 一個新任務:給定知識圖譜中的一條query path,生成對應的問題
一個新任務:給定知識圖譜中的一條query path,生成對應的問題
引言
EMNLP2020中,復旦大學數據智能與社會計算實驗室 (Fudan DISC) 提出了一篇基于事實的問題生成工作,論文題目為:PathQG: Neural Question Generation from Facts,被錄取為長文。
文章摘要

關于問題生成的當前研究通常將輸入文本作為序列直接編碼,而沒有明確建模其中的事實信息,這會導致生成的問題和文本不太相關或者信息量較少。在這篇論文中,我們考慮結合文本中的事實以幫助問題生成。我們基于輸入文本的事實信息構造了知識圖,并提出了一個新任務:給定知識圖中的一條query路徑生成問題。任務可以被分為兩個步驟,(1)對query表示的學習;(2)基于query的問題生成。我們首先將query表示學習定義為序列標記問題,以識別涉及的事實從而學習到一個query表示,之后使用基于RNN的生成器進行問題生成。我們以端到端的方式共同訓練這兩個模塊,并提出通過變分框架加強這兩個模塊之間的交互。我們基于SQuAD構造了實驗數據集,實驗結果表明我們的模型優于其他方法,并且當目標問題復雜時,性能提升更多。通過人工評估,也驗證了我們生成的問題的確和文本更相關且信息更豐富。
研究動機
本文關注基于文本的問題生成任務(Question Generation from Text):輸入一段文本,自動生成對應的問題。
