 一篇了解 Linux 操作系統需要仔細研讀的一篇文章
一篇了解 Linux 操作系統需要仔細研讀的一篇文章
Linux 簡介
UNIX 是一個交互式系統,用于同時處理多進程和多用戶同時在線。為什么要說 UNIX,那是因為 Linux 是由 UNIX 發展而來的,UNIX 是由程序員設計,它的主要服務對象也是程序員。Linux 繼承了 UNIX 的設計目標。從智能手機到汽車,超級計算機和家用電器,從家用臺式機到企業服務器,Linux 操作系統無處不在。
大多數程序員都喜歡讓系統盡量簡單,優雅并具有一致性。舉個例子,從最底層的角度來講,一個文件應該只是一個字節集合。為了實現順序存取、隨機存取、按鍵存取、遠程存取只能是妨礙你的工作。相同的,如果命令
lsA*
意味著只列出以 A 為開頭的所有文件,那么命令
rmA*
應該會移除所有以 A 為開頭的文件而不是只刪除文件名是A*的文件。這個特性也是最小吃驚原則(principle of least surprise)
?最小吃驚原則一半常用于用戶界面和軟件設計。它的原型是:該功能或者特征應該符合用戶的預期,不應該使用戶感到驚訝和震驚。?
一些有經驗的程序員通常希望系統具有較強的功能性和靈活性。設計 Linux 的一個基本目標是每個應用程序只做一件事情并把他做好。所以編譯器只負責編譯的工作,編譯器不會產生列表,因為有其他應用比編譯器做的更好。
很多人都不喜歡冗余,為什么在 cp 就能描述清楚你想干什么時候還使用 copy?這完全是在浪費寶貴的hacking time。為了從文件中提取所有包含字符串ard的行,Linux 程序員應該輸入
grepardf
Linux 接口
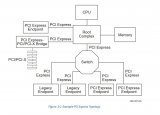
Linux 系統是一種金字塔模型的系統,如下所示
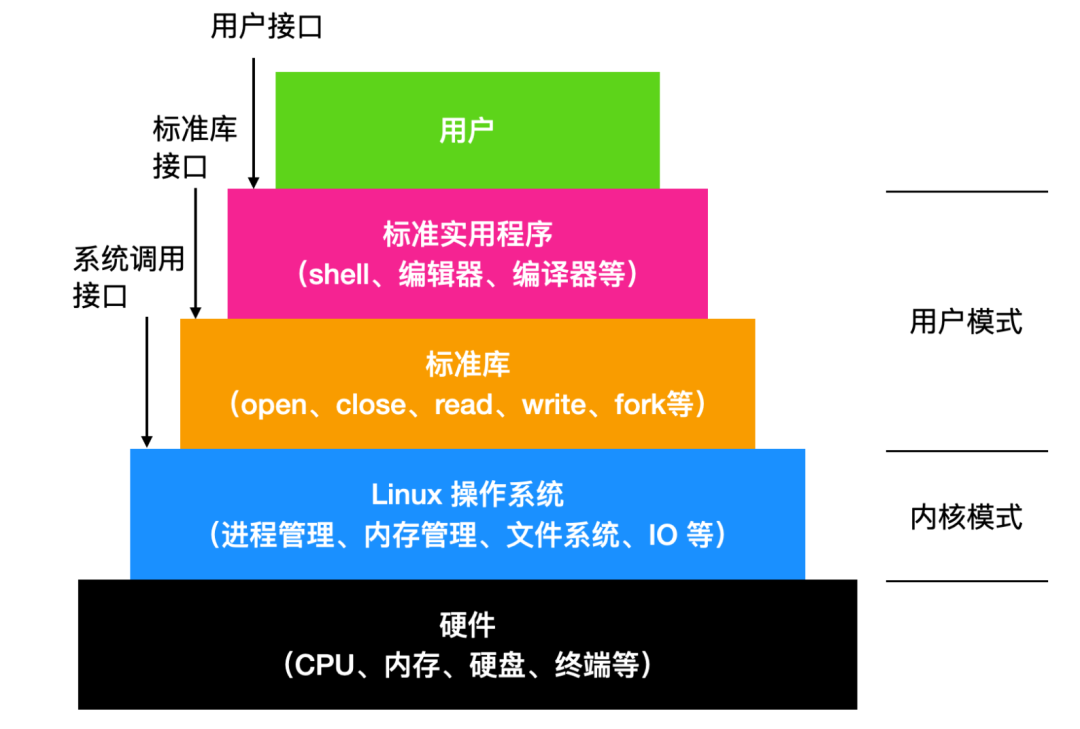
應用程序發起系統調用把參數放在寄存器中(有時候放在棧中),并發出trap系統陷入指令切換用戶態至內核態。因為不能直接在 C 中編寫 trap 指令,因此 C 提供了一個庫,庫中的函數對應著系統調用。有些函數是使用匯編編寫的,但是能夠從 C 中調用。每個函數首先把參數放在合適的位置然后執行系統調用指令。因此如果你想要執行 read 系統調用的話,C 程序會調用 read 函數庫來執行。這里順便提一下,是由 POSIX 指定的庫接口而不是系統調用接口。也就是說,POSIX 會告訴一個標準系統應該提供哪些庫過程,它們的參數是什么,它們必須做什么以及它們必須返回什么結果。
除了操作系統和系統調用庫外,Linux 操作系統還要提供一些標準程序,比如文本編輯器、編譯器、文件操作工具等。直接和用戶打交道的是上面這些應用程序。因此我們可以說 Linux 具有三種不同的接口:「系統調用接口、庫函數接口和應用程序接口」
Linux 中的GUI(Graphical User Interface)和 UNIX 中的非常相似,這種 GUI 創建一個桌面環境,包括窗口、目標和文件夾、工具欄和文件拖拽功能。一個完整的 GUI 還包括窗口管理器以及各種應用程序。
Linux 上的 GUI 由 X 窗口支持,主要組成部分是 X 服務器、控制鍵盤、鼠標、顯示器等。當在 Linux 上使用圖形界面時,用戶可以通過鼠標點擊運行程序或者打開文件,通過拖拽將文件進行復制等。
Linux 組成部分
事實上,Linux 操作系統可以由下面這幾部分構成
引導程序(Bootloader):引導程序是管理計算機啟動過程的軟件,對于大多數用戶而言,只是彈出一個屏幕,但其實內部操作系統做了很多事情
內核(Kernel):內核是操作系統的核心,負責管理 CPU、內存和外圍設備等。
初始化系統(Init System):這是一個引導用戶空間并負責控制守護程序的子系統。一旦從引導加載程序移交了初始引導,它就是用于管理引導過程的初始化系統。
后臺進程(Daemon):后臺進程顧名思義就是在后臺運行的程序,比如打印、聲音、調度等,它們可以在引導過程中啟動,也可以在登錄桌面后啟動
圖形服務器(Graphical server):這是在監視器上顯示圖形的子系統。通常將其稱為 X 服務器或 X。
桌面環境(Desktop environment):這是用戶與之實際交互的部分,有很多桌面環境可供選擇,每個桌面環境都包含內置應用程序,比如文件管理器、Web 瀏覽器、游戲等
應用程序(Applications):桌面環境不提供完整的應用程序,就像 Windows 和 macOS 一樣,Linux 提供了成千上萬個可以輕松找到并安裝的高質量軟件。
Shell
盡管 Linux 應用程序提供了 GUI ,但是大部分程序員仍偏好于使用命令行(command-line interface),稱為shell。用戶通常在 GUI 中啟動一個 shell 窗口然后就在 shell 窗口下進行工作。
shell 命令行使用速度快、功能更強大、而且易于擴展、并且不會帶來肢體重復性勞損(RSI)。
下面會介紹一些最簡單的 bash shell。當 shell 啟動時,它首先進行初始化,在屏幕上輸出一個提示符(prompt),通常是一個百分號或者美元符號,等待用戶輸入

等用戶輸入一個命令后,shell 提取其中的第一個詞,這里的詞指的是被空格或制表符分隔開的一連串字符。假定這個詞是將要運行程序的程序名,那么就會搜索這個程序,如果找到了這個程序就會運行它。然后 shell 會將自己掛起直到程序運行完畢,之后再嘗試讀入下一條指令。shell 也是一個普通的用戶程序。它的主要功能就是讀取用戶的輸入和顯示計算的輸出。shell 命令中可以包含參數,它們作為字符串傳遞給所調用的程序。比如
cpsrcdest
會調用 cp 應用程序并包含兩個參數src和dest。這個程序會解釋第一個參數是一個已經存在的文件名,然后創建一個該文件的副本,名稱為 dest。
并不是所有的參數都是文件名,比如下面
head-20file
第一個參數 -20,會告訴 head 應用程序打印文件的前 20 行,而不是默認的 10 行。控制命令操作或者指定可選值的參數稱為標志(flag),按照慣例標志應該使用-來表示。這個符號是必要的,比如
head20file
是一個完全合法的命令,它會告訴 head 程序輸出文件名為 20 的文件的前 10 行,然后輸出文件名為 file 文件的前 10 行。Linux 操作系統可以接受一個或多個參數。
為了更容易的指定多個文件名,shell 支持魔法字符(magic character),也被稱為通配符(wild cards)。比如,*可以匹配一個或者多個可能的字符串
ls*.c
告訴 ls 列舉出所有文件名以.c結束的文件。如果同時存在多個文件,則會在后面進行并列。
另一個通配符是問號,負責匹配任意一個字符。一組在中括號中的字符可以表示其中任意一個,因此
ls[abc]*
會列舉出所有以a、b或者c開頭的文件。
shell 應用程序不一定通過終端進行輸入和輸出。shell 啟動時,就會獲取「標準輸入、標準輸出、標準錯誤」文件進行訪問的能力。
標準輸出是從鍵盤輸入的,標準輸出或者標準錯誤是輸出到顯示器的。許多 Linux 程序默認是從標準輸入進行輸入并從標準輸出進行輸出。比如
sort
會調用 sort 程序,會從終端讀取數據(直到用戶輸入 ctrl-d 結束),根據字母順序進行排序,然后將結果輸出到屏幕上。
通常還可以重定向標準輸入和標準輸出,重定向標準輸入使用進行重定向。允許一個命令中重定向標準輸入和輸出。例如命令
sort
會使 sort 從文件 in 中得到輸入,并把結果輸出到 out 文件中。由于標準錯誤沒有重定向,所以錯誤信息會直接打印到屏幕上。從標準輸入讀入,對其進行處理并將其寫入到標準輸出的程序稱為過濾器。
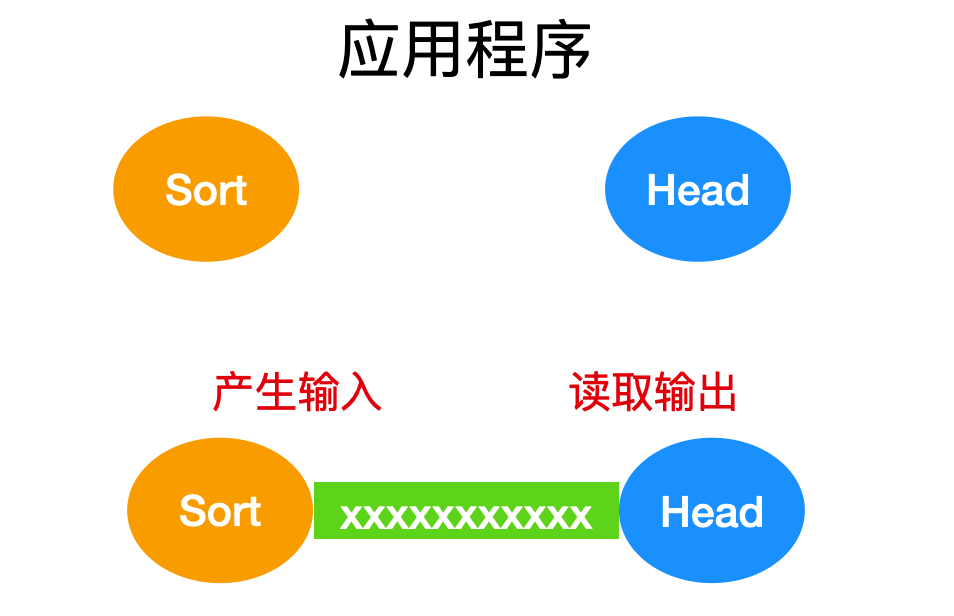
考慮下面由三個分開的命令組成的指令
sort
首先會調用 sort 應用程序,從標準輸入 in 中進行讀取,并通過標準輸出到 temp。當程序運行完畢后,shell 會運行 head ,告訴它打印前 30 行,并在標準輸出(默認為終端)上打印。最后,temp 臨時文件被刪除。「輕輕的,你走了,你揮一揮衣袖,不帶走一片云彩」。
命令行中的第一個程序通常會產生輸出,在上面的例子中,產生的輸出都不 temp 文件接收。然而,Linux 還提供了一個簡單的命令來做這件事,例如下面
sort
上面|稱為豎線符號,它的意思是從 sort 應用程序產生的排序輸出會直接作為輸入顯示,無需創建、使用和移除臨時文件。由管道符號連接的命令集合稱為管道(pipeline)。例如如下
grepcxuan*.c|sort|head-30|tail-5>f00
對任意以.c結尾的文件中包含cxuan的行被寫到標準輸出中,然后進行排序。這些內容中的前 30 行被 head 出來并傳給 tail ,它又將最后 5 行傳遞給 foo。這個例子提供了一個管道將多個命令連接起來。
可以把一系列 shell 命令放在一個文件中,然后將此文件作為輸入來運行。shell 會按照順序對他們進行處理,就像在鍵盤上鍵入命令一樣。包含 shell 命令的文件被稱為shell 腳本(shell scripts)。
?推薦一個 shell 命令的學習網站:https://www.shellscript.sh/?
shell 腳本其實也是一段程序,shell 腳本中可以對變量進行賦值,也包含循環控制語句比如「if、for、while」等,shell 的設計目標是讓其看起來和 C 相似(There is no doubt that C is father)。由于 shell 也是一個用戶程序,所以用戶可以選擇不同的 shell。
Linux 應用程序
Linux 的命令行也就是 shell,它由大量標準應用程序組成。這些應用程序主要有下面六種
文件和目錄操作命令
過濾器
文本程序
系統管理
程序開發工具,例如編輯器和編譯器
其他
除了這些標準應用程序外,還有其他應用程序比如「Web 瀏覽器、多媒體播放器、圖片瀏覽器、辦公軟件和游戲程序等」。
我們在上面的例子中已經見過了幾個 Linux 的應用程序,比如 sort、cp、ls、head,下面我們再來認識一下其他 Linux 的應用程序。
我們先從幾個例子開始講起,比如
cpab
是將 a 復制一個副本為 b ,而
mvab
是將 a 移動到 b ,但是刪除原文件。
上面這兩個命令有一些區別,cp是將文件進行復制,復制完成后會有兩個文件 a 和 b;而mv相當于是文件的移動,移動完成后就不再有 a 文件。cat命令可以把多個文件內容進行連接。使用rm可以刪除文件;使用chmod可以允許所有者改變訪問權限;文件目錄的的創建和刪除可以使用mkdir和rmdir命令;使用ls可以查看目錄文件,ls 可以顯示很多屬性,比如大小、用戶、創建日期等;sort 決定文件的顯示順序
Linux 應用程序還包括過濾器 grep,grep從標準輸入或者一個或多個輸入文件中提取特定模式的行;sort將輸入進行排序并輸出到標準輸出;head提取輸入的前幾行;tail 提取輸入的后面幾行;除此之外的過濾器還有cut和paste,允許對文本行的剪切和復制;od將輸入轉換為 ASCII ;tr實現字符大小寫轉換;pr為格式化打印輸出等。
程序編譯工具使用gcc;
make命令用于自動編譯,這是一個很強大的命令,它用于維護一個大的程序,往往這類程序的源碼由許多文件構成。典型的,有一些是header files 頭文件,源文件通常使用include指令包含這些文件,make 的作用就是跟蹤哪些文件屬于頭文件,然后安排自動編譯的過程。
下面列出了 POSIX 的標準應用程序
Linux 內核結構
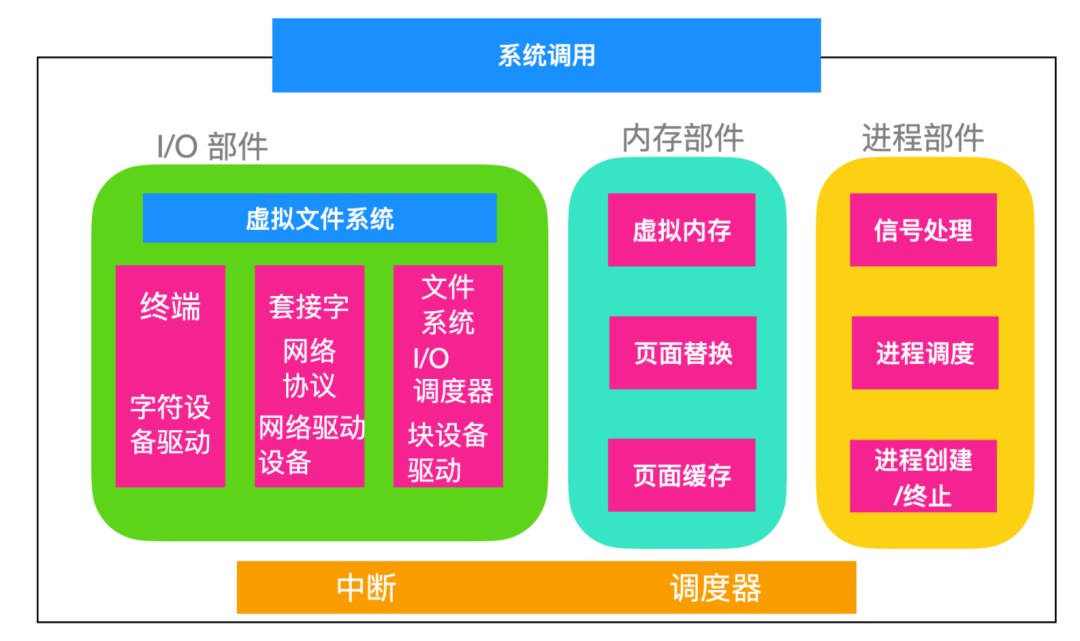
在上面我們看到了 Linux 的整體結構,下面我們從整體的角度來看一下 Linux 的內核結構
內核直接坐落在硬件上,內核的主要作用就是 I/O 交互、內存管理和控制 CPU 訪問。上圖中還包括了中斷和調度器,中斷是與設備交互的主要方式。中斷出現時調度器就會發揮作用。這里的低級代碼停止正在運行的進程,將其狀態保存在內核進程結構中,并啟動驅動程序。進程調度也會發生在內核完成一些操作并且啟動用戶進程的時候。圖中的調度器是 dispatcher。
?注意這里的調度器是dispatcher而不是scheduler,這兩者是有區別的
scheduler 和 dispatcher 都是和進程調度相關的概念,不同的是 scheduler 會從幾個進程中隨意選取一個進程;而 dispatcher 會給 scheduler 選擇的進程分配 CPU。?
然后,我們把內核系統分為三部分。
I/O 部分負責與設備進行交互以及執行網絡和存儲 I/O 操作的所有內核部分。
從圖中可以看出 I/O 層次的關系,最高層是一個虛擬文件系統,也就是說不管文件是來自內存還是磁盤中,都是經過虛擬文件系統中的。從底層看,所有的驅動都是字符驅動或者塊設備驅動。二者的主要區別就是是否允許隨機訪問。網絡驅動設備并不是一種獨立的驅動設備,它實際上是一種字符設備,不過網絡設備的處理方式和字符設備不同。
上面的設備驅動程序中,每個設備類型的內核代碼都不同。字符設備有兩種使用方式,有一鍵式的比如 vi 或者 emacs ,需要每一個鍵盤輸入。其他的比如 shell ,是需要輸入一行按回車鍵將字符串發送給程序進行編輯。
網絡軟件通常是模塊化的,由不同的設備和協議來支持。大多數 Linux 系統在內核中包含一個完整的硬件路由器的功能,但是這個不能和外部路由器相比,路由器上面是協議棧,包括 TCP/IP 協議,協議棧上面是 socket 接口,socket 負責與外部進行通信,充當了門的作用。
磁盤驅動上面是 I/O 調度器,它負責排序和分配磁盤讀寫操作,以盡可能減少磁頭的無用移動。
I/O 右邊的是內存部件,程序被裝載進內存,由 CPU 執行,這里會涉及到虛擬內存的部件,頁面的換入和換出是如何進行的,壞頁面的替換和經常使用的頁面會進行緩存。
進程模塊負責進程的創建和終止、進程的調度、Linux 把進程和線程看作是可運行的實體,并使用統一的調度策略來進行調度。
在內核最頂層的是系統調用接口,所有的系統調用都是經過這里,系統調用會觸發一個 trap,將系統從用戶態轉換為內核態,然后將控制權移交給上面的內核部件。
Linux 進程和線程
下面我們就深入理解一下 Linux 內核來理解 Linux 的基本概念之進程和線程。系統調用是操作系統本身的接口,它對于創建進程和線程,內存分配,共享文件和 I/O 來說都很重要。
我們將從各個版本的共性出發來進行探討。
基本概念
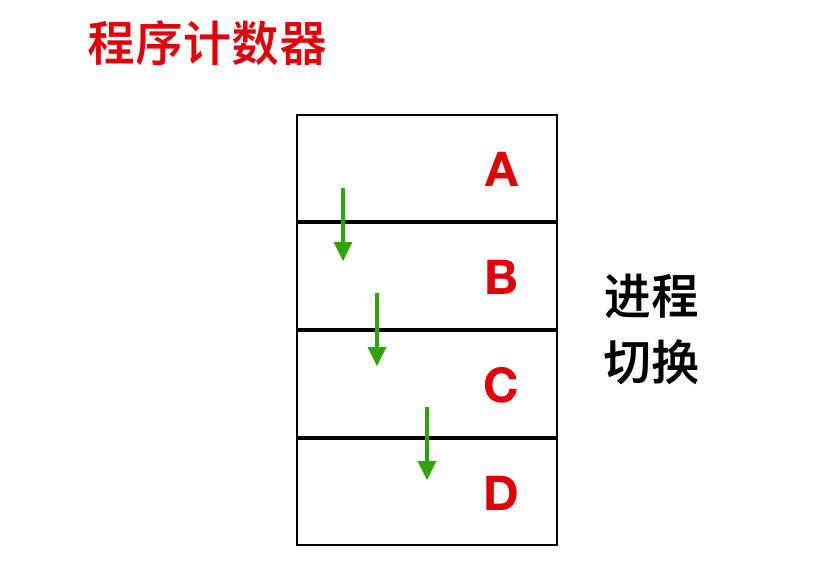
每個進程都會運行一段獨立的程序,并且在初始化的時候擁有一個獨立的控制線程。換句話說,每個進程都會有一個自己的程序計數器,這個程序計數器用來記錄下一個需要被執行的指令。Linux 允許進程在運行時創建額外的線程。
Linux 是一個多道程序設計系統,因此系統中存在彼此相互獨立的進程同時運行。此外,每個用戶都會同時有幾個活動的進程。因為如果是一個大型系統,可能有數百上千的進程在同時運行。
在某些用戶空間中,即使用戶退出登錄,仍然會有一些后臺進程在運行,這些進程被稱為守護進程(daemon)。
Linux 中有一種特殊的守護進程被稱為計劃守護進程(Cron daemon),計劃守護進程可以每分鐘醒來一次檢查是否有工作要做,做完會繼續回到睡眠狀態等待下一次喚醒。
?Cron 是一個守護程序,可以做任何你想做的事情,比如說你可以定期進行系統維護、定期進行系統備份等。在其他操作系統上也有類似的程序,比如 Mac OS X 上 Cron 守護程序被稱為launchd的守護進程。在 Windows 上可以被稱為計劃任務(Task Scheduler)。?
