 人工智能該如何建立起自身可信度?
人工智能該如何建立起自身可信度?
人工智能(AI)往往被視為一種暗箱實踐,即人們并不關注技術本身的運作方式,只強調其能夠提供看似正確的結果。在某些情況下,這種效果就已經可以滿足需求,因為大多數時候我們都更關注結果,而非結果的具體實現方式。
遺憾的是,將AI視為暗箱過程會產生信任與可靠性等問題。從純技術的角度來看,這也導致我們難以分析或解決AI模型中存在的問題。
在本文中,我們將共同了解其中的部分潛在問題以及幾種解決方案思路。
AI是什么?
不少企業已經將人工智能(AI)元素納入自家產品。雖然有些“AI”表述只是虛假的營銷策略,但也確實有不少產品開始使用AI及機器學習(ML)技術實現自我提升。
簡而言之,AI是指一切能夠表現出智能行為的計算機系統。在本文的語境下,智能代表著計算機在學習、理解或者概念總結等層面的飛躍式進步。
當前,AI技術最常見的實現形式為機器學習,其中由計算機算法學習并識別數據中的模式。機器學習大致分為三類:
監督學習:即使用已知數據進行模型訓練。這有點像給孩子們看最簡單的看圖識字教材。這類ML也是大家最常接觸到的實現形式,但其有著一個致命缺點:只有具備大量可信且經過正確標記的訓練數據,才能建立起相關模型。
無監督學習:模型自行在數據中查找模式。手機導航軟件使用的就是這種學習方式,特別適合我們對數據一無所知的情況。目前業界往往使用無監督學習從數據中識別出可能具有現實意義的重要聚類。
強化學習:模型在每次正確執行時都會得到獎勵。因為這是一種典型的“實驗試錯”學習方法。如果我們初期只有少量數據,那么這種ML方法將表現得尤為強大。它的出現,直接令持續學習模型成為可能,即模型在接觸到新數據后會不斷適應及發展,從而保證自身永不過時。
但這些方法都面臨著同一個問題,我們無法理解學習后生成的最終模型。換言之,人工智能無法實現人性化。
信任問題
暗箱式AI系統大多屬于由機器經過自學過程建立起模型。但由于無法理解系統得出結論的過程,我們就很難理解模型給出特定結論的理由,或者對該結論缺乏信心。我們無法詢問模型為什么會這么判斷,只能拿結果跟自己的期望進行比較。
如果不理解AI模型的起效原理,我們又怎么能相信模型會永遠正確?
結果就是,這種不可理解性同無數反烏托邦科幻作品映射起來,讓AI成了恐怖神秘的代名詞。更糟糕的是,不少AI模型確實表現出嚴重的偏差,這也令信任危機被進一步激化。
偏差或者說偏見,一直植根于人類的思想意識當中,現在它也開始成為AI技術無法回避的大難題。因為系統只能從過往的情況中學習經驗,而這些可能并不足以指導模型做出面向未來的正確選擇。
以AI模型在犯罪預測中的應用為例,這些模型會使用以往犯罪統計數據來確定哪些地區的犯罪率比較高。執法部門則調整巡邏路線以向這些地區集中警力資源。但人們普遍質疑,使用這類數據本身就是在加強偏見,或者潛在地將相關性混淆為因果性。
例如,隨著新冠疫情的肆虐,美國各大主要城市的暴力犯罪率開始顯著下降;但在某些司法管轄區內,汽車盜竊及其他劫掠案件卻有所增加。普通人可能會將這些變化與全國范圍內的社交隔離合理聯系起來,但預測性警務模型卻有可能錯誤地將犯罪數量及逮捕率的降低解釋為穩定性與治安水平的提升。
目前,人工智能中存在多種形式的偏見。以人臉識別軟件為例,研究表明包含“人口統計學偏見”的算法會根據對象的年齡、性別或種族做出準確率波動極大的判斷。
有時,數據科學家在執行特征工程以嘗試清洗源數據時,同樣會引發偏差/偏見問題,導致其中某些微妙但卻極為重要的特征意外丟失。
影響最大的偏見甚至可能引發社會層面的問題。例如,廣告算法會根據人口統計數據定期投放廣告,從而將對于年齡、性別、種族、宗教或社會經濟等因素的偏見永久留存在模型之內。AI技術在招聘應用中也暴露出了類似的缺陷。
當然,這一切都源自人類自己引發的原始偏見。但是,我們該如何在AI模型中發現這些偏見并將其清除出去?