當前端到端的問題生成研究,通常對輸入文本直接編碼并學習一個隱表示,而沒有對其中的語義信息進行明確建模,這會使得生成過程有較大不確定性,導致生成的問題包含和給定文本不相關的信息或者信息量較少,如下圖顯示,生成的問題Q2包含了不相關的信息“Everton Fc”,而Q1雖然正確但是缺少特定的信息描述,顯得比較簡略。
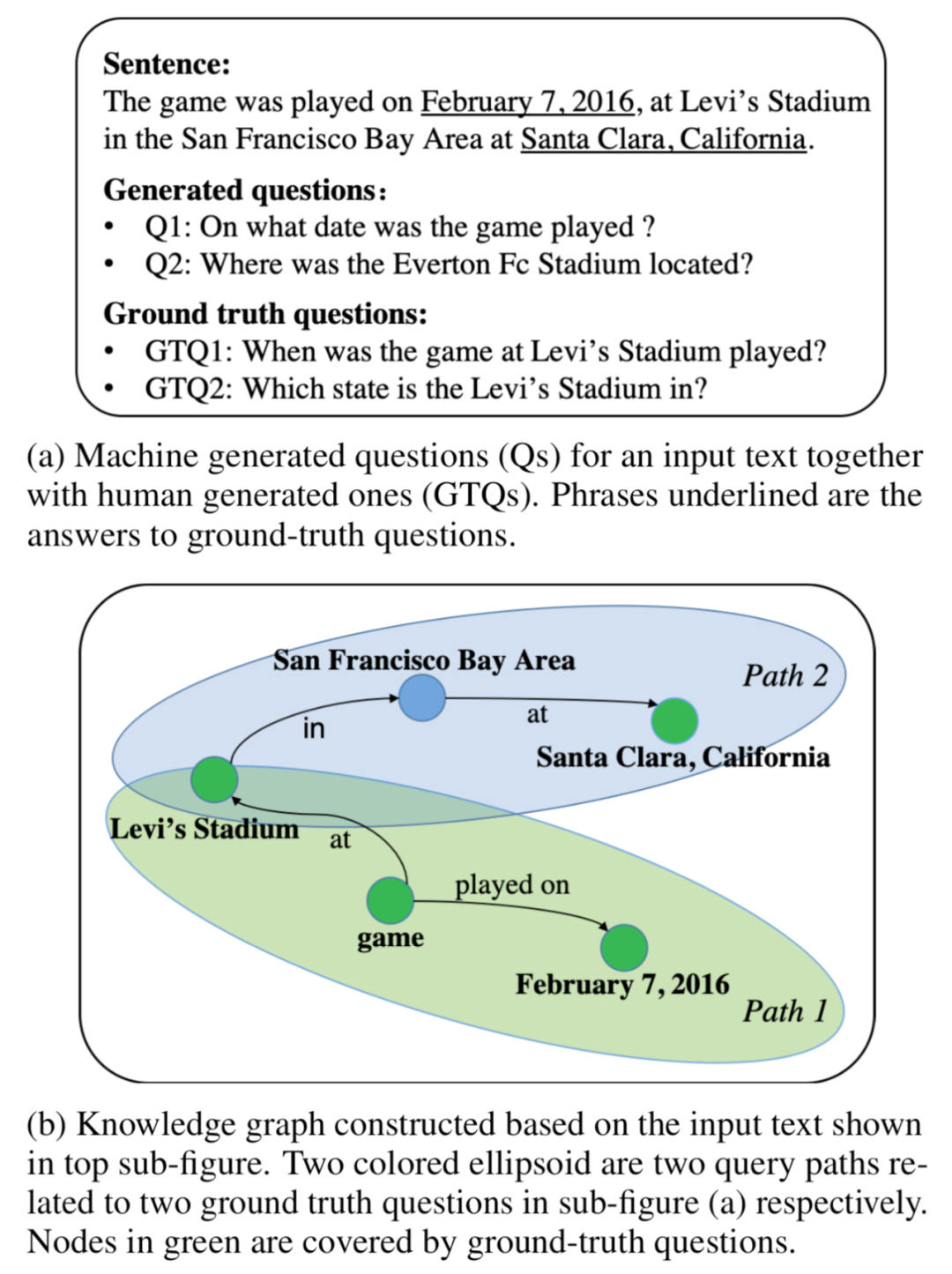
先對輸入文本中的事實(facts)進行建模可以減輕這些問題,并且針對文本中的多個事實,可以生成較為復雜(complex)的問題。我們通過對給定文本構建知識圖譜(Knowledge Graph,KG)來表示其中的事實,并提出一個新任務:給定知識圖譜中的一條query path來生成問題,其中query path是一條由多個事實三元組構成的序列,每個事實三元組包含兩個實體以及它們的關系。如上圖(b)顯示了一個KG以及其中的兩條query paths。
由于query path中并非所有事實都會在目標問題中被提及,我們首先需要學習一個query representation來表示query path中會被提及的事實信息,并基于此生成對應的問題,因此任務可以分成兩個步驟:(1)對query representation的學習;(2)基于query的問題生成。我們以端到端的方式共同訓練這兩個模塊,并提出通過變分框架加強這兩個模塊之間的交互。
我們使用了數據集SQuAD,并且為了驗證模型在復雜問題生成上的效果,基于SQuAD構造了一個復雜問題數據集,并分別進行了實驗。
