 一文詳解GPU加速器的知識點
一文詳解GPU加速器的知識點
2020 年了,什么樣的GPU才是人工智能訓練的最佳選擇?工欲善其事必先利其器,今天我們就來了解一下,GPU加速器的各路神仙吧!
NVIDIA最新一代 GPU
NVIDIA A100 Tensor Core GPU 可針對 AI、數據分析和高性能計算 (HPC),在各種規模上實現出色的加速。作為 NVIDIA 數據中心平臺的引擎,A100 可以高效擴展,系統中可以集成數千個 A100 GPU,也可以利用 NVIDIA 多實例 GPU (MIG) 技術將每個 A100 劃分割為七個獨立的 GPU 實例,以加速各種規模的工作負載。
深度學習訓練NVIDIA A100 的第三代 Tensor Core 借助 Tensor 浮點運算 (TF32) 精度,可提供比上一代高 10 倍之多的性能,并且無需更改代碼,更能通過自動混合精度將性能進一步提升兩倍。大型 AI 模型只需在 A100 構成的集群上進行訓練幾十分鐘。
深度學習推理通過全系列精度(從 FP32、FP16、INT8 一直到 INT4)加速,實現了強大的多元化用途。MIG 技術支持多個網絡同時在單個 A100 GPU 運行,從而優化計算資源的利用率。在 A100 其他推理性能提升的基礎上,結構化稀疏支持將性能再提升兩倍。
高性能計算A100 引入了雙精度 Tensor Cores, 原本在 NVIDIA V100 Tensor Core GPU 上需要 10 小時的雙精度模擬作業如今只要 4 小時就能完成。HPC 應用還可以利用 A100 的 Tensor Core,將單精度矩陣乘法運算的吞吐量提高 10 倍之多。
數據分析搭載 A100 的加速服務器可以提供必要的計算能力,并利用第三代 NVLink 和 NVSwitch 1.6TB/s 的顯存帶寬和可擴展性,妥善應對這些龐大的工作負載。
企業級利用率A100 的 多實例 GPU (MIG) 功能使 GPU 加速的基礎架構利用率大幅提升,達到前所未有的水平。
技術參數
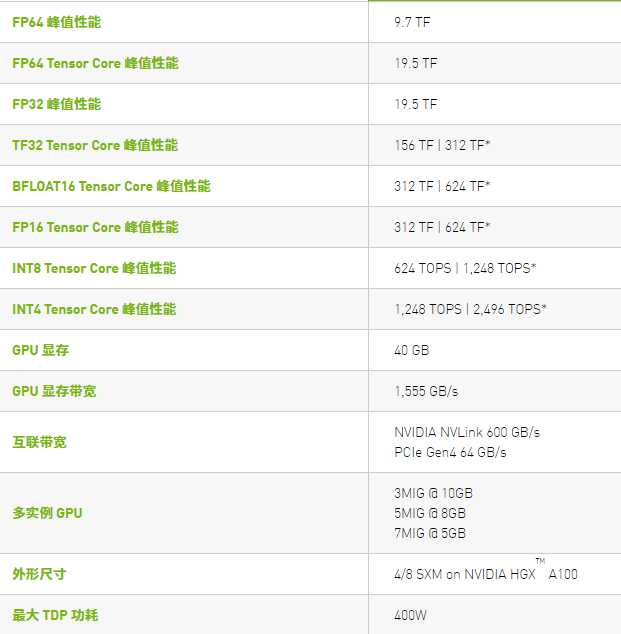
* 采用稀疏技術
構建數據中心必備的GPU
從語音識別到訓練虛擬個人助理和教會自動駕駛汽車自動駕駛,從天氣預報到發現藥物和發現新能源,數據科學家們正利用人工智能解決日益復雜的挑戰,使用大型計算系統來模擬和預測我們的世界。 NVIDIA V100 Tensor Core 是有史以來極其先進的數據中心 GPU,能加快 AI、高性能計算 (HPC) 和圖形技術的發展。其采用 NVIDIA Volta 架構,并帶有 16 GB 和 32GB 兩種配置,在單個 GPU 中即可提供高達 100 個 CPU 的性能。
人工智能訓練Tesla V100 擁有 640 個 Tensor 內核,是世界上第一個突破 100 萬億次 (TFLOPS) 深度學習性能障礙的 GPU。新一代 NVIDIA NVLink 以高達 300 GB/s 的速度連接多個 V100 GPU。
人工智能推理NVIDIA V100 GPU 可提供比 CPU 服務器高 30 倍的推理性能。
高性能計算 (HPC)通過在一個統一架構內搭配使用 NVIDIA CUDA 內核和 Tensor 內核,配備 NVIDIA V100 GPU 的單臺服務器可以取代數百臺僅配備通用 CPU 的服務器來處理傳統的高性能計算和人工智能工作負載。
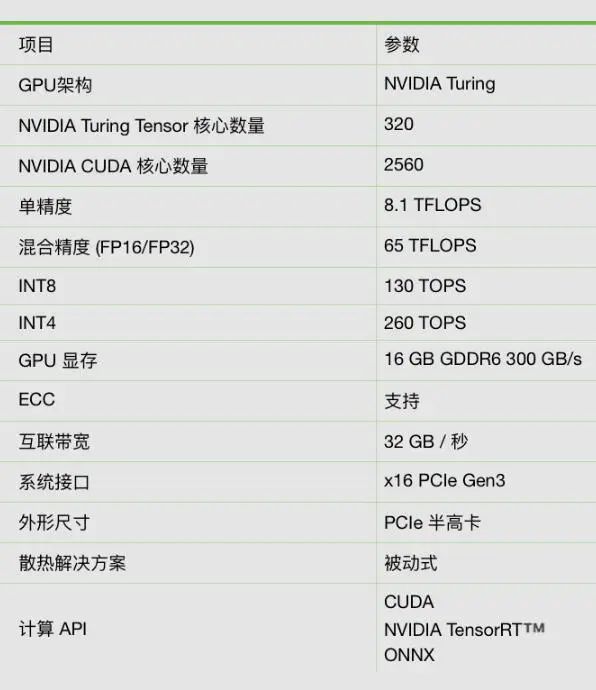
技術參數