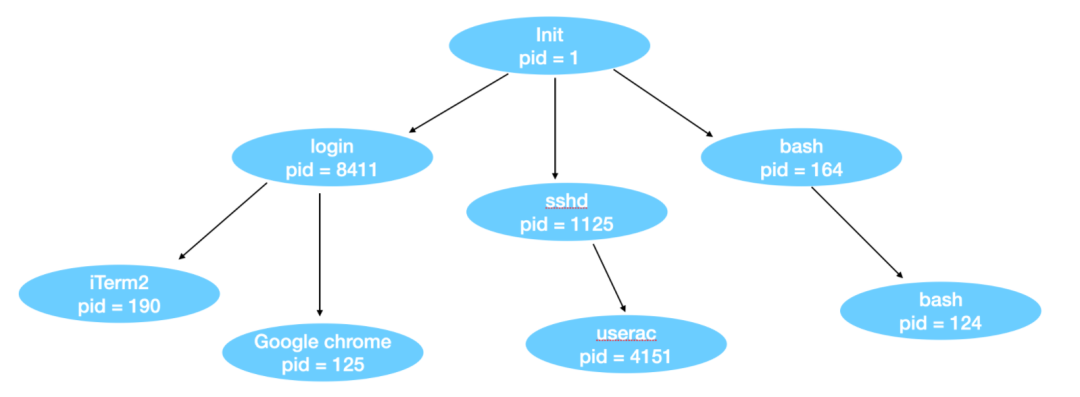
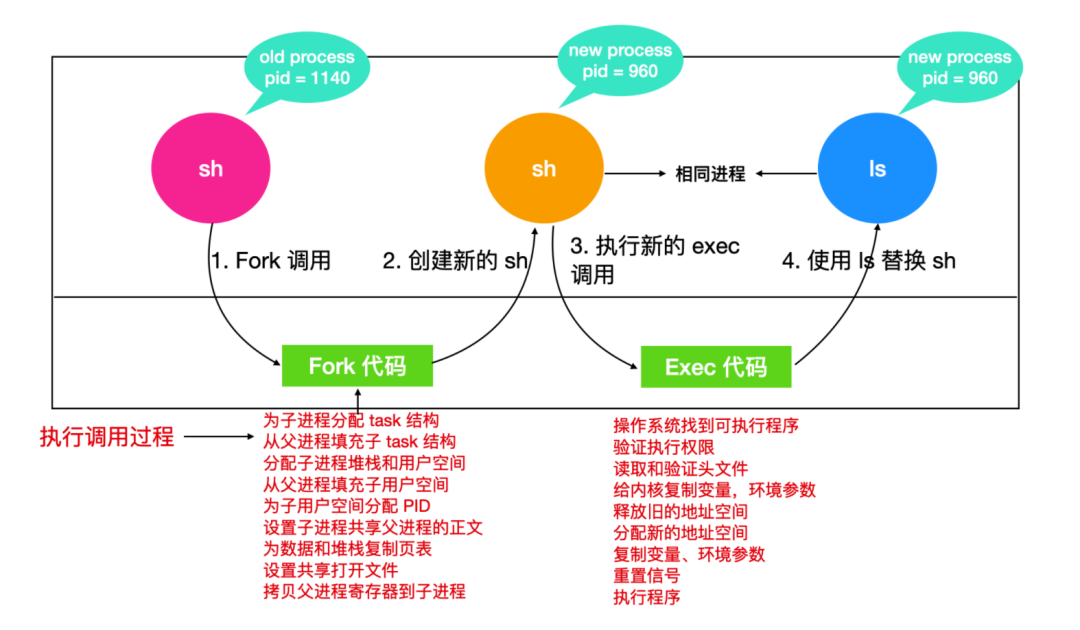
在 Linux 系統中,進程通過非常簡單的方式來創建,fork系統調用會創建一個源進程的拷貝(副本)。調用 fork 函數的進程被稱為父進程(parent process),使用 fork 函數創建出來的進程被稱為子進程(child process)。父進程和子進程都有自己的內存映像。如果在子進程創建出來后,父進程修改了一些變量等,那么子進程是看不到這些變化的,也就是 fork 后,父進程和子進程相互獨立。
雖然父進程和子進程保持相互獨立,但是它們卻能夠共享相同的文件,如果在 fork 之前,父進程已經打開了某個文件,那么 fork 后,父進程和子進程仍然共享這個打開的文件。對共享文件的修改會對父進程和子進程同時可見。
那么該如何區分父進程和子進程呢?子進程只是父進程的拷貝,所以它們幾乎所有的情況都一樣,包括內存映像、變量、寄存器等。區分的關鍵在于fork函數調用后的返回值,如果 fork 后返回一個非零值,這個非零值即是子進程的進程標識符(Process Identiier, PID),而會給子進程返回一個零值,可以用下面代碼來進行表示
pid=fork();//調用fork函數創建進程 if(pid0){ parent_handle()//父進程代碼 } else{ child_handle()//子進程代碼 }
父進程在 fork 后會得到子進程的 PID,這個 PID 即能代表這個子進程的唯一標識符也就是 PID。如果子進程想要知道自己的 PID,可以調用getpid方法。當子進程結束運行時,父進程會得到子進程的 PID,因為一個進程會 fork 很多子進程,子進程也會 fork 子進程,所以 PID 是非常重要的。我們把第一次調用 fork 后的進程稱為原始進程,一個原始進程可以生成一顆繼承樹
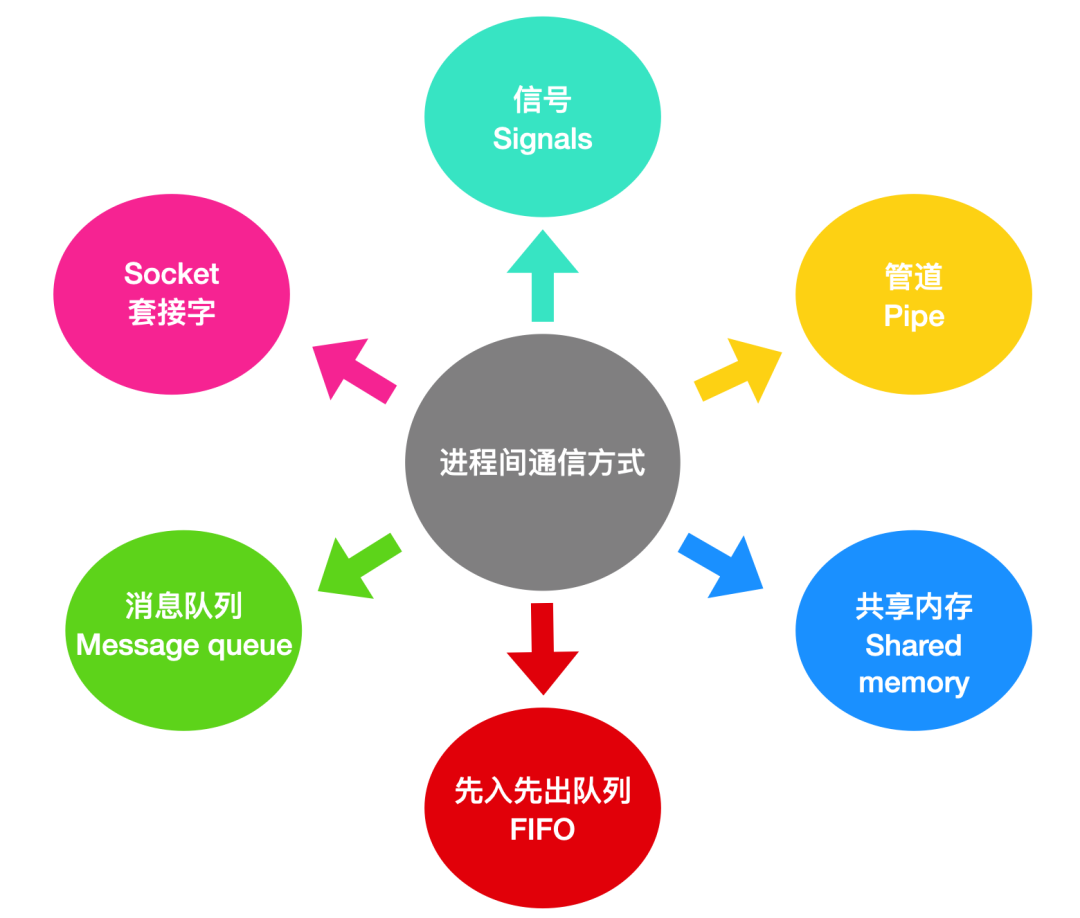
Linux 進程間通信
Linux 進程間的通信機制通常被稱為Internel-Process communication,IPC下面我們來說一說 Linux 進程間通信的機制,大致來說,Linux 進程間的通信機制可以分為 6 種
下面我們分別對其進行概述
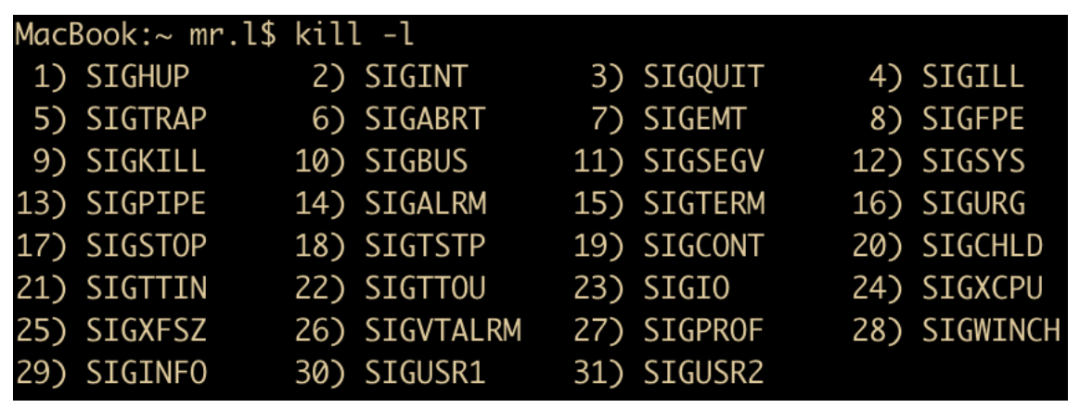
信號 signal
信號是 UNIX 系統最先開始使用的進程間通信機制,因為 Linux 是繼承于 UNIX 的,所以 Linux 也支持信號機制,通過向一個或多個進程發送異步事件信號來實現,信號可以從鍵盤或者訪問不存在的位置等地方產生;信號通過 shell 將任務發送給子進程。
你可以在 Linux 系統上輸入kill -l來列出系統使用的信號,下面是我提供的一些信號
進程可以選擇忽略發送過來的信號,但是有兩個是不能忽略的:SIGSTOP和SIGKILL信號。SIGSTOP 信號會通知當前正在運行的進程執行關閉操作,SIGKILL 信號會通知當前進程應該被殺死。除此之外,進程可以選擇它想要處理的信號,進程也可以選擇阻止信號,如果不阻止,可以選擇自行處理,也可以選擇進行內核處理。如果選擇交給內核進行處理,那么就執行默認處理。
操作系統會中斷目標程序的進程來向其發送信號、在任何非原子指令中,執行都可以中斷,如果進程已經注冊了新號處理程序,那么就執行進程,如果沒有注冊,將采用默認處理的方式。
例如:當進程收到SIGFPE浮點異常的信號后,默認操作是對其進行dump(轉儲)和退出。信號沒有優先級的說法。如果同時為某個進程產生了兩個信號,則可以將它們呈現給進程或者以任意的順序進行處理。
下面我們就來看一下這些信號是干什么用的
SIGABRT 和 SIGIOT
SIGABRT 和 SIGIOT 信號發送給進程,告訴其進行終止,這個 信號通常在調用 C標準庫的abort()函數時由進程本身啟動
SIGALRM 、 SIGVTALRM、SIGPROF
當設置的時鐘功能超時時會將 SIGALRM 、 SIGVTALRM、SIGPROF 發送給進程。當實際時間或時鐘時間超時時,發送 SIGALRM。當進程使用的 CPU 時間超時時,將發送 SIGVTALRM。當進程和系統代表進程使用的CPU 時間超時時,將發送 SIGPROF。
SIGBUS
SIGBUS 將造成總線中斷錯誤時發送給進程
SIGCHLD
當子進程終止、被中斷或者被中斷恢復,將 SIGCHLD 發送給進程。此信號的一種常見用法是指示操作系統在子進程終止后清除其使用的資源。
SIGCONT
SIGCONT 信號指示操作系統繼續執行先前由 SIGSTOP 或 SIGTSTP 信號暫停的進程。該信號的一個重要用途是在 Unix shell 中的作業控制中。
SIGFPE
SIGFPE 信號在執行錯誤的算術運算(例如除以零)時將被發送到進程。
SIGUP
當 SIGUP 信號控制的終端關閉時,會發送給進程。許多守護程序將重新加載其配置文件并重新打開其日志文件,而不是在收到此信號時退出。
SIGILL
SIGILL 信號在嘗試執行非法、格式錯誤、未知或者特權指令時發出
SIGINT
當用戶希望中斷進程時,操作系統會向進程發送 SIGINT 信號。用戶輸入 ctrl - c 就是希望中斷進程。
SIGKILL
SIGKILL 信號發送到進程以使其馬上進行終止。與 SIGTERM 和 SIGINT 相比,這個信號無法捕獲和忽略執行,并且進程在接收到此信號后無法執行任何清理操作,下面是一些例外情況
僵尸進程無法殺死,因為僵尸進程已經死了,它在等待父進程對其進行捕獲
處于阻塞狀態的進程只有再次喚醒后才會被 kill 掉
init進程是 Linux 的初始化進程,這個進程會忽略任何信號。
SIGKILL 通常是作為最后殺死進程的信號、它通常作用于 SIGTERM 沒有響應時發送給進程。
SIGPIPE
SIGPIPE 嘗試寫入進程管道時發現管道未連接無法寫入時發送到進程
SIGPOLL
當在明確監視的文件描述符上發生事件時,將發送 SIGPOLL 信號。
SIGRTMIN 至 SIGRTMAX
SIGRTMIN 至 SIGRTMAX 是實時信號
SIGQUIT
當用戶請求退出進程并執行核心轉儲時,SIGQUIT 信號將由其控制終端發送給進程。
SIGSEGV
當 SIGSEGV 信號做出無效的虛擬內存引用或分段錯誤時,即在執行分段違規時,將其發送到進程。
SIGSTOP
SIGSTOP 指示操作系統終止以便以后進行恢復時
SIGSYS
當 SIGSYS 信號將錯誤參數傳遞給系統調用時,該信號將發送到進程。
SYSTERM
我們上面簡單提到過了 SYSTERM 這個名詞,這個信號發送給進程以請求終止。與 SIGKILL 信號不同,該信號可以被過程捕獲或忽略。這允許進程執行良好的終止,從而釋放資源并在適當時保存狀態。SIGINT 與SIGTERM 幾乎相同。
SIGTSIP
SIGTSTP 信號由其控制終端發送到進程,以請求終端停止。
SIGTTIN 和 SIGTTOU
當 SIGTTIN 和SIGTTOU 信號分別在后臺嘗試從 tty 讀取或寫入時,信號將發送到該進程。
SIGTRAP
在發生異常或者 trap 時,將 SIGTRAP 信號發送到進程
SIGURG
當套接字具有可讀取的緊急或帶外數據時,將 SIGURG 信號發送到進程。
SIGUSR1 和 SIGUSR2
SIGUSR1 和 SIGUSR2 信號被發送到進程以指示用戶定義的條件。
SIGXCPU
當 SIGXCPU 信號耗盡 CPU 的時間超過某個用戶可設置的預定值時,將其發送到進程
SIGXFSZ
當 SIGXFSZ 信號增長超過最大允許大小的文件時,該信號將發送到該進程。
SIGWINCH
SIGWINCH 信號在其控制終端更改其大小(窗口更改)時發送給進程。
管道 pipe
Linux 系統中的進程可以通過建立管道 pipe 進行通信。
在兩個進程之間,可以建立一個通道,一個進程向這個通道里寫入字節流,另一個進程從這個管道中讀取字節流。管道是同步的,當進程嘗試從空管道讀取數據時,該進程會被阻塞,直到有可用數據為止。shell 中的管線 pipelines就是用管道實現的,當 shell 發現輸出
sort
它會創建兩個進程,一個是 sort,一個是 head,sort,會在這兩個應用程序之間建立一個管道使得 sort 進程的標準輸出作為 head 程序的標準輸入。sort 進程產生的輸出就不用寫到文件中了,如果管道滿了系統會停止 sort 以等待 head 讀出數據
管道實際上就是|,兩個應用程序不知道有管道的存在,一切都是由 shell 管理和控制的。
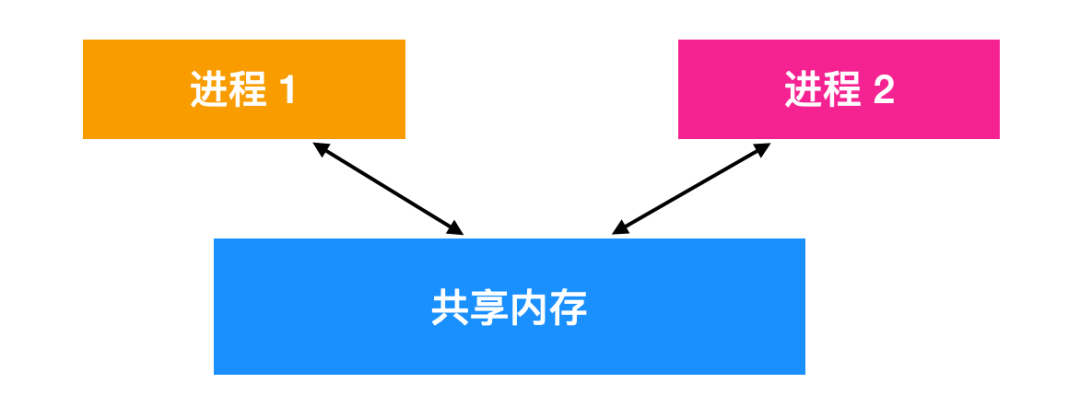
共享內存 shared memory
兩個進程之間還可以通過共享內存進行進程間通信,其中兩個或者多個進程可以訪問公共內存空間。兩個進程的共享工作是通過共享內存完成的,一個進程所作的修改可以對另一個進程可見(很像線程間的通信)。
在使用共享內存前,需要經過一系列的調用流程,流程如下
創建共享內存段或者使用已創建的共享內存段(shmget())
將進程附加到已經創建的內存段中(shmat())
從已連接的共享內存段分離進程(shmdt())
對共享內存段執行控制操作(shmctl())
先入先出隊列 FIFO
先入先出隊列 FIFO 通常被稱為命名管道(Named Pipes),命名管道的工作方式與常規管道非常相似,但是確實有一些明顯的區別。未命名的管道沒有備份文件:操作系統負責維護內存中的緩沖區,用來將字節從寫入器傳輸到讀取器。一旦寫入或者輸出終止的話,緩沖區將被回收,傳輸的數據會丟失。相比之下,命名管道具有支持文件和獨特 API ,命名管道在文件系統中作為設備的專用文件存在。當所有的進程通信完成后,命名管道將保留在文件系統中以備后用。命名管道具有嚴格的 FIFO 行為
寫入的第一個字節是讀取的第一個字節,寫入的第二個字節是讀取的第二個字節,依此類推。
消息隊列 Message Queue
一聽到消息隊列這個名詞你可能不知道是什么意思,消息隊列是用來描述內核尋址空間內的內部鏈接列表。可以按幾種不同的方式將消息按順序發送到隊列并從隊列中檢索消息。每個消息隊列由 IPC 標識符唯一標識。消息隊列有兩種模式,一種是嚴格模式, 嚴格模式就像是 FIFO 先入先出隊列似的,消息順序發送,順序讀取。還有一種模式是非嚴格模式,消息的順序性不是非常重要。
套接字 Socket
還有一種管理兩個進程間通信的是使用socket,socket 提供端到端的雙相通信。一個套接字可以與一個或多個進程關聯。就像管道有命令管道和未命名管道一樣,套接字也有兩種模式,套接字一般用于兩個進程之間的網絡通信,網絡套接字需要來自諸如TCP(傳輸控制協議)或較低級別UDP(用戶數據報協議)等基礎協議的支持。
套接字有以下幾種分類
順序包套接字(Sequential Packet Socket):此類套接字為最大長度固定的數據報提供可靠的連接。此連接是雙向的并且是順序的。
數據報套接字(Datagram Socket):數據包套接字支持雙向數據流。數據包套接字接受消息的順序與發送者可能不同。
流式套接字(Stream Socket):流套接字的工作方式類似于電話對話,提供雙向可靠的數據流。
原始套接字(Raw Socket):可以使用原始套接字訪問基礎通信協議。
Linux 中進程管理系統調用
現在關注一下 Linux 系統中與進程管理相關的系統調用。在了解之前你需要先知道一下什么是系統調用。
操作系統為我們屏蔽了硬件和軟件的差異,它的最主要功能就是為用戶提供一種抽象,隱藏內部實現,讓用戶只關心在 GUI 圖形界面下如何使用即可。操作系統可以分為兩種模式
內核態:操作系統內核使用的模式
用戶態:用戶應用程序所使用的模式
我們常說的上下文切換指的就是內核態模式和用戶態模式的頻繁切換。而系統調用指的就是引起內核態和用戶態切換的一種方式,系統調用通常在后臺靜默運行,表示計算機程序向其操作系統內核請求服務。
系統調用指令有很多,下面是一些與進程管理相關的最主要的系統調用
fork
fork 調用用于創建一個與父進程相同的子進程,創建完進程后的子進程擁有和父進程一樣的程序計數器、相同的 CPU 寄存器、相同的打開文件。
exec
exec 系統調用用于執行駐留在活動進程中的文件,調用 exec 后,新的可執行文件會替換先前的可執行文件并獲得執行。也就是說,調用 exec 后,會將舊文件或程序替換為新文件或執行,然后執行文件或程序。新的執行程序被加載到相同的執行空間中,因此進程的PID不會修改,因為我們「沒有創建新進程,只是替換舊進程」。但是進程的數據、代碼、堆棧都已經被修改。如果當前要被替換的進程包含多個線程,那么所有的線程將被終止,新的進程映像被加載執行。
這里需要解釋一下進程映像(Process image)的概念
「什么是進程映像呢」?進程映像是執行程序時所需要的可執行文件,通常會包括下面這些東西
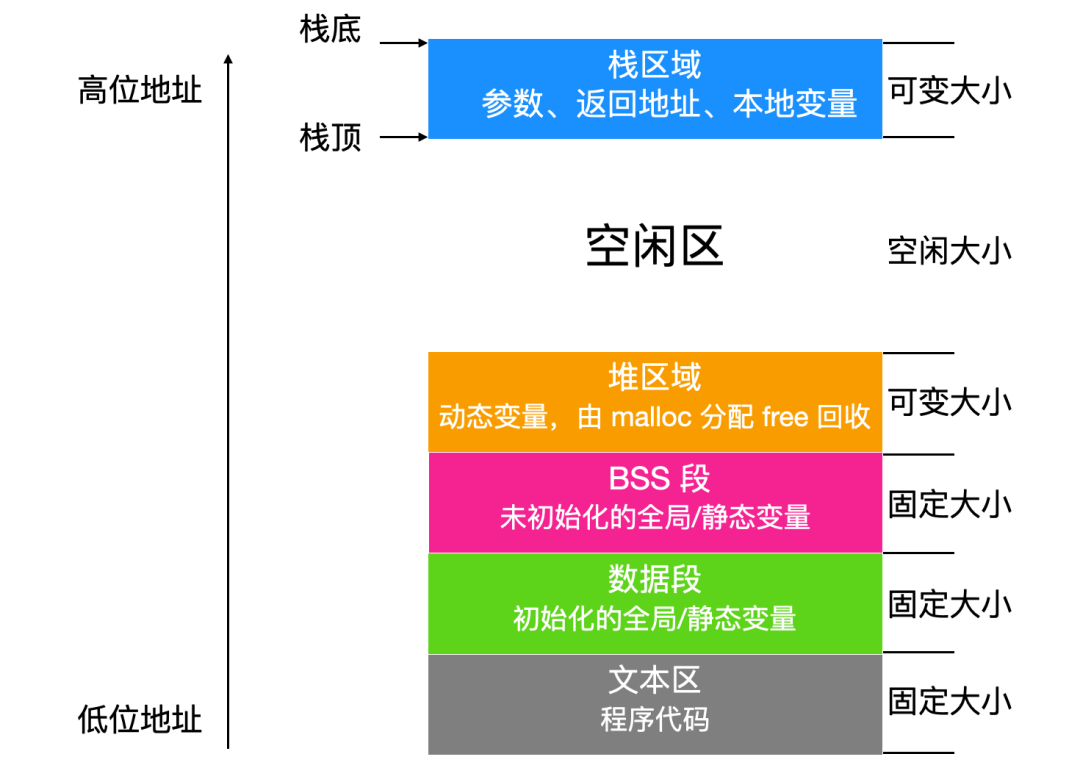
「代碼段(codesegment/textsegment)」
又稱文本段,用來存放指令,運行代碼的一塊內存空間
此空間大小在代碼運行前就已經確定
內存空間一般屬于只讀,某些架構的代碼也允許可寫
在代碼段中,也有可能包含一些只讀的常數變量,例如字符串常量等。
「數據段(datasegment)」
可讀可寫
存儲初始化的全局變量和初始化的 static 變量
數據段中數據的生存期是隨程序持續性(隨進程持續性) 隨進程持續性:進程創建就存在,進程死亡就消失
「bss 段(bsssegment):」
可讀可寫
存儲未初始化的全局變量和未初始化的 static 變量
bss 段中的數據一般默認為 0
「Data 段」
是可讀寫的,因為變量的值可以在運行時更改。此段的大小也固定。
「棧(stack):」
可讀可寫
存儲的是函數或代碼中的局部變量(非 static 變量)
棧的生存期隨代碼塊持續性,代碼塊運行就給你分配空間,代碼塊結束,就自動回收空間
「堆(heap):」
可讀可寫
存儲的是程序運行期間動態分配的 malloc/realloc 的空間
堆的生存期隨進程持續性,從 malloc/realloc 到 free 一直存在
下面是這些區域的構成圖
exec 系統調用是一些函數的集合,這些函數是
execl
execle
execlp
execv
execve
execvp
下面來看一下 exec 的工作原理
當前進程映像被替換為新的進程映像
新的進程映像是你做為 exec 傳遞的燦睡
結束當前正在運行的進程
新的進程映像有 PID,相同的環境和一些文件描述符(因為未替換進程,只是替換了進程映像)
CPU 狀態和虛擬內存受到影響,當前進程映像的虛擬內存映射被新進程映像的虛擬內存代替。
waitpid
等待子進程結束或終止
exit
在許多計算機操作系統上,計算機進程的終止是通過執行exit系統調用命令執行的。0 表示進程能夠正常結束,其他值表示進程以非正常的行為結束。
其他一些常見的系統調用如下
Linux 進程和線程的實現
Linux 進程
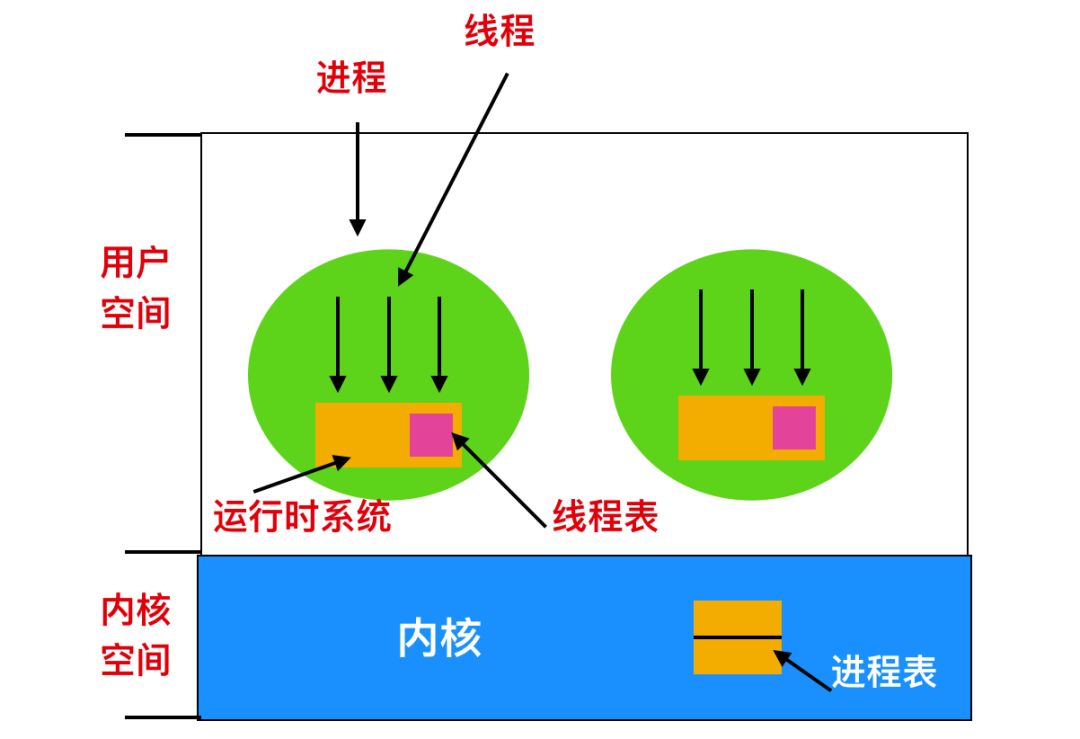
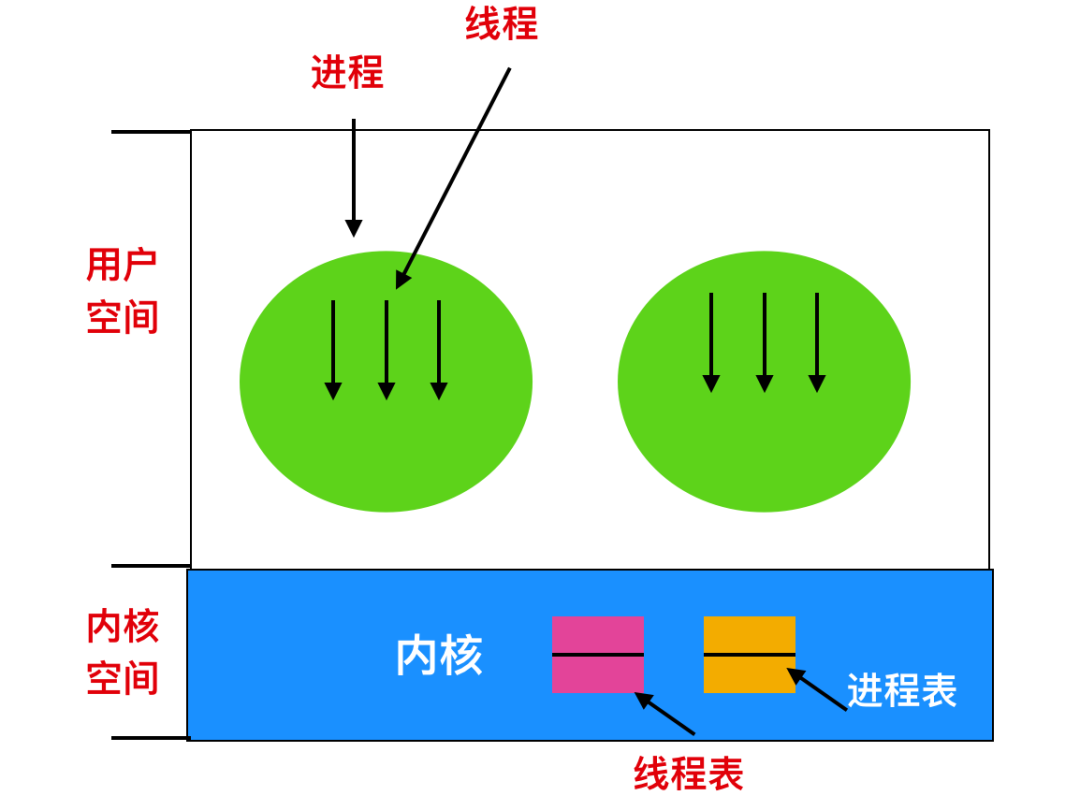
在 Linux 內核結構中,進程會被表示為任務,通過結構體structure來創建。不像其他的操作系統會區分進程、輕量級進程和線程,Linux 統一使用任務結構來代表執行上下文。因此,對于每個單線程進程來說,單線程進程將用一個任務結構表示,對于多線程進程來說,將為每一個用戶級線程分配一個任務結構。Linux 內核是多線程的,并且內核級線程不與任何用戶級線程相關聯。
對于每個進程來說,在內存中都會有一個task_struct進程描述符與之對應。進程描述符包含了內核管理進程所有有用的信息,包括「調度參數、打開文件描述符等等」。進程描述符從進程創建開始就一直存在于內核堆棧中。
Linux 和 Unix 一樣,都是通過PID來區分不同的進程,內核會將所有進程的任務結構組成為一個雙向鏈表。PID 能夠直接被映射稱為進程的任務結構所在的地址,從而不需要遍歷雙向鏈表直接訪問。
我們上面提到了進程描述符,這是一個非常重要的概念,我們上面還提到了進程描述符是位于內存中的,這里我們省略了一句話,那就是進程描述符是存在用戶的任務結構中,當進程位于內存并開始運行時,進程描述符才會被調入內存。
?進程位于內存被稱為PIM(Process In Memory),這是馮諾伊曼體系架構的一種體現,加載到內存中并執行的程序稱為進程。簡單來說,一個進程就是正在執行的程序。?