模型
Path-based Question Generation
給定query path的問題生成任務包含兩個步驟,我們設計兩個模塊:Query Representation Learner和Query-based Question Generator分別進行任務中的兩個步驟。我們首先以端到端的框架PathQG共同訓練這兩個模塊,具體結構如下圖顯示。
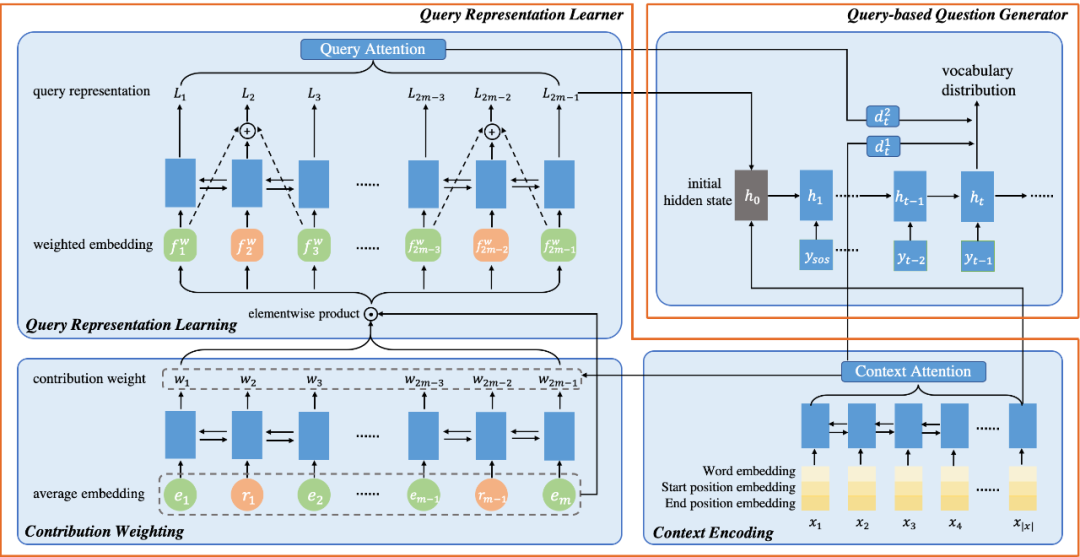
1. Query Representation Learner
由于query path中的不同的實體和關系會對生成目標問題有不同的貢獻度,我們首先計算它們各自的貢獻權重,從而學到一個query representation來表示目標問題將涉及的事實信息。
貢獻權重計算:將query path看作是一條由實體和關系相間構成的序列,并將query path中各個成分的貢獻度計算看作是一個序列標記過程。并且對輸入文本進行編碼作為context,通過attention幫助序列標記的概率計算,最后將各個位置的sigmoid概率作為各自的貢獻權重。
Query表示學習:得到query path的各個成分的貢獻權重后,我們以加權的方式對query path編碼,學習到對應的query representationL。考慮到query path由實體和關系相間構成的特殊結構,我們使用循環跳躍網絡(recurrent skipping network, RSN)來對路徑序列進行編碼。