可解釋AI
為了增加對AI系統的信任度,AI研究人員正在探索構建可解釋AI(XAI)的可能性,希望借此實現AI方案的人性化。
XAI能夠避免我們在暗箱模型中難以識別的種種問題。例如,2017年研究人員的報告稱發現了一項AI作弊問題。該AI模型在訓練之后能夠成功識別出馬匹的圖像,相當于對經典狗/貓識別能力的變體。但事實證明,AI學會的實際上是識別與馬匹圖片相關的特定版權標注。
為了實現XAI,我們需要觀察并理解模型內部的整個運作過程。這項探索本身已經構成了理論計算機科學中的一大分支,其困難程度可能也遠超大家的想象。
比較簡單的機器學習算法當然相對易于解釋,但神經網絡則復雜得多。即使是包括分層相關性傳播(LRP)在內的各類最新技術,也只能顯示哪些輸入對于決策制定更為重要。因此,研究人員的注意力開始轉向本地可解釋性目標,希望借此對模型做出的某些特定預測做出解釋。
AI模型為什么難以理解?
目前,大多數ML模型基于人工神經元。人工神經元(或稱感知器)使用傳遞函數對一個或多個加權輸入進行組合。以此為基礎,激活函數將使用閾值以決定是否觸發。這種方法,實際上限制了神經元在人腦中的工作方式。
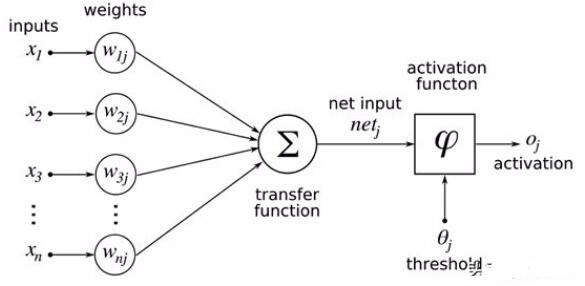
作為一種常見的ML模型,神經網絡由多層人工神經元組成。輸入層與重要特征擁有相同的輸入數量,同時輔以大量隱藏層。最后,輸出層也將擁有與重要特征相同的輸出數量。
我們以最簡單的應用場景為例,考慮ML模型如果根據今天是星期幾及是否屬于假期來預測您的起床時間。
在隨機分配權重的情況下,模型會生成錯誤的結果,即我們周三需要在上午9點起床。
我們當然不可能以手動方式為每個人工神經元設置確切的權重。相反,我們需要使用所謂反向傳播過程,算法將在模型中反向運作,借此調整網絡的權重與偏差,力求將預測輸出與預期輸出間的差異控制在最小范圍。在調整之后,結果是周三早上應該7點起床。
信任與道德
技術信任問題正變得愈發重要,畢竟我們已經在嘗試使用AI診斷癌癥、識別人群中的通緝犯并做出雇用/解雇決策。如果無法實現AI人性化,又怎么能要求人們向其給予信任呢?如果沒有這種信任,以符合道德的方式加以使用更是癡人說夢。
對于這個重要問題,歐盟已經通過一套關于可信AI的道德準則,針對AI是否符合道德及具備可信度設置了七項測試:
人類代理與監督:AI系統不可在人類不具備最終決定權的情況下做出決策。
技術的健壯性與安全性:在使用AI技術之前,必須明確其是否可靠,包括具備故障保護能力且不會被黑客入侵。
隱私與數據治理:AI模型往往需要處理個人數據,例如通過醫學造影圖像診斷疾病。這意味著數據隱私將非常重要。
透明度:AI模型應該具備人類可解釋的基本屬性。
多樣性、非歧視性與公平性:主要涉及我們前文討論過的偏見問題。
環境與社會福祉:在這里,準則制定者們希望消除人們對于AI技術發展造成反烏托邦式未來的擔憂。
問責制度:必須建立起獨立的監督或監控制度。
當然,指南也強調,必須以合法方式使用AI技術。
AI的人性化之路
本文關注的重點只有一個:人工智能該如何實現人性化,從而切實建立起自身可信度。
人類很難相信自己無法理解的機器,并最終阻礙了我們從這一創新技術中切實受益。
這個問題在軟件測試自動化領域表現得尤其明顯,因為此類系統的意義就是在應用方案發布之前找到其中存在的潛在問題。如果不了解具體流程,我們要如何確定測試結果的正確性?如果做出了錯誤決定,該怎么辦?如果AI系統遺漏了某些問題,我們該如何發現或者做出響應?
為了解決這個難題,必須將ML算法與測試體系結合起來,實現決策制定與相應數據間關聯關系的可視化。只有這樣,我們才能徹底告別暗箱式AI。這是一項踏踏實實的工作,沒有奇跡、沒有魔法,可以依賴的只有不懈努力與對機器學習美好未來的憧憬。
責任編輯:YYX
-
AI
+關注
關注
87文章
30763瀏覽量
268907 -
人工智能
+關注
關注
1791文章
47208瀏覽量
238290
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論