 關于C++編碼的轉換
關于C++編碼的轉換
【CPP開發者導讀】:在處理東方語言(中日韓)時,經常會遇到各種編碼問題,而且被這類問題搞的暈頭轉向。到網上查資料,看的也是一頭霧水,最后往往是誤打誤撞的把問題解決了,自己仍然稀里糊涂。
這篇文章介紹了如何在最常見的編碼方式(Unicode, UTF-8, ANSI)之間進行轉換,結合代碼實例,清晰明了,方便讀者理解,例子也可以直接拿來使用。本文推薦給經常對文字字符串進行處理的程序員閱讀,使其掌握字符轉換的一些基本方法。
以下是正文
C++的項目,字符編碼是一個大坑,不同平臺之間的編碼往往不一樣,如果不同編碼格式用一套字符讀取格式讀取就會出現亂碼。因此,一般都是轉化成UTF-8這種平臺通用,且支持性很好的編碼格式。
Unicode、UTF-8的概念不做過多解釋,這里說一下ANSI,我第一次看到這個名詞,我看成了ASCII。被Mentor狠批一頓。
ANSI是一種字符代碼,為使計算機支持更多語言,通常使用 0x00 ~ 0x7F范圍的1 個字節來表示 1 個英文字符。超出此范圍使用0x80~0xFFFF來編碼,即擴展的ASCII編碼。
不同的國家和地區制定了不同標準,由此產生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的編碼標準。這些使用多個字節來代表一個字符的各種漢字延伸編碼方式,稱為 ANSI 編碼。在簡體中文Windows操作系統,ANSI 編碼代表 GBK 編碼;在繁體中文Windows操作系統,ANSI編碼代表Big5;在日文Windows操作系統,ANSI 編碼代表 Shift_JIS 編碼。
以上內容摘自百度百科,可以看出,ANSI和ASCII還是有關系的。ANSI也叫本地碼。
我們要做到能在Unicode、UTF-8、ANSI這三種編碼格式中自由轉換。如下圖所示:
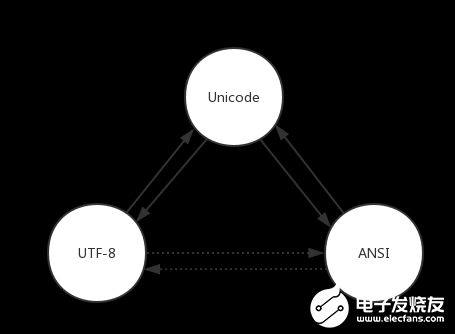
在C++中,要怎么做呢?當然是用標準庫的東西啦,C++11對國際化標準做得還是可以的,提供了這些接口,正如圖中虛線所示,標準庫沒有提供UTF-8到ANSI的互相轉化接口,但是我們可以自己封轉接口,借用這條路(UTF-8 《=》 Unicode 《=》 ANSI)來實現。
因此,接下來就聊聊UTF8 《=》 Unicode和Unicode 《=》 ANSI。
UTF8 《=》 Unicode
先看代碼:
std::string UnicodeToUTF8(const std::wstring & wstr){ std::string ret; try { std::wstring_convert《 std::codecvt_utf8《wchar_t》 》 wcv; ret = wcv.to_bytes(wstr); } catch (const std::exception & e) { std::cerr 《《 e.what() 《《 std::endl; } return ret;}std::wstring UTF8ToUnicode(const std::string & str){ std::wstring ret; try { std::wstring_convert《 std::codecvt_utf8《wchar_t》 》 wcv; ret = wcv.from_bytes(str); } catch (const std::exception & e) { std::cerr 《《 e.what() 《《 std::endl; } return ret;}
UTF-8是多字節字符串(multibyte string),而Unicode是寬字符字符串(wchar_t string)。
而C++11提供了wstring_convert這個類,這個類可以在wchar_t string和multibyte string之間來回轉換;
而codecvt_utf8可以提供UTF-8的編碼規則。這個類在#include 《codecvt》中。有了wstring_convert提供寬字符字符串到多字節字符串的轉化,而這個轉換規則由codecvt_uft8提供。這樣子就可以實現UTF8和Unicode的互相轉換。
從UTF8到Unicode調用成員函數wstring_convert::from_bytes;
從Unicode到UTF8調用成員函數wstring_convert::to_bytes;
Unicode 《=》 ANSI