進程描述符可以歸為下面這幾類
調度參數(scheduling parameters):進程優先級、最近消耗 CPU 的時間、最近睡眠時間一起決定了下一個需要運行的進程
內存映像(memory image):我們上面說到,進程映像是執行程序時所需要的可執行文件,它由數據和代碼組成。
信號(signals):顯示哪些信號被捕獲、哪些信號被執行
寄存器:當發生內核陷入 (trap) 時,寄存器的內容會被保存下來。
系統調用狀態(system call state):當前系統調用的信息,包括參數和結果
文件描述符表(file descriptor table):有關文件描述符的系統被調用時,文件描述符作為索引在文件描述符表中定位相關文件的 i-node 數據結構
統計數據(accounting):記錄用戶、進程占用系統 CPU 時間表的指針,一些操作系統還保存進程最多占用的 CPU 時間、進程擁有的最大堆棧空間、進程可以消耗的頁面數等。
內核堆棧(kernel stack):進程的內核部分可以使用的固定堆棧
其他:當前進程狀態、事件等待時間、距離警報的超時時間、PID、父進程的 PID 以及用戶標識符等
有了上面這些信息,現在就很容易描述在 Linux 中是如何創建這些進程的了,創建新流程實際上非常簡單。「為子進程開辟一塊新的用戶空間的進程描述符,然后從父進程復制大量的內容。為這個子進程分配一個 PID,設置其內存映射,賦予它訪問父進程文件的權限,注冊并啟動」。
當執行 fork 系統調用時,調用進程會陷入內核并創建一些和任務相關的數據結構,比如內核堆棧(kernel stack)和thread_info結構。
?關于 thread_info 結構可以參考
https://docs.huihoo.com/doxygen/linux/kernel/3.7/arch_2avr32_2include_2asm_2thread__info_8h_source.html?
這個結構中包含進程描述符,進程描述符位于固定的位置,使得 Linux 系統只需要很小的開銷就可以定位到一個運行中進程的數據結構。
進程描述符的主要內容是根據父進程的描述符來填充。Linux 操作系統會尋找一個可用的 PID,并且此 PID 沒有被任何進程使用,更新進程標示符使其指向一個新的數據結構即可。為了減少 hash table 的碰撞,進程描述符會形成鏈表。它還將 task_struct 的字段設置為指向任務數組上相應的上一個/下一個進程。
?task_struct :Linux 進程描述符,內部涉及到眾多 C++ 源碼,我們會在后面進行講解。?
從原則上來說,為子進程開辟內存區域并為子進程分配數據段、堆棧段,并且對父進程的內容進行復制,但是實際上 fork 完成后,子進程和父進程沒有共享內存,所以需要復制技術來實現同步,但是復制開銷比較大,因此 Linux 操作系統使用了一種欺騙方式。即為子進程分配頁表,然后新分配的頁表指向父進程的頁面,同時這些頁面是只讀的。當進程向這些頁面進行寫入的時候,會開啟保護錯誤。內核發現寫入操作后,會為進程分配一個副本,使得寫入時把數據復制到這個副本上,這個副本是共享的,這種方式稱為寫入時復制(copy on write),這種方式避免了在同一塊內存區域維護兩個副本的必要,節省內存空間。
在子進程開始運行后,操作系統會調用 exec 系統調用,內核會進行查找驗證可執行文件,把參數和環境變量復制到內核,釋放舊的地址空間。
現在新的地址空間需要被創建和填充。如果系統支持映射文件,就像 Unix 系統一樣,那么新的頁表就會創建,表明內存中沒有任何頁,除非所使用的頁面是堆棧頁,其地址空間由磁盤上的可執行文件支持。新進程開始運行時,立刻會收到一個缺頁異常(page fault),這會使具有代碼的頁面加載進入內存。最后,參數和環境變量被復制到新的堆棧中,重置信號,寄存器全部清零。新的命令開始運行。
下面是一個示例,用戶輸出 ls,shell 會調用 fork 函數復制一個新進程,shell 進程會調用 exec 函數用可執行文件 ls 的內容覆蓋它的內存。
Linux 線程
現在我們來討論一下 Linux 中的線程,線程是輕量級的進程,想必這句話你已經聽過很多次了,輕量級體現在所有的進程切換都需要清除所有的表、進程間的共享信息也比較麻煩,一般來說通過管道或者共享內存,如果是 fork 函數后的父子進程則使用共享文件,然而線程切換不需要像進程一樣具有昂貴的開銷,而且線程通信起來也更方便。線程分為兩種:用戶級線程和內核級線程
用戶級線程
用戶級線程避免使用內核,通常,每個線程會顯示調用開關,發送信號或者執行某種切換操作來放棄 CPU,同樣,計時器可以強制進行開關,用戶線程的切換速度通常比內核線程快很多。在用戶級別實現線程會有一個問題,即單個線程可能會壟斷 CPU 時間片,導致其他線程無法執行從而餓死。如果執行一個 I/O 操作,那么 I/O 會阻塞,其他線程也無法運行。
一種解決方案是,一些用戶級的線程包解決了這個問題。可以使用時鐘周期的監視器來控制第一時間時間片獨占。然后,一些庫通過特殊的包裝來解決系統調用的 I/O 阻塞問題,或者可以為非阻塞 I/O 編寫任務。
內核級線程
內核級線程通常使用幾個進程表在內核中實現,每個任務都會對應一個進程表。在這種情況下,內核會在每個進程的時間片內調度每個線程。
所有能夠阻塞的調用都會通過系統調用的方式來實現,當一個線程阻塞時,內核可以進行選擇,是運行在同一個進程中的另一個線程(如果有就緒線程的話)還是運行一個另一個進程中的線程。
從用戶空間 -> 內核空間 -> 用戶空間的開銷比較大,但是線程初始化的時間損耗可以忽略不計。這種實現的好處是由時鐘決定線程切換時間,因此不太可能將時間片與任務中的其他線程占用時間綁定到一起。同樣,I/O 阻塞也不是問題。
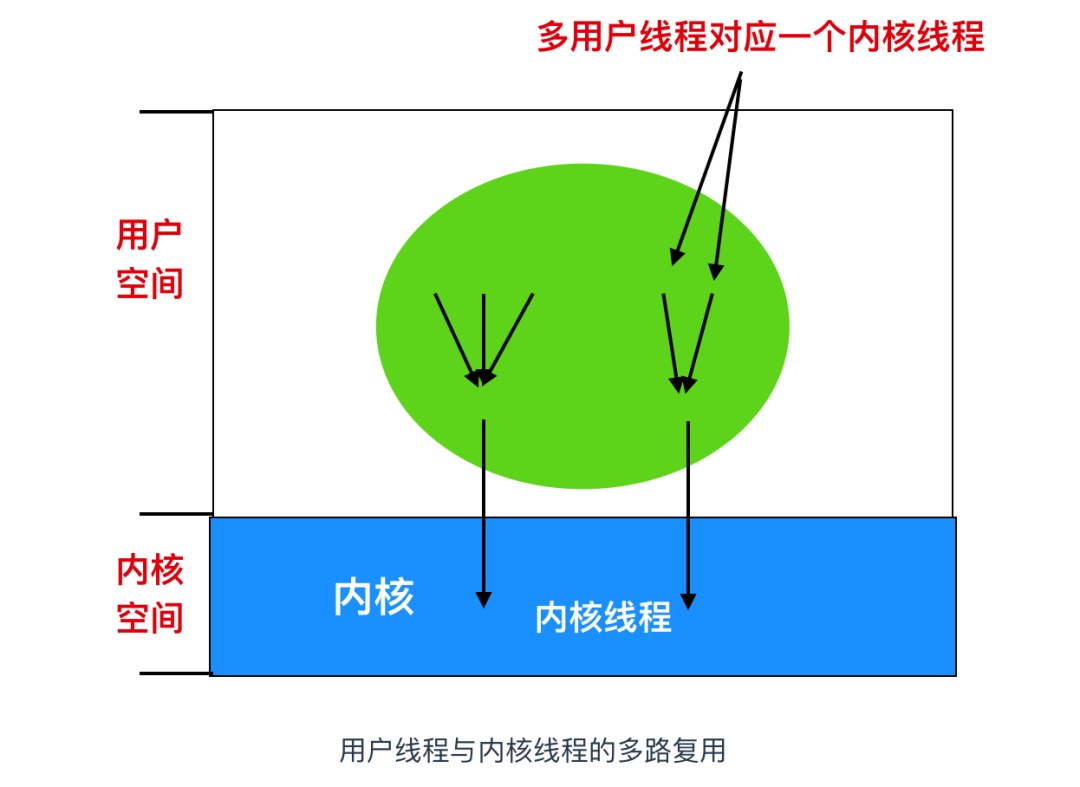
混合實現
結合用戶空間和內核空間的優點,設計人員采用了一種內核級線程的方式,然后將用戶級線程與某些或者全部內核線程多路復用起來
在這種模型中,編程人員可以自由控制用戶線程和內核線程的數量,具有很大的靈活度。采用這種方法,內核只識別內核級線程,并對其進行調度。其中一些內核級線程會被多個用戶級線程多路復用。
Linux 調度
下面我們來關注一下 Linux 系統的調度算法,首先需要認識到,Linux 系統的線程是內核線程,所以 Linux 系統是基于線程的,而不是基于進程的。
為了進行調度,Linux 系統將線程分為三類
實時先入先出
實時輪詢
分時
實時先入先出線程具有最高優先級,它不會被其他線程所搶占,除非那是一個剛剛準備好的,擁有更高優先級的線程進入。實時輪轉線程與實時先入先出線程基本相同,只是每個實時輪轉線程都有一個時間量,時間到了之后就可以被搶占。如果多個實時線程準備完畢,那么每個線程運行它時間量所規定的時間,然后插入到實時輪轉線程末尾。
?注意這個實時只是相對的,無法做到絕對的實時,因為線程的運行時間無法確定。它們相對分時系統來說,更加具有實時性?
Linux 系統會給每個線程分配一個nice值,這個值代表了優先級的概念。nice 值默認值是 0 ,但是可以通過系統調用 nice 值來修改。修改值的范圍從 -20 - +19。nice 值決定了線程的靜態優先級。一般系統管理員的 nice 值會比一般線程的優先級高,它的范圍是 -20 - -1。
下面我們更詳細的討論一下 Linux 系統的兩個調度算法,它們的內部與調度隊列(runqueue)的設計很相似。運行隊列有一個數據結構用來監視系統中所有可運行的任務并選擇下一個可以運行的任務。每個運行隊列和系統中的每個 CPU 有關。
Linux O(1)調度器是歷史上很流行的一個調度器。這個名字的由來是因為它能夠在常數時間內執行任務調度。在 O(1) 調度器里,調度隊列被組織成兩個數組,一個是任務「正在活動」的數組,一個是任務「過期失效」的數組。如下圖所示,每個數組都包含了 140 個鏈表頭,每個鏈表頭具有不同的優先級。
大致流程如下:
調度器從正在活動數組中選擇一個優先級最高的任務。如果這個任務的時間片過期失效了,就把它移動到過期失效數組中。如果這個任務阻塞了,比如說正在等待 I/O 事件,那么在它的時間片過期失效之前,一旦 I/O 操作完成,那么這個任務將會繼續運行,它將被放回到之前正在活動的數組中,因為這個任務之前已經消耗一部分 CPU 時間片,所以它將運行剩下的時間片。當這個任務運行完它的時間片后,它就會被放到過期失效數組中。一旦正在活動的任務數組中沒有其他任務后,調度器將會交換指針,使得正在活動的數組變為過期失效數組,過期失效數組變為正在活動的數組。使用這種方式可以保證每個優先級的任務都能夠得到執行,不會導致線程饑餓。
在這種調度方式中,不同優先級的任務所得到 CPU 分配的時間片也是不同的,高優先級進程往往能得到較長的時間片,低優先級的任務得到較少的時間片。
這種方式為了保證能夠更好的提供服務,通常會為交互式進程賦予較高的優先級,交互式進程就是用戶進程。
Linux 系統不知道一個任務究竟是 I/O 密集型的還是 CPU 密集型的,它只是依賴于交互式的方式,Linux 系統會區分是靜態優先級還是動態優先級。動態優先級是采用一種獎勵機制來實現的。獎勵機制有兩種方式:「獎勵交互式線程、懲罰占用 CPU 的線程」。在 Linux O(1) 調度器中,最高的優先級獎勵是 -5,注意這個優先級越低越容易被線程調度器接受,所以最高懲罰的優先級是 +5。具體體現就是操作系統維護一個名為sleep_avg的變量,任務喚醒會增加 sleep_avg 變量的值,當任務被搶占或者時間量過期會減少這個變量的值,反映在獎勵機制上。
?O(1) 調度算法是 2.6 內核版本的調度器,最初引入這個調度算法的是不穩定的 2.5 版本。早期的調度算法在多處理器環境中說明了通過訪問正在活動數組就可以做出調度的決定。使調度可以在固定的時間 O(1) 完成。?
O(1) 調度器使用了一種啟發式的方式,這是什么意思?
?在計算機科學中,啟發式是一種當傳統方式解決問題很慢時用來快速解決問題的方式,或者找到一個在傳統方法無法找到任何精確解的情況下找到近似解。?
O(1) 使用啟發式的這種方式,會使任務的優先級變得復雜并且不完善,從而導致在處理交互任務時性能很糟糕。
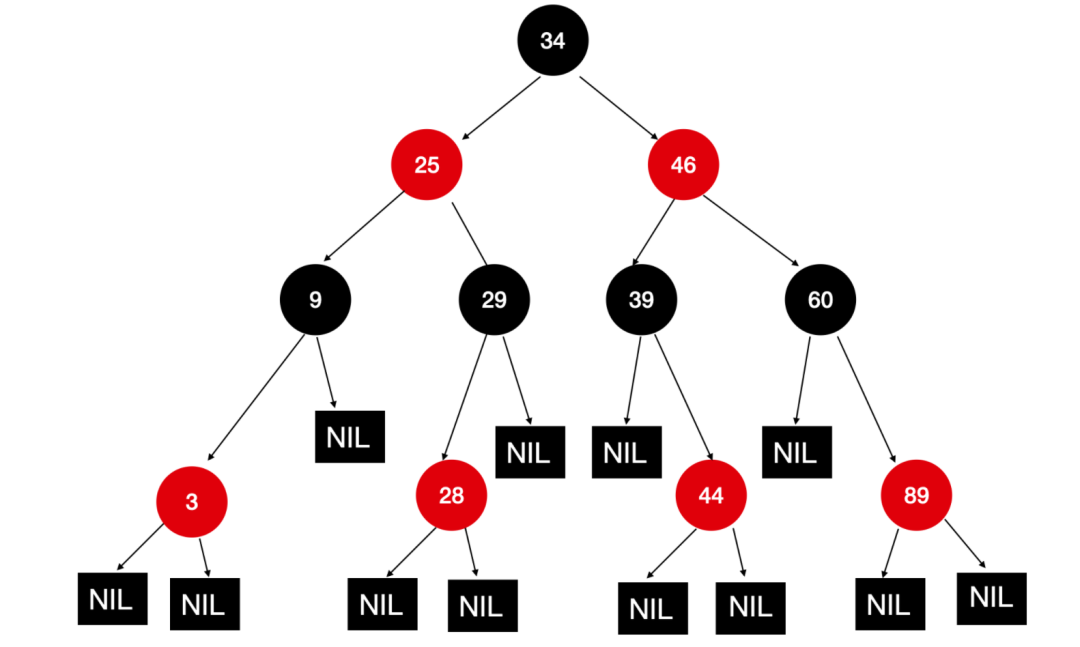
為了改進這個缺點,O(1) 調度器的開發者又提出了一個新的方案,即公平調度器(Completely Fair Scheduler, CFS)。CFS 的主要思想是使用一顆紅黑樹作為調度隊列。
?數據結構太重要了。?
