") 檢索增強(qiáng)型語言表征模型預(yù)訓(xùn)練
檢索增強(qiáng)型語言表征模型預(yù)訓(xùn)練
自然語言處理的最新進(jìn)展以 無監(jiān)督預(yù)訓(xùn)練 為基礎(chǔ),使用大量文本訓(xùn)練通用語言表征模型 (Language Representation Models),無需人工標(biāo)注或標(biāo)簽。這些預(yù)訓(xùn)練模型,如 BERT和 RoBERTa,經(jīng)證明可以記憶大量世界知識(shí),例如“the birthplace of Francesco Bartolomeo Conti”、“the developer of JDK”和“the owner of Border TV”。
RoBERTa
https://arxiv.org/abs/1907.11692
經(jīng)證明可以記憶大量世界知識(shí)
https://arxiv.org/pdf/1909.01066.pdf
雖然知識(shí)編碼能力對(duì)于某些自然語言處理任務(wù)(如問題回答、信息檢索和文本生成等)尤為重要,但這些模型是 隱式地 記憶知識(shí),也就是說世界知識(shí)在模型權(quán)重中以抽象的方式被捕獲,導(dǎo)致已存儲(chǔ)的知識(shí)及其在模型中的位置都難以確定。此外,存儲(chǔ)空間以及模型的準(zhǔn)確率也受到網(wǎng)絡(luò)規(guī)模的限制。為了獲取更多的世界知識(shí),標(biāo)準(zhǔn)做法是訓(xùn)練更大的網(wǎng)絡(luò),這可能非常緩慢或非常昂貴。
如果有一種預(yù)訓(xùn)練方法可以 顯式地 獲取知識(shí),如引用額外的大型外部文本語料庫,在不增加模型大小或復(fù)雜性的情況下獲得準(zhǔn)確結(jié)果,會(huì)怎么樣?
例如,模型可以引用外部文集中的句子“Francesco Bartolomeo Conti was born in Florence”來確定這位音樂家的出生地,而不是依靠模型隱晦的訪問存儲(chǔ)于自身參數(shù)中的某個(gè)知識(shí)。像這樣檢索包含顯性知識(shí)的文本,將提高預(yù)訓(xùn)練的效率,同時(shí)使模型能夠在不使用數(shù)十億個(gè)參數(shù)的情況下順利完成知識(shí)密集型任務(wù)。
在 2020 ICML 我們介紹的 “REALM: Retrieval-Augmented Language Model Pre-Training”中,我們分享了一種語言預(yù)訓(xùn)練模型的新范例,用 知識(shí)檢索器 (Knowledge Retriever) 增強(qiáng)語言模型,讓 REALM 模型能夠從原始文本文檔中 顯式 檢索文本中的世界知識(shí),而不是將所有知識(shí)存儲(chǔ)在模型參數(shù)中。我們還開源了 REALM 代碼庫,以演示如何聯(lián)合訓(xùn)練檢索器和語言表示。
REALM: Retrieval-Augmented Language Model Pre-Training
https://arxiv.org/abs/2002.08909
REALM 代碼庫
https://github.com/google-research/language/tree/master/language/realm
背景:預(yù)訓(xùn)練語言表征模型
要了解標(biāo)準(zhǔn)語言表征模型記憶世界知識(shí)的方式,首先應(yīng)該回顧這些模型的預(yù)訓(xùn)練過程。自從 BERT 問世以來,稱為遮蔽語言建模 (Masked Language Modeling) 的填空任務(wù)已廣泛用于預(yù)訓(xùn)練語言表征模型。給定某些單詞被遮蓋的文本,任務(wù)是填充缺失的單詞。任務(wù)的樣本如下所示:
I am so thirsty. I need to __ water.
