 數據庫設計的技巧分享
數據庫設計的技巧分享
1.原始單據與實體之間的關系
可以是一對一、一對多、多對多的關系。在一般情況下,它們是一對一的關系:即一張原始單據對應且只對應一個實體。在特殊情況下,它們可能是一對多或多對一的關系,即一張原始單證對應多個實體,或多張原始單證對應一個實體。這里的實體可以理解為基本表。明確這種對應關系后,對我們設計錄入界面大有好處。
〖例1〗:一份員工履歷資料,在人力資源信息系統中,就對應三個基本表:員工基本情況表、社會關系表、工作簡歷表。這就是“一張原始單證對應多個實體”的典型例子。
2.主鍵與外鍵
一般而言,一個實體不能既無主鍵又無外鍵。在E—R圖中,處于葉子部位的實體,可以定義主鍵,也可以不定義主鍵(因為它無子孫),但必須要有外鍵(因為它有父親)。
主鍵與外鍵的設計,在全局數據庫的設計中,占有重要地位。當全局數據庫的設計完成以后,有個美國數據庫設計專家說:“鍵,到處都是鍵,除了鍵之外,什么也沒有”,這就是他的數據庫設計經驗之談,也反映了他對信息系統核心(數據模型)的高度抽象思想。因為:主鍵是實體的高度抽象,主鍵與外鍵的配對,表示實體之間的連接。
3.基本表的性質
基本表與中間表、臨時表不同,因為它具有如下四個特性:
原子性。基本表中的字段是不可再分解的。
原始性。基本表中的記錄是原始數據(基礎數據)的記錄。
演繹性。由基本表與代碼表中的數據,可以派生出所有的輸出數據。
穩定性。基本表的結構是相對穩定的,表中的記錄是要長期保存的。
理解基本表的性質后,在設計數據庫時,就能將基本表與中間表、臨時表區分開來。
4.范式標準
基本表及其字段之間的關系,應盡量滿足第三范式。但是,滿足第三范式的數據庫設計,往往不是最好的設計。為了提高數據庫的運行效率,常常需要降低范式標準:適當增加冗余,達到以空間換時間的目的。
〖例2〗:有一張存放商品的基本表,如表1所示。“金額”這個字段的存在,表明該表的設計不滿足第三范式,因為“金額”可以由“單價”乘以“數量”得到,說明“金額”是冗余字段。但是,增加“金額”這個冗余字段,可以提高查詢統計的速度,這就是以空間換時間的作法。
在Rose2002中,規定列有兩種類型:數據列和計算列。“金額”這樣的列被稱為“計算列”,而“單價”和“數量”這樣的列被稱為“數據列”。
表1商品表的表結構
5.通俗地理解三個范式
通俗地理解三個范式,對于數據庫設計大有好處。在數據庫設計中,為了更好地應用三個范式,就必須通俗地理解三個范式(通俗地理解是夠用的理解,并不是最科學最準確的理解):
第一范式:1NF是對屬性的原子性約束,要求屬性具有原子性,不可再分解;
第二范式:2NF是對記錄的惟一性約束,要求記錄有惟一標識,即實體的惟一性;
第三范式:3NF是對字段冗余性的約束,即任何字段不能由其他字段派生出來,它要求字段沒有冗余。
沒有冗余的數據庫設計可以做到。但是,沒有冗余的數據庫未必是最好的數據庫,有時為了提高運行效率,就必須降低范式標準,適當保留冗余數據。
具體做法是:在概念數據模型設計時遵守第三范式,降低范式標準的工作放到物理數據模型設計時考慮。降低范式就是增加字段,允許冗余。
6.要善于識別與正確處理多對多的關系
若兩個實體之間存在多對多的關系,則應消除這種關系。消除的辦法是,在兩者之間增加第三個實體。這樣,原來一個多對多的關系,現在變為兩個一對多的關系。要將原來兩個實體的屬性合理地分配到三個實體中去。這里的第三個實體,實質上是一個較復雜的關系,它對應一張基本表。一般來講,數據庫設計工具不能識別多對多的關系,但能處理多對多的關系。
〖例3〗:在“圖書館信息系統”中,“圖書”是一個實體,“讀者”也是一個實體。這兩個實體之間的關系,是一個典型的多對多關系:一本圖書在不同時間可以被多個讀者借閱,一個讀者又可以借多本圖書。為此,要在二者之間增加第三個實體,該實體取名為“借還書”,它的屬性為:借還時間、借還標志(0表示借書,1表示還書),另外,它還應該有兩個外鍵(“圖書”的主鍵,“讀者”的主鍵),使它能與“圖書”和“讀者”連接。
7.主鍵PK的取值方法
PK是供程序員使用的表間連接工具,可以是一無物理意義的數字串,由程序自動加1來實現。也可以是有物理意義的字段名或字段名的組合。不過前者比后者好。當PK是字段名的組合時,建議字段的個數不要太多,多了不但索引占用空間大,而且速度也慢。
8.正確認識數據冗余
主鍵與外鍵在多表中的重復出現,不屬于數據冗余,這個概念必須清楚,事實上有許多人還不清楚。非鍵字段的重復出現,才是數據冗余!而且是一種低級冗余,即重復性的冗余。高級冗余不是字段的重復出現,而是字段的派生出現。
〖例4〗:商品中的“單價、數量、金額”三個字段,“金額”就是由“單價”乘以“數量”派生出來的,它就是冗余,而且是一種高級冗余。冗余的目的是為了提高處理速度。只有低級冗余才會增加數據的不一致性,因為同一數據,可能從不同時間、地點、角色上多次錄入。因此,我們提倡高級冗余(派生性冗余),反對低級冗余(重復性冗余)。
9.E--R圖沒有標準答案
信息系統的E--R圖沒有標準答案,因為它的設計與畫法不是惟一的,只要它覆蓋了系統需求的業務范圍和功能內容,就是可行的。反之要修改E--R圖。盡管它沒有惟一的標準答案,并不意味著可以隨意設計。好的E—R圖的標準是:結構清晰、關聯簡潔、實體個數適中、屬性分配合理、沒有低級冗余。