CFS 會根據任務在 CPU 上的運行時間長短而將其有序地排列在樹中,時間精確到納秒級。下面是 CFS 的構造模型
CFS 的調度過程如下:
CFS 算法總是優先調度哪些使用 CPU 時間最少的任務。最小的任務一般都是在最左邊的位置。當有一個新的任務需要運行時,CFS 會把這個任務和最左邊的數值進行對比,如果此任務具有最小時間值,那么它將進行運行,否則它會進行比較,找到合適的位置進行插入。然后 CPU 運行紅黑樹上當前比較的最左邊的任務。
在紅黑樹中選擇一個節點來運行的時間可以是常數時間,但是插入一個任務的時間是O(loog(N)),其中 N 是系統中的任務數。考慮到當前系統的負載水平,這是可以接受的。
調度器只需要考慮可運行的任務即可。這些任務被放在適當的調度隊列中。不可運行的任務和正在等待的各種 I/O 操作或內核事件的任務被放入一個等待隊列中。等待隊列頭包含一個指向任務鏈表的指針和一個自旋鎖。自旋鎖對于并發處理場景下用處很大。
Linux 系統中的同步
下面來聊一下 Linux 中的同步機制。早期的 Linux 內核只有一個大內核鎖(Big Kernel Lock,BKL)。它阻止了不同處理器并發處理的能力。因此,需要引入一些粒度更細的鎖機制。
Linux 提供了若干不同類型的同步變量,這些變量既能夠在內核中使用,也能夠在用戶應用程序中使用。在地層中,Linux 通過使用atomic_set和atomic_read這樣的操作為硬件支持的原子指令提供封裝。硬件提供內存重排序,這是 Linux 屏障的機制。
具有高級別的同步像是自旋鎖的描述是這樣的,當兩個進程同時對資源進行訪問,在一個進程獲得資源后,另一個進程不想被阻塞,所以它就會自旋,等待一會兒再對資源進行訪問。Linux 也提供互斥量或信號量這樣的機制,也支持像是mutex_tryLock和mutex_tryWait這樣的非阻塞調用。也支持中斷處理事務,也可以通過動態禁用和啟用相應的中斷來實現。
Linux 啟動
下面來聊一聊 Linux 是如何啟動的。
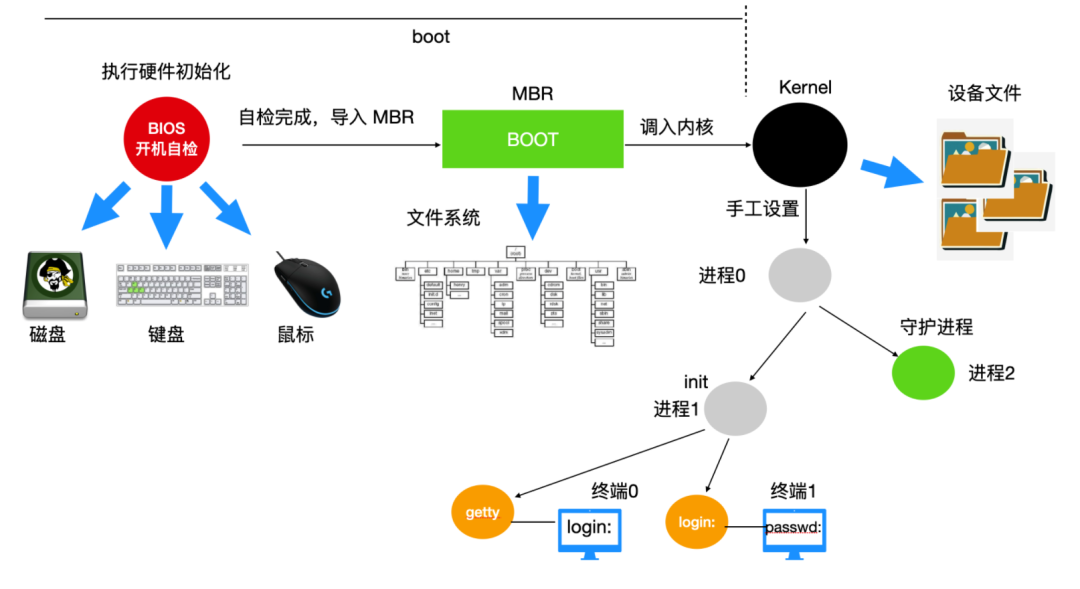
當計算機電源通電后,BIOS會進行開機自檢(Power-On-Self-Test, POST),對硬件進行檢測和初始化。因為操作系統的啟動會使用到磁盤、屏幕、鍵盤、鼠標等設備。下一步,磁盤中的第一個分區,也被稱為MBR(Master Boot Record)主引導記錄,被讀入到一個固定的內存區域并執行。這個分區中有一個非常小的,只有 512 字節的程序。程序從磁盤中調入 boot 獨立程序,boot 程序將自身復制到高位地址的內存從而為操作系統釋放低位地址的內存。
復制完成后,boot 程序讀取啟動設備的根目錄。boot 程序要理解文件系統和目錄格式。然后 boot 程序被調入內核,把控制權移交給內核。直到這里,boot 完成了它的工作。系統內核開始運行。
內核啟動代碼是使用匯編語言完成的,主要包括創建內核堆棧、識別 CPU 類型、計算內存、禁用中斷、啟動內存管理單元等,然后調用 C 語言的 main 函數執行操作系統部分。
這部分也會做很多事情,首先會分配一個消息緩沖區來存放調試出現的問題,調試信息會寫入緩沖區。如果調試出現錯誤,這些信息可以通過診斷程序調出來。
然后操作系統會進行自動配置,檢測設備,加載配置文件,被檢測設備如果做出響應,就會被添加到已鏈接的設備表中,如果沒有相應,就歸為未連接直接忽略。
配置完所有硬件后,接下來要做的就是仔細手工處理進程0,設置其堆棧,然后運行它,執行初始化、配置時鐘、掛載文件系統。創建init 進程(進程 1 )和守護進程(進程 2)。
init 進程會檢測它的標志以確定它是否為單用戶還是多用戶服務。在前一種情況中,它會調用 fork 函數創建一個 shell 進程,并且等待這個進程結束。后一種情況調用 fork 函數創建一個運行系統初始化的 shell 腳本(即 /etc/rc)的進程,這個進程可以進行文件系統一致性檢測、掛載文件系統、開啟守護進程等。
然后 /etc/rc 這個進程會從 /etc/ttys 中讀取數據,/etc/ttys 列出了所有的終端和屬性。對于每一個啟用的終端,這個進程調用 fork 函數創建一個自身的副本,進行內部處理并運行一個名為getty的程序。
getty 程序會在終端上輸入
login:
等待用戶輸入用戶名,在輸入用戶名后,getty 程序結束,登陸程序/bin/login開始運行。login 程序需要輸入密碼,并與保存在/etc/passwd中的密碼進行對比,如果輸入正確,login 程序以用戶 shell 程序替換自身,等待第一個命令。如果不正確,login 程序要求輸入另一個用戶名。
整個系統啟動過程如下
Linux 內存管理
Linux 內存管理模型非常直接明了,因為 Linux 的這種機制使其具有可移植性并且能夠在內存管理單元相差不大的機器下實現 Linux,下面我們就來認識一下 Linux 內存管理是如何實現的。
基本概念
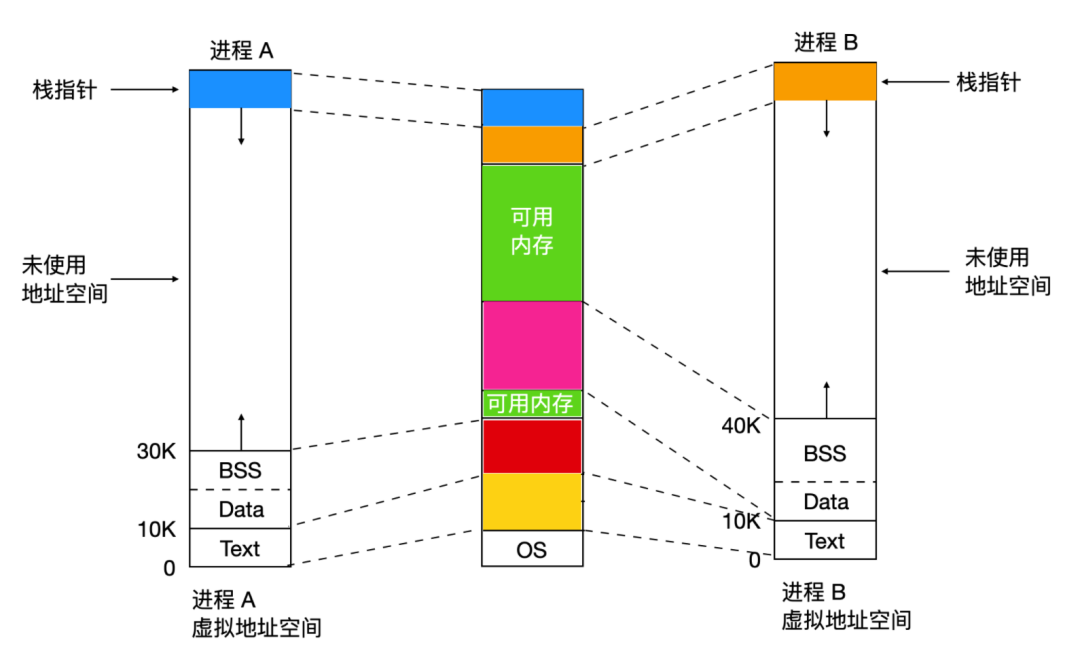
每個 Linux 進程都會有地址空間,這些地址空間由三個段區域組成:「text 段、data 段、stack 段」。下面是進程地址空間的示例。
數據段(data segment)包含了程序的變量、字符串、數組和其他數據的存儲。數據段分為兩部分,已經初始化的數據和尚未初始化的數據。其中尚未初始化的數據就是我們說的 BSS。數據段部分的初始化需要編譯就期確定的常量以及程序啟動就需要一個初始值的變量。所有 BSS 部分中的變量在加載后被初始化為 0 。
和代碼段(Text segment)不一樣,data segment 數據段可以改變。程序總是修改它的變量。而且,許多程序需要在執行時動態分配空間。Linux 允許數據段隨著內存的分配和回收從而增大或者減小。為了分配內存,程序可以增加數據段的大小。在 C 語言中有一套標準庫malloc經常用于分配內存。進程地址空間描述符包含動態分配的內存區域稱為堆(heap)。
第三部分段是棧段(stack segment)。在大部分機器上,棧段會在虛擬內存地址頂部地址位置處,并向低位置處(向地址空間為 0 處)拓展。舉個例子來說,在 32 位 x86 架構的機器上,棧開始于0xC0000000,這是用戶模式下進程允許可見的 3GB 虛擬地址限制。如果棧一直增大到超過棧段后,就會發生硬件故障并把頁面下降一個頁面。
當程序啟動時,棧區域并不是空的,相反,它會包含所有的 shell 環境變量以及為了調用它而向 shell 輸入的命令行。舉個例子,當你輸入
cpcxuanlx
時,cp 程序會運行并在棧中帶著字符串cp cxuan lx,這樣就能夠找出源文件和目標文件的名稱。
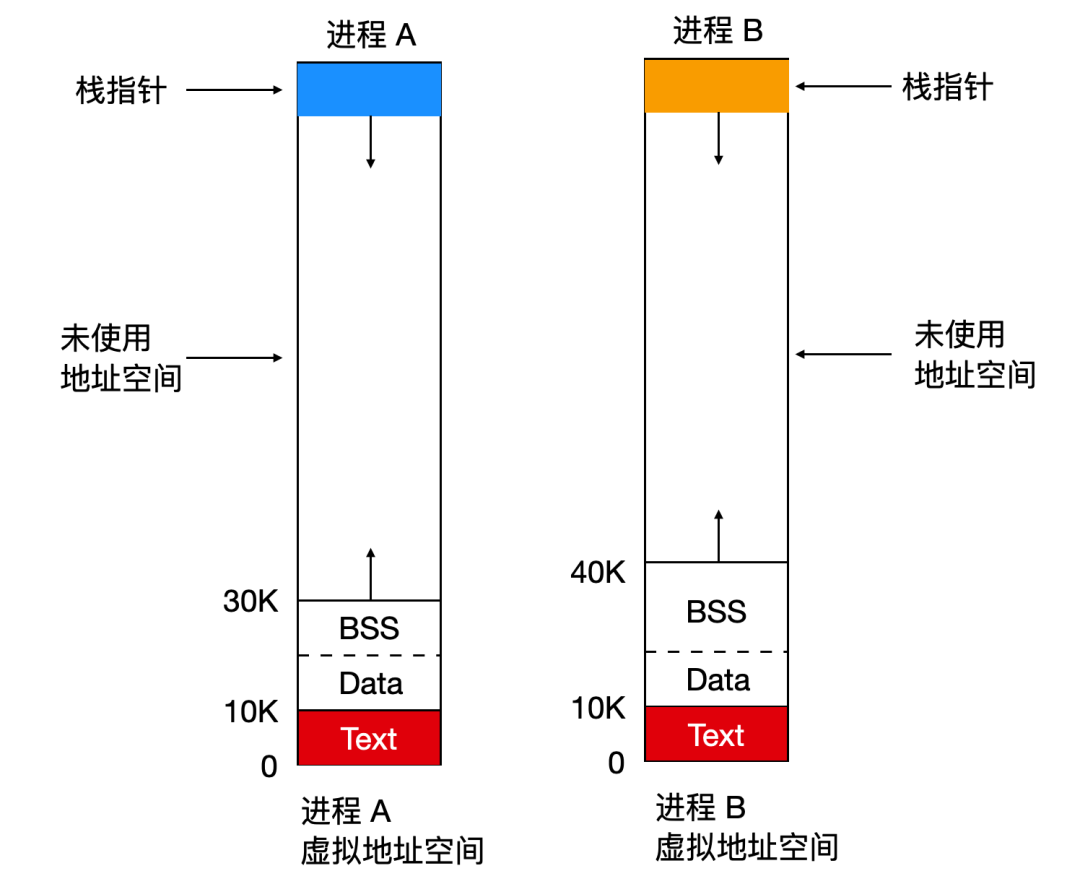
當兩個用戶運行在相同程序中,例如編輯器(editor),那么就會在內存中保持編輯器程序代碼的兩個副本,但是這種方式并不高效。Linux 系統支持共享文本段作為替代。下面圖中我們會看到 A 和 B 兩個進程,它們有著相同的文本區域。
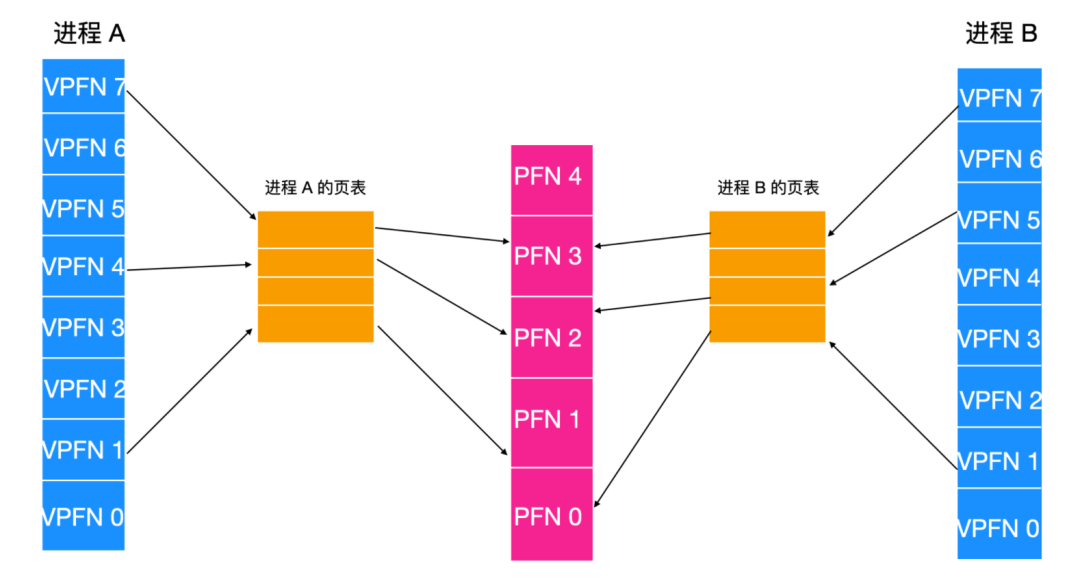
數據段和棧段只有在 fork 之后才會共享,共享也是共享未修改過的頁面。如果任何一個都需要變大但是沒有相鄰空間容納的話,也不會有問題,因為相鄰的虛擬頁面不必映射到相鄰的物理頁面上。
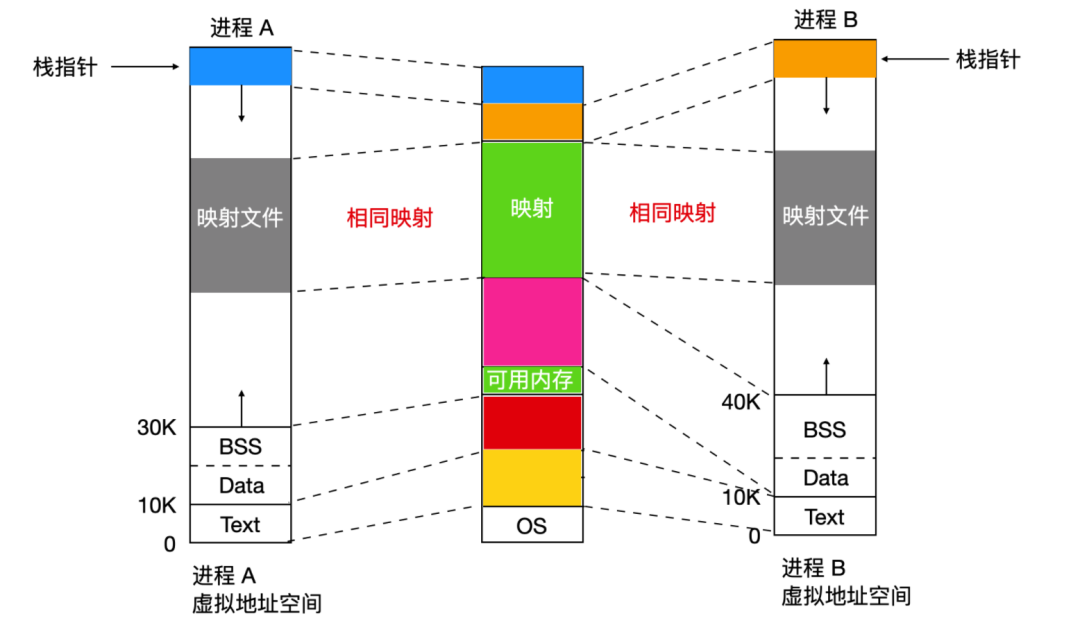
除了動態分配更多的內存,Linux 中的進程可以通過內存映射文件來訪問文件數據。這個特性可以使我們把一個文件映射到進程空間的一部分而該文件就可以像位于內存中的字節數組一樣被讀寫。把一個文件映射進來使得隨機讀寫比使用 read 和 write 之類的 I/O 系統調用要容易得多。共享庫的訪問就是使用了這種機制。如下所示
我們可以看到兩個相同文件會被映射到相同的物理地址上,但是它們屬于不同的地址空間。
映射文件的優點是,兩個或多個進程可以同時映射到同一文件中,任意一個進程對文件的寫操作對其他文件可見。通過使用映射臨時文件的方式,可以為多線程共享內存提供高帶寬,臨時文件在進程退出后消失。但是實際上,并沒有兩個相同的地址空間,因為每個進程維護的打開文件和信號不同。
Linux 內存管理系統調用
下面我們探討一下關于內存管理的系統調用方式。事實上,POSIX 并沒有給內存管理指定任何的系統調用。然而,Linux 卻有自己的內存系統調用,主要系統調用如下
如果遇到錯誤,那么 s 的返回值是 -1,a 和 addr 是內存地址,len 表示的是長度,prot 表示的是控制保護位,flags 是其他標志位,fd 是文件描述符,offset 是文件偏移量。
brk通過給出超過數據段之外的第一個字節地址來指定數據段的大小。如果新的值要比原來的大,那么數據區會變得越來越大,反之會越來越小。
mmap和unmap系統調用會控制映射文件。mmp 的第一個參數 addr 決定了文件映射的地址。它必須是頁面大小的倍數。如果參數是 0,系統會分配地址并返回 a。第二個參數是長度,它告訴了需要映射多少字節。它也是頁面大小的倍數。prot 決定了映射文件的保護位,保護位可以標記為「可讀、可寫、可執行或者這些的結合」。第四個參數 flags 能夠控制文件是私有的還是可讀的以及 addr 是必須的還是只是進行提示。第五個參數 fd 是要映射的文件描述符。只有打開的文件是可以被映射的,因此如果想要進行文件映射,必須打開文件;最后一個參數 offset 會指示文件從什么時候開始,并不一定每次都要從零開始。
Linux 內存管理實現
內存管理系統是操作系統最重要的部分之一。從計算機早期開始,我們實際使用的內存都要比系統中實際存在的內存多。內存分配策略克服了這一限制,并且其中最有名的就是虛擬內存(virtual memory)。通過在多個競爭的進程之間共享虛擬內存,虛擬內存得以讓系統有更多的內存。虛擬內存子系統主要包括下面這些概念。
「大地址空間」
操作系統使系統使用起來好像比實際的物理內存要大很多,那是因為虛擬內存要比物理內存大很多倍。
「保護」
系統中的每個進程都會有自己的虛擬地址空間。這些虛擬地址空間彼此完全分開,因此運行一個應用程序的進程不會影響另一個。并且,硬件虛擬內存機制允許內存保護關鍵內存區域。
「內存映射」
內存映射用來向進程地址空間映射圖像和數據文件。在內存映射中,文件的內容直接映射到進程的虛擬空間中。
「公平的物理內存分配」
內存管理子系統允許系統中的每個正在運行的進程公平分配系統的物理內存。
「共享虛擬內存」
盡管虛擬內存讓進程有自己的內存空間,但是有的時候你是需要共享內存的。例如幾個進程同時在 shell 中運行,這會涉及到 IPC 的進程間通信問題,這個時候你需要的是共享內存來進行信息傳遞而不是通過拷貝每個進程的副本獨立運行。
下面我們就正式探討一下什么是虛擬內存
虛擬內存的抽象模型
在考慮 Linux 用于支持虛擬內存的方法之前,考慮一個不會被太多細節困擾的抽象模型是很有用的。
處理器在執行指令時,會從內存中讀取指令并將其解碼(decode),在指令解碼時會獲取某個位置的內容并將他存到內存中。然后處理器繼續執行下一條指令。這樣,處理器總是在訪問存儲器以獲取指令和存儲數據。
在虛擬內存系統中,所有的地址空間都是虛擬的而不是物理的。但是實際存儲和提取指令的是物理地址,所以需要讓處理器根據操作系統維護的一張表將虛擬地址轉換為物理地址。
為了簡單的完成轉換,虛擬地址和物理地址會被分為固定大小的塊,稱為頁(page)。這些頁有相同大小,如果頁面大小不一樣的話,那么操作系統將很難管理。Alpha AXP系統上的 Linux 使用 8 KB 頁面,而 Intel x86 系統上的 Linux 使用 4 KB 頁面。每個頁面都有一個唯一的編號,即頁面框架號(PFN)。
上面就是 Linux 內存映射模型了,在這個頁模型中,虛擬地址由兩部分組成:「偏移量和虛擬頁框號」。每次處理器遇到虛擬地址時都會提取偏移量和虛擬頁框號。處理器必須將虛擬頁框號轉換為物理頁號,然后以正確的偏移量的位置訪問物理頁。
上圖中展示了兩個進程 A 和 B 的虛擬地址空間,每個進程都有自己的頁表。這些頁表將進程中的虛擬頁映射到內存中的物理頁中。頁表中每一項均包含
有效標志(valid flag):表明此頁表條目是否有效
該條目描述的物理頁框號
訪問控制信息,頁面使用方式,是否可寫以及是否可以執行代碼
要將處理器的虛擬地址映射為內存的物理地址,首先需要計算虛擬地址的頁框號和偏移量。頁面大小為 2 的次冪,可以通過移位完成操作。
如果當前進程嘗試訪問虛擬地址,但是訪問不到的話,這種情況稱為缺頁異常,此時虛擬操作系統的錯誤地址和頁面錯誤的原因將通知操作系統。
通過以這種方式將虛擬地址映射到物理地址,虛擬內存可以以任何順序映射到系統的物理頁面。
按需分頁
