") 人工智能科普:數(shù)據(jù)質(zhì)量在 ML Ops 工作流中的關(guān)鍵作用
人工智能科普:數(shù)據(jù)質(zhì)量在 ML Ops 工作流中的關(guān)鍵作用
ML Ops 是 AI 領(lǐng)域中一個(gè)相對(duì)較新的概念,可解釋為「機(jī)器學(xué)習(xí)操作」。如何更好地管理數(shù)據(jù)科學(xué)家和操作人員,以便有效地開發(fā)、部署和監(jiān)視模型?其中數(shù)據(jù)質(zhì)量至關(guān)重要。
本文將介紹 ML Ops,并強(qiáng)調(diào)數(shù)據(jù)質(zhì)量在 ML Ops 工作流中的關(guān)鍵作用。
ML Ops 的發(fā)展彌補(bǔ)了機(jī)器學(xué)習(xí)與傳統(tǒng)軟件工程之間的差距,而數(shù)據(jù)質(zhì)量是 ML Ops 工作流的關(guān)鍵,可以加速數(shù)據(jù)團(tuán)隊(duì),并維護(hù)對(duì)數(shù)據(jù)的信任。
什么是 ML Ops
ML Ops 這個(gè)術(shù)語(yǔ)從 DevOps 演變而來。
DevOps 是一組過程、方法與系統(tǒng)的統(tǒng)稱,用于促進(jìn)開發(fā)(應(yīng)用程序 / 軟件工程)、技術(shù)運(yùn)營(yíng)和質(zhì)量保障(QA)部門之間的溝通、協(xié)作與整合。DevOps 旨在重視軟件開發(fā)人員(Dev)和 IT 運(yùn)維技術(shù)人員(Ops)之間溝通合作的文化、運(yùn)動(dòng)或慣例。透過自動(dòng)化軟件交付和架構(gòu)變更的流程,來使得構(gòu)建、測(cè)試、發(fā)布軟件能夠更加地快捷、頻繁和可靠。
而 MLOps 基于可提高工作流效率的 DevOps 原理和做法,例如持續(xù)集成、持續(xù)交付和持續(xù)部署。ML Ops 將這些原理應(yīng)用到機(jī)器學(xué)習(xí)過程,其目標(biāo)是:
更快地試驗(yàn)和開發(fā)模型
更快地將模型部署到生產(chǎn)環(huán)境
質(zhì)量保證
DevOps 的常用示例是使用多種工具對(duì)代碼進(jìn)行版本控制,如 git、代碼審查、持續(xù)集成(CI,即頻繁地將代碼合并到共享主線中)、自動(dòng)測(cè)試和持續(xù)部署(CD,即自動(dòng)將代碼合并到生產(chǎn)環(huán)境)。
在應(yīng)用于機(jī)器學(xué)習(xí)時(shí),ML Ops 旨在確保模型輸出質(zhì)量的同時(shí),加快機(jī)器學(xué)習(xí)模型的開發(fā)和生產(chǎn)部署。但是,與軟件開發(fā)不同,ML 需要處理代碼和數(shù)據(jù):
機(jī)器學(xué)習(xí)始于數(shù)據(jù),而數(shù)據(jù)來源不同,需要用代碼對(duì)不同來源數(shù)據(jù)進(jìn)行清洗、轉(zhuǎn)換和存儲(chǔ)。
然后,將處理好的數(shù)據(jù)提供給數(shù)據(jù)科學(xué)家,數(shù)據(jù)科學(xué)家進(jìn)行代碼編寫,完成特征工程、開發(fā)、訓(xùn)練和測(cè)試機(jī)器學(xué)習(xí)模型,最終將這些模型部署到生產(chǎn)環(huán)境中。
在生產(chǎn)中,ML 模型是以代碼的形式存在的,輸入數(shù)據(jù)同樣可以從各種來源獲取,并創(chuàng)建用于輸入產(chǎn)品和業(yè)務(wù)流程的輸出數(shù)據(jù)。
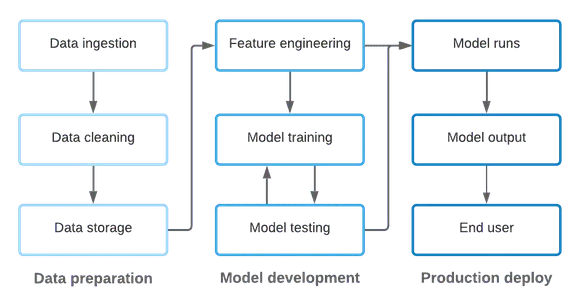
