 Mobileye公布最新自動駕駛方案
Mobileye公布最新自動駕駛方案
2020年9月24日,吉利汽車與Mobileye正式簽約,將使用EyeQ5做自動駕駛,同時,Mobileye也公布了最新的自動駕駛方案。
11個攝像頭中,4個魚眼短距離的泊車用攝像頭,7個遠距離自動駕駛用攝像頭,包括前向6個,后向1個。與EyeQ4最大不同之處在于三目攝像頭被雙目取代了,三目攝像頭實際是單目攝像頭在不同FOV上的擴展,特斯拉和國內新興造車的輔助駕駛或自動駕駛方案都是采用三目。而Mobileye這次沒有用三目,擋風玻璃后視鏡位置是兩個單目攝像頭,FOV分別是28度和120度。
考慮到兩個攝像頭之間的距離,顯然不是奔馳那樣傳統的Stereo Camera立體雙目攝像頭,并且根據這兩個攝像頭的FOV看,也不是主攝像頭。倒車鏡上則有一個FOV為100度的攝像頭,A柱下方還有一個側向的FOV為100度的攝像頭。 實際上Mobileye的前部六個攝像頭(可能后部的攝像頭也參與了)構成了SfM(Structurefrom Motion)。Stereo Vision(立體視覺)SfM比較稀疏,再進一步稠密化就是Multi ViewStereo,即MVS。雖然這七個攝像頭都是單目,但他們是合在一起工作的,應該叫多目立體視覺。 Mobileye有關SfM的專利主要有三個,一個是2014年的DenseStructure from motion,另一個是2017年的StereoAuto-Calibration From Structure-from-motion,還有一個是2020年的COMFORTRESPONSIBILITY SENSITIVITY SAFETY MODEL(長達197頁),其中雖未提及SfM具體算法,但描述了SfM Stereo Image的處理流程。