由于物理內存要比虛擬內存少很多,因此操作系統需要注意盡量避免直接使用低效的物理內存。節省物理內存的一種方式是僅加載執行程序當前使用的頁面(這何嘗不是一種懶加載的思想呢?)。例如,可以運行數據庫來查詢數據庫,在這種情況下,不是所有的數據都裝入內存,只裝載需要檢查的數據。這種僅僅在需要時才將虛擬頁面加載進內中的技術稱為按需分頁。
交換
如果某個進程需要將虛擬頁面傳入內存,但是此時沒有可用的物理頁面,那么操作系統必須丟棄物理內存中的另一個頁面來為該頁面騰出空間。
如果頁面已經修改過,那么操作系統必須保留該頁面的內容,以便以后可以訪問它。這種類型的頁面被稱為臟頁,當將其從內存中移除時,它會保存在稱為交換文件的特殊文件中。相對于處理器和物理內存的速度,對交換文件的訪問非常慢,并且操作系統需要兼顧將頁面寫到磁盤的以及將它們保留在內存中以便再次使用。
Linux 使用最近最少使用(LRU)頁面老化技術來公平的選擇可能會從系統中刪除的頁面,這個方案涉及系統中的每個頁面,頁面的年齡隨著訪問次數的變化而變化,如果某個頁面訪問次數多,那么該頁就表示越年輕,如果某個呃頁面訪問次數太少,那么該頁越容易被換出。
物理和虛擬尋址模式
大多數多功能處理器都支持物理地址模式和虛擬地址模式的概念。物理尋址模式不需要頁表,并且處理器不會在此模式下嘗試執行任何地址轉換。Linux 內核被鏈接在物理地址空間中運行。
Alpha AXP 處理器沒有物理尋址模式。相反,它將內存空間劃分為幾個區域,并將其中兩個指定為物理映射的地址。此內核地址空間稱為 KSEG 地址空間,它包含從 0xfffffc0000000000 向上的所有地址。為了從 KSEG 中鏈接的代碼(按照定義,內核代碼)執行或訪問其中的數據,該代碼必須在內核模式下執行。鏈接到 Alpha 上的 Linux內核以從地址 0xfffffc0000310000 執行。
訪問控制
頁面表的每一項還包含訪問控制信息,訪問控制信息主要檢查進程是否應該訪問內存。
必要時需要對內存進行訪問限制。例如包含可執行代碼的內存,自然是只讀內存;操作系統不應允許進程通過其可執行代碼寫入數據。相比之下,包含數據的頁面可以被寫入,但是嘗試執行該內存的指令將失敗。大多數處理器至少具有兩種執行模式:內核態和用戶態。你不希望訪問用戶執行內核代碼或內核數據結構,除非處理器以內核模式運行。
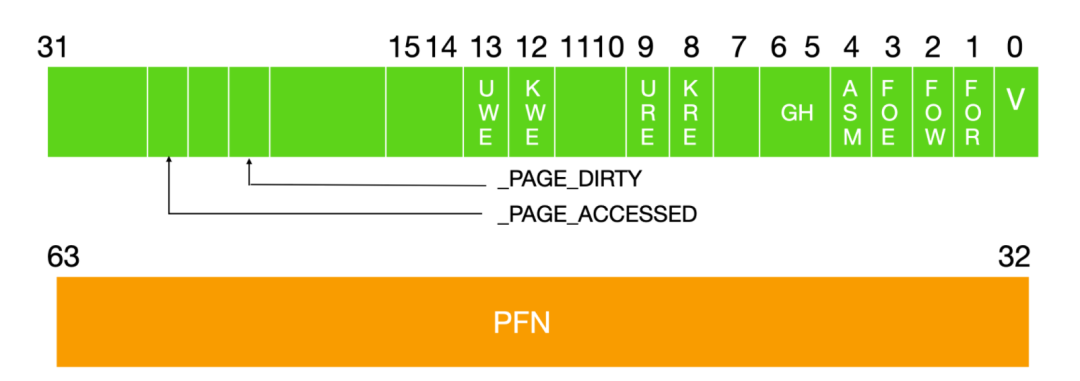
訪問控制信息被保存在上面的 Page Table Entry ,頁表項中,上面這幅圖是 Alpha AXP的 PTE。位字段具有以下含義
V
表示 valid ,是否有效位
FOR
讀取時故障,在嘗試讀取此頁面時出現故障
FOW
寫入時錯誤,在嘗試寫入時發生錯誤
FOE
執行時發生錯誤,在嘗試執行此頁面中的指令時,處理器都會報告頁面錯誤并將控制權傳遞給操作系統,
ASM
地址空間匹配,當操作系統希望清除轉換緩沖區中的某些條目時,將使用此選項。
GH
當在使用單個轉換緩沖區條目而不是多個轉換緩沖區條目映射整個塊時使用的提示。
KRE
內核模式運行下的代碼可以讀取頁面
URE
用戶模式下的代碼可以讀取頁面
KWE
以內核模式運行的代碼可以寫入頁面
UWE
以用戶模式運行的代碼可以寫入頁面
頁框號
對于設置了 V 位的 PTE,此字段包含此 PTE 的物理頁面幀號(頁面幀號)。對于無效的 PTE,如果此字段不為零,則包含有關頁面在交換文件中的位置的信息。
除此之外,Linux 還使用了兩個位
_PAGE_DIRTY
如果已設置,則需要將頁面寫出到交換文件中
_PAGE_ACCESSED
Linux 用來將頁面標記為已訪問。
緩存
上面的虛擬內存抽象模型可以用來實施,但是效率不會太高。操作系統和處理器設計人員都嘗試提高性能。但是除了提高處理器,內存等的速度之外,最好的方法就是維護有用信息和數據的高速緩存,從而使某些操作更快。在 Linux 中,使用很多和內存管理有關的緩沖區,使用緩沖區來提高效率。
緩沖區緩存
緩沖區高速緩存包含塊設備驅動程序使用的數據緩沖區。
還記得什么是塊設備么?這里回顧下
塊設備是一個能存儲固定大小塊信息的設備,它支持「以固定大小的塊,扇區或群集讀取和(可選)寫入數據」。每個塊都有自己的物理地址。通常塊的大小在 512 - 65536 之間。所有傳輸的信息都會以連續的塊為單位。塊設備的基本特征是每個塊都較為對立,能夠獨立的進行讀寫。常見的塊設備有「硬盤、藍光光盤、USB 盤」
與字符設備相比,塊設備通常需要較少的引腳。
緩沖區高速緩存通過設備標識符和塊編號用于快速查找數據塊。如果可以在緩沖區高速緩存中找到數據,則無需從物理塊設備中讀取數據,這種訪問方式要快得多。
頁緩存
頁緩存用于加快對磁盤上圖像和數據的訪問
它用于一次一頁地緩存文件中的內容,并且可以通過文件和文件中的偏移量進行訪問。當頁面從磁盤讀入內存時,它們被緩存在頁面緩存中。
交換區緩存
僅僅已修改(臟頁)被保存在交換文件中
只要這些頁面在寫入交換文件后沒有修改,則下次交換該頁面時,無需將其寫入交換文件,因為該頁面已在交換文件中。可以直接丟棄。在大量交換的系統中,這節省了許多不必要的和昂貴的磁盤操作。
硬件緩存
處理器中通常使用一種硬件緩存。頁表條目的緩存。在這種情況下,處理器并不總是直接讀取頁表,而是根據需要緩存頁的翻譯。這些是轉換后備緩沖區也被稱為TLB,包含來自系統中一個或多個進程的頁表項的緩存副本。
引用虛擬地址后,處理器將嘗試查找匹配的 TLB 條目。如果找到,則可以將虛擬地址直接轉換為物理地址,并對數據執行正確的操作。如果處理器找不到匹配的 TLB 條目, 它通過向操作系統發信號通知已發生 TLB 丟失獲得操作系統的支持和幫助。系統特定的機制用于將該異常傳遞給可以修復問題的操作系統代碼。操作系統為地址映射生成一個新的 TLB 條目。清除異常后,處理器將再次嘗試轉換虛擬地址。這次能夠執行成功。
使用緩存也存在缺點,為了節省精力,Linux 必須使用更多的時間和空間來維護這些緩存,并且如果緩存損壞,系統將會崩潰。
Linux 頁表
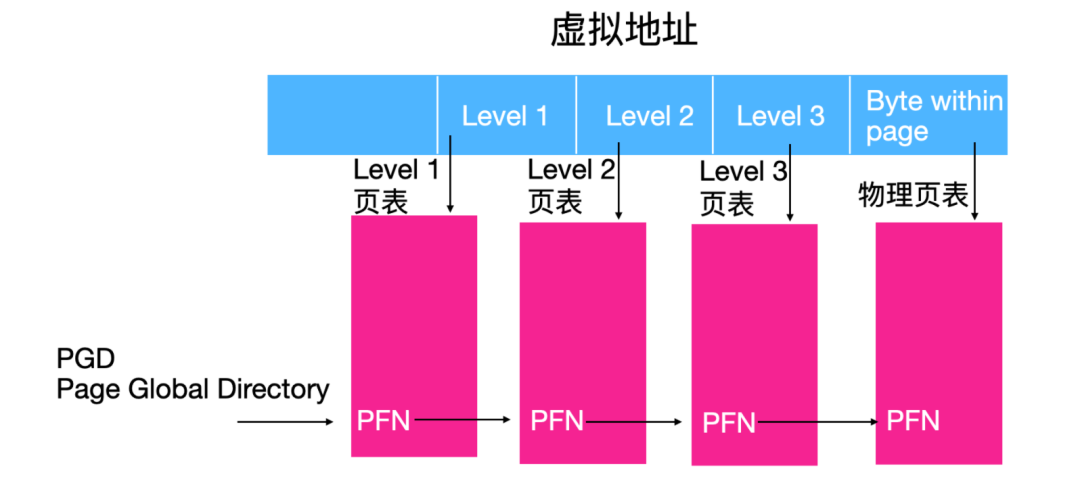
Linux 假定頁表分為三個級別。訪問的每個頁表都包含下一級頁表
圖中的 PDG 表示全局頁表,當創建一個新的進程時,都要為新進程創建一個新的頁面目錄,即 PGD。
要將虛擬地址轉換為物理地址,處理器必須獲取每個級別字段的內容,將其轉換為包含頁表的物理頁的偏移量,并讀取下一級頁表的頁框號。這樣重復三次,直到找到包含虛擬地址的物理頁面的頁框號為止。
Linux 運行的每個平臺都必須提供翻譯宏,這些宏允許內核遍歷特定進程的頁表。這樣,內核無需知道頁表條目的格式或它們的排列方式。
頁分配和取消分配
對系統中物理頁面有很多需求。例如,當圖像加載到內存中時,操作系統需要分配頁面。
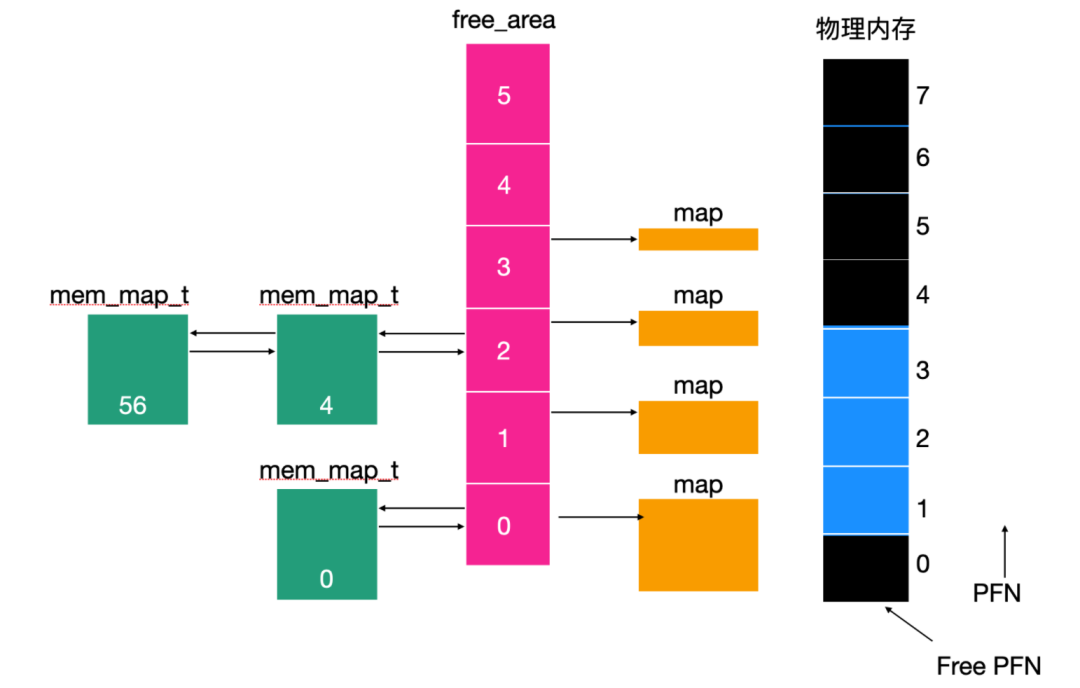
系統中所有物理頁面均由mem_map數據結構描述,這個數據結構是mem_map_t的列表。它包括一些重要的屬性
count :這是頁面的用戶數計數,當頁面在多個進程之間共享時,計數大于 1
age:這是描述頁面的年齡,用于確定頁面是否適合丟棄或交換
map_nr :這是此mem_map_t描述的物理頁框號。
頁面分配代碼使用free_area向量查找和釋放頁面,free_area 的每個元素都包含有關頁面塊的信息。
頁面分配
Linux 的頁面分配使用一種著名的伙伴算法來進行頁面的分配和取消分配。頁面以 2 的冪為單位進行塊分配。這就意味著它可以分配 1頁、2 頁、4頁等等,只要系統中有足夠可用的頁面來滿足需求就可以。判斷的標準是「nr_free_pages> min_free_pages」,如果滿足,就會在 free_area 中搜索所需大小的頁面塊完成分配。free_area 的每個元素都有該大小的塊的已分配頁面和空閑頁面塊的映射。
分配算法會搜索請求大小的頁面塊。如果沒有任何請求大小的頁面塊可用的話,會搜尋一個是請求大小二倍的頁面塊,然后重復,直到一直搜尋完 free_area 找到一個頁面塊為止。如果找到的頁面塊要比請求的頁面塊大,就會對找到的頁面塊進行細分,直到找到合適的大小塊為止。
因為每個塊都是 2 的次冪,所以拆分過程很容易,因為你只需將塊分成兩半即可。空閑塊在適當的隊列中排隊,分配的頁面塊返回給調用者。
如果請求一個 2 個頁的塊,則 4 頁的第一個塊(從第 4 頁的框架開始)將被分成兩個 2 頁的塊。第一個頁面(從第 4 頁的幀開始)將作為分配的頁面返回給調用方,第二個塊(從第 6 頁的頁面開始)將作為 2 頁的空閑塊排隊到 free_area 數組的元素 1 上。
頁面取消分配
上面的這種內存方式最造成一種后果,那就是內存的碎片化,會將較大的空閑頁面分成較小的頁面。頁面解除分配代碼會盡可能將頁面重新組合成為更大的空閑塊。每釋放一個頁面,都會檢查相同大小的相鄰的塊,以查看是否空閑。如果是,則將其與新釋放的頁面塊組合以形成下一個頁面大小塊的新的自由頁面塊。每次將兩個頁面塊重新組合為更大的空閑頁面塊時,頁面釋放代碼就會嘗試將該頁面塊重新組合為更大的空閑頁面。通過這種方式,可用頁面的塊將盡可能多地使用內存。
例如上圖,如果要釋放第 1 頁的頁面,則將其與已經空閑的第 0 頁頁面框架組合在一起,并作為大小為 2頁的空閑塊排隊到 free_area 的元素 1 中
內存映射
內核有兩種類型的內存映射:共享型(shared)和私有型(private)。私有型是當進程為了只讀文件,而不寫文件時使用,這時,私有映射更加高效。但是,任何對私有映射頁的寫操作都會導致內核停止映射該文件中的頁。所以,寫操作既不會改變磁盤上的文件,對訪問該文件的其它進程也是不可見的。
按需分頁
一旦可執行映像被內存映射到虛擬內存后,它就可以被執行了。因為只將映像的開頭部分物理的拉入到內存中,因此它將很快訪問物理內存尚未存在的虛擬內存區域。當進程訪問沒有有效頁表的虛擬地址時,操作系統會報告這項錯誤。
頁面錯誤描述頁面出錯的虛擬地址和引起的內存訪問(RAM)類型。
Linux 必須找到代表發生頁面錯誤的內存區域的 vm_area_struct 結構。由于搜索 vm_area_struct 數據結構對于有效處理頁面錯誤至關重要,因此它們以AVL(Adelson-Velskii和Landis)樹結構鏈接在一起。如果引起故障的虛擬地址沒有vm_area_struct結構,則此進程已經訪問了非法地址,Linux 會向進程發出SIGSEGV信號,如果進程沒有用于該信號的處理程序,那么進程將會終止。
然后,Linux 會針對此虛擬內存區域所允許的訪問類型,檢查發生的頁面錯誤類型。如果該進程以非法方式訪問內存,例如寫入僅允許讀的區域,則還會發出內存訪問錯誤信號。
現在,Linux 已確定頁面錯誤是合法的,因此必須對其進行處理。
文件系統
在 Linux 中,最直觀、最可見的部分就是文件系統(file system)。下面我們就來一起探討一下關于 Linux 中國的文件系統,系統調用以及文件系統實現背后的原理和思想。這些思想中有一些來源于 MULTICS,現在已經被 Windows 等其他操作系統使用。Linux 的設計理念就是小的就是好的(Small is Beautiful)。雖然 Linux 只是使用了最簡單的機制和少量的系統調用,但是 Linux 卻提供了強大而優雅的文件系統。
Linux 文件系統基本概念
Linux 在最初的設計是 MINIX1 文件系統,它只支持 14 字節的文件名,它的最大文件只支持到 64 MB。在 MINIX 1 之后的文件系統是 ext 文件系統。ext 系統相較于 MINIX 1 來說,在支持字節大小和文件大小上均有很大提升,但是 ext 的速度仍沒有 MINIX 1 快,于是,ext 2 被開發出來,它能夠支持長文件名和大文件,而且具有比 MINIX 1 更好的性能。這使他成為 Linux 的主要文件系統。只不過 Linux 會使用VFS曾支持多種文件系統。在 Linux 鏈接時,用戶可以動態的將不同的文件系統掛載倒 VFS 上。
Linux 中的文件是一個任意長度的字節序列,Linux 中的文件可以包含任意信息,比如 ASCII 碼、二進制文件和其他類型的文件是不加區分的。
為了方便起見,文件可以被組織在一個目錄中,目錄存儲成文件的形式在很大程度上可以作為文件處理。目錄可以有子目錄,這樣形成有層次的文件系統,Linux 系統下面的根目錄是/,它通常包含了多個子目錄。字符/還用于對目錄名進行區分,例如「/usr/cxuan」表示的就是根目錄下面的 usr 目錄,其中有一個叫做 cxuan 的子目錄。
下面我們介紹一下 Linux 系統根目錄下面的目錄名
/bin,它是重要的二進制應用程序,包含二進制文件,系統的所有用戶使用的命令都在這里
/boot,啟動包含引導加載程序的相關文件
/dev,包含設備文件,終端文件,USB 或者連接到系統的任何設備
/etc,配置文件,啟動腳本等,包含所有程序所需要的配置文件,也包含了啟動/停止單個應用程序的啟動和關閉 shell 腳本
/home,本地主要路徑,所有用戶用 home 目錄存儲個人信息
/lib,系統庫文件,包含支持位于 /bin 和 /sbin 下的二進制庫文件