推理加速的神器
NVIDIA Tesla T4 Tensor Core GPU是世界上極其先進的推理加速器。搭載 NVIDIA Turing Tensor 核心的 T4 提供革命性的多精度推理性能,以加速現代人工智能的各種應用。T4 封裝在節能的小型 70 瓦 PCIe 中,可針對橫向擴展服務器進行優化,并且旨在實時提供極其先進的推理。
極具突破性的推理性能NVIDIA T4 引入革命性的 Turing Tensor 核心技術,具備人工智能推理的多精度計算性能。從 FP32 到 FP16 再到 INT8,以及 INT4 精度,T4 的性能比 CPU 高出 40 倍。
先進的實時推理NVIDIA T4 可提供優于 40 倍的低延時高吞吐量,進而可以實時滿足更多的請求。
視頻轉碼性能NVIDIA T4 專用的硬件轉碼引擎將解碼性能提升至上一代 GPU 的兩倍。T4 可以解碼多達 38 個全高清視頻流。
技術參數
適用于桌面的個人工作站
一臺DGX工作站就可以提供相當于 400 個 CPU 的計算能力,以低功耗、水冷靜音而著稱。 過去,硬件及軟件的購置、集成和測試可能就要花一個月或更長時間。此外, 優化框架、庫及驅動程序還需掌握更多專業知識, 付出更多努力。這些用在系統集成和軟件 工程上的寶貴時間和金錢,現在可以用于訓練和實驗。
專為您辦公室設計的超級計算機為辦公室及安靜場所設計,噪音僅為其他工作站的十分之一 。
更快開始使用深度學習只需插入和接通電源,這種部署簡單直觀。這個集成軟硬件的解決方案可讓您將更多時間專注探索發現而不是組裝組件上。
從桌面到數據中心,顯著提升工作效率DGX工作站可以節省價值幾十萬元的工程時間,避免因等待開源框架的穩定版本而導致工作效率降低。
相較目前最快的 GPU 工作站提速2倍基于 4 個 NVIDIA V100 加速器構建的工作站, 同時采用了下一代 NVLink 以及全新 Tensor 核心架構等創新技術 。DGX 工作站相較現今最快的 GPU 工作站,深度學習訓練性能提升了 2 倍 ,具備 480 TFLOPS 的水冷性能和 FP16 精度。
技術參數