雖然上文的描述對(duì)該過程進(jìn)行了簡(jiǎn)化,但是仍然可以看出代碼和數(shù)據(jù)在 ML 環(huán)境中是緊密耦合的,而 ML Ops 需要兼顧兩者。
具體來說,這意味著 ML Ops 包含以下任務(wù):
對(duì)用于數(shù)據(jù)轉(zhuǎn)換和模型定義的代碼進(jìn)行版本控制;
在投入生產(chǎn)之前,對(duì)所獲取的數(shù)據(jù)和模型代碼進(jìn)行自動(dòng)測(cè)試;
在穩(wěn)定且可擴(kuò)展的環(huán)境中將模型部署到生產(chǎn)中;
監(jiān)控模型性能和輸出。
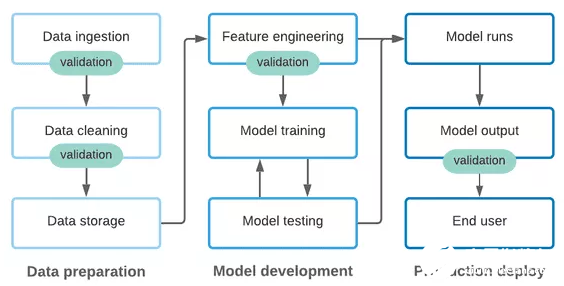
數(shù)據(jù)測(cè)試和文檔記錄如何適配 ML Ops?
ML Ops 旨在加速機(jī)器學(xué)習(xí)模型的開發(fā)和生產(chǎn)部署,同時(shí)確保模型輸出的質(zhì)量。當(dāng)然,對(duì)于數(shù)據(jù)質(zhì)量人員來說,要實(shí)現(xiàn) ML 工作流中各個(gè)階段的加速和質(zhì)量,數(shù)據(jù)測(cè)試和文檔記錄是非常重要的:
在利益相關(guān)者方面,質(zhì)量差的數(shù)據(jù)會(huì)影響他們對(duì)系統(tǒng)的信任,從而對(duì)基于該系統(tǒng)做出決策產(chǎn)生負(fù)面影響。甚至更糟的是,未引起注意的數(shù)據(jù)質(zhì)量問題可能導(dǎo)致錯(cuò)誤的結(jié)論,并糾正這些問題又會(huì)浪費(fèi)很多時(shí)間。
在工程方面,急于修復(fù)下游消費(fèi)者注意到的數(shù)據(jù)質(zhì)量問題,是消耗團(tuán)隊(duì)時(shí)間并緩慢侵蝕團(tuán)隊(duì)生產(chǎn)力和士氣的頭號(hào)問題之一。
此外,數(shù)據(jù)文檔記錄對(duì)于所有利益相關(guān)者進(jìn)行數(shù)據(jù)交流、建立數(shù)據(jù)合同至關(guān)重要。
下文將從非常抽象的角度介紹 ML pipeline 中的各個(gè)階段,并討論數(shù)據(jù)測(cè)試和文檔記錄如何適應(yīng)每個(gè)階段。
1. 數(shù)據(jù)獲取階段
即使是在數(shù)據(jù)集處理的早期階段,從長(zhǎng)遠(yuǎn)來看,對(duì)數(shù)據(jù)進(jìn)行質(zhì)量檢查和文檔記錄可以極大地加速操作。對(duì)于工程師來說,可靠的數(shù)據(jù)測(cè)試非常重要,可以使他們安全地對(duì)數(shù)據(jù)獲取 pipeline 進(jìn)行更改,而不會(huì)造成不必要的問題。同時(shí),當(dāng)從內(nèi)部和外部上游來源獲取數(shù)據(jù)時(shí),為了確保數(shù)據(jù)出現(xiàn)未預(yù)料的更改,在獲取階段進(jìn)行數(shù)據(jù)驗(yàn)證是非常重要的。
2. 模型開發(fā)
本文將特征工程、模型訓(xùn)練和模型測(cè)試作為核心模型開發(fā)流程的一部分。在這個(gè)不斷迭代的過程中,圍繞數(shù)據(jù)轉(zhuǎn)換代碼和支持?jǐn)?shù)據(jù)科學(xué)家的模型輸出提供支持,因此在一個(gè)地方進(jìn)行更改不會(huì)破壞其他地方的內(nèi)容。