/lost+found,在根目錄下提供一個遺失+查找系統,必須在 root 用戶下才能查看當前目錄下的內容
/media,掛載可移動介質
/mnt,掛載文件系統
/opt,提供一個可選的應用程序安裝目錄
/proc,特殊的動態目錄,用于維護系統信息和狀態,包括當前運行中進程信息
/root,root 用戶的主要目錄文件夾
/sbin,重要的二進制系統文件
/tmp, 系統和用戶創建的臨時文件,系統重啟時,這個目錄下的文件都會被刪除
/usr,包含絕大多數用戶都能訪問的應用程序和文件
/var,經常變化的文件,諸如日志文件或數據庫等
在 Linux 中,有兩種路徑,一種是絕對路徑(absolute path),絕對路徑告訴你從根目錄下查找文件,絕對路徑的缺點是太長而且不太方便。還有一種是相對路徑(relative path),相對路徑所在的目錄也叫做工作目錄(working directory)。
如果/usr/local/books是工作目錄,那么 shell 命令
cpbooksbooks-replica
就表示的是相對路徑,而
cp/usr/local/books/books/usr/local/books/books-replica
則表示的是絕對路徑。
在 Linux 中經常出現一個用戶使用另一個用戶的文件或者使用文件樹結構中的文件。兩個用戶共享同一個文件,這個文件位于某個用戶的目錄結構中,另一個用戶需要使用這個文件時,必須通過絕對路徑才能引用到他。如果絕對路徑很長,那么每次輸入起來會變的非常麻煩,所以 Linux 提供了一種鏈接(link)機制。
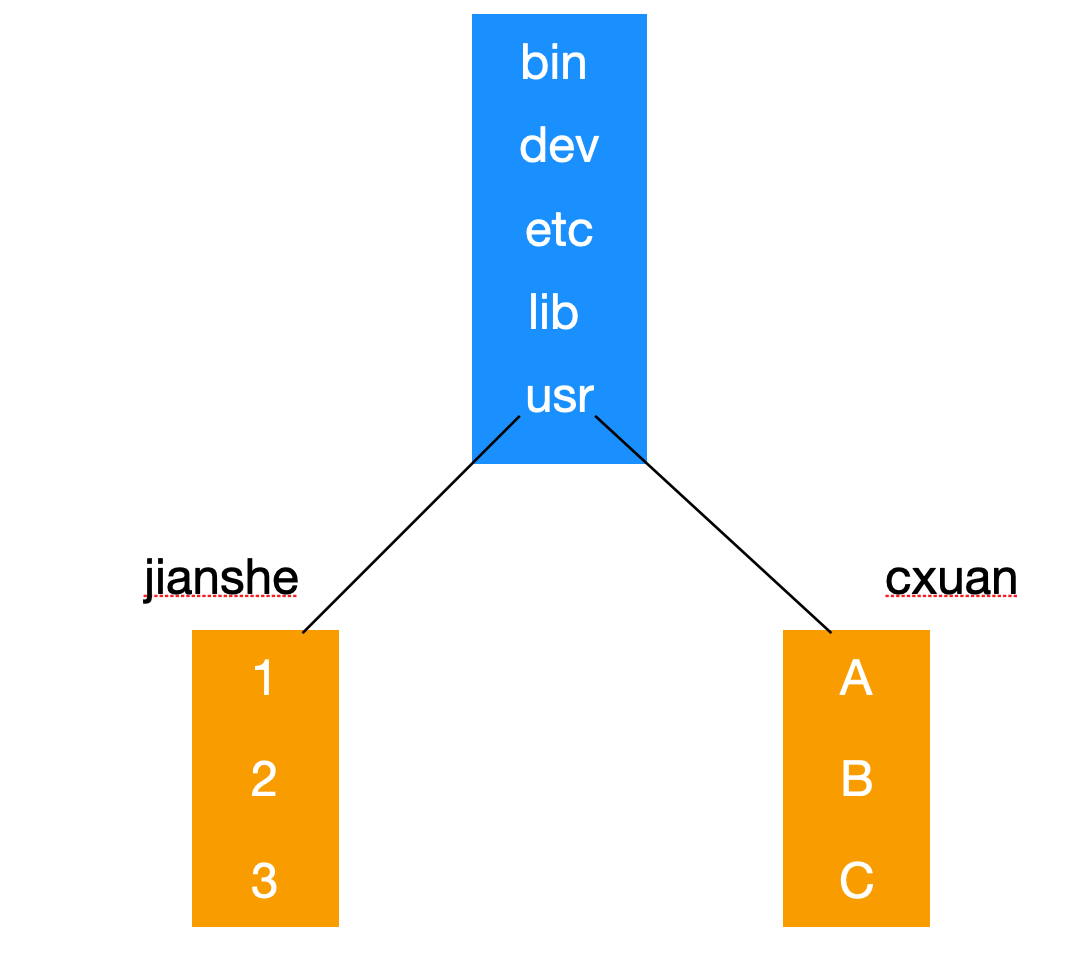
舉個例子,下面是一個使用鏈接之前的圖
以上所示,比如有兩個工作賬戶 jianshe 和 cxuan,jianshe 想要使用 cxuan 賬戶下的 A 目錄,那么它可能會輸入/usr/cxuan/A,這是一種未使用鏈接之后的圖。
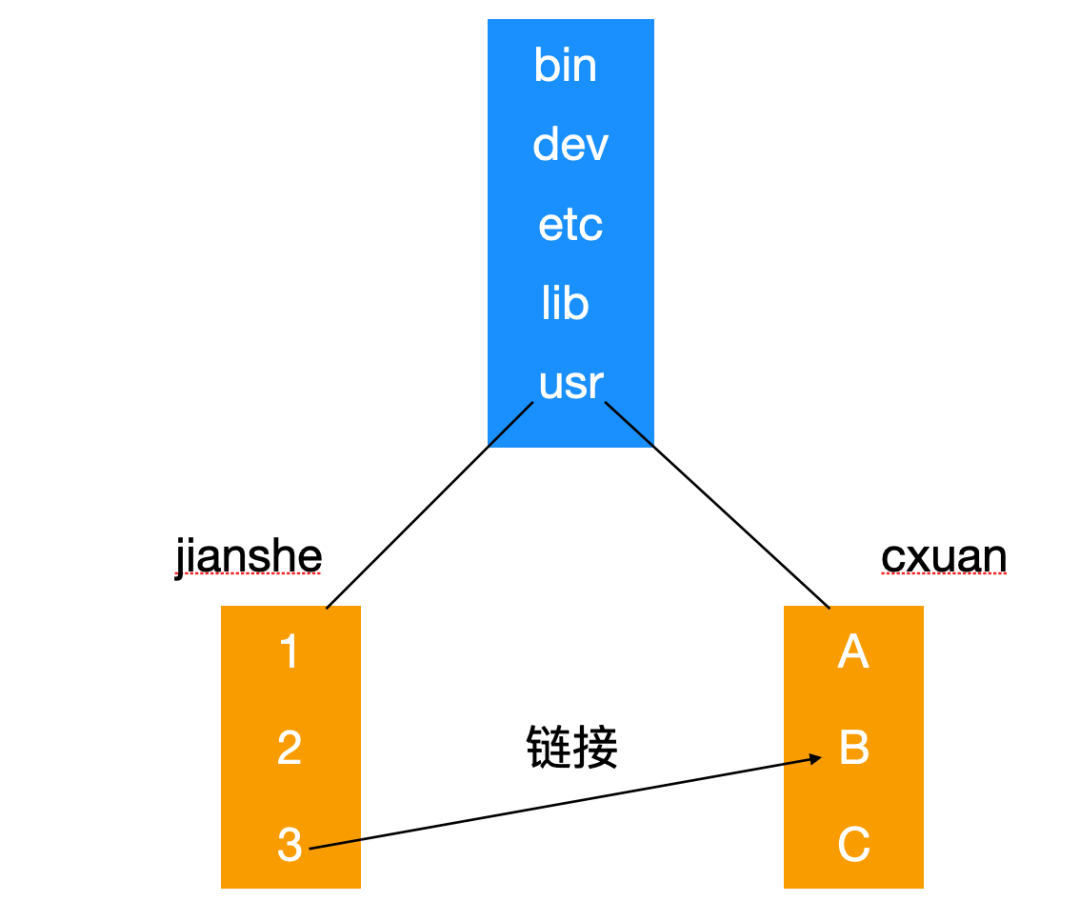
使用鏈接后的示意如下
現在,jianshe 可以創建一個鏈接來使用 cxuan 下面的目錄了。‘
當一個目錄被創建出來后,有兩個目錄項也同時被創建出來,它們就是.和..,前者代表工作目錄自身,后者代表該目錄的父目錄,也就是該目錄所在的目錄。這樣一來,在 /usr/jianshe 中訪問 cxuan 中的目錄就是../cxuan/xxx
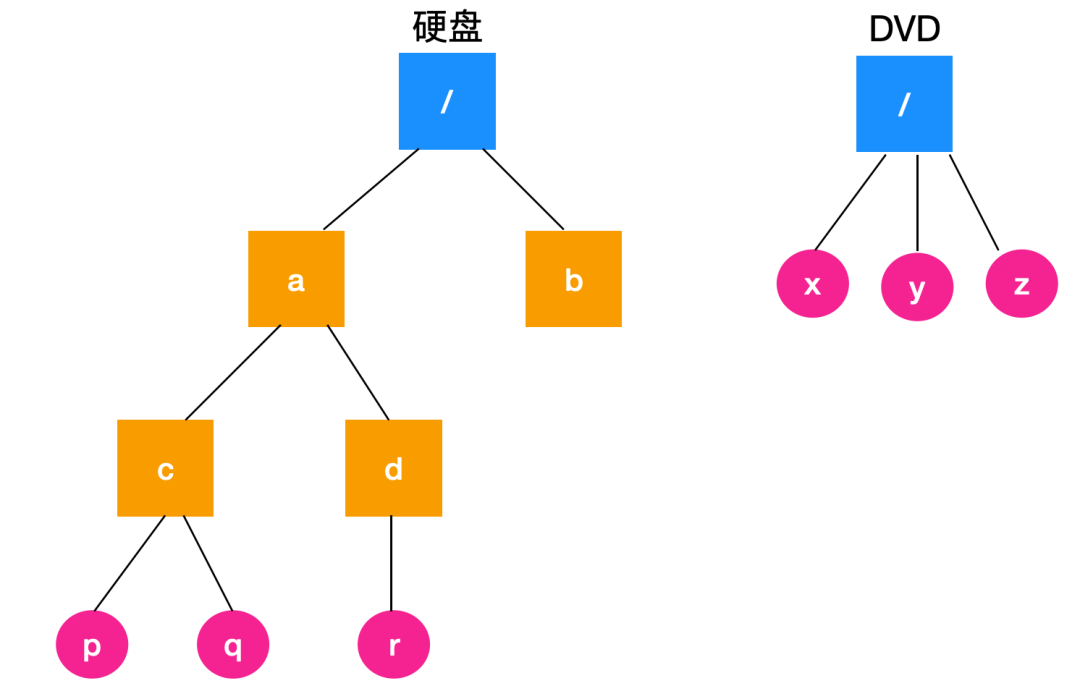
Linux 文件系統不區分磁盤的,這是什么意思呢?一般來說,一個磁盤中的文件系統相互之間保持獨立,如果一個文件系統目錄想要訪問另一個磁盤中的文件系統,在 Windows 中你可以像下面這樣。
兩個文件系統分別在不同的磁盤中,彼此保持獨立。
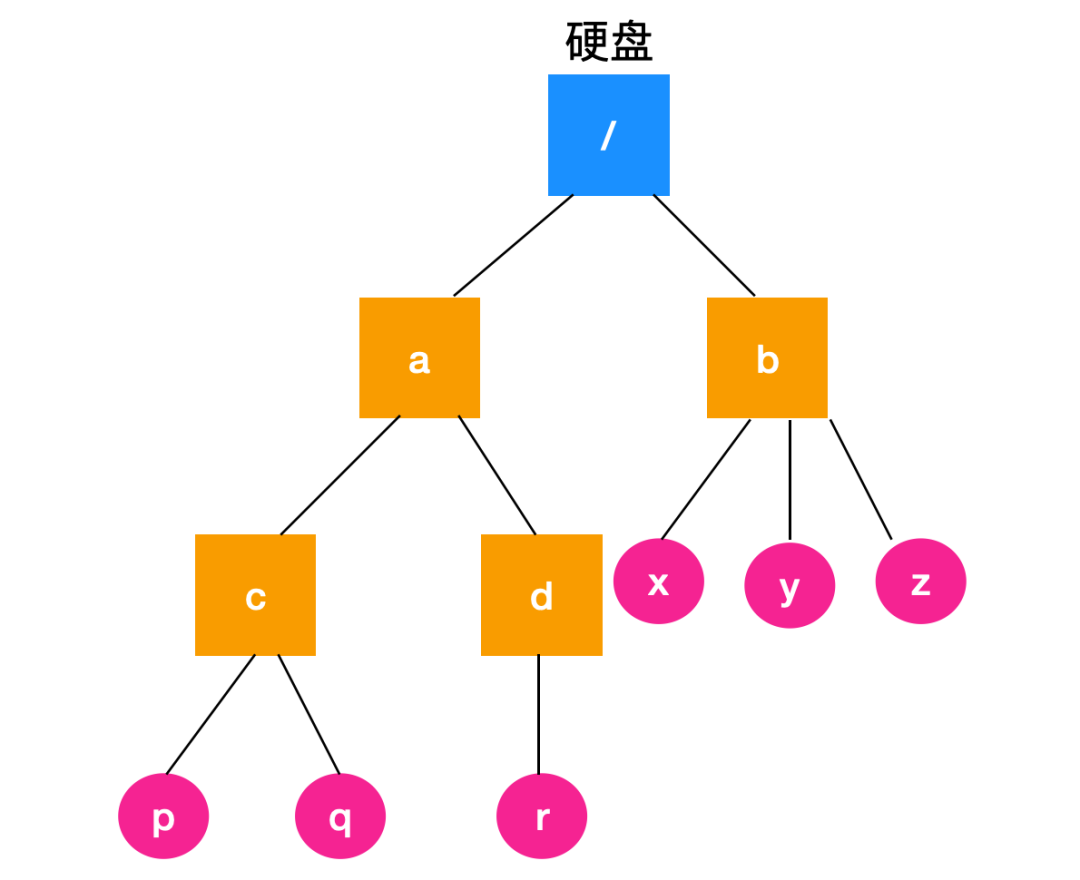
而在 Linux 中,是支持掛載的,它允許一個磁盤掛在到另外一個磁盤上,那么上面的關系會變成下面這樣
掛在之后,兩個文件系統就不再需要關心文件系統在哪個磁盤上了,兩個文件系統彼此可見。
Linux 文件系統的另外一個特性是支持加鎖(locking)。在一些應用中會出現兩個或者更多的進程同時使用同一個文件的情況,這樣很可能會導致競爭條件(race condition)。一種解決方法是對其進行加不同粒度的鎖,就是為了防止某一個進程只修改某一行記錄從而導致整個文件都不能使用的情況。
POSIX 提供了一種靈活的、不同粒度級別的鎖機制,允許一個進程使用一個不可分割的操作對一個字節或者整個文件進行加鎖。加鎖機制要求嘗試加鎖的進程指定其「要加鎖的文件,開始位置以及要加鎖的字節」
Linux 系統提供了兩種鎖:「共享鎖和互斥鎖」。如果文件的一部分已經加上了共享鎖,那么再加排他鎖是不會成功的;如果文件系統的一部分已經被加了互斥鎖,那么在互斥鎖解除之前的任何加鎖都不會成功。為了成功加鎖、請求加鎖的部分的所有字節都必須是可用的。
在加鎖階段,進程需要設計好加鎖失敗后的情況,也就是判斷加鎖失敗后是否選擇阻塞,如果選擇阻塞式,那么當已經加鎖的進程中的鎖被刪除時,這個進程會解除阻塞并替換鎖。如果進程選擇非阻塞式的,那么就不會替換這個鎖,會立刻從系統調用中返回,標記狀態碼表示是否加鎖成功,然后進程會選擇下一個時間再次嘗試。
加鎖區域是可以重疊的。下面我們演示了三種不同條件的加鎖區域。
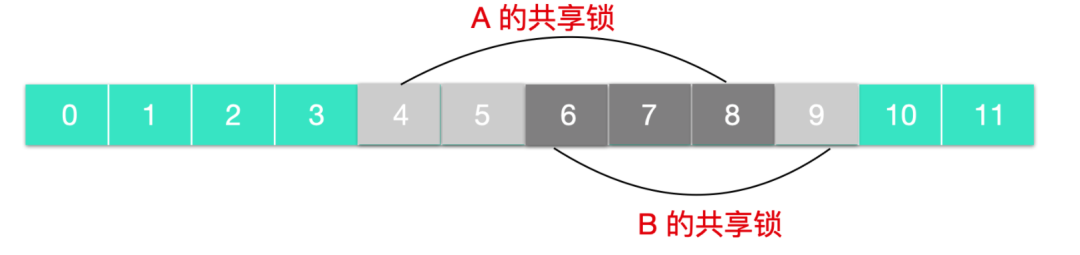
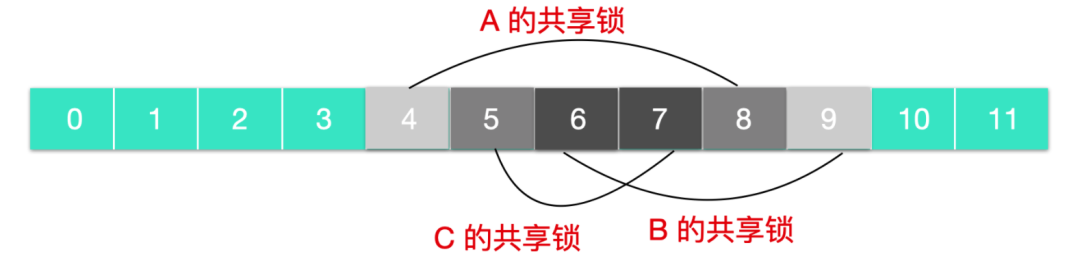
如上圖所示,A 的共享鎖在第四字節到第八字節進行加鎖
如上圖所示,進程在 A 和 B 上同時加了共享鎖,其中 6 - 8 字節是重疊鎖
如上圖所示,進程 A 和 B 和 C 同時加了共享鎖,那么第六字節和第七字節是共享鎖。
如果此時一個進程嘗試在第 6 個字節處加鎖,此時會設置失敗并阻塞,由于該區域被 A B C 同時加鎖,那么只有等到 A B C 都釋放鎖后,進程才能加鎖成功。
Linux 文件系統調用
許多系統調用都會和文件與文件系統有關。我們首先先看一下對單個文件的系統調用,然后再來看一下對整個目錄和文件的系統調用。
為了創建一個新的文件,會使用到creat方法,注意沒有e。
?這里說一個小插曲,曾經有人問 UNIX 創始人 Ken Thompson,如果有機會重新寫 UNIX ,你會怎么辦,他回答自己要把 creat 改成 create ,哈哈哈哈。?
這個系統調用的兩個參數是文件名和保護模式
fd=creat("aaa",mode);
這段命令會創建一個名為 aaa 的文件,并根據 mode 設置文件的保護位。這些位決定了哪個用戶可能訪問文件、如何訪問。
creat 系統調用不僅僅創建了一個名為 aaa 的文件,還會打開這個文件。為了允許后續的系統調用訪問這個文件,這個 creat 系統調用會返回一個非負整數, 這個就叫做文件描述符(file descriptor),也就是上面的 fd。
如果在已經存在的文件上調用了 creat 系統調用,那么該文件中的內容會被清除,從 0 開始。通過設置合適的參數,open系統調用也能夠創建文件。
下面讓我們看一看主要的系統調用,如下表所示
為了對一個文件進行讀寫的前提是先需要打開文件,必須使用 creat 或者 open 打開,參數是打開文件的方式,是只讀、可讀寫還是只寫。open 系統調用也會返回文件描述符。打開文件后,需要使用close系統調用進行關閉。close 和 open 返回的 fd 總是未被使用的最小數量。
?
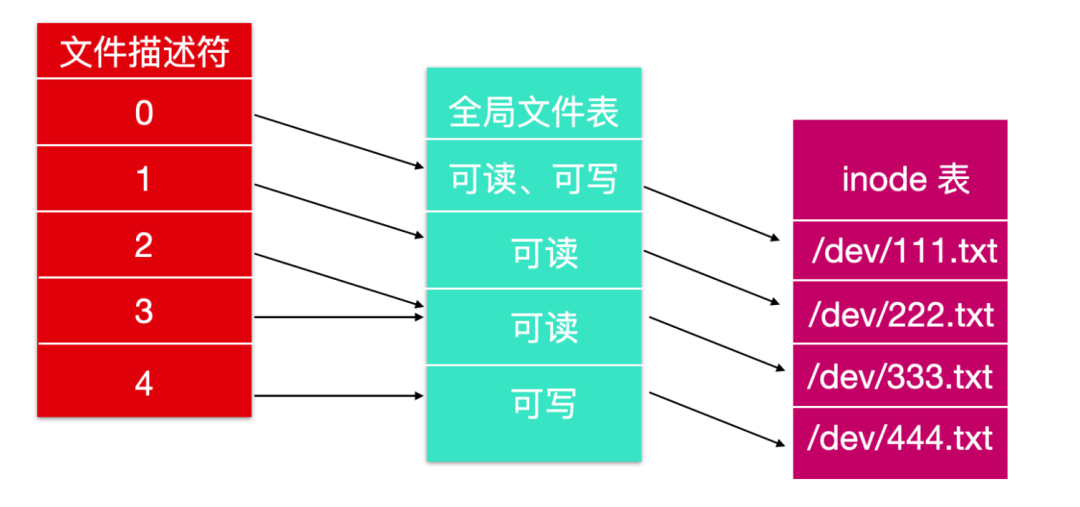
什么是文件描述符?文件描述符就是一個數字,這個數字標示了計算機操作系統中打開的文件。它描述了數據資源,以及訪問資源的方式。
?
當程序要求打開一個文件時,內核會進行如下操作
授予訪問權限
在全局文件表(global file table)中創建一個條目(entry)
向軟件提供條目的位置
文件描述符由唯一的非負整數組成,系統上每個打開的文件至少存在一個文件描述符。文件描述符最初在 Unix 中使用,并且被包括 Linux,macOS 和 BSD 在內的現代操作系統所使用。
當一個進程成功訪問一個打開的文件時,內核會返回一個文件描述符,這個文件描述符指向全局文件表的 entry 項。這個文件表項包含文件的 inode 信息,字節位移,訪問限制等。例如下圖所示
默認情況下,前三個文件描述符為STDIN(標準輸入)、STDOUT(標準輸出)、STDERR(標準錯誤)。
標準輸入的文件描述符是 0 ,在終端中,默認為用戶的鍵盤輸入
標準輸出的文件描述符是 1 ,在終端中,默認為用戶的屏幕
與錯誤有關的默認數據流是 2,在終端中,默認為用戶的屏幕。
在簡單聊了一下文件描述符后,我們繼續回到文件系統調用的探討。
在文件系統調用中,開銷最大的就是 read 和 write 了。read 和 write 都有三個參數
文件描述符:告訴需要對哪一個打開文件進行讀取和寫入
緩沖區地址:告訴數據需要從哪里讀取和寫入哪里
統計:告訴需要傳輸多少字節
這就是所有的參數了,這個設計非常簡單輕巧。
雖然幾乎所有程序都按順序讀取和寫入文件,但是某些程序需要能夠隨機訪問文件的任何部分。與每個文件相關聯的是一個指針,該指針指示文件中的當前位置。順序讀取(或寫入)時,它通常指向要讀取(寫入)的下一個字節。如果指針在讀取 1024 個字節之前位于 4096 的位置,則它將在成功讀取系統調用后自動移至 5120 的位置。
Lseek系統調用會更改指針位置的值,以便后續對 read 或 write 的調用可以在文件中的任何位置開始,甚至可以超出文件末尾。
?lseek = Lseek ,段首大寫。?
lseek 避免叫做 seek 的原因就是 seek 已經在之前 16 位的計算機上用于搜素功能了。
Lseek有三個參數:第一個是文件的文件描述符,第二個是文件的位置;第三個告訴文件位置是相對于文件的開頭,當前位置還是文件的結尾
lseek(intfildes,off_toffset,intwhence);
lseek 的返回值是更改文件指針后文件中的絕對位置。lseek 是唯一從來不會造成真正磁盤查找的系統調用,它只是更新當前的文件位置,這個文件位置就是內存中的數字。
對于每個文件,Linux 都會跟蹤文件模式(常規,目錄,特殊文件),大小,最后修改時間以及其他信息。程序能夠通過stat系統調用看到這些信息。第一個參數就是文件名,第二個是指向要放置請求信息結構的指針。這些結構的屬性如下圖所示。
fstat調用和stat相同,只有一點區別,fstat 可以對打開文件進行操作,而 stat 只能對路徑進行操作。
pipe文件系統調用被用來創建 shell 管道。它會創建一系列的偽文件,來緩沖和管道組件之間的數據,并且返回讀取或者寫入緩沖區的文件描述符。在管道中,像是如下操作
sort
sort 進程將會輸出到文件描述符1,也就是標準輸出,寫入管道中,而 head 進程將從管道中讀入。在這種方式中,sort 只是從文件描述符 0 中讀取并寫入到文件描述符 1 (管道)中,甚至不知道它們已經被重定向了。如果沒有重定向的話,sort 會自動的從鍵盤讀入并輸出到屏幕中。
最后一個系統調用是fcntl,它用來鎖定和解鎖文件,應用共享鎖和互斥鎖,或者是執行一些文件相關的其他操作。
現在我們來關心一下和整體目錄和文件系統相關的系統調用,而不是把精力放在單個的文件上,下面列出了這些系統調用,我們一起來看一下。
可以使用 mkdir 和 rmdir 創建和刪除目錄。但是需要注意,只有目錄為空時才可以刪除。
創建一個指向已有文件的鏈接時會創建一個目錄項(directory entry)。系統調用 link 來創建鏈接,oldpath 代表已有的路徑,newpath 代表需要鏈接的路徑,使用unlink可以刪除目錄項。當文件的最后一個鏈接被刪除時,這個文件會被自動刪除。
使用chdir系統調用可以改變工作目錄。
最后四個系統調用是用于讀取目錄的。和普通文件類似,他們可以被打開、關閉和讀取。每次調用readdir都會以固定的格式返回一個目錄項。用戶不能對目錄執行寫操作,但是可以使用 creat 或者 link 在文件夾中創建一個目錄,或使用 unlink 刪除一個目錄。用戶不能在目錄中查找某個特定文件,但是可以使用rewindir作用于一個打開的目錄,使他能在此從頭開始讀取。
Linux 文件系統的實現
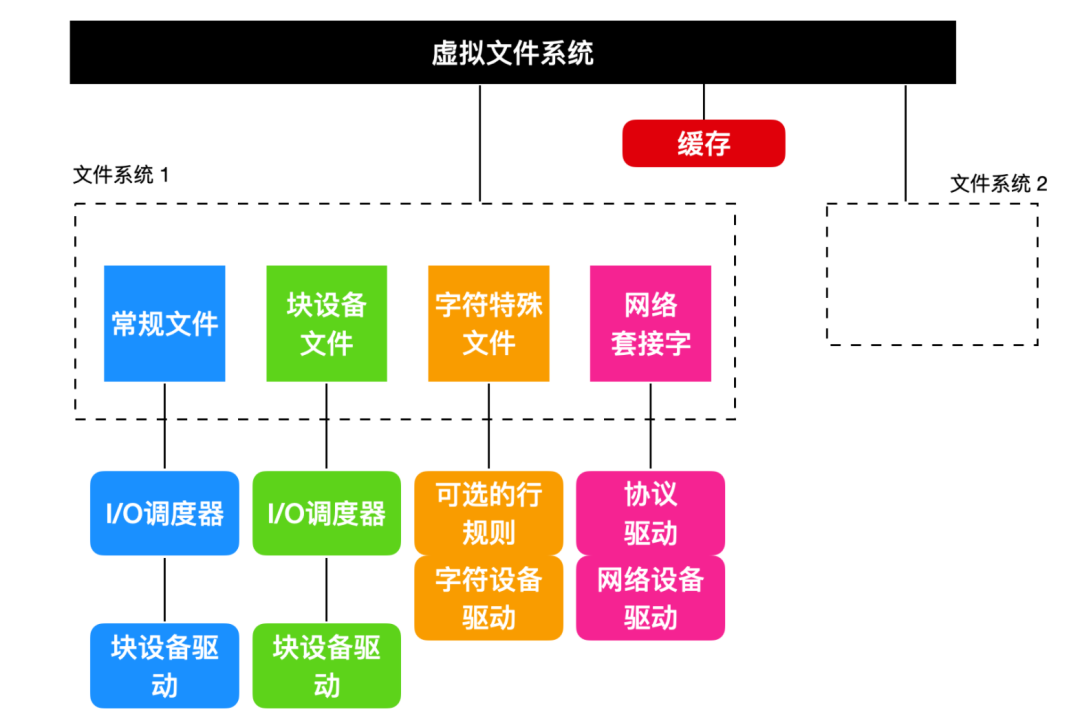
下面我們主要討論一下虛擬文件系統(Virtual File System)。VFS 對高層進程和應用程序隱藏了 Linux 支持的所有文件系統的區別,以及文件系統是存儲在本地設備,還是需要通過網絡訪問遠程設備。設備和其他特殊文件和 VFS 層相關聯。接下來,我們就會探討一下第一個 Linux 廣泛傳播的文件系統:ext2。隨后,我們就會探討ext4文件系統所做的改進。各種各樣的其他文件系統也正在使用中。所有 Linux 系統都可以處理多個磁盤分區,每個磁盤分區上都有不同的文件系統。
Linux 虛擬文件系統
為了能夠使應用程序能夠在不同類型的本地或者遠程設備上的文件系統進行交互,因為在 Linux 當中文件系統千奇百種,比較常見的有 EXT3、EXT4,還有基于內存的 ramfs、tmpfs 和基于網絡的 nfs,和基于用戶態的 fuse,當然 fuse 應該不能完全的文件系統,只能算是一個能把文件系統實現放到用戶態的模塊,滿足了內核文件系統的接口,他們都是文件系統的一種實現。對于這些文件系統,Linux 做了一層抽象就是VFS虛擬文件系統,
下表總結了 VFS 支持的四個主要的文件系統結構。
超級塊(superblock)包含了有關文件系統布局的重要信息,超級塊如果遭到破壞那么就會導致整個文件系統不可讀。
i-node索引節點,包含了每一個文件的描述符。
?
在 Linux 中,目錄和設備也表示為文件,因為它們具有對應的 i-node
?