開箱即可用的解決方案
NVIDIA DGX-1 通過開箱即用的解決方案。借助 DGX-1,再加上集成式 NVIDIA 深度學習軟件堆棧,您只需開啟電源,即可開始工作。
輕松取得工作成果借助 NVIDIA DGX-1提高研究效率,簡化工作流程并與團隊開展協作。
革命性的 AI 性能DGX-1 憑借 NVIDIA GPU Cloud 深度學習軟件堆棧和當今流行的技術框架,將訓練速度提升高達三倍。
投資保護NVIDIA 的企業級支持讓您無需耗費時間對硬件和開源軟件進行問題排查,節省調試和優化時間。
技術參數

AI企業的必要基礎設施
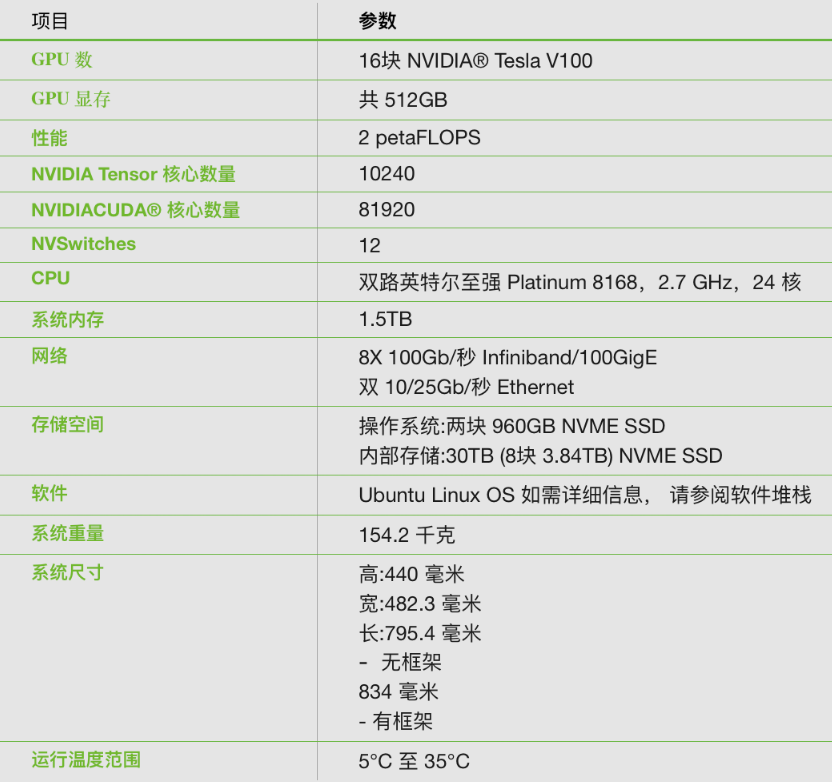
NVIDIA DGX-2 是世界上第一個 2-petaFLOPS 系統,配備 16 塊極為先進的 GPU,可以在單個節點訓練 4 倍 規模的模型。與傳統的 x86 架構相比,DGX-2 訓練 ResNet-50 的性能相當于 300 臺配備雙路英特爾至強 Gold CPU 服務器的性能。
非同一般的計算能力造就出眾的訓練性能可在單一節點上訓練規模擴大 4 倍的模型,而且其性能達到 8 GPU 系統的 10 倍。
革命性的人工智能網絡架構NVIDIA 首款 2 petaFLOPS GPU 加速器采用的正是這種創新技術,其 GPU 間帶寬高達 2.4 TB/s,性能比前代系統提升了 24 倍,并且問題解決速度提高了 5 倍。
將人工智能規模提升至全新水平的最快途徑憑借用于構建大型深度學習計算集群的靈活網絡選項,再結合可在共享基礎設施環境中改進用戶和工作負載隔離的安全多租戶功能。
始終運行的企業級人工智能基礎設施DGX-2 專為 RAS 而打造,可以減少計劃外停機時間,簡化可維護性,并保持運行連續性。
技術參數
目前全球最先進的 GPU 系統
NVIDIA DGX A100 為全球首款 5 petaFLOPS AI 系統提供超高的計算密度、性能和靈活性。采用全球超強大的加速器 NVIDIA A100 Tensor Core GPU,可讓企業將深度學習訓練、推理和分析整合至一個易于部署的統一 AI 基礎架構中,該基礎架構具備直接聯系 NVIDIA AI 專家的功能。
各種 AI 工作負載的通用系統 NVIDIA DGX A100 是適用于所有 AI 基礎架構(包括分析、訓練、推理基礎架構)的通用系統。
DGXperts:集中獲取 AI 專業知識 NVIDIA DGXperts 是一個擁有 14000 多位 AI 專業人士的全球團隊,能夠幫助您更大限度地提升 DGX 投資價值。
更快的加速體驗 集成八塊 A100 GPU,可針對 NVIDIA CUDA-X 軟件和整套端到端 NVIDIA 數據中心解決方案進行全面優化。
卓越的數據中心可擴展性 NVIDIA DGX A100 內置 Mellanox ConnectX-6 VPI HDR InfiniBand 和以太網適配器,其雙向帶寬峰值為 450Gb/s。
技術參數