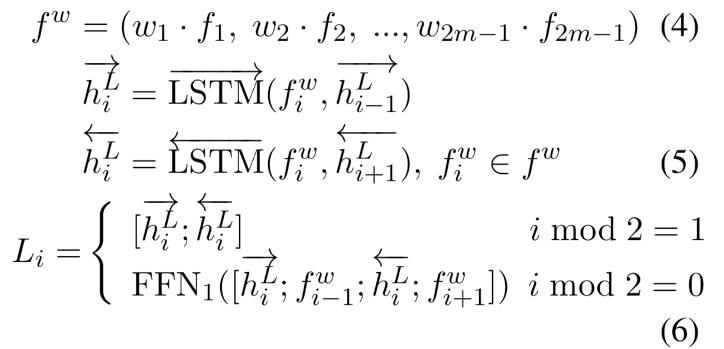
2. Query-based Question Generator
基于學到的query representationL,解碼生成對應的問題。將最后的query representation和context表示聯合作為解碼器的初始狀態,并分別對他們執行注意力機制,逐步生成問題。
Variational Path-based Question Generation
對query representation的學習可以看成是對query path的一個推斷過程,參考變分推斷的思想,我們將query representation的學習看作是推導query的先驗分布(prior query distribution),而基于query的問題生成是在計算目標問題的likelihood,我們又引入了一個額外的后驗query分布(posterior query distribution),通過將目標問題作為指導來幫助減少query representation學習的不確定性。并且通過訓練,使得query的先驗分布不斷靠近后驗分布,最終提升生成的問題質量。變分PathQG的結構如下圖。
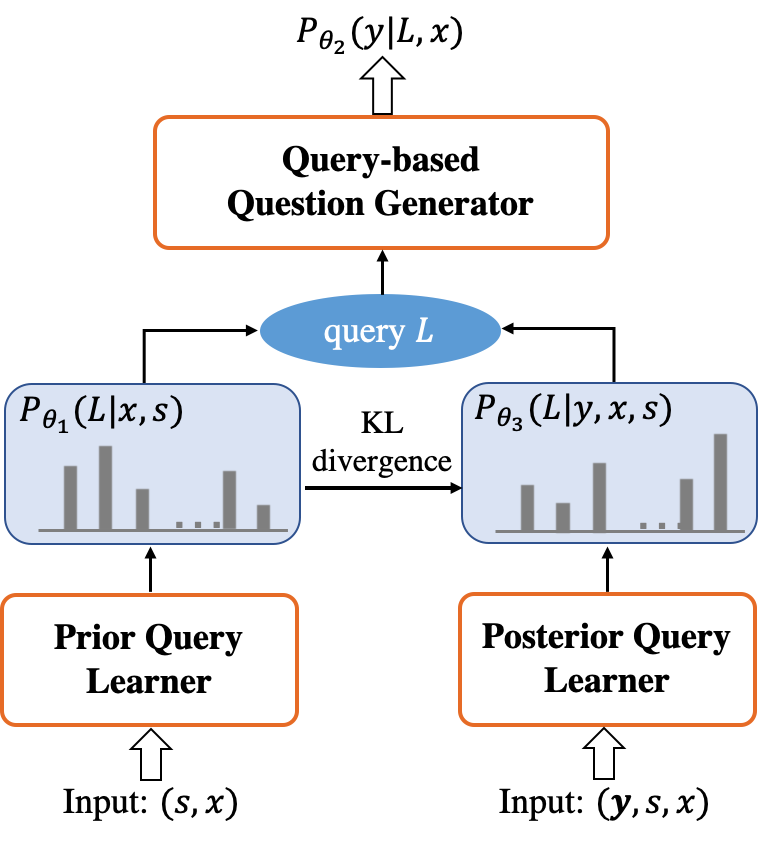
實驗