超級塊和索引塊所在的文件系統都在磁盤上有對應的結構。
為了便于某些目錄操作和路徑遍歷,比如 /usr/local/cxuan,VFS 支持一個dentry數據結構,該數據結構代表著目錄項。這個 dentry 數據結構有很多東西(http://books.gigatux.nl/mirror/kerneldevelopment/0672327201/ch12lev1sec7.html)這個數據結構由文件系統動態創建。
目錄項被緩存在dentry_cache緩存中。例如,緩存條目會緩存 /usr 、 /usr/local 等條目。如果多個進程通過硬連接訪問相同的文件,他們的文件對象將指向此緩存中的相同條目。
最后,文件數據結構是代表著打開的文件,也代表著內存表示,它根據 open 系統調用創建。它支持「read、write、sendfile、lock」和其他在我們之前描述的系統調用中。
在 VFS 下實現的實際文件系統不需要在內部使用完全相同的抽象和操作。但是,它們必須在語義上實現與 VFS 對象指定的文件系統操作相同的文件系統操作。四個 VFS 對象中每個對象的操作數據結構的元素都是指向基礎文件系統中功能的指針。
Linux Ext2 文件系統
現在我們一起看一下 Linux 中最流行的一個磁盤文件系統,那就是ext2。Linux 的第一個版本用于MINIX1文件系統,它的文件名大小被限制為最大 64 MB。MINIX 1 文件系統被永遠的被它的擴展系統 ext 取代,因為 ext 允許更長的文件名和文件大小。由于 ext 的性能低下,ext 被其替代者 ext2 取代,ext2 目前仍在廣泛使用。
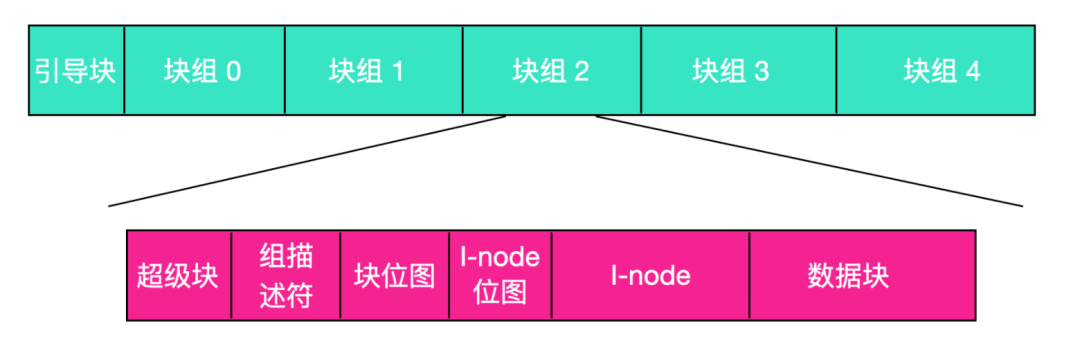
一個 ext2 Linux 磁盤分區包含了一個文件系統,這個文件系統的布局如下所示
Boot 塊也就是第 0 塊不是讓 Linux 使用的,而是用來加載和引導計算機啟動代碼的。在塊 0 之后,磁盤分區被分成多個組,這些組與磁盤柱面邊界所處的位置無關。
第一個塊是超級塊(superblock)。它包含有關文件系統布局的信息,包括 i-node、磁盤塊數量和以及空閑磁盤塊列表的開始。下一個是組描述符(group descriptor),其中包含有關位圖的位置,組中空閑塊和 i-node 的數量以及組中的目錄數量的信息。這些信息很重要,因為 ext2 會在磁盤上均勻分布目錄。
圖中的兩個位圖用來記錄空閑塊和空閑 i-node,這是從 MINIX 1文件系統繼承的選擇,大多數 UNIX 文件系統使用位圖而不是空閑列表。每個位圖的大小是一個塊。如果一個塊的大小是 1 KB,那么就限制了塊組的數量是 8192 個塊和 8192 個 i-node。塊的大小是一個嚴格的限制,塊組的數量不固定,在 4KB 的塊中,塊組的數量增大四倍。
在超級塊之后分布的是i-node它們自己,i-node 取值范圍是 1 - 某些最大值。每個 i-node 是 128 字節的long,這些字節恰好能夠描述一個文件。i-node 包含了統計信息(包含了stat系統調用能獲得的所有者信息,實際上 stat 就是從 i-node 中讀取信息的),以及足夠的信息來查找保存文件數據的所有磁盤塊。
在 i-node 之后的是數據塊(data blocks)。所有的文件和目錄都保存在這。如果一個文件或者目錄包含多個塊,那么這些塊在磁盤中的分布不一定是連續的,也有可能不連續。事實上,大文件塊可能會被拆分成很多小塊散布在整個磁盤上。
對應于目錄的 i-node 分散在整個磁盤組上。如果有足夠的空間,ext2 會把普通文件組織到與父目錄相同的塊組中,而把同一塊上的數據文件組織成初始i-node節點。位圖用來快速確定新文件系統數據的分配位置。在分配新的文件塊時,ext2 也會給該文件預分配許多額外的數據塊,這樣可以減少將來向文件寫入數據時產生的文件碎片。這種策略在整個磁盤上實現了文件系統的負載,后續還有對文件碎片的排列和整理,而且性能也比較好。
為了達到訪問的目的,需要首先使用 Linux 系統調用,例如open,這個系統調用會確定打開文件的路徑。路徑分為兩種,相對路徑和絕對路徑。如果使用相對路徑,那么就會從當前目錄開始查找,否則就會從根目錄進行查找。
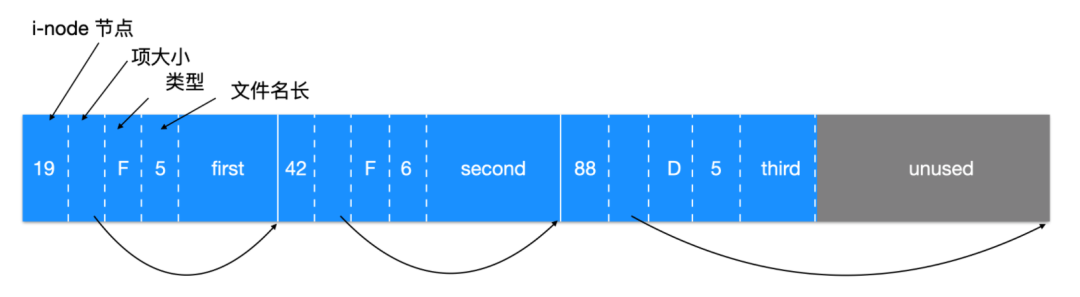
目錄文件的文件名最高不能超過 255 個字符,它的分配如下圖所示
每一個目錄都由整數個磁盤塊組成,這樣目錄就可以整體的寫入磁盤。在一個目錄中,文件和子目錄的目錄項都是未經排序的,并且一個挨著一個。目錄項不能跨越磁盤塊,所以通常在每個磁盤塊的尾部會有部分未使用的字節。
上圖中每個目錄項都由四個固定長度的屬性和一個長度可變的屬性組成。第一個屬性是i-node節點數量,文件 first 的 i-node 編號是 19 ,文件 second 的編號是 42,目錄 third 的 i-node 編號是 88。緊隨其后的是rec_len域,表明目錄項大小是多少字節,名稱后面會有一些擴展,當名字以未知長度填充時,這個域被用來尋找下一個目錄項,直至最后的未使用。這也是圖中箭頭的含義。緊隨其后的是類型域:F 表示的是文件,D 表示的是目錄,最后是固定長度的文件名,上面的文件名的長度依次是 5、6、5,最后以文件名結束。
rec_len 域是如何擴展的呢?如下圖所示
我們可以看到,中間的second被移除了,所以將其所在的域變為第一個目錄項的填充。當然,這個填充可以作為后續的目錄項。
由于目錄是按照線性的順序進行查找的,因此可能需要很長時間才能在大文件末尾找到目錄項。因此,系統會為近期的訪問目錄維護一個緩存。這個緩存用文件名來查找,如果緩存命中,那么就會避免線程搜索這樣昂貴的開銷。組成路徑的每個部分都在目錄緩存中保存一個dentry對象,并且通過 i-node 找到后續的路徑元素的目錄項,直到找到真正的文件 i - node。
比如說要使用絕對路徑來尋找一個文件,我們暫定這個路徑是/usr/local/file,那么需要經過如下幾個步驟:
首先,系統會確定根目錄,它通常使用 2 號 i -node ,也就是索引 2 節點,因為索引節點 1 是 ext2 /3/4 文件系統上的壞塊索引節點。系統會將一項放在 dentry 緩存中,以應對將來對根目錄的查找。
然后,在根目錄中查找字符串usr,得到 /usr 目錄的 i - node 節點號。/usr 的 i - node 同樣也進入 dentry 緩存。然后節點被取出,并從中解析出磁盤塊,這樣就可以讀取 /usr 目錄并查找字符串local了。一旦找到這個目錄項,目錄/usr/local的 i - node 節點就可以從中獲得。有了 /usr/local 的 i - node 節點號,就可以讀取 i - node 并確定目錄所在的磁盤塊。最后,從 /usr/local 目錄查找 file 并確定其 i - node 節點呢號。
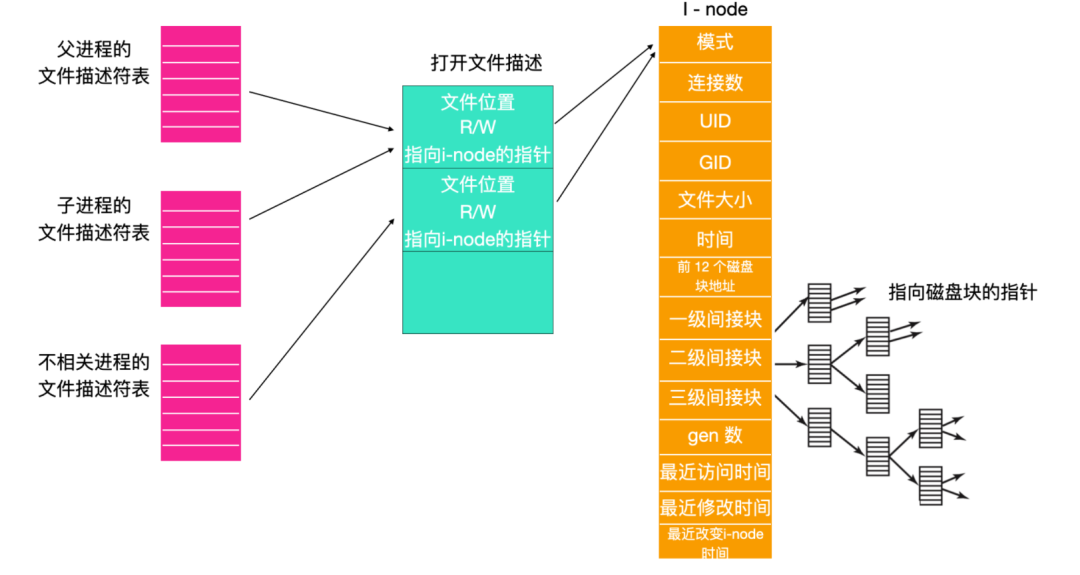
如果文件存在,那么系統會提取 i - node 節點號并把它作為索引在 i - node 節點表中定位相應的 i - node 節點并裝入內存。i - node 被存放在 i - node 節點表(i-node table)中,節點表是一個內核數據結構,它會持有當前打開文件和目錄的 i - node 節點號。下面是一些 Linux 文件系統支持的 i - node 數據結構。
現在我們來一起探討一下文件讀取過程,還記得read函數是如何調用的嗎?
n=read(fd,buffer,nbytes);
當內核接管后,它會從這三個參數以及內部表與用戶有關的信息開始。內部表的其中一項是文件描述符數組。文件描述符數組用文件描述符作為索引并為每一個打開文件保存一個表項。
文件是和 i - node 節點號相關的。那么如何通過一個文件描述符找到文件對應的 i - node 節點呢?
這里使用的一種設計思想是在文件描述符表和 i - node 節點表之間插入一個新的表,叫做打開文件描述符(open-file-description table)。文件的讀寫位置會在打開文件描述符表中存在,如下圖所示
我們使用 shell 、P1 和 P2 來描述一下父進程、子進程、子進程的關系。Shell 首先生成 P1,P1 的數據結構就是 Shell 的一個副本,因此兩者都指向相同的打開文件描述符的表項。當 P1 運行完成后,Shell 的文件描述符仍會指向 P1 文件位置的打開文件描述。然后 Shell 生成了 P2,新的子進程自動繼承文件的讀寫位置,甚至 P2 和 Shell 都不知道文件具體的讀寫位置。
上面描述的是父進程和子進程這兩個相關進程,如果是一個不相關進程打開文件時,它將得到自己的打開文件描述符表項,以及自己的文件讀寫位置,這是我們需要的。
?因此,打開文件描述符相當于是給相關進程提供同一個讀寫位置,而給不相關進程提供各自私有的位置。?
i - node 包含三個間接塊的磁盤地址,它們每個指向磁盤塊的地址所能夠存儲的大小不一樣。
Linux Ext4 文件系統
為了防止由于系統崩潰和電源故障造成的數據丟失,ext2 系統必須在每個數據塊創建之后立即將其寫入到磁盤上,磁盤磁頭尋道操作導致的延遲是無法讓人忍受的。為了增強文件系統的健壯性,Linux 依靠日志文件系統,ext3 是一個日志文件系統,它在 ext2 文件系統的基礎之上做了改進,ext4 也是 ext3 的改進,ext4 也是一個日志文件系統。ext4 改變了 ext3 的塊尋址方案,從而支持更大的文件和更大的文件系統大小。下面我們就來描述一下 ext4 文件系統的特性。
具有記錄的文件系統最基本的功能就是記錄日志,這個日志記錄了按照順序描述所有文件系統的操作。通過順序寫出文件系統數據或元數據的更改,操作不受磁盤訪問期間磁盤頭移動的開銷。最終,這個變更會寫入并提交到合適的磁盤位置上。如果這個變更在提交到磁盤前文件系統宕機了,那么在重啟期間,系統會檢測到文件系統未正確卸載,那么就會遍歷日志并應用日志的記錄來對文件系統進行更改。
Ext4 文件系統被設計用來高度匹配 ext2 和 ext3 文件系統的,盡管 ext4 文件系統在內核數據結構和磁盤布局上都做了變更。盡管如此,一個文件系統能夠從 ext2 文件系統上卸載后成功的掛載到 ext4 文件系統上,并提供合適的日志記錄。
日志是作為循環緩沖區管理的文件。日志可以存儲在與主文件系統相同或者不同的設備上。日志記錄的讀寫操作會由單獨的JBD(Journaling Block Device)來扮演。
JBD 中有三個主要的數據結構,分別是「log record(日志記錄)、原子操作和事務」。一個日志記錄描述了一個低級別的文件系統操作,這個操作通常導致塊內的變化。因為像是write這種系統調用會包含多個地方的改動 --- i - node 節點,現有的文件塊,新的文件塊和空閑列表等。相關的日志記錄會以原子性的方式分組。ext4 會通知系統調用進程的開始和結束,以此使 JBD 能夠確保原子操作的記錄都能被應用,或者一個也不被應用。最后,主要從效率方面考慮,JBD 會視原子操作的集合為事務。一個事務中的日志記錄是連續存儲的。只有在所有的變更一起應用到磁盤后,日志記錄才能夠被丟棄。
由于為每個磁盤寫出日志的開銷會很大,所以 ext4 可以配置為保留所有磁盤更改的日志,或者僅僅保留與文件系統元數據相關的日志更改。僅僅記錄元數據可以減少系統開銷,提升性能,但不能保證不會損壞文件數據。其他的幾個日志系統維護著一系列元數據操作的日志,例如 SGI 的 XFS。
/proc 文件系統
另外一個 Linux 文件系統是/proc(process) 文件系統
?它的主要思想來源于貝爾實驗室開發的第 8 版的 UNIX,后來被 BSD 和 System V 采用。?
然而,Linux 在一些方面上對這個想法進行了擴充。它的基本概念是為系統中的每個進程在/proc中創建一個目錄。目錄的名字就是進程 PID,以十進制數進行表示。例如,/proc/1024就是一個進程號為 1024 的目錄。在該目錄下是進程信息相關的文件,比如進程的命令行、環境變量和信號掩碼等。事實上,這些文件在磁盤上并不存在磁盤中。當需要這些信息的時候,系統會按需從進程中讀取,并以標準格式返回給用戶。
許多 Linux 擴展與/proc中的其他文件和目錄有關。它們包含各種各樣的關于 CPU、磁盤分區、設備、中斷向量、內核計數器、文件系統、已加載模塊等信息。非特權用戶可以讀取很多這樣的信息,于是就可以通過一種安全的方式了解系統情況。
NFS 網絡文件系統
從一開始,網絡就在 Linux 中扮演了很重要的作用。下面我們會探討一下NFS(Network File System)網絡文件系統,它在現代 Linux 操作系統的作用是將不同計算機上的不同文件系統鏈接成一個邏輯整體。
NFS 架構
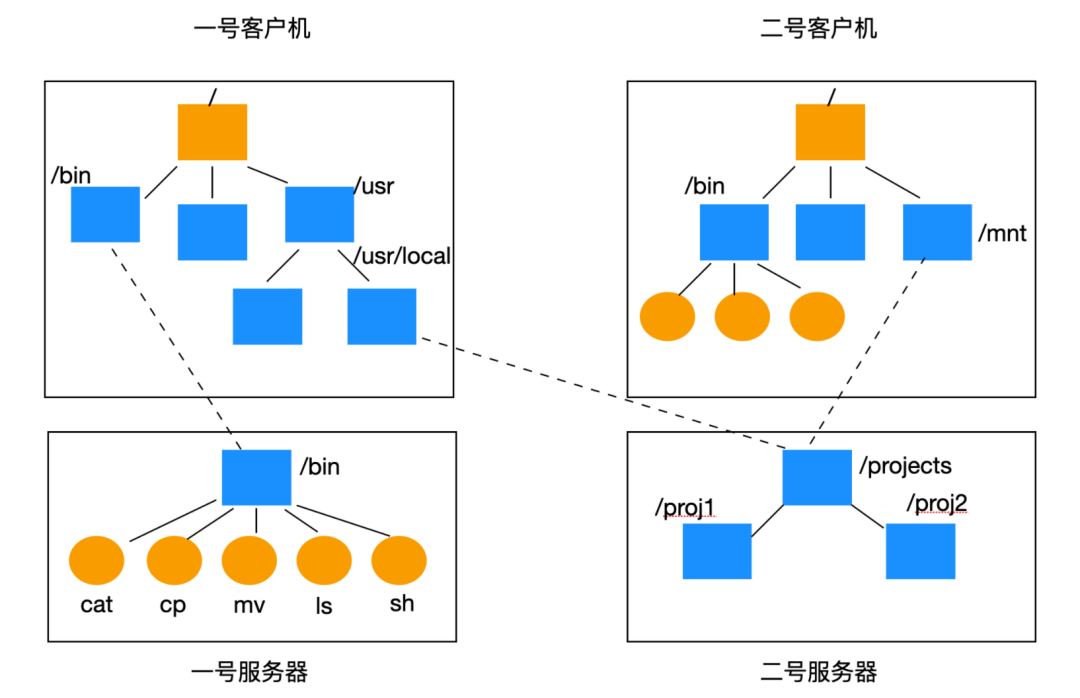
NFS 最基本的思想是允許任意選定的一些客戶端和服務器共享一個公共文件系統。在許多情況下,所有的客戶端和服務器都會在同一個LAN(Local Area Network)局域網內共享,但是這并不是必須的。也可能是下面這樣的情況:如果客戶端和服務器距離較遠,那么它們也可以在廣域網上運行。客戶端可以是服務器,服務器可以是客戶端,但是為了簡單起見,我們說的客戶端就是消費服務,而服務器就是提供服務的角度來聊。
每一個 NFS 服務都會導出一個或者多個目錄供遠程客戶端訪問。當一個目錄可用時,它的所有子目錄也可用。因此,通常整個目錄樹都會作為一個整體導出。服務器導出的目錄列表會用一個文件來維護,這個文件是/etc/exports,當服務器啟動后,這些目錄可以自動的被導出。客戶端通過掛載這些導出的目錄來訪問它們。當一個客戶端掛載了一個遠程目錄,這個目錄就成為客戶端目錄層次的一部分,如下圖所示。
在這個示例中,一號客戶機掛載到服務器的 bin 目錄下,因此它現在可以使用 shell 訪問 /bin/cat 或者其他任何一個目錄。同樣,客戶機 1 也可以掛載到 二號服務器上從而訪問 /usr/local/projects/proj1 或者其他目錄。二號客戶機同樣可以掛載到二號服務器上,訪問路徑是 /mnt/projects/proj2。
從上面可以看到,由于不同的客戶端將文件掛載到各自目錄樹的不同位置,同一個文件在不同的客戶端有不同的訪問路徑和不同的名字。掛載點一般通常在客戶端本地,服務器不知道任何一個掛載點的存在。
NFS 協議
由于 NFS 的協議之一是支持異構系統,客戶端和服務器可能在不同的硬件上運行不同的操作系統,因此有必要在服務器和客戶端之間進行接口定義。這樣才能讓任何寫一個新客戶端能夠和現有的服務器一起正常工作,反之亦然。
NFS 就通過定義兩個客戶端 - 服務器協議從而實現了這個目標。協議就是客戶端發送給服務器的一連串的請求,以及服務器發送回客戶端的相應答復。
第一個 NFS 協議是處理掛載。客戶端可以向服務器發送路徑名并且請求服務器是否能夠將服務器的目錄掛載到自己目錄層次上。因為服務器不關心掛載到哪里,因此請求不會包含掛載地址。如果路徑名是合法的并且指定的目錄已經被導出,那么服務器會將文件句柄返回給客戶端。
?文件句柄包含唯一標識文件系統類型,磁盤,目錄的i節點號和安全性信息的字段。?
隨后調用讀取和寫入已安裝目錄或其任何子目錄中的文件,都將使用文件句柄。
當 Linux 啟動時會在多用戶之前運行 shell 腳本 /etc/rc 。可以將掛載遠程文件系統的命令寫入該腳本中,這樣就可以在允許用戶登陸之前自動掛載必要的遠程文件系統。大部分 Linux 版本是支持自動掛載的。這個特性會支持將遠程目錄和本地目錄進行關聯。
相對于手動掛載到 /etc/rc 目錄下,自動掛載具有以下優勢
如果列出的 /etc/rc 目錄下出現了某種故障,那么客戶端將無法啟動,或者啟動會很困難、延遲或者伴隨一些出錯信息,如果客戶根本不需要這個服務器,那么手動做了這些工作就白費了。
允許客戶端并行的嘗試一組服務器,可以實現一定程度的容錯率,并且性能也可以得到提高。
另一方面,我們默認在自動掛載時所有可選的文件系統都是相同的。由于 NFS 不提供對文件或目錄復制的支持,用戶需要自己確保這些所有的文件系統都是相同的。因此,大部分的自動掛載都只應用于二進制文件和很少改動的只讀的文件系統。
第二個 NFS 協議是為文件和目錄的訪問而設計的。客戶端能夠通過向服務器發送消息來操作目錄和讀寫文件。客戶端也可以訪問文件屬性,比如文件模式、大小、上次修改時間。NFS 支持大多數的 Linux 系統調用,但是 open 和 close 系統調用卻不支持。
?不支持 open 和 close 并不是一種疏忽,而是一種刻意的設計,完全沒有必要在讀一個文件之前對其進行打開,也沒有必要在讀完時對其進行關閉。?
NFS 使用了標準的 UNIX 保護機制,使用rwx位來標示所有者(owner)、組(groups)、其他用戶。最初,每個請求消息都會攜帶調用者的 groupId 和 userId,NFS 會對其進行驗證。事實上,它會信任客戶端不會發生欺騙行為。可以使用公鑰密碼來創建一個安全密鑰,在每次請求和應答中使用它驗證客戶端和服務器。
NFS 實現
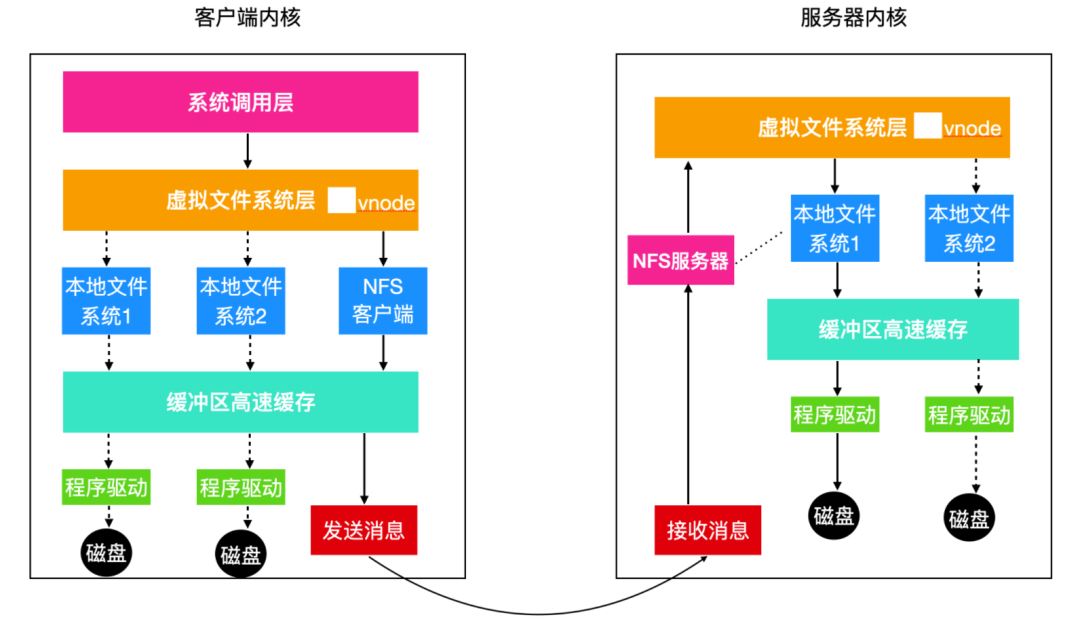
即使客戶端和服務器的代碼實現是獨立于 NFS 協議的,大部分的 Linux 系統會使用一個下圖的三層實現,頂層是系統調用層,系統調用層能夠處理 open 、 read 、 close 這類的系統調用。在解析和參數檢查結束后調用第二層,虛擬文件系統 (VFS)層。
VFS 層的任務是維護一個表,每個已經打開的文件都在表中有一個表項。VFS 層為每一個打開的文件維護著一個虛擬i節點,簡稱為 v - node。v 節點用來說明文件是本地文件還是遠程文件。如果是遠程文件的話,那么 v - node 會提供足夠的信息使客戶端能夠訪問它們。對于本地文件,會記錄其所在的文件系統和文件的 i-node ,因為現代操作系統能夠支持多文件系統。雖然 VFS 是為了支持 NFS 而設計的,但是現代操作系統都會使用 VFS,而不管有沒有 NFS。
Linux IO
我們之前了解過了 Linux 的進程和線程、Linux 內存管理,那么下面我們就來認識一下 Linux 中的 I/O 管理。
Linux 系統和其他 UNIX 系統一樣,IO 管理比較直接和簡潔。所有 IO 設備都被當作文件,通過在系統內部使用相同的 read 和 write 一樣進行讀寫。
Linux IO 基本概念
Linux 中也有磁盤、打印機、網絡等 I/O 設備,Linux 把這些設備當作一種特殊文件整合到文件系統中,一般通常位于/dev目錄下。可以使用與普通文件相同的方式來對待這些特殊文件。
特殊文件一般分為兩種:
塊特殊文件是一個能存儲固定大小塊信息的設備,它支持「以固定大小的塊,扇區或群集讀取和(可選)寫入數據」。每個塊都有自己的物理地址。通常塊的大小在 512 - 65536 之間。所有傳輸的信息都會以連續的塊為單位。塊設備的基本特征是每個塊都較為對立,能夠獨立的進行讀寫。常見的塊設備有「硬盤、藍光光盤、USB 盤」與字符設備相比,塊設備通常需要較少的引腳。
塊特殊文件的缺點基于給定固態存儲器的塊設備比基于相同類型的存儲器的字節尋址要慢一些,因為必須在塊的開頭開始讀取或寫入。所以,要讀取該塊的任何部分,必須尋找到該塊的開始,讀取整個塊,如果不使用該塊,則將其丟棄。要寫入塊的一部分,必須尋找到塊的開始,將整個塊讀入內存,修改數據,再次尋找到塊的開頭處,然后將整個塊寫回設備。
另一類 I/O 設備是字符特殊文件。字符設備以字符為單位發送或接收一個字符流,而不考慮任何塊結構。字符設備是不可尋址的,也沒有任何尋道操作。常見的字符設備有「打印機、網絡設備、鼠標、以及大多數與磁盤不同的設備」。
每個設備特殊文件都會和設備驅動相關聯。每個驅動程序都通過一個主設備號來標識。如果一個驅動支持多個設備的話,此時會在主設備的后面新加一個次設備號來標識。主設備號和次設備號共同確定了唯一的驅動設備。
我們知道,在計算機系統中,CPU 并不直接和設備打交道,它們中間有一個叫作設備控制器(Device Control Unit)的組件,例如硬盤有磁盤控制器、USB 有 USB 控制器、顯示器有視頻控制器等。這些控制器就像代理商一樣,它們知道如何應對硬盤、鼠標、鍵盤、顯示器的行為。
絕大多數字符特殊文件都不能隨機訪問,因為他們需要使用和塊特殊文件不同的方式來控制。比如,你在鍵盤上輸入了一些字符,但是你發現輸錯了一個,這時有一些人喜歡使用backspace來刪除,有人喜歡用del來刪除。為了中斷正在運行的設備,一些系統使用ctrl-u來結束,但是現在一般使用ctrl-c來結束。
網絡
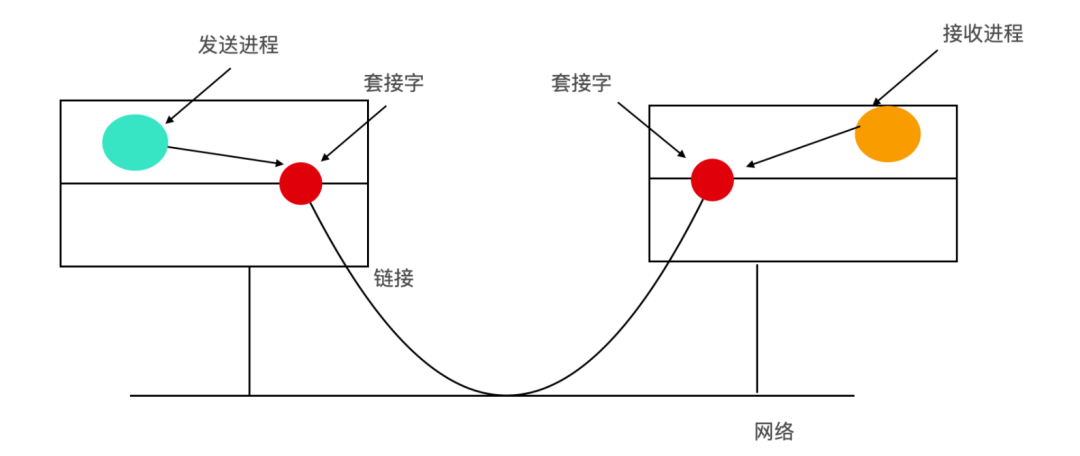
I/O 的另外一個概念是網絡, 也是由 UNIX 引入,網絡中一個很關鍵的概念就是套接字(socket)。套接字允許用戶連接到網絡,正如郵筒允許用戶連接到郵政系統,套接字的示意圖如下
套接字的位置如上圖所示,套接字可以動態創建和銷毀。成功創建一個套接字后,系統會返回一個文件描述符(file descriptor),在后面的創建鏈接、讀數據、寫數據、解除連接時都需要使用到這個文件描述符。每個套接字都支持一種特定類型的網絡類型,在創建時指定。一般最常用的幾種
可靠的面向連接的字節流
可靠的面向連接的數據包
不可靠的數據包傳輸
可靠的面向連接的字節流會使用管道在兩臺機器之間建立連接。能夠保證字節從一臺機器按照順序到達另一臺機器,系統能夠保證所有字節都能到達。
除了數據包之間的分界之外,第二種類型和第一種類型是類似的。如果發送了 3 次寫操作,那么使用第一種方式的接受者會直接接收到所有字節;第二種方式的接受者會分 3 次接受所有字節。除此之外,用戶還可以使用第三種即不可靠的數據包來傳輸,使用這種傳輸方式的優點在于高性能,有的時候它比可靠性更加重要,比如在流媒體中,性能就尤其重要。
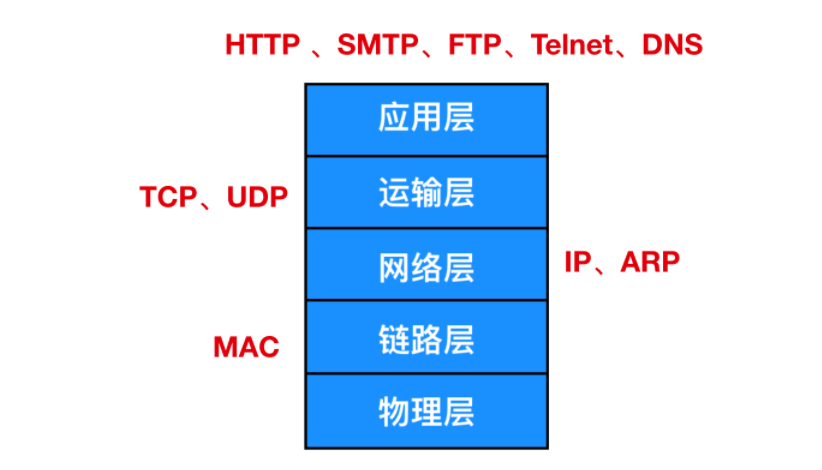
以上涉及兩種形式的傳輸協議,即TCP和UDP,TCP 是傳輸控制協議,它能夠傳輸可靠的字節流。UDP是用戶數據報協議,它只能夠傳輸不可靠的字節流。它們都屬于 TCP/IP 協議簇中的協議,下面是網絡協議分層
可以看到,TCP 、UDP 都位于網絡層上,可見它們都把 IP 協議 即互聯網協議作為基礎。
一旦套接字在源計算機和目的計算機建立成功,那么兩個計算機之間就可以建立一個鏈接。通信一方在本地套接字上使用listen系統調用,它就會創建一個緩沖區,然后阻塞直到數據到來。另一方使用connect系統調用,如果另一方接受 connect 系統調用后,則系統會在兩個套接字之間建立連接。
socket 連接建立成功后就像是一個管道,一個進程可以使用本地套接字的文件描述符從中讀寫數據,當連接不再需要的時候使用close系統調用來關閉。
Linux I/O 系統調用
Linux 系統中的每個 I/O 設備都有一個特殊文件(special file)與之關聯,什么是特殊文件呢?