眾所周知,如果將英偉達GPU比喻成通往人工智能路上的交通工具的話,選對了方式你坐的可能就是火箭,只需要花費一小時即可完成幾百個T的數據研究,選錯了,那可能就是“11”路公交車。
責任編輯人:CC
-
加速器
+關注
關注
2文章
796瀏覽量
37840 -
gpu
+關注
關注
28文章
4729瀏覽量
128890
原文標題:關注 | GPU加速器知識知多少?
文章出處:【微信號:wc_ysj,微信公眾號:旺材芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
《CST Studio Suite 2024 GPU加速計算指南》
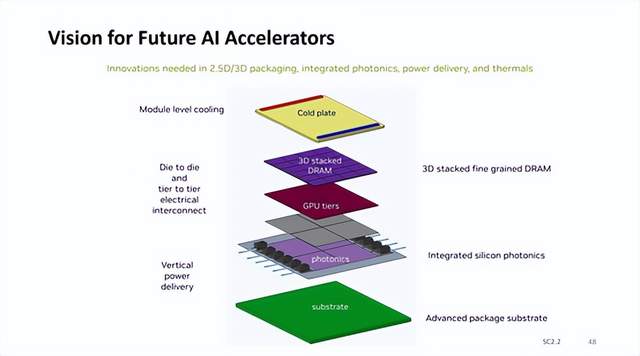
英偉達AI加速器新藍圖:集成硅光子I/O,3D垂直堆疊 DRAM 內存

接口測試理論、疑問收錄與擴展相關知識點
什么是神經網絡加速器?它有哪些特點?

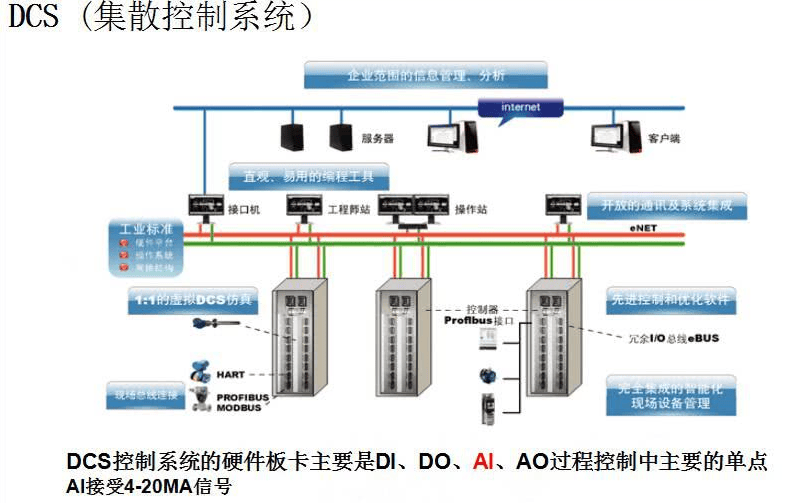
一篇搞定DCS系統相關知識點
瑞薩發布下一代動態可重構人工智能處理器加速器
NVIDIA將在今年第二季度發布Blackwell架構的新一代GPU加速器“B100”

家居智能化,推動AI加速器的發展
回旋加速器原理 回旋加速器的影響因素
回旋加速器中粒子的最大動能與什么有關
Wakefield激光加速器 - 能量里程碑






 工商網監
工商網監
評論