我們在SQuAD數據集上進行了實驗,對每一條文本,通過場景圖解析器(scene garph parser)和詞性標注器(part-of-speech tagger)自動構建了知識圖譜,并且根據參考問題從知識圖譜中抽取出對應的query path。為了進一步驗證模型在復雜問題生成上的效果,我們還根據query path中事實三元組的個數從SQuAD中劃分了一個復雜問題數據集。在全數據集和復雜數據集上的實驗結果顯示我們的模型都優于其他模型。
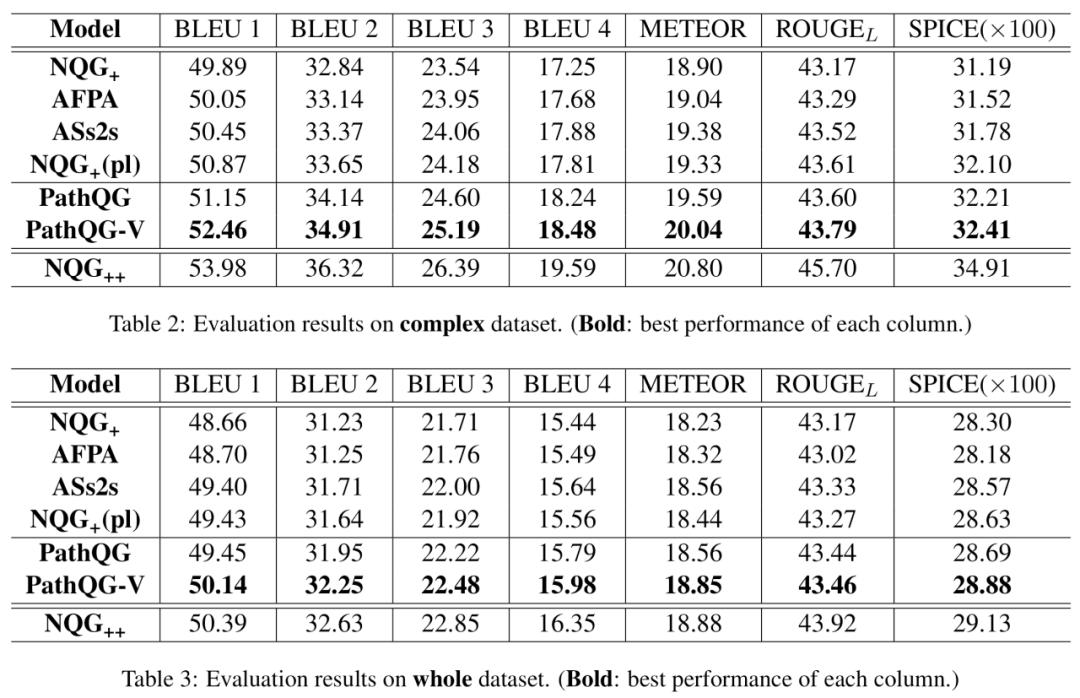
除了自動評估,我們還通過Amazon Mechanical Turk (AMT)進行了人工評估,分別從問題的流利度、正確性(和給定文本和答案一致)、信息量對不同模型生成的問題進行了兩兩比較,結果顯示我們的模型也取得不錯效果。
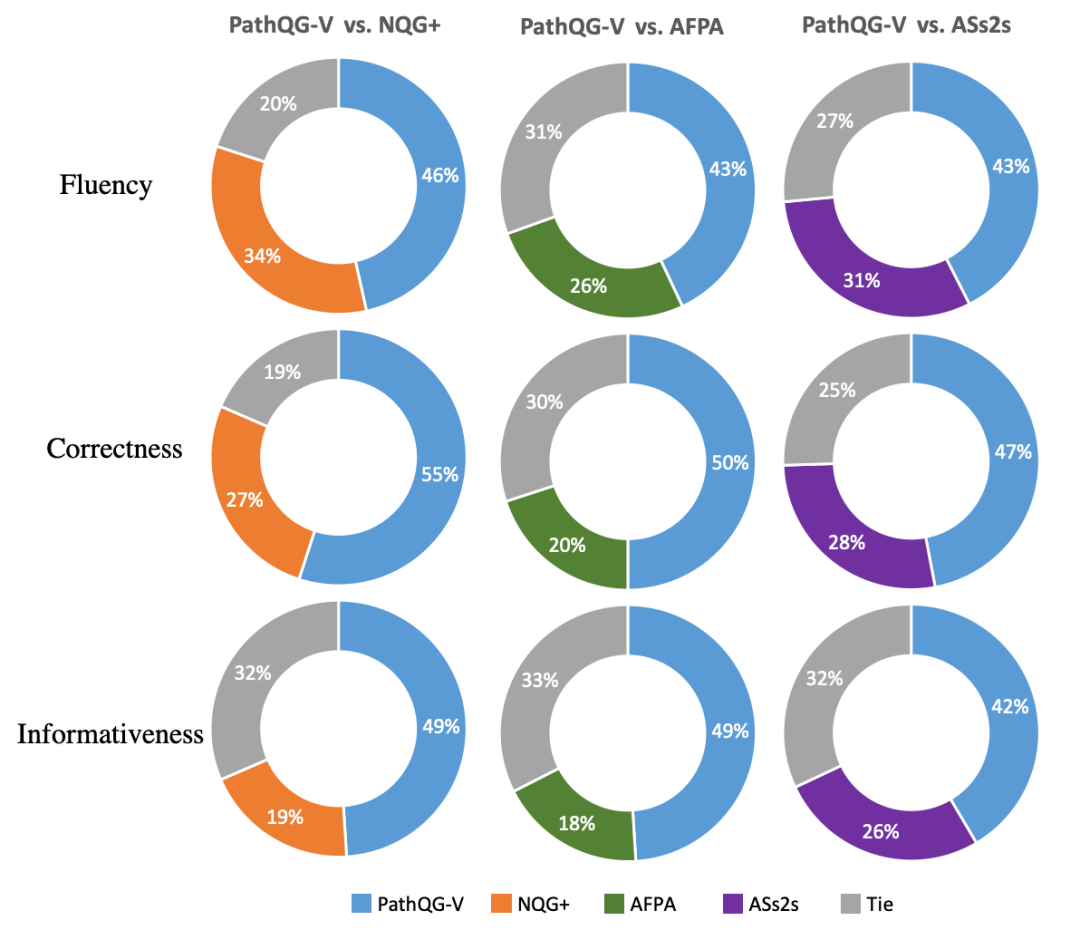
我們還通過對不同模型生成的問題和給定文本之間的重疊率進行比較,來評估生成問題和給定文本的相關性。
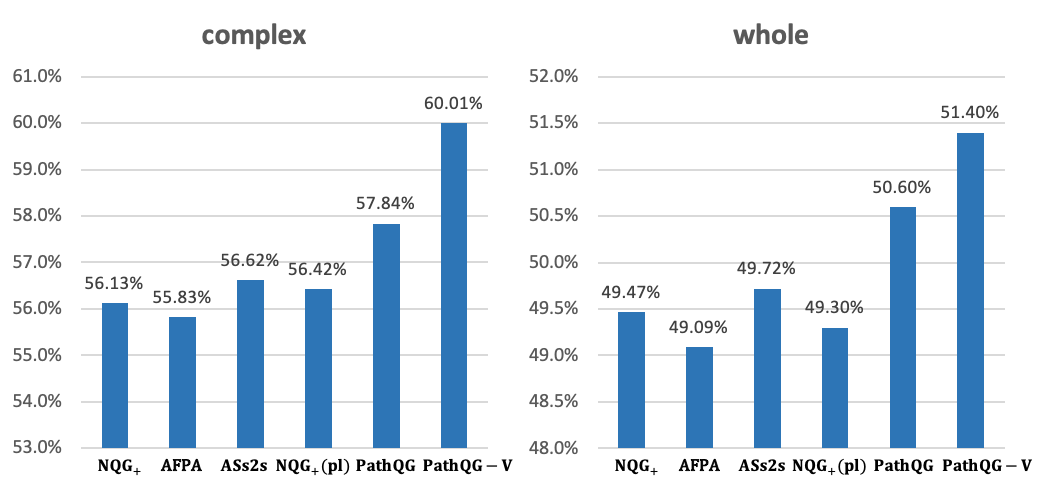
最后還進行了一些案例分析,可以看出相對模型NQG+,我們生成的問題更加和文本相關和有信息量。在第一個樣例中,我們生成的問題包含有特定信息“plymouth”和“late 18th”而*NQG+沒有,而在第二個例子中NQG+*生成的問題包含不相關的“swazi economye”而我們生成的和給定文本更一致。
總結