預(yù)訓(xùn)練期間,模型將遍歷大量樣本并調(diào)整參數(shù),預(yù)測(cè)缺失的單詞(上述樣本中的答案:answer: drink)。于是,填空任務(wù)使模型記住了世界中的某些事實(shí)。例如,在以下樣本中,需要了解愛因斯坦的出生地才能填補(bǔ)缺失單詞:
Einstein was a __-born scientist. (answer: German)
但是,模型捕獲的世界知識(shí)存儲(chǔ)在模型權(quán)重中,因此是抽象的,難以模型到底理解存儲(chǔ)了哪些信息。
檢索增強(qiáng)型語言表征模型預(yù)訓(xùn)練
與標(biāo)準(zhǔn)語言表征模型相比,REALM 通過 知識(shí)檢索器 增強(qiáng)語言表征模型,首先從外部文檔集中檢索另一段文本作為支持知識(shí),在實(shí)驗(yàn)中為 Wikipedia 文本語料庫,然后將這一段支持文本與原始文本一起輸入語言表征模型。
Wikipedia 文本語料庫
https://archive.org/details/wikimediadownloads
REALM 的關(guān)鍵理念是檢索系統(tǒng)應(yīng)提高模型填補(bǔ)缺失單詞的能力。因此,應(yīng)該獎(jiǎng)勵(lì)提供了更多上下文填補(bǔ)缺失單詞的檢索。如果檢索到的信息不能幫助模型做出預(yù)測(cè),就應(yīng)該進(jìn)行阻攔,為更好的檢索騰出空間。
假定預(yù)訓(xùn)練期間只有未標(biāo)記的文本,那么該如何訓(xùn)練知識(shí)檢索器?事實(shí)證明,可以使用填補(bǔ)單詞的任務(wù)來間接訓(xùn)練知識(shí)檢索器,無需任何人工標(biāo)注。假設(shè)查詢的輸入為:
We paid twenty __ at the Buckingham Palace gift shop.
在沒有檢索的情況下,很難填補(bǔ)句子中缺失的單詞 (answer: pounds),因?yàn)槟P托枰[式存儲(chǔ)白金漢宮所在國家和相關(guān)貨幣的知識(shí),并在兩者之間建立聯(lián)系。如果提供了一段與從外部語料庫中檢索的必要知識(shí)顯式連接的段落,模型會(huì)更容易填補(bǔ)缺失的單詞。
在此例中,檢索器會(huì)因?yàn)闄z索以下句子獲得獎(jiǎng)勵(lì)。
Buckingham Palace is the London residence of the British monarchy.
由于檢索步驟需要添加更多上下文,因此可能會(huì)有多個(gè)檢索目標(biāo)對(duì)填補(bǔ)缺失單詞有所幫助,例如“The official currency of the United Kingdom is the Pound.”。下圖演示了整個(gè)過程:

REALM 的計(jì)算挑戰(zhàn)
擴(kuò)展 REALM 預(yù)訓(xùn)練使模型從數(shù)百萬個(gè)文檔中檢索知識(shí)具有一定挑戰(zhàn)性。在 REALM 中,最佳文檔選擇為最大內(nèi)積搜索 (Maximum Inner Product Search,MIPS)。檢索前,MIPS 模型需要首先對(duì)集合中的所有文檔進(jìn)行編碼,使每個(gè)文檔都有一個(gè)對(duì)應(yīng)的文檔向量。輸入到達(dá)時(shí)會(huì)被編碼為一個(gè)查詢向量。在 MIPS 中,給定查詢就會(huì)檢索出集合中文檔向量和查詢向量之間具有最大內(nèi)積值的文檔,如下圖所示:
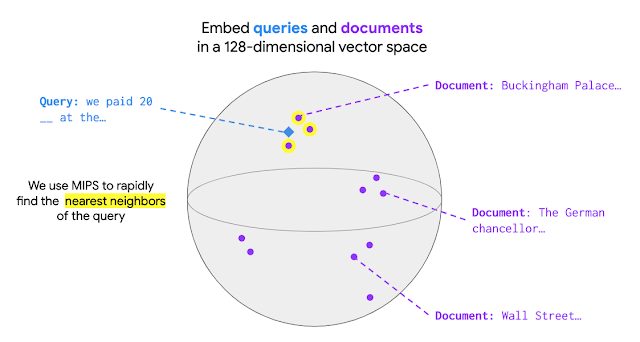
REALM 采用 ScaNN軟件包高效執(zhí)行 MIPS,在預(yù)先計(jì)算文檔向量的情況下,相對(duì)降低了尋找最大內(nèi)積值的成本。但是,如果在訓(xùn)練期間更新了模型參數(shù),通常有必要對(duì)整個(gè)文檔集重新編碼文檔向量。為了解決算力上的挑戰(zhàn),檢索器經(jīng)過結(jié)構(gòu)化設(shè)計(jì)可以緩存并異步更新對(duì)每個(gè)文檔執(zhí)行的計(jì)算。另外,要實(shí)現(xiàn)良好性能并使訓(xùn)練可控,應(yīng)每 500 個(gè)訓(xùn)練步驟更新文檔向量而不是每步都更新。
將 REALM 應(yīng)用于開放域問答
將 REALM 應(yīng)用于開放域問答 (Open-QA) 評(píng)估其有效性,這是自然語言處理中知識(shí)最密集的任務(wù)之一。任務(wù)的目的是回答問題,例如“What is the angle of the equilateral triangle(等邊三角形的一角是多少度)?”
在標(biāo)準(zhǔn)問答任務(wù)中(例如 SQuAD 或 Natural Questions),支持文檔是輸入的一部分,因此模型只需要在給定文檔中查找答案。Open-QA 中沒有給定文檔,因此 Open-QA 模型需要自主查找知識(shí),這就使 Open-QA 成為檢查 REALM 有效性的絕佳任務(wù)。
SQuAD
https://arxiv.org/abs/1606.05250
Natural Questions
https://ai.google.com/research/NaturalQuestions/
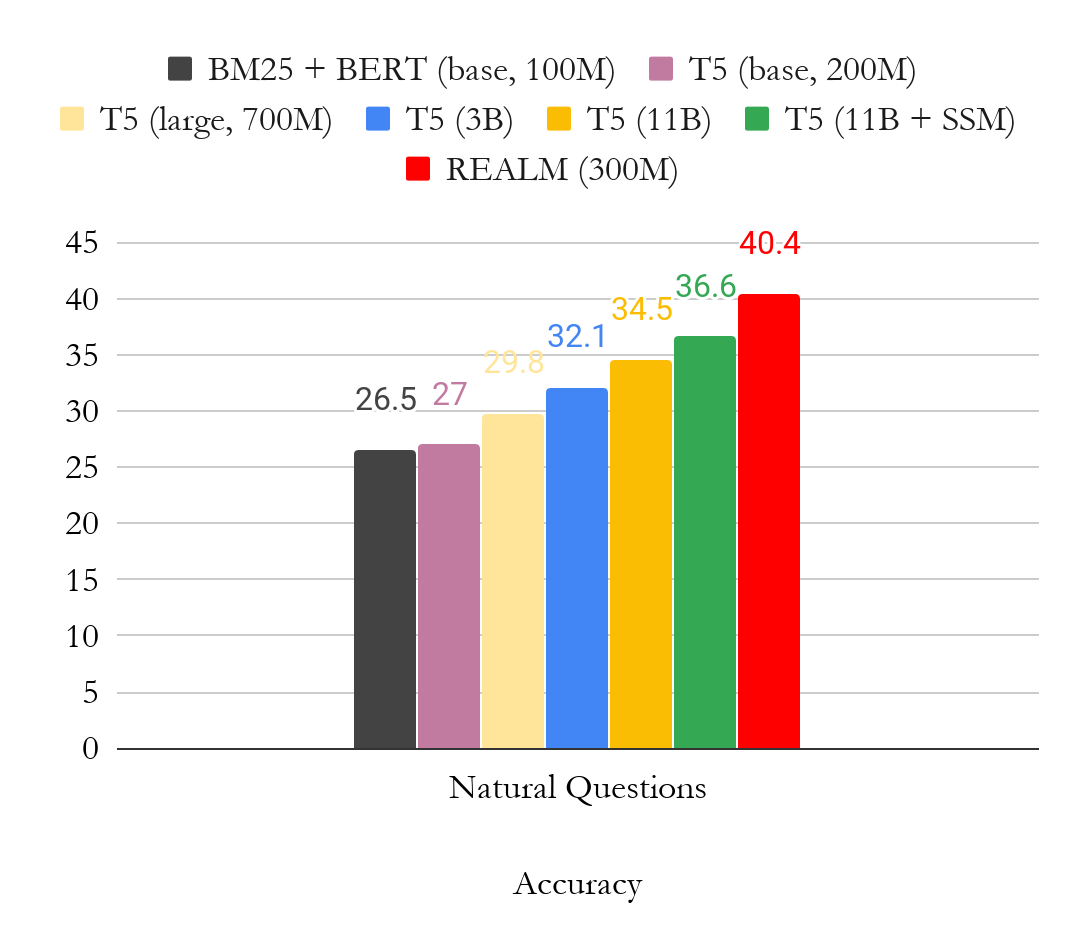
下圖是 OpenQA 版本 Natural Question 的結(jié)果。我們主要將結(jié)果與 T5 進(jìn)行比較,T5 是另一種無需標(biāo)注文檔即可訓(xùn)練模型的方法。從圖中可以清楚地看到,REALM 預(yù)訓(xùn)練生成了非常強(qiáng)大的 Open-QA 模型,僅使用少量參數(shù) (300M),性能就比更大的 T5 (11B) 模型要高出近 4 個(gè)點(diǎn)。