在傳統(tǒng)的 DevOps 中,通過 CI/CD 工作流進(jìn)行持續(xù)的測(cè)試,可以快速地找出因代碼修改而引入的任何問題。更進(jìn)一步,大多數(shù)軟件工程團(tuán)隊(duì)要求開發(fā)人員不僅要使用現(xiàn)有的測(cè)試來測(cè)試代碼,還要在創(chuàng)建新功能時(shí)添加新的測(cè)試。同樣,運(yùn)行測(cè)試以及編寫新的測(cè)試應(yīng)該是 ML 模型開發(fā)過程的一部分。
3. 在生產(chǎn)中運(yùn)行模型
與所有 ML Ops 一樣,在生產(chǎn)環(huán)境中運(yùn)行的模型依賴于代碼和輸入數(shù)據(jù),來產(chǎn)生可靠的結(jié)果。與數(shù)據(jù)獲取階段類似,我們需要保護(hù)數(shù)據(jù)輸入,以避免由于代碼更改或?qū)嶋H數(shù)據(jù)更改而引起的不必要問題。同時(shí),我們還應(yīng)該圍繞模型輸出進(jìn)行一些測(cè)試,以確保模型繼續(xù)滿足我們的期望。
尤其是在具有黑盒 ML 模型的環(huán)境中,建立和維護(hù)質(zhì)量標(biāo)準(zhǔn)對(duì)于模型輸出至關(guān)重要。同樣地,在共享區(qū)域記錄模型的預(yù)期輸出可以幫助數(shù)據(jù)團(tuán)隊(duì)和利益相關(guān)者定義和傳達(dá)「數(shù)據(jù)合同」,從而增加 ML pipeline 的透明度和信任度。
原文鏈接:https://greatexpectations.io/blog/ml-ops-data-quality/
責(zé)編AJX
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7014瀏覽量
88980 -
人工智能
+關(guān)注
關(guān)注
1791文章
47233瀏覽量
238350 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8411瀏覽量
132600
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
嵌入式和人工智能究竟是什么關(guān)系?
soc在人工智能中的創(chuàng)新應(yīng)用
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第6章人AI與能源科學(xué)讀后感
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第二章AI for Science的技術(shù)支撐學(xué)習(xí)心得
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第一章人工智能驅(qū)動(dòng)的科學(xué)創(chuàng)新學(xué)習(xí)心得
risc-v在人工智能圖像處理應(yīng)用前景分析
FPGA在人工智能中的應(yīng)用有哪些?
西部數(shù)據(jù)發(fā)布AI數(shù)據(jù)周期框架,推動(dòng)人工智能革新
西部數(shù)據(jù)發(fā)布全新人工智能數(shù)據(jù)周期存儲(chǔ)框架,助力用戶發(fā)掘人工智能價(jià)值
人工智能在影像升級(jí)中的關(guān)鍵作用
引領(lǐng)數(shù)字時(shí)代:華為云函數(shù)工作流與人工智能的共舞

WiFi模塊引領(lǐng)智能制造時(shí)代:工業(yè)4.0中的關(guān)鍵作用
嵌入式人工智能的就業(yè)方向有哪些?
語(yǔ)音數(shù)據(jù)集在智能駕駛中的關(guān)鍵作用與應(yīng)用
DC電源模塊在物聯(lián)網(wǎng)設(shè)備中的關(guān)鍵作用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論