這篇文章中,我們通過知識圖譜對文本中的事實建模用于問題生成,并提出一個新任務:給定知識圖譜中的一條query path,生成對應的問題。我們提出先學習一個query representation來表示問題中可能涉及的事實,再生成問題,將這兩個模塊聯合進行訓練并提出一個變分模型提升問題的生成。我們通過自動構建知識圖譜并抽取出對應的query path構建了我們的實驗數據集,結果驗證了我們模型的有效性。
責任編輯:lq
-
編碼
+關注
關注
6文章
946瀏覽量
54873 -
生成器
+關注
關注
7文章
317瀏覽量
21053 -
數據集
+關注
關注
4文章
1208瀏覽量
24738
原文標題:【論文】PathQG: 基于事實的神經問題生成
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據手冊中的一些參數的數值有時畫一條橫線或者空著不填是什么意思?
三星自主研發知識圖譜技術,強化Galaxy AI用戶體驗與數據安全
請問LM311能準確的交截生成對應的PWM波形嗎?
革新未來智能版圖,神州數碼榮登IDC生成式AI圖譜

三星電子將收購英國知識圖譜技術初創企業
遲滯比較器的輸出為一條直線的原因
知識圖譜與大模型之間的關系
生成對抗網絡(GANs)的原理與應用案例
如何手擼一個自有知識庫的RAG系統
請問UCOSIII如何切換到新任務?
在使用spc5 stdio的時候生成對應的功能,main.c里面為什么沒有調用對應的接口?
利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(下)






 工商網監
工商網監
評論