10.視圖技術在數據庫設計中很有用
與基本表、代碼表、中間表不同,視圖是一種虛表,它依賴數據源的實表而存在。視圖是供程序員使用數據庫的一個窗口,是基表數據綜合的一種形式,是數據處理的一種方法,是用戶數據保密的一種手段。為了進行復雜處理、提高運算速度和節省存儲空間,視圖的定義深度一般不得超過三層。若三層視圖仍不夠用,則應在視圖上定義臨時表,在臨時表上再定義視圖。
這樣反復交迭定義,視圖的深度就不受限制了。對于某些與國家政治、經濟、技術、軍事和安全利益有關的信息系統,視圖的作用更加重要。這些系統的基本表完成物理設計之后,立即在基本表上建立第一層視圖,這層視圖的個數和結構,與基本表的個數和結構是完全相同。并且規定,所有的程序員,一律只準在視圖上操作。只有數據庫管理員,帶著多個人員共同掌握的“安全鑰匙”,才能直接在基本表上操作。請讀者想想:這是為什么?
11.中間表、報表和臨時表
中間表是存放統計數據的表,它是為數據倉庫、輸出報表或查詢結果而設計的,有時它沒有主鍵與外鍵(數據倉庫除外)。臨時表是程序員個人設計的,存放臨時記錄,為個人所用。基表和中間表由DBA維護,臨時表由程序員自己用程序自動維護。
12.完整性約束表現在三個方面
域的完整性:用Check來實現約束,在數據庫設計工具中,對字段的取值范圍進行定義時,有一個Check按鈕,通過它定義字段的值城。參照完整性:用PK、FK、表級觸發器來實現。用戶定義完整性:它是一些業務規則,用存儲過程和觸發器來實現。
13.防止數據庫設計打補丁的方法是“三少原則”
一個數據庫中表的個數越少越好。只有表的個數少了,才能說明系統的E--R圖少而精,去掉了重復的多余的實體,形成了對客觀世界的高度抽象,進行了系統的數據集成,防止了打補丁式的設計;
一個表中組合主鍵的字段個數越少越好。因為主鍵的作用,一是建主鍵索引,二是做為子表的外鍵,所以組合主鍵的字段個數少了,不僅節省了運行時間,而且節省了索引存儲空間;
一個表中的字段個數越少越好。只有字段的個數少了,才能說明在系統中不存在數據重復,且很少有數據冗余,更重要的是督促讀者學會“列變行”,這樣就防止了將子表中的字段拉入到主表中去,在主表中留下許多空余的字段。所謂“列變行”,就是將主表中的一部分內容拉出去,另外單獨建一個子表。這個方法很簡單,有的人就是不習慣、不采納、不執行。
數據庫設計的實用原則是:在數據冗余和處理速度之間找到合適的平衡點。“三少”是一個整體概念,綜合觀點,不能孤立某一個原則。該原則是相對的,不是絕對的。“三多”原則肯定是錯誤的。試想:若覆蓋系統同樣的功能,一百個實體(共一千個屬性)的E--R圖,肯定比二百個實體(共二千個屬性)的E--R圖,要好得多。
提倡“三少”原則,是叫讀者學會利用數據庫設計技術進行系統的數據集成。數據集成的步驟是將文件系統集成為應用數據庫,將應用數據庫集成為主題數據庫,將主題數據庫集成為全局綜合數據庫。
集成的程度越高,數據共享性就越強,信息孤島現象就越少,整個企業信息系統的全局E—R圖中實體的個數、主鍵的個數、屬性的個數就會越少。
提倡“三少”原則的目的,是防止讀者利用打補丁技術,不斷地對數據庫進行增刪改,使企業數據庫變成了隨意設計數據庫表的“垃圾堆”,或數據庫表的“大雜院”,最后造成數據庫中的基本表、代碼表、中間表、臨時表雜亂無章,不計其數,導致企事業單位的信息系統無法維護而癱瘓。
“三多”原則任何人都可以做到,該原則是“打補丁方法”設計數據庫的歪理學說。“三少”原則是少而精的原則,它要求有較高的數據庫設計技巧與藝術,不是任何人都能做到的,因為該原則是杜絕用“打補丁方法”設計數據庫的理論依據。
14.提高數據庫運行效率的辦法
在給定的系統硬件和系統軟件條件下,提高數據庫系統的運行效率的辦法是:
在數據庫物理設計時,降低范式,增加冗余,少用觸發器,多用存儲過程。
當計算非常復雜、而且記錄條數非常巨大時(例如一千萬條),復雜計算要先在數據庫外面,以文件系統方式用C++語言計算處理完成之后,最后才入庫追加到表中去。這是電信計費系統設計的經驗。
發現某個表的記錄太多,例如超過一千萬條,則要對該表進行水平分割。水平分割的做法是,以該表主鍵PK的某個值為界線,將該表的記錄水平分割為兩個表。若發現某個表的字段太多,例如超過八十個,則垂直分割該表,將原來的一個表分解為兩個表。
對數據庫管理系統DBMS進行系統優化,即優化各種系統參數,如緩沖區個數。SQL數據庫小技巧,這個推薦看一下。
在使用面向數據的SQL語言進行程序設計時,盡量采取優化算法。
總之,要提高數據庫的運行效率,必須從數據庫系統級優化、數據庫設計級優化、程序實現級優化,這三個層次上同時下功夫。
上述十四個技巧,是許多人在大量的數據庫分析與設計實踐中,逐步總結出來的。對于這些經驗的運用,讀者不能生幫硬套,死記硬背,而要消化理解,實事求是,靈活掌握。并逐步做到:在應用中發展,在發展中應用。
責任編輯人:CC
-
數據庫
+關注
關注
7文章
3798瀏覽量
64371 -
數據庫設計
+關注
關注
0文章
4瀏覽量
5694
發布評論請先 登錄
相關推薦
數據庫加密辦法
數據庫數據恢復—Mysql數據庫表記錄丟失的數據恢復流程