結(jié)論
REALM 有助于推動(dòng)人們對(duì)端到端檢索增強(qiáng)型模型的關(guān)注,包括最近的一個(gè)檢索增強(qiáng)型生成模型。我們期待以多種方式擴(kuò)展這一工作范圍,包括 :
將類似 REALM 的方法應(yīng)用于需要知識(shí)密集型推理和可解釋出處的新應(yīng)用(超越 Open-QA)
了解對(duì)其他形式的知識(shí)進(jìn)行檢索的好處,例如圖像、知識(shí)圖譜結(jié)構(gòu)甚至其他語言的文本。我們也很高興看到研究界開始使用開源 REALM 代碼庫!
檢索增強(qiáng)型生成模型
https://arxiv.org/abs/2005.11401
REALM 代碼庫
https://github.com/google-research/language/tree/master/language/realm
-
模型
+關(guān)注
關(guān)注
1文章
3254瀏覽量
48876 -
代碼
+關(guān)注
關(guān)注
30文章
4791瀏覽量
68680 -
自然語言處理
+關(guān)注
關(guān)注
1文章
618瀏覽量
13570
原文標(biāo)題:REALM:將檢索集成到語言表征模型,搞定知識(shí)密集型任務(wù)!
文章出處:【微信號(hào):tensorflowers,微信公眾號(hào):Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
檢索增強(qiáng)型生成(RAG)系統(tǒng)詳解
什么是大模型、大模型是怎么訓(xùn)練出來的及大模型作用

【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
增強(qiáng)型MOS管的結(jié)構(gòu)解析
mos管增強(qiáng)型與耗盡型的區(qū)別是什么
大語言模型的預(yù)訓(xùn)練
預(yù)訓(xùn)練模型的基本原理和應(yīng)用
大語言模型:原理與工程時(shí)間+小白初識(shí)大語言模型
【大語言模型:原理與工程實(shí)踐】大語言模型的應(yīng)用
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實(shí)踐】核心技術(shù)綜述
【大語言模型:原理與工程實(shí)踐】揭開大語言模型的面紗
【大語言模型:原理與工程實(shí)踐】探索《大語言模型原理與工程實(shí)踐》
大語言模型推斷中的批處理效應(yīng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論