std::string UnicodeToANSI(const std::wstring & wstr){ std::string ret; std::mbstate_t state = {}; const wchar_t *src = wstr.data(); size_t len = std::wcsrtombs(nullptr, &src, 0, &state); if (static_cast《size_t》(-1) != len) { std::unique_ptr《 char [] 》 buff(new char[len + 1]); len = std::wcsrtombs(buff.get(), &src, len, &state); if (static_cast《size_t》(-1) != len) { ret.assign(buff.get(), len); } } return ret;}std::wstring ANSIToUnicode(const std::string & str){ std::wstring ret; std::mbstate_t state = {}; const char *src = str.data(); size_t len = std::mbsrtowcs(nullptr, &src, 0, &state); if (static_cast《size_t》(-1) != len) { std::unique_ptr《 wchar_t [] 》 buff(new wchar_t[len + 1]); len = std::mbsrtowcs(buff.get(), &src, len, &state); if (static_cast《size_t》(-1) != len) { ret.assign(buff.get(), len); } } return ret;}
標準庫提供了wcsrtombs和mbsrtowcs這兩個函數,當然C的標準庫也提供了這兩個函數。
講下wcsrtombs,這個函數把寬字符串轉成多字節字符串。編碼規則受地域的LC_CTYPE影響。因此這個函數可以用于本地碼的轉化(和本地的編碼息息相關)。
因此,有關于本地碼的使用,在代碼中要加上下列語句:
setlocale(LC_CTYPE, “”);
目的是讓本地碼生效,這條代碼的作用就是讓C++語言的Locale(地域)和本地的地域相同。在Linux下可以運行locale命令看看:
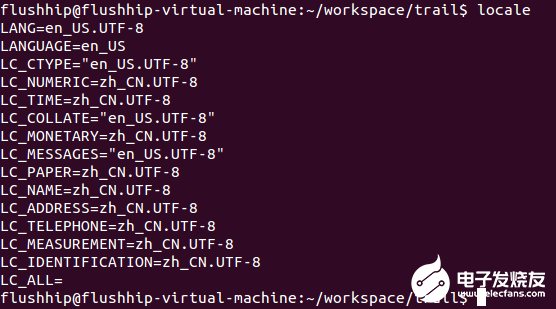
可以看到,LC_CTYPE = en_US.UTF-8,這表示英文,英國,UTF-8編碼,也就是說本地碼就是這個。
當然,你也可以在setlocale中指定一些編碼規則,把wcsrtombs用于別的編碼轉化,但是,這里不推薦,因為setlocale是全局的,設置了這個就會影響其他地方的編碼。
wcsrtombs的四個參數分別代表什么意思呢?
std::size_t wcsrtombs( char* dst, const wchar_t** src, std::size_t len, std::mbstate_t* ps );
dst,轉化后的結果存入dst指向的內存;
src,待轉化的字符串的指針的指針;
len,dst指向內存的可用字節數;
ps,轉換的狀態,一般默認初始化就好了;
return type,轉化后結果的長度,不包含\0。
注意:如果dst == nullptr,這個時候wcstombs的返回值表示會有這么多字節的結果產生,因此,我們可以拿到這個返回值去新建一個數組來存儲new char[len + 1]。所以,一般調用兩次wcstombs。
mbsrtowcs同理。
UTF-8 《=》 ANSI
以Unicode為中介裝換便是。
std::string UTF8ToANSI(const std::string & str){ return UnicodeToANSI(UTF8ToUnicode(str));}std::string ANSIToUTF8(const std::string & str){ return UnicodeToUTF8(ANSIToUnicode(str));}
總結
C++11的標準庫還是挺強大的,雖然這么強大,但是很多特性還不了解,因此還是要多擴寬自己的視野,不然有好東西都不知道用,那就棒槌了。
對了,在Linux下加上setlocale(LC_CTYPE, “”)后程序在命令行中可以正常顯示,不加有可能不正常顯示,原因是setlocale(LC_CTYPE, “”)也影響了cout,全局的嘛;而在CodeBlocks下不能正常顯示,不知道為什么,但是調試的過程中,觀察到了正常的結果;Visual Studio中沒有做實驗,不過應該沒問題。
作者:FlushHip
來源:CSDN
責任編輯:haq
-
編程
+關注
關注
88文章
3614瀏覽量
93686 -
編碼
+關注
關注
6文章
942瀏覽量
54814 -
C++
+關注
關注
22文章
2108瀏覽量
73623
發布評論請先 登錄
相關推薦

OpenVINO2024 C++推理使用技巧
c++編譯后鏈接失敗的原因?如何解決?
C++中實現類似instanceof的方法

keil用c++編譯含有rtos模塊時的錯誤問題怎么解決?
鴻蒙OS開發實例:【Native C++】
使用 MISRA C++:2023? 避免基于范圍的 for 循環中的錯誤

c語言,c++,java,python區別
vb語言和c++語言的區別
C++在Linux內核開發中從爭議到成熟

C++簡史:C++是如何開始的





 工商網監
工商網監
評論