Mobileye的Stereo Image處理流程
自動駕駛領域,感知部分的任務就是建立一個準確的3D環境模型。深度學習加單目三目是無法完成這個任務的。單目和三目攝像頭的致命缺陷就是目標識別(分類)和探測(Detection)是一體的,無法分割的。
必須先識別才能探測得知目標的信息,而深度學習肯定會出現漏檢,也就是說3D模型有缺失,因為深度學習的認知范圍來自其數據集,而數據集是有限的,不可能窮舉所有類型,因此深度學習容易出現漏檢而忽略前方障礙物,如果無法識別目標,單目就無法獲得距離信息,系統就會認為前方障礙物不存在危險,不做任何減速,特斯拉多次事故大多都是這個原因。 傳統算法,則可能無法識別前方障礙物,但依然能夠獲知前方障礙物的信息,能夠最大限度地保證安全。當然這需要傳感器配合,激光雷達和雙目立體視覺都是以傳統算法為核心(因為它不需要識別目標,自然就不需要深度學習,當然你也可以用深度學習處理激光雷達數據,但不是為了識別目標)。
其次,深度學習是一個典型的黑盒子系統,汽車上任何事物都必須具備可解釋性和確定性,深度學習并不具備。傳統車廠盡量避免在直接有關汽車安全領域使用深度學習,當然,深度學習是識別目標準確度最高的方法,不得不用。大部分車廠會堅持使用可解釋的具備確定性的傳統圖像算法,直到深度學習變成白盒子。
上圖為Waymo深度學習科學家drago anguelov 2019年2月在MIT在講述無人車感知系統時,坦承機器學習的不足,單目系統漏檢無法避免,特別是在交通復雜的中國。深度學習的漏檢和算力沒有任何關系,再強大的算力也無法避免漏檢,也就無法避免事故。 若要解決漏檢這個問題,或者說構建一個沒有缺失的3D環境模型就必須用將識別與探測分離,無需識別也可以探測目標的信息,忘掉深度學習,傳統的做法是激光雷達和雙目立體視覺。但激光雷達商業化,車載化一直進展緩慢,雙目的缺陷是立體匹配算法門檻太高,在線標定非常困難,只有奔馳、斯巴魯、路虎和雷克薩斯運用的比較好。寶馬雖然高端車型使用雙目,但實測結果并不理想,寶馬如今也部分放棄了雙目路線,電動SUV領域還未放棄雙目。
除了激光雷達和雙目立體視覺外還有一種方法,這就是今天要說的主角:SfM。在雙目立體視覺中,兩個相機之間的相對位姿是通過標定靶精確標定出來的,在重建時直接使用三角法進行計算;而在SfM中該相對位姿是需要在重建之前先計算的。雙目必須兩個鏡頭輸入兩張照片雙目重建方法,SfM和MVS屬于單目重建多目立體視覺,輸入的是一系列同一物體和場景的多視圖。SfM得到的通常是稀疏點云,而經過MVS處理極線約束后可建立稠密點云,可以媲美激光雷達點云,也就是Mobileye所說的Vidar。
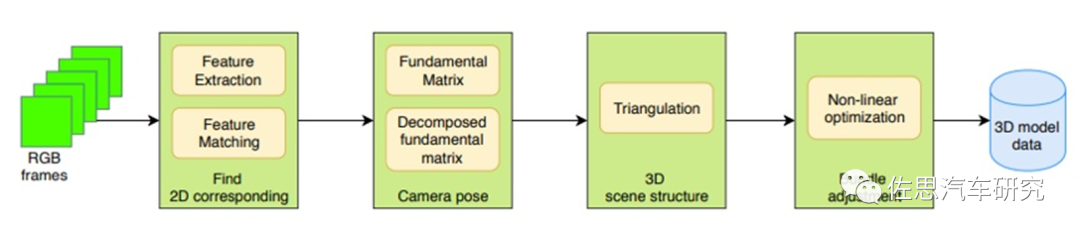
SfM的框架圖
Structure fromMotion(SfM)是一個估計相機參數及三維點位置的問題。一個基本的SfM pipeline可以描述為:對每張2維圖片檢測特征點(feature point),對每對圖片中的特征點進行匹配,只保留滿足幾何約束的匹配,最后執行一個迭代式的、魯棒的SfM方法來恢復攝像機的內參(intrinsic parameter)和外參(extrinsic parameter)。并由三角化得到三維點坐標,然后使用Bundle Adjustment進行優化。常見的SfM方法可以分為增量式(incremental/sequentialSfM),全局式(global SfM),混合式(hybrid SfM),層次式(hierarchica SfM)。這些都是傳統OpenCV算法,跟深度學習無關,而如今,簡單易學深度學習橫掃一切,復雜難學的傳統算法人才非常稀缺,導致SfM幾乎沒有商業化的例子。
SfM最初是假定相機圍繞靜態場景運動,實際就是相機獲取在目標不同位置的圖像,因此可以用放置多個相機取代運動的單一相機。為了避免干擾,28度FOV與兩個100度FOV的攝像頭構成SfM系統。SfM通常針對靜止目標(古建筑物居多),移動目標難度極大,干擾因素比較多,大部分人都望而卻步。 在MVS重建精準3D尺寸模型領域有個難點,即尺度因子不確定性,這個可以用其他傳感器如高精度IMU獲取真實尺寸校準,但高精度IMU太貴了,還有一種方法就是DNN。也可以看作用先驗尺寸數據推算實際尺寸。當然也有傳統的非深度學習方法。
上圖即Mobileye的VIDAR,基于比較簡單的神經網絡DNN,對算力要求遠低于圖像識別分類的CNN。基于深度學習的3D點云和mesh重構是較難以計算的,因為深度學習一個物體完整的架構需要大量數據的支持。傳統的3D模型是由vertices和mesh組成的,因此不一樣的數據尺寸data size造成了訓練的困難。所以后續大家都用voxelization(Voxel)的方法把所有CAD model轉成binary voxel模式(有值為1,空缺為0)這樣保證了每個模型都是相同的大小。利用一個標準的CNN結構對原始input image進行編碼,然后用Deconv進行解碼,最后用3D LSTM的每個單元重構output voxel。3D voxel是三維的,它的精度成指數增長,所以它的計算相對復雜。
這個多目立體視覺制造出來的VIDAR與真實的Lidar當然有一定差距,與傳統的雙目立體視覺相比精度也有一定差距,畢竟雙目立體視覺發展了20年,不過多目比雙目覆蓋面更廣。
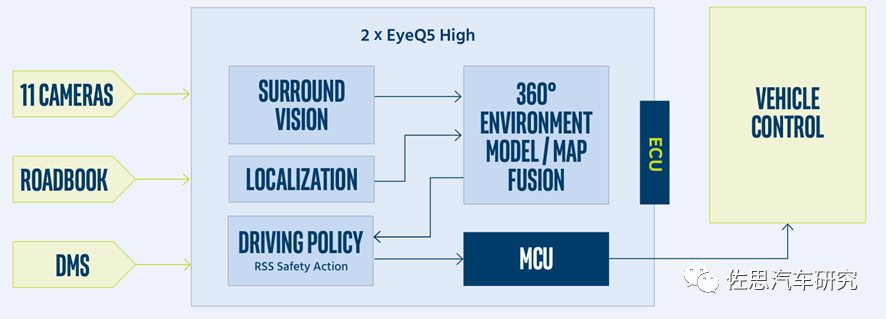
Mobileye SuperVision的系統框架圖
在2020年Mobileye的專利里也提到了雙處理器設置,第一個視覺處理器檢測道路標識、交通標識,并根絕ROADBOOK做定位,第二個視覺處理器則處理SfM,并發送到第一個視覺處理器,構建起一個帶有完整道路結構的3D環境模型。 和英偉達、特斯拉以及一堆視覺加速器廠家比,Mobileye并不擅長硬件高算力,EyeQ5的算力只有24TOPS,低于英偉達Xavier的32TOPS,2022年即將量產的Orin高達200TOPS。
Mobileye擅長的是算法,SfM和MVS將筑起一道算法護城河,并借此提高安全。EyeQ5預計在2021年3月量產,盡管其算力與許多國內初創廠家相比都低,但高算力不代表安全,EyeQ5依然獲得吉利、寶馬等4個大整車廠的訂單。 加入佐思數據平臺會員,可獲得Mobileye立體視覺專利完整版。
原文標題:忘掉單目和三目吧,Mobileye轉向立體視覺
文章出處:【微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
處理器
+關注
關注
68文章
19259瀏覽量
229653 -
攝像頭
+關注
關注
59文章
4836瀏覽量
95600 -
激光雷達
+關注
關注
968文章
3967瀏覽量
189829 -
自動駕駛
+關注
關注
784文章
13784瀏覽量
166397
原文標題:忘掉單目和三目吧,Mobileye轉向立體視覺
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Lyft攜手Mobileye推動自動駕駛出行服務規模化發展


Mobileye端到端自動駕駛解決方案的深度解析








 工商網監
工商網監
評論