訓練集和測試集,由于采集的數據不均衡,因此在訓練時對訓練數據采用過采樣的方法來縮小數據量之間的差異。采用了Adam優化器和動態學習率來提高模型的訓練速度。最終訓練好的模型在測試集上的結果如表3所示。
表3測試集結果
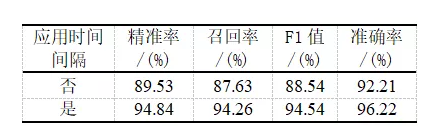
為了驗證在預處理階段引入時間間隔對模型準確率的影響,還做了一組對比實驗。對比實驗在預處理階段不對時間間隔做特殊處理,直接舍棄該字段,最終結果如表4所示。可以看出,利用時間間隔可以有效提高分類結果的準確率。
表4不同預處理方式對應的實驗結果
04、結語
本文提出了一種基于深度學習的加密網絡流量識別方法,該方法對采集到的流量進行預處理,利用傳輸層數據及數據包之間的時間間隔,將時間間隔轉換為二進制數據中的特殊值,然后將解析后的數據轉換為灰度圖片,采用卷積神經網絡對采集到的14類應用的加密流量進行分類,最終識別準確率為96.22%,可以滿足實際應用。后續研究將關注流量類型的甄別,即對每種應用流量中不同類型的流量進行識別,如視頻流量、文本流量、圖片流量等,進一步挖掘用戶行為。
編輯:hfy
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
網絡安全
+關注
關注
10文章
3155瀏覽量
59702 -
機器學習
+關注
關注
66文章
8408瀏覽量
132568 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
發布評論請先 登錄
相關推薦
VLAN 實施對網絡性能的影響
什么是機器學習?通過機器學習方法能解決哪些問題?

機器學習中的數據分割方法
深度學習中的無監督學習方法綜述
深度學習與nlp的區別在哪
人工神經網絡與傳統機器學習模型的區別
艾體寶干貨 IOTA流量分析秘籍第一招:網絡基線管理
艾體寶干貨 | 教程:使用ntopng和nProbe監控網絡流量
網絡監控工具有哪些 網絡監控用幾芯網線
虹科分享 | 實現網絡流量的全面訪問和可視性——Profitap和Ntop聯合解決方案
實現網絡流量的全面訪問和可視性——Profitap和Ntop聯合解決方案

請問初學者要怎么快速掌握FPGA的學習方法?
網絡流量對PLC控制過程的影響測試內容





 工商網監
工商網監
評論