數據庫事件觸發的設置和應用
數據庫數據恢復—MYSQL數據庫ibdata1文件損壞的數據恢復案例
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

數據庫數據恢復—Oracle數據庫文件system01.dbf損壞的數據恢復案例
數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

恒訊科技分析:sql數據庫怎么用?
數據庫數據恢復—SQL Server數據庫所在分區空間不足報錯的數據恢復案例
數據庫數據恢復—raid5陣列上層Sql Server數據庫數據恢復案例

選擇 KV 數據庫最重要的是什么?
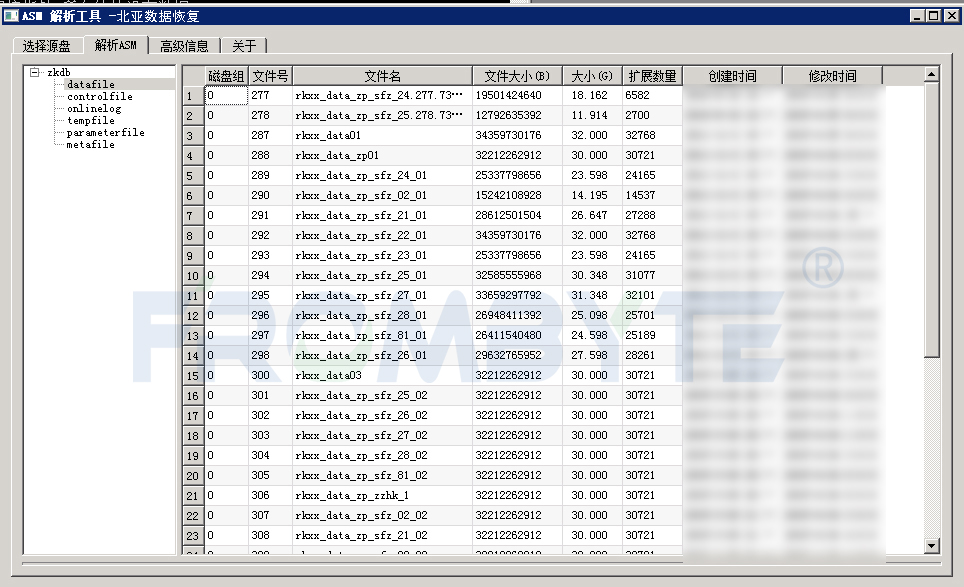
【數據庫數據恢復】Oracle數據庫ASM實例無法掛載的數據恢復案例
Oracle數據庫是什么 Oracle數據庫的特點
星火夜話,論道國產數據庫






 工商網監
工商網監
評論