?在操作系統中,特殊文件是一種在文件系統中與硬件設備相關聯的文件。特殊文件也被稱為設備文件(device file)。特殊文件的目的是將設備作為文件系統中的文件進行公開。特殊文件為硬件設備提供了借口,用于文件 I/O 的工具可以進行訪問。因為設備有兩種類型,同樣特殊文件也有兩種,即字符特殊文件和塊特殊文件?
對于大部分 I/O 操作來說,只用合適的文件就可以完成,并不需要特殊的系統調用。然后,有時需要一些設備專用的處理。在 POSIX 之前,大多數 UNIX 系統會有一個叫做ioctl的系統調用,它用于執行大量的系統調用。隨著時間的發展,POSIX 對其進行了整理,把 ioctl 的功能劃分為面向終端設備的獨立功能調用,現在已經變成獨立的系統調用了。
下面是幾個管理終端的系統調用
Linux IO 實現
Linux 中的 IO 是通過一系列設備驅動實現的,每個設備類型對應一個設備驅動。設備驅動為操作系統和硬件分別預留接口,通過設備驅動來屏蔽操作系統和硬件的差異。
當用戶訪問一個特殊的文件時,由文件系統提供此特殊文件的主設備號和次設備號,并判斷它是一個塊特殊文件還是字符特殊文件。主設備號用于標識字符設備還是塊設備,次設備號用于參數傳遞。
每個驅動程序都有兩部分:這兩部分都是屬于 Linux 內核,也都運行在內核態下。上半部分運行在調用者上下文并且與 Linux 其他部分交互。下半部分運行在內核上下文并且與設備進行交互。驅動程序可以調用內存分配、定時器管理、DMA 控制等內核過程。可被調用的內核功能都位于驅動程序 - 內核接口的文檔中。
I/O 實現指的就是對字符設備和塊設備的實現
塊設備實現
系統中處理塊特殊文件 I/O 部分的目標是為了使傳輸次數盡可能的小。為了實現這個目標,Linux 系統在磁盤驅動程序和文件系統之間設置了一個高速緩存(cache),如下圖所示
在 Linux 內核 2.2 之前,Linux 系統維護著兩個緩存:頁面緩存(page cache)和緩沖區緩存(buffer cache),因此,存儲在一個磁盤塊中的文件可能會在兩個緩存中。2.2 版本以后 Linux 內核只有一個統一的緩存一個通用數據塊層(generic block layer)把這些融合在一起,實現了磁盤、數據塊、緩沖區和數據頁之間必要的轉換。那么什么是通用數據塊層?
?通用數據塊層是一個內核的組成部分,用于處理對系統中所有塊設備的請求。通用數據塊主要有以下幾個功能
將數據緩沖區放在內存高位處,當 CPU 訪問數據時,頁面才會映射到內核線性地址中,并且此后取消映射
實現零拷貝機制,磁盤數據可以直接放入用戶模式的地址空間,而無需先復制到內核內存中
管理磁盤卷,會把不同塊設備上的多個磁盤分區視為一個分區。
利用最新的磁盤控制器的高級功能,例如 DMA 等。?
cache 是提升性能的利器,不管以什么樣的目的需要一個數據塊,都會先從 cache 中查找,如果找到直接返回,避免一次磁盤訪問,能夠極大的提升系統性能。
如果頁面 cache 中沒有這個塊,操作系統就會把頁面從磁盤中調入內存,然后讀入 cache 進行緩存。
cache 除了支持讀操作外,也支持寫操作,一個程序要寫回一個塊,首先把它寫到 cache 中,而不是直接寫入到磁盤中,等到磁盤中緩存達到一定數量值時再被寫入到 cache 中。
Linux 系統中使用IO 調度器來保證減少磁頭的反復移動從而減少損失。I/O 調度器的作用是對塊設備的讀寫操作進行排序,對讀寫請求進行合并。Linux 有許多調度器的變體,從而滿足不同的工作需要。最基本的 Linux 調度器是基于傳統的Linux 電梯調度器(Linux elevator scheduler)。Linux 電梯調度器的主要工作流程就是按照磁盤扇區的地址排序并存儲在一個雙向鏈表中。新的請求將會以鏈表的形式插入。這種方法可以有效的防止磁頭重復移動。因為電梯調度器會容易產生饑餓現象。因此,Linux 在原基礎上進行了修改,維護了兩個鏈表,在最后日期(deadline)內維護了排序后的讀寫操作。默認的讀操作耗時 0.5s,默認寫操作耗時 5s。如果在最后期限內等待時間最長的鏈表沒有獲得服務,那么它將優先獲得服務。
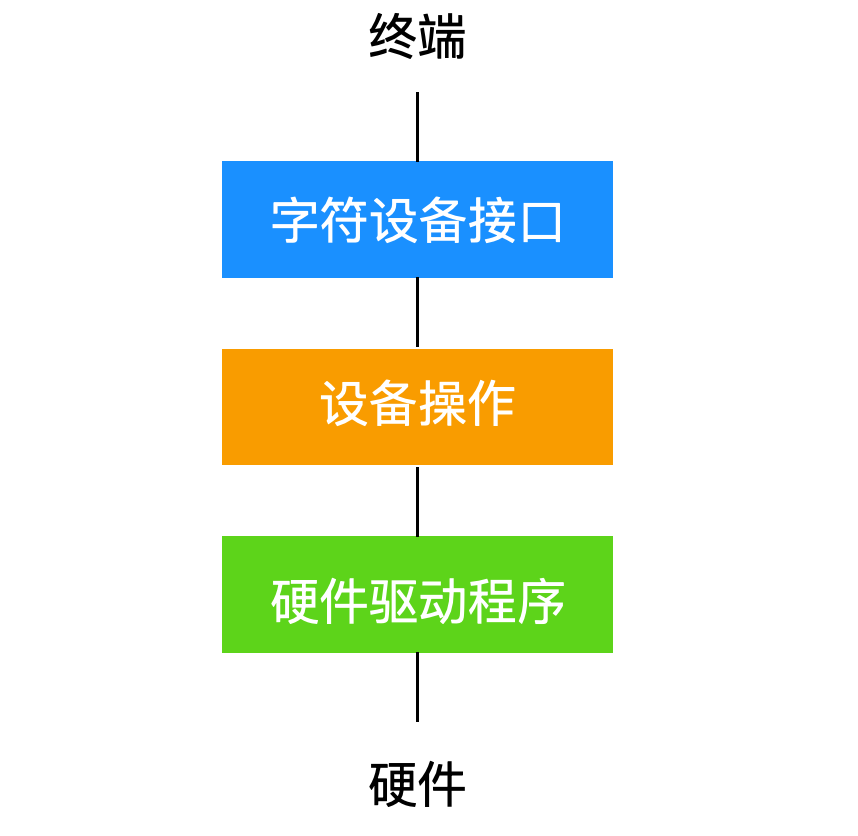
字符設備實現
和字符設備的交互是比較簡單的。由于字符設備會產生并使用字符流、字節數據,因此對隨機訪問的支持意義不大。一個例外是使用行規則(line disciplines)。一個行規可以和終端設備相關聯,使用tty_struct結構來表示,它表示與終端設備交換數據的解釋器,當然這也屬于內核的一部分。例如:行規可以對行進行編輯,映射回車為換行等一系列其他操作。
?什么是行規則?
行規是某些類 UNIX 系統中的一層,終端子系統通常由三層組成:上層提供字符設備接口,下層硬件驅動程序與硬件或偽終端進行交互,中層規則用于實現終端設備共有的行為。?
網絡設備實現
網絡設備的交互是不一樣的,雖然網絡設備(network devices)也會產生字符流,因為它們的異步(asynchronous)特性是他們不易與其他字符設備在同一接口下集成。網絡設備驅動程序會產生很多數據包,經由網絡協議到達用戶應用程序中。
Linux 中的模塊
UNIX 設備驅動程序是被靜態加載到內核中的。因此,只要系統啟動后,設備驅動程序都會被加載到內存中。隨著個人電腦 Linux 的出現,這種靜態鏈接完成后會使用一段時間的模式被打破。相對于小型機上的 I/O 設備,PC 上可用的 I/O 設備有了數量級的增長。絕大多數用戶沒有能力去添加一個新的應用程序、更新設備驅動、重新連接內核,然后進行安裝。
Linux 為了解決這個問題,引入了可加載(loadable module)機制。可加載是在系統運行時添加到內核中的代碼塊。
當一個模塊被加載到內核時,會發生下面幾件事情:第一,在加載的過程中,模塊會被動態的重新部署。第二,系統會檢查程序程序所需的資源是否可用。如果可用,則把這些資源標記為正在使用。第三步,設置所需的中斷向量。第四,更新驅動轉換表使其能夠處理新的主設備類型。最后再來運行設備驅動程序。
在完成上述工作后,驅動程序就會安裝完成,其他現代 UNIX 系統也支持可加載機制。
Linux 安全
Linux 作為 MINIX 和 UNIX 的衍生操作系統,從一開始就是一個多用戶系統。這意味著 Linux 從早期開始就建立了安全和信息訪問控制機制。下面我們主要探討的就是 Linux 安全性的一些內容
Linux 安全基本概念
一個 Linux 系統的用戶群里由一系列注冊用戶組成,他們每一個都有一個唯一的 UID (User ID)。一個 UID 是一個位于 0 到 65535 之間的整數。文件(進程或者是其他資源)都標記了它的所有者的 UID。默認情況下,文件的所有者是創建文件的人,文件的所有者是創建文件的用戶。
用戶可以被分成許多組,每個組都會由一個 16 位的整數標記,這個組叫做GID(組 ID)。給用戶分組是手動完成的,它由系統管理員執行,分組就是在數據庫中添加一條記錄指明哪個用戶屬于哪個組。一個用戶可以屬于不同組。
Linux 中的基本安全機制比較容易理解,每個進程都會記錄它所有者的 UID 和 GID。當文件創建后,它會獲取創建進程的 UID 和 GID。當一個文件被創建時,它的 UID 和 GID 就會被標記為進程的 UID 和 GID。這個文件同時會獲取由該進程決定的一些權限。這些權限會指定所有者、所有者所在組的其他用戶及其他用戶對文件具有什么樣的訪問權限。對于這三類用戶而言,潛在的訪問權限是「讀、寫和執行」,分別由 r、w 和 x 標記。當然,執行文件的權限僅當文件時可逆二進制程序時才有意義。試圖執行一個擁有執行權限的非可執行文件,系統會報錯。
「Linux 用戶分為三種」
root(超級管理員),它的 UID 為 0,這個用戶有極大的權限,可以直接無視很多的限制 ,包括讀寫執行的權限。
系統用戶,UID 為 1~499。
普通用戶,UID 范圍一般是 500~65534。這類用戶的權限會受到基本權限的限制,也會受到來自管理員的限制。不過要注意 nobody 這個特殊的帳號,UID 為 65534,這個用戶的權限會進一步的受到限制,一般用于實現來賓帳號。
Linux 中的每類用戶由 3 個比特為來標記,所以 9 個比特位就能夠表示所有的權限。
下面來看一下一些基本的用戶和權限例子
我們上面提到,UID 為 0 的是一個特殊用戶,稱為超級用戶(或者根用戶)。超級用戶能夠讀和寫系統中的任何文件,不管這個文件由誰所有,也不管這個文件的保護模式如何。UID 為 0 的進程還具有少數調用受保護系統調用的權限,而普通用戶是不可能有這些功能的。通常情況下,只有系統管理員知道超級用戶的密碼。
在 Linux 系統下,目錄也是一種文件,并且具有和普通文件一樣的保護模式。不同的是,目錄的 x 比特位表示查找權限而不是執行權限。因此,如果一個目錄的保護模式是rwxr-xr-x,那么它允許所有者讀、寫和查找目錄,而其他人只可以讀和查找,而不允許從中添加或者刪除目錄中的文件。
與 I/O 有關的特殊文件擁有和普通文件一樣的保護位。這種機制可以用來限制對 I/O 設備的訪問權限。舉個例子,打印機是特殊文件,它的目錄是/dev/lp,它可以被根用戶或者一個叫守護進程的特殊用戶擁有,具有保護模式 rw-------,從而阻止其他所有人對打印機的訪問。畢竟每個人都使用打印機的話會發生混亂。
當然,如果 /dev/lp 的保護模式是 rw-------,那就意味著其他任何人都不能使用打印機。
這個問題通過增加一個保護位SETUID到之前的 9 個比特位來解決。當一個進程的 SETUID 位打開,它的有效 UID將變成相應可執行文件的所有者 UID,而不是當前使用該進程的用戶的 UID。將訪問打印機的程序設置為守護進程所有,同時打開 SETUID 位,這樣任何用戶都可以執行此程序,而且擁有守護進程的權限。
除了 SETUID 之外,還有一個 SETGID 位,SETGID 的工作原理和 SETUID 類似。但是這個位一般很不常用。
Linux 安全相關的系統調用
Linux 中關于安全的系統調用不是很多,只有幾個,如下列表所示
我們在日常開發中用到最多的就是chmod了,沒想到我們日常開發過程中也能用到系統調用啊,chmod 之前我們一直認為是改變權限,現在專業一點是改變文件的保護模式。它的具體函數如下
s=chmod("路徑名","值");
例如
s=chmod("/usr/local/cxuan",777);
他就是會把/usr/local/cxuan這個路徑的保護模式改為 rwxrwxrwx,任何組和人都可以操作這個路徑。只有該文件的所有者和超級用戶才有權利更改保護模式。
access系統調用用來檢驗實際的 UID 和 GID 對某文件是否擁有特定的權限。下面就是四個 getxxx 的系統調用,這些用來獲取 uid 和 gid 的。
?注意:其中的 chown、setuid 和 setgid 是超級用戶才能使用,用來改變所有者進程的 UID 和 GID。?
Linux 安全實現
當用戶登錄時,登錄程序,也被稱為login,會要求輸入用戶名和密碼。它會對密碼進行哈希處理,然后在/etc/passwd中進行查找,看看是否有匹配的項。使用哈希的原因是防止密碼在系統中以非加密的方式存在。如果密碼正確,登錄程序會在 /etc/passwd 中讀取用戶選擇的 shell 程序的名稱,有可能是bash,有可能是shell或者其他的csh或ksh。然后登錄程序使用 setuid 和 setgid 這兩個系統調用來把自己的 UID 和 GID 變為用戶的 UID 和 GID,然后它打開鍵盤作為標準輸入、標準輸入的文件描述符是 0 ,屏幕作為標準輸出,文件描述符是 1 ,屏幕也作為標準錯誤輸出,文件描述符為 2。最后,執行用戶選擇的 shell 程序,終止。
當任何進程想要打開一個文件,系統首先將文件的 i - node 所記錄的保護位與用戶有效 UID 和 有效 GID 進行對比,來檢查訪問是否允許。如果訪問允許,就打開文件并返回文件描述符;否則不打開文件,返回 - 1。
Linux 安全模型和實現在本質上與大多數傳統的 UNIX 系統相同。
后記
這篇文章從 Linux 進程線程、內存管理、文件系統、IO 管理和安全來為你呈現了一幅 Linux 藍圖,文中涉及大量的系統調用和解釋,是你了解 Linux 操作系統需要仔細研讀的一篇文章。
責任編輯:xj
原文標題:對不起,學會這些 Linux 知識后,我有點飄
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
程序
應用
ls
列出目錄
cp
復制文件
head
顯示文件的前幾行
make
編譯文件生成二進制文件
cd
切換目錄
mkdir
創建目錄
chmod
修改文件訪問權限
ps
列出文件進程
pr
格式化打印
rm
刪除一個文件
rmdir
刪除文件目錄
tail
提取文件最后幾行
tr
字符集轉換
grep
分組
cat
將多個文件連續標準輸出
od
以八進制顯示文件
cut
從文件中剪切
paste
從文件中粘貼

系統調用指令
描述
pause
掛起信號
nice
改變分時進程的優先級
ptrace
進程跟蹤
kill
向進程發送信號
pipe
創建管道
mkfifo
創建 fifo 的特殊文件(命名管道)
sigaction
設置對指定信號的處理方法
msgctl
消息控制操作
semctl
信號量控制

系統調用
描述
s = brk(addr)
改變數據段大小
a = mmap(addr,len,prot,flags,fd,offset)
進行映射
s = unmap(addr,len)
取消映射


系統調用
描述
fd = creat(name,mode)
一種創建一個新文件的方式
fd = open(file, ...)
打開文件讀、寫或者讀寫
s = close(fd)
關閉一個打開的文件
n = read(fd, buffer, nbytes)
從文件中向緩存中讀入數據
n = write(fd, buffer, nbytes)
從緩存中向文件中寫入數據
position = lseek(fd, offset, whence)
移動文件指針
s = stat(name, &buf)
獲取文件信息
s = fstat(fd, &buf)
獲取文件信息
s = pipe(&fd[0])
創建一個管道
s = fcntl(fd,...)
文件加鎖等其他操作
存儲文件的設備
存儲文件的設備
i-node 編號
文件模式(包括保護位信息)
文件鏈接的數量
文件所有者標識
文件所屬的組
文件大小(字節)
創建時間
最后一個修改/訪問時間
系統調用
描述
s = mkdir(path,mode)
創建一個新的目錄
s = rmdir(path)
移除一個目錄
s = link(oldpath,newpath)
創建指向已有文件的鏈接
s = unlink(path)
取消文件的鏈接
s = chdir(path)
改變工作目錄
dir = opendir(path)
打開一個目錄讀取
s = closedir(dir)
關閉一個目錄
dirent = readdir(dir)
讀取一個目錄項
rewinddir(dir)
回轉目錄使其在此使用
對象
描述
超級塊
特定的文件系統
Dentry
目錄項,路徑的一個組成部分
I-node
特定的文件
File
跟一個進程相關聯的打開文件

屬性
字節
描述
Mode
2
文件屬性、保護位、setuid 和 setgid 位
Nlinks
2
指向 i - node 節點目錄項的數目
Uid
2
文件所有者的 UID
Gid
2
文件所有者的 GID
Size
4
文件字節大小
Addr
60
12 個磁盤塊以及后面 3 個間接塊的地址
Gen
1
每次重復使用 i - node 時增加的代號
Atime
4
最近訪問文件的時間
Mtime
4
最近修改文件的時間
Ctime
4
最近更改 i - node 的時間


系統調用
描述
tcgetattr
獲取屬性
tcsetattr
設置屬性
cfgetispeed
獲取輸入速率
cfgetospeed
獲取輸出速率
cfsetispeed
設置輸入速率
cfsetospeed
設置輸出速率
二進制
標記
準許的文件訪問權限
111000000
rwx------
所有者可讀、寫和執行
111111000
rwxrwx---
所有者和組可以讀、寫和執行
111111111
rwxrwxrwx
所有人可以讀、寫和執行
000000000
---------
任何人不擁有任何權限
000000111
------rwx
只有組以外的其他用戶擁有所有權
110100100
rw-r--r--
所有者可以讀和寫,其他人可以讀
110100100
rw-r-----
所有者可以讀和寫,組可以讀
系統調用
描述
chmod
改變文件的保護模式
access
使用真實的 UID 和 GID 測試訪問權限
chown
改變所有者和組
setuid
設置 UID
setgid
設置 GID
getuid
獲取真實的 UID
getgid
獲取真實的 GID
geteuid
獲取有效的 UID
getegid
獲取有效的 GID
-
Linux
+關注
關注
87文章
11298瀏覽量
209382 -
LINUX內核
+關注
關注
1文章
316瀏覽量
21646
原文標題:對不起,學會這些 Linux 知識后,我有點飄
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
deepin操作系統介紹

linux是實時系統還是分時操作系統
嵌入式 Linux 操作系統配置
linux操作系統安裝步驟 linux操作系統的特點及組成
Linux操作系統份額創歷史新高,逼近4.5%里程碑
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
聚徽觸控-工業一體機選擇什么操作系統好
嵌入式實時操作系統:Intewell操作系統與VxWorks操作系統有啥區別

工業實時操作系統對比:鴻道Intewell跟rt-linux有啥區別

研華工控機用什么系統?Windows與Linux操作系統的較量

服務器操作系統有幾種?

航天宏圖推出新一代衛星操作系統PIESAT-OS 1.0版





 工商網監
